基于参数寻优决策树SVM的语音情感识别
2018-07-25孙林慧
王 富,孙林慧,苏 敏,赵 城
(南京邮电大学 通信与信息工程学院 宽带无线通信与传感网技术教育部重点实验室,江苏 南京 210003)
0 引 言
近年来,随着人工智能的飞速发展,人机交互技术得到了广泛应用。目前,虽已有很多人机交互产品在生活中得到应用,但都无法从情感层面去理解人类意图。为了实现更加智能化的人机交互,人机交互产品必须能够充分理解人类情感。语音作为人类日常生活中交流的主要方式,其所承载的情感信息越来越受到研究者重视,并被应用到人机交互领域[1-2]。目前,语音情感识别存在两大难点[3]:一是如何寻找有效的语音情感特征,二是如何构造合适的语音情感识别模型。
当前,被应用于语音情感识别的特征参数主要有韵律学特征、基于谱的特征和音质特征[4]。由于语音信号的这些特征分别从不同的方面对语音情感信息进行表达,且单一的特征识别效果不理想,因此特征联合的语音情感识别成为当前的主要研究方向[5-6]。文献[7]将语音信号的能量、基音频率、同态频率系数和共振峰应用到语音情感识别中,并在生气、高兴和伤心三种情感的识别中取得了87.25%的正确识别率。Wang K等将语音信号的前120个傅里叶系数(Fourier parameters,FP)和梅尔倒谱系数(Mel-frequency cepstral coefficient,MFCC)应用到语音情感识别中,在德国柏林语音情感数据库的六种情感识别中取得了79.51%的正确识别率[8]。语音情感识别是一个典型的模式识别问题,分类器的性能对识别效果具有重要的作用。目前,在语音情感识别领域应用比较广的分类器有:高斯混合模型(Gaussian mixture model,GMM)[9]、人工神经网络(artificial neutral network,ANN)[10]和支持向量机(support vector machines,SVM)等。其中,SVM在解决非线性、小样本以及高维模式识别等方面表现出了特有的优势,因此广泛应用于语音情感识别中[11-12]。文献[13]将多级SVM分类算法应用到德国柏林情感语料库七种情感的识别中,并取得了63.74%的正确识别率。同时,在多种情感识别的情况下,基于决策树SVM的识别模型也被应用到语音情感识别中,并取得了不错的效果[14]。但是,SVM的核函数及其参数对SVM的识别效果影响比较大,目前研究领域中还没有统一的标准,一般是多次尝试取其经验值,或者是通过寻优算法对其参数进行寻优。目前,应用于SVM参数寻优的算法主要有微粒群优化算法(particle swarm optimization,PSO)、遗传算法(genetic algorithm,GA)等[15-16]。
在语音多种情感识别中,由于部分情感状态容易混淆,语音情感之间的可分性存在差异,导致语音情感识别的识别率不高;同时,对于不同的训练集,SVM参数惩罚因子和核函数参数对识别结果也存在一定影响。为了有效提高语音情感识别系统的识别率,提出了一种基于参数寻优决策树SVM的语音情感识别方法,并通过实验对该方法进行验证。
1 语音情感特征参数的提取
在语音情感识别中,特征参数通常以帧为单位进行提取,由于单帧含有的信息较少,大部分研究者将特征参数以多帧为单位计算统计变量的形式用于情感识别任务。文中采用MFCC和傅里叶系数这两种特征,并以多帧为单位分别计算这两种特征的5个统计变量(最大值、最小值、均值、标准差和中值),并将其应用于识别任务。
1.1 MFCC参数
MFCC参数是根据人耳听觉特性,将频谱最终转化为倒谱域上的系数。它将人耳的听觉感知特性和语音信号的产生机制有效地结合起来,具有较好的识别性能和抗噪能力,广泛应用于语音识别中。文中选取了24维MFCC参数以及它的一阶差分作为特征参数。
1.2 傅里叶系数
傅里叶分析是信号领域主要的分析方法之一。近年来,研究者通过傅里叶分析提取了语音信号的傅里叶系数,并将其应用于语音情感识别,取得了不错的效果[17]。傅里叶系数的提取过程:语音信号首先经过预加重、分帧、加窗等预处理,然后进行傅里叶变换得到谐波系数,并计算每个谐波系数的模值得到傅里叶系数。文中采用它的前160个系数用于识别。
2 基于参数寻优决策树SVM的构造
2.1 支持向量机简介
SVM是一种应用广泛的机器学习方法。对于非线性可分的问题,它的基本思想是:通过非线性变换将输入空间映射到一个高维特征空间中,数据被超平面进行分割,在高维空间变得可分,因此在高维空间中寻找一个最优超平面是训练SVM的目标[17]。
非线性可分的支持向量机对应的目标函数如下:
(1)
其中,ω为权系数向量;b为常量;C为惩罚系数,它控制着对错分样本的惩罚程度,具有平衡模型复杂度和损失误差的作用;ξI为松弛因子,用来调整分类面允许分类过程中存在一定的错分样本。
数据空间样本点xi和xj,采用数据空间到特征空间的映射函数Φ(),应用核函数变换等式:(xi,xj)→K(xi,xj)=Φ(xi)·Φ(xj),得到最优超平面函数:
(2)
其中,αi为拉格朗日因子。
SVM用于处理分类问题时,有一对多(one-to-all)和一对一(one-to-one)两种策略。根据前期的分析研究,一对一的分类策略更有效,故文中采用该策略。核函数是支持向量机的关键,目前常用的核函数有线性核函数、多项式核函数、径向基核函数和多层感知机核函数等。根据前期的实验发现,文中采用效果最好的径向基核函数。如何选择合适的惩罚因子C和核函数参数g是训练一个SVM分类器的关键问题。
2.2 遗传算法参数优化过程
遗传算法是一种借鉴生物界的进化规律演变而来的随机优化搜索方法[18]。遗传算法参数优化是将需要优化的参数进行二进制编码构成染色体,随机产生初始的群体。在遗传进化过程中,利用基于适应度函数的选择策略来模拟“优胜劣汰”生存法则进行个体选择,采用交叉和变异两个过程来产生下一代种群,种群不断进行优化直到满足终止条件。最后一代的染色体作为全局最优解,经过解码得到优化后的参数。
文中采用遗传算法对SVM参数进行寻优的具体步骤为:
(1)参数初始化,并对SVM的惩罚因子C和核函数参数g进行二进制编码,然后随机产生初始种群。
(2)将解码后的参数C和g代入SVM分类函数中,把训练得到的识别率作为适应度值。适应度越高的个体遗传给下一代的概率就越大,反之则越小。
(3)选择操作,根据适应度值在每代进化中模拟“优胜劣汰”生存法则,从群体中选取优良的个体,作为父代再产生新的群体。
(4)交叉操作,挑选出选择操作后的个体,按照交叉概率产生新个体。
(5)变异操作,在群体个体中,根据变异的概率来改变某基音座的基音,从而产生新个体。
(6)解码并计算适应度值,同时将子代和父代之间的分类识别率进行比较,更新最优个体。
(7)判断迭代次数或者适应度值是否满足终止条件。如果没有,则重复步骤3~6;如果满足条件,则执行步骤8。
(8)输出最优解C和g。
2.3 决策树SVM的构造策略
在多种情感识别中,由于情感间的混淆度比较大,从而降低了整体的识别率。针对此问题,先将比较接近的情感归为一类,用一级SVM进行粗分类,然后针对容易混淆的情感通过利用不同的特征参数来训练不同的SVM进行细分类,从而实现对所有情感的分类。
首先定义一个情感状态集合E={e1,e2,…,en},其中情感状态的个数s=n。情感混淆度是指各类情感之间的相似度,定义第i类情感ei和第j类情感ej的混淆度为Ii,j,其表示第i类情感误判为第j类情感和第j类情感误判为第i类情感的概率的平均值[13]。计算公式为:
(3)
其中,x为测试样本;r为测试样本x所对应的分类结果。
决策树SVM构造算法的具体步骤如下:
(1)利用MFCC参数及傅里叶系数和传统SVM的方法计算出情感识别混淆矩阵,并根据混淆矩阵计算出各类情感之间的混淆度。
(2)将混淆度超过阈值P的情感分为一类,且初次分类时阈值被设置为6%。若情感不重复,则将其分为一组;若与其他组内情感重复,则将重复组并为一组。即若Ia,b>P,Ic,d>P,则将a,b分为一组,c,d分为一组;若Ia,b>P,Ib,c>P,则将a,b,c分为一组。如果某种情感与其他情感的混淆度都小于阈值,则将其单独归为一类。
(3)对于未分组的情感类别,根据式3计算与其他情感类别之间的混淆度,转至步骤2,将其分入已有组或者单独成组。
(4)计算各组中情感类别个数,如果个数大于2,则将阈值P增加6%,并转至步骤1;否则,转至步骤5。
(5)所有情感都完成分组,结束。
2.4 基于参数寻优决策树SVM的构造流程
为了更好地提高多分类语音情感识别的识别率,提出了基于参数寻优决策树SVM的语音情感识别方法。该方法首先将语音信号进行预处理,提取语音信号的MFCC系数和傅里叶系数。然后采用MFCC系数及傅里叶系数和传统SVM进行实验得到情感间的混淆矩阵,并根据混淆矩阵计算得到情感间的混淆度,同时根据决策树SVM构造策略来构造决策树SVM。当决策树SVM构造完成之后,采用遗传算法为决策树SVM中每个SVM的惩罚因子C及其核函数参数g进行寻优,并将寻优后的参数用于训练SVM模型。
3 实验与结果分析
3.1 实验语料库及实验环境
实验采用的语料库为中科院汉语情感语音库,该语料库由中科院自动化所录制并提供。该语料库由两名男性和两名女性专业发音人录制而成,包括生气(angry)、高兴(happy)、害怕(fear)、平静(neutral)、惊讶(surprise)和伤心(sad)六种不同情感,共1 200条语句。该语料库的采样率为16 000样值/秒,采用16 bit量化,并以wav的格式存储。文中利用所有的情感语句进行实验。为了排除性别和说话人对实验的影响,实验均是采用十折交叉验证的方法,即每种情感的语料随机分成十份,且每一份中各类情感的比重相同。在识别时,将每一部分轮流抽取九份作为训练数据,剩下的一份作为测试数据。最后将十次识别结果的平均值作为最终的识别结果。采用的分类器为SVM分类器,并使用台湾大学林智仁教授开发的LIBSVM工具箱来实现SVM。实验环境为Matlab2013a,LIBSVM的安装环境为Visual Studio 2010。
在提取语音信号的参数时,都先对语音信号进行端点检测,并且以帧长为256点、帧移为128点的形式对语音信号进行分帧。实验所选的特征参数为傅里叶系数的前160个、24阶的MFCC及其一阶差分,并求出它们各自的统计变量(最大值、最小值、均值、中值、方差),共1 040维,构成联合特征。同时,所有的特征参数数据都进行归一化。
3.2 实验仿真与分析
3.2.1 基于参数寻优决策树SVM的具体构造
首先,采用传统的MFCC参数及傅里叶系数和传统的SVM对语音库中的六种情感进行实验,得到六种情感之间的混淆矩阵,如表1所示。
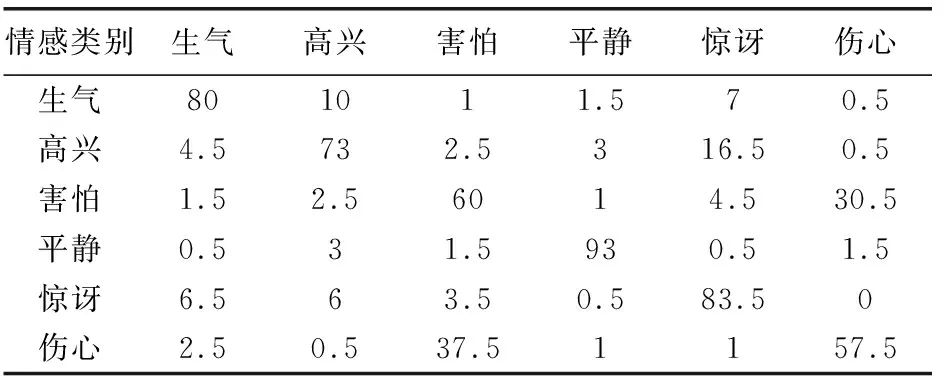
表1 六种情感的识别率混淆矩阵 %
根据式3计算六种情感间的混淆度,得到任意两种情感间的混淆度,如表2所示。
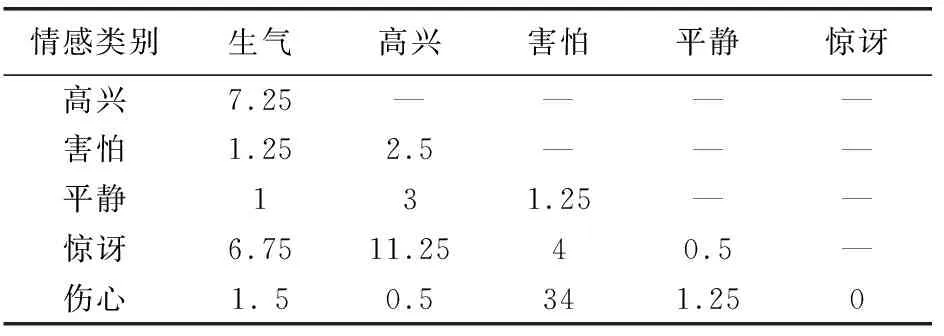
表2 六种情感的类别间混淆度 %
从表2中可得,生气与惊讶的混淆度为7.25%,高兴与生气的混淆度为6.75%,它们之间的混淆度都大于初次分类的阈值6%,依据决策树SVM构造策略的步骤2可知,将生气、高兴、惊讶归为一大类;由于害怕与伤心两种情感之间的混淆度为34%,同理可将害怕和伤心归为一大类;由于平静与其他情感之间的混淆度都小于初次分类的阈值6%,所以将其单独归为一大类。此时,通过SVM1对这三大类情感进行区分。
根据决策树SVM构造算法中的步骤4,需要对生气、高兴和惊讶三种情感进行再分类,因此通过构造算法得到这三类情感之间的混淆度如下:生气与惊讶之间的混淆度为7.25%,高兴与惊讶之间的混淆度为11.5%,高兴与生气之间的混淆度为8%。其混淆度都小于第二次分类的阈值12%,根据决策树SVM构造算法,将生气、高兴和惊讶归为一类,采用SVM2直接进行分类。对于害怕和伤心这两种情感,直接采用SVM3进行二分类。
在SVM的训练过程中,SVM的惩罚因子C和核函数参数g对识别效果影响较大,且不同的训练集需要不同的参数值。因此,采用遗传算法为决策树SVM中每个SVM的惩罚因子C和核函数参数g进行寻优,并将寻优后的参数用于训练SVM模型。
得到的基于参数寻优决策树SVM的结构如图1所示。
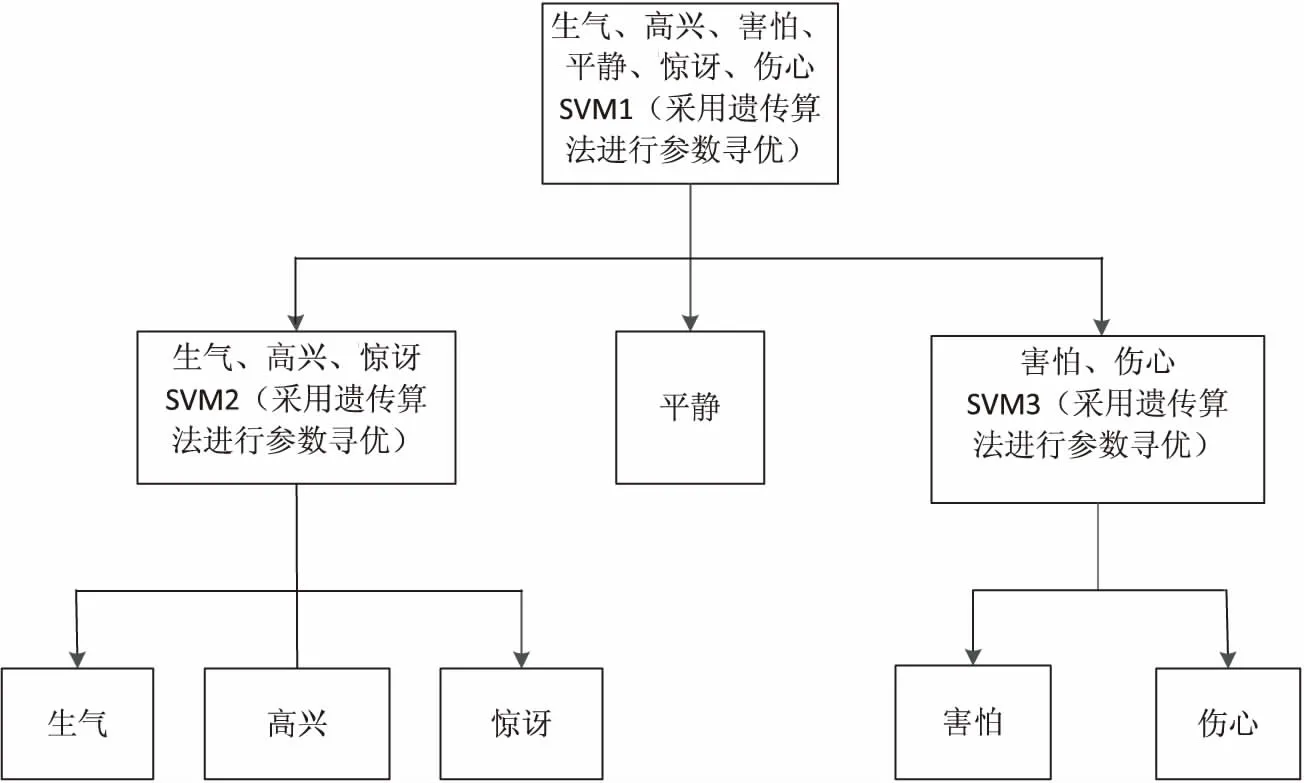
图1 基于参数寻优决策树SVM结构框图
3.2.2 参数优化选择实验
对于决策树SVM中的每个SVM,先采用遗传算法对其参数C和g进行优化,然后用最优参数进行SVM的训练与识别。遗传算法的参数设置如下:交叉率和变异率分别为0.6和0.035,种群数量为20,最大迭代次数为200,参数采用二进制进行编码。通过参数优化实验,得到决策树SVM中各个SVM的参数值,如表3所示。

表3 遗传算法寻优后的各个SVM的参数值
3.2.3 与其他方法的性能比较
为了验证决策树SVM分类模型的有效性,采用1 040维的联合特征作为特征参数,并用决策树SVM作为分类器进行实验,得到各类情感的识别率如表4所示。
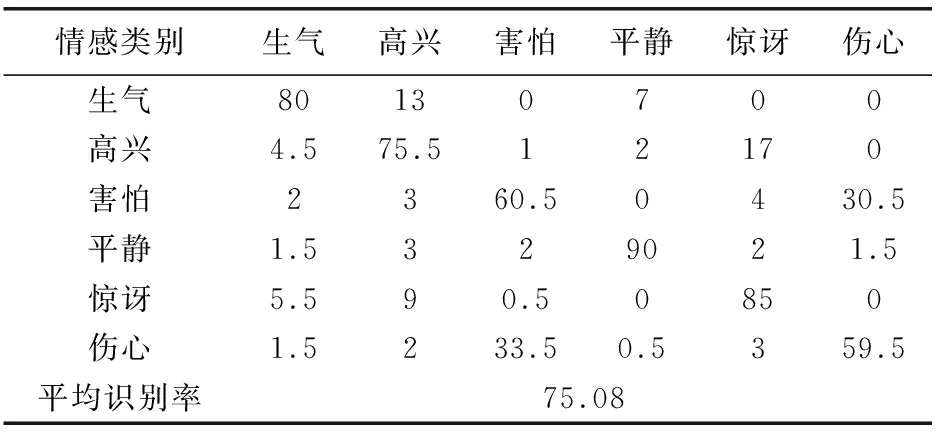
表4 基于联合特征和决策树SVM的 语音情感识别结果 %
将表4与表1的识别结果进行对比可知:平静情感的识别率略微降低,生气情感的识别率保持不变,其他四种情感的识别率都有所提高,同时平均识别率由74.5%提高到75.08%,从而证明了决策树SVM对语音情感识别的有效性。因为决策树SVM的识别方法根据混淆度,首先对情感进行粗分类,将容易混淆的情感归为一类,降低了情感之间的混淆度,从而提高了所有情感的平均识别率。
为了验证参数寻优对语音情感识别的有效性,采用提出的基于参数寻优决策树SVM的语音情感识别方法进行实验,得到的识别结果如表5所示。
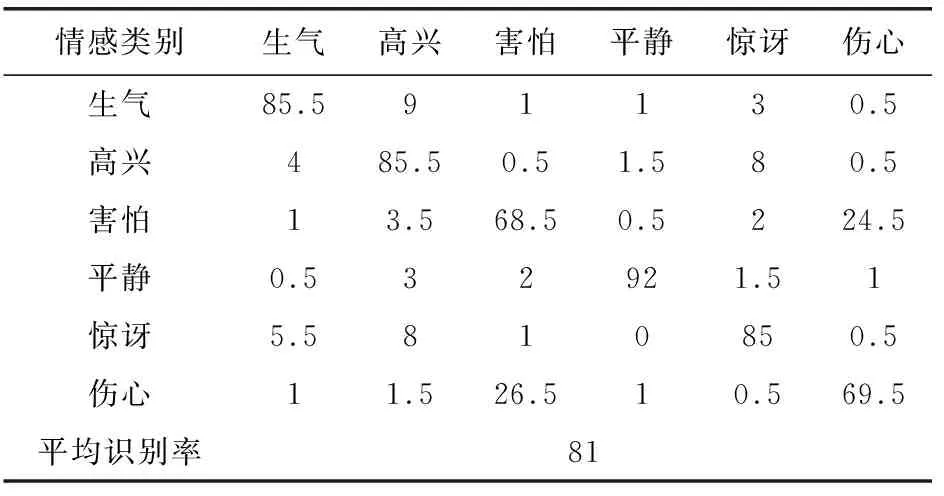
表5 基于参数寻优决策树SVM的 语音情感识别 %
通过表4和表5可知,文中方法使得除了惊讶之外的其他五种情感的识别率都得到了不同程度的提高,且平均识别率也由75.08%提高到81%。原因是在SVM的训练过程中,SVM的惩罚因子C和核函数参数g对识别效果影响较大,且不同的训练集需要不同的参数值;而通过遗传算法对SVM参数进行优化,得到了每个SVM的最优参数,从而使语音情感识别系统的平均识别率得到提高。
4 结束语
在多种情感识别的情况下,为了有效提高语音情感识别系统的识别率,提出了基于参数寻优决策树SVM的语音情感识别方法。在中文情感语音库的实验结果表明,该方法可以有效提高语音情感识别正确率。但依然存在不足之处,由于决策树SVM中的每个SVM都需要通过遗传算法进行寻优,会花费一定的时间。在下一步的研究工作中,将会寻找耗时更少的优化算法,以缩短整个识别系统的时间。
