基于SVM和VAR/LBP的车脸识别
2018-07-23朱善玮李玉惠
朱善玮,李玉惠
(昆明理工大学 信息工程与自动化学院,昆明 云南 650500)
智能交通系统(ITS)在减轻交通压力、提高交通管理效率、预防肇事逃逸等违法行为方面有很大的作用,其中的车辆识别是智能交通系统的一个重要方向,是国内外学者研究的热门话题,通过视频图像对车辆进行识别是被广泛研究的一种方法,近年来有许多相关的算法被提出。有关视频图像在车辆识别方面的应用,最开始是通过车牌的信息来确定车辆身份,但对于一些遮挡车牌、无车牌等“灰牌照”的车辆则不能有效识别。后来的研究者们又提出其它有关车辆模型识别的方法,例如,文献[1~3]利用SIFT特征并通过PCA、池化等方法对特征进行降维,然后对车辆进行识别;文献[4]则是通过提取图像中车辆轮廓的Harris角点对车辆进行识别,这些方法都具有很好的识别效果,但只能识别出车辆的轿车、客车、卡车等大类的车型划分,对于每类车型下的具体品牌则不能识别。
人脸的识别是通过面部及五官特征的不同分布来区分人的各异性,而对于车辆来说,不同品牌车辆的车标不同,相同品牌下不同车系的栅格、车前灯也不相同,这些车标、栅格、车灯构成的车脸特征为车辆的识别提供依据。文献[5~8]均提出了用车脸图像的信息对车辆进行识别的方法;文献[6]利用灰度共生矩阵提取车脸图像的纹理特征,然后用最小距离法对车辆进行识别;文献[7]提出利用车脸图像的HOG特征对15个品牌下的80种不同轿车车型进行识别,上述方法证明了基于车脸图像识别车辆模型的可行性,但均需要提高识别率。LBP算子作为一种有效的纹理特征,可以度量和描述图像中不同的纹理信息,并且它对单调的光照变化不敏感且计算效率高,被广泛应用于人脸识别[9-10]领域。原始的LBP算子不具有旋转不变性,并且直方图统计特征的维数相对较高,为了增加车脸图像对光照和旋转的鲁棒性,本文采用旋转不变模式和等价模式相结合的VAR/LBP[11]特征,并通过提取到的特征训练出SVM[12-13]分类模型,以此来提高车脸图像的识别率。
1 算法流程
基于SVM和VAR/LBP的车脸识别算法流程如图1所示。
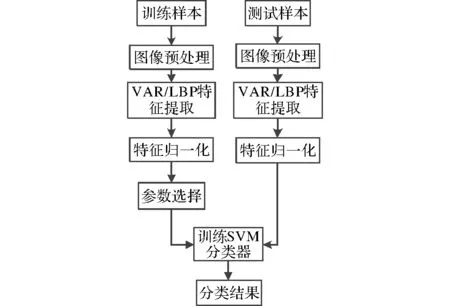
图1 车脸图像识别流程图
从算法流程图可知,车辆图像的识别过程主要分为两个部分,特征的提取和分类模型的训练。
2 LBP特征提取
原始的LBP算子的窗口大小定义为3×3的矩形窗口,特征编码方式是将灰度图像中矩形窗口的中心像素灰度值与其邻域像素灰度值比较,领域像素灰度值大于中心像素的灰度值则置1,否则为0,编码过程如图2所示。
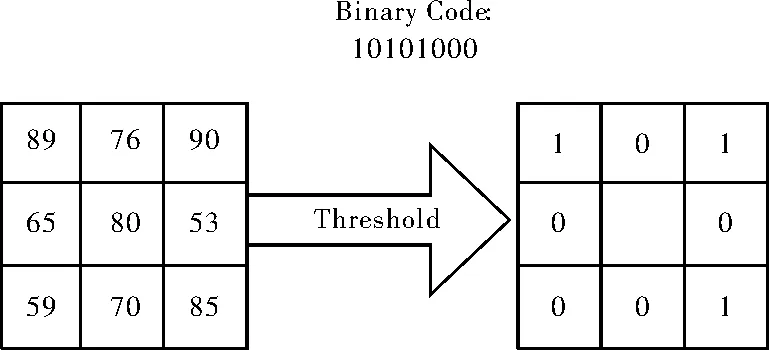
图2 原始LBP编码过程示意图
由此可以得到一个8位的二进制编码,将每一位编码乘以相对应的权重累加求和可以得到LBP值,即
(1)
其中,gc为中心像素的灰度值,gi为邻域像素的灰度值,s为权重系数,其取值规则为
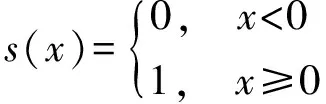
(2)
不同于原始的LBP编码过程,VAR/LBP则是在关于中心像素对称的半径为R的圆形分布上采样P个像素点,代替原始的矩形窗口,对没有处于图像像素位置的采样点通过线性插值的方法获得相应的灰度值,采样过程如图2所示。
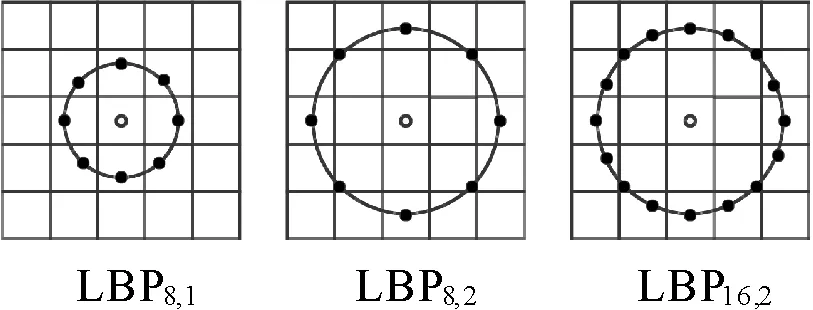
图3 VAR/LBP采样示意图
为了增加车脸图像对光照的鲁棒性,首先对车脸图像提取VAR特征,然后再对提取到的VAR特征图像进行采样,采样点的编码取值同原始的LBP;同时为了增加LBP特征的旋转不变性,对图像的采样点进行旋转,得到的最小的二进制编码值作为具有旋转不变性的LBP值,这不仅增加了LBP特征的旋转不变性同时也降低了特征编码的模式。为了进一步降低特征编码的模式,研究者发现绝大多数LBP特征模式最多只包含两次从1到0或从0到1的跳变,进而提出了LBP等价模式(Uniform Pattern),即当某个LBP所对应的循环二进制数从0到1或从1到0最多有两次跳变时,该类型保留;跳变次数超过2次时,均归为一类,最终的VAR/LBP特征编码的公式为
(3)
其中
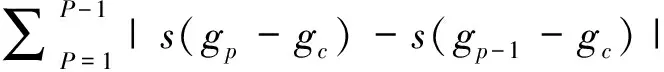
(4)
式中,gc为中心像素,gp为采样点,对一整幅图像提取VAR/LBP特征并统计直方图特征,所得到的VAR/LBP直方图统计特征不能表达出图像相对完整的信息,并且同一类图像之间也会产生很大误差,因此需要对图像进行分块处理,分块的车脸图像提取VAR/LBP特征的步骤如下:
步骤1对车脸图像进行均衡化和高斯平滑的预处理;
步骤2对车脸图像提取VAR特征,得到VAR特征图像;
步骤3把VAR特征图像划分为M×N个子图像块;
步骤4对每个子图像块分别提取像素点的LBP特征,分别对各个子图像块的LBP特征统计直方图;
施工单位还要对工程材料的使用进行控制,根据相关规范的要求,对物资进行定量供应,对材料的采购、领取、使用进行严格的控制及监督管理。施工单位要派专人进行材料的管理工作,并且材料负责人要具备较高的专业水平和严谨的工作态度,并且各个部门要对材料的使用进行相互监督,共同维护工程材料的使用标准,使工程材料的使用率最大化,实现材料成本的有效控制。
步骤5级联各个子图像块的统计直方图;
步骤6采用L2-norm方法对统计直方图特征向量进行归一化处理。
至此,得到车脸图像的VAR/LBP特征向量,用这些特征向量进行下一步的SVM模型训练。
3 SVM原理
SVM的思想是通过核函数将在低维空间线性不可分的数据样本映射到线性可分的高维空间,并找到线性可分的最大间距作为最优的分类超平面。即对于数据样本集(xi,yi),xi∈Rd,yi∈{-1,1},i=1,2,…,n,在满足条件
yi[(w,xi)+b]≥1-ξi
(5)
的情况下,求解最优化
(6)
式中,w为权重参数;ξi为松弛变量;C为正则化参数,用来调节分类的准确率以及防止分类模型过拟合[14]。为取得较好的分类效果,对特征向量由低维空间向高维空间投影时采用高斯核函数k(xi,x)=exp(-‖xi-x‖2)。
4 实验与分析
实验环境为Intel i5-4210M CPU,2.60 GHz,8 GB内存,Win8.1操作系统,编程语言为Python,使用Scikit-learn作为SVM的开发工具包。实验数据为高速公路卡口所拍摄车辆的车脸图像,共4 800幅(包括大众、别克、雪弗兰3个品牌下共8系不同的车脸图像,每个车系有600幅)。

图4 部分车脸样本图
4.1 图像分块选择
采用KNN算法比较VAR/LBP直方图特征在不同分块1×1、1×2、2×2、2×4、4×4、4×8以及8×8之间的车脸图像识别率,识别率结果如图5所示。
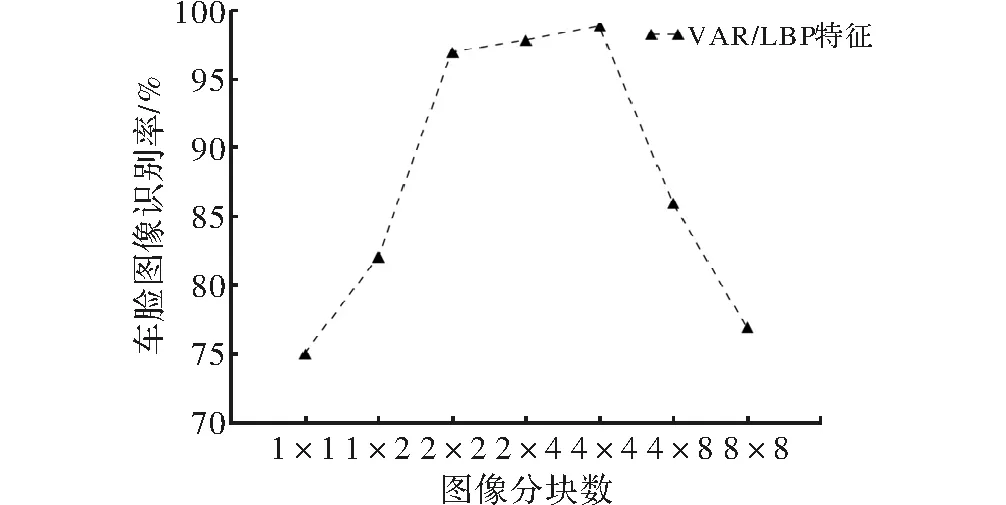
图5 不同分块下的识别率
从图中可以看出,当分块大小为4×4时车脸图像的识别率最高,因此,实验选取的图像分块数为4×4。
4.2 正则化参数选择
SVM模型训练的一个关键环节是选取正则化参数[15],合适的正则化参数能够降低模型的复杂度,避免模型发生过拟合,使训练模型具有较好的泛化能力。在同一车脸图像样本集下,本文通过交叉验证的方法,得到正则化参数C在不同取值下的损失值,如图6所示。
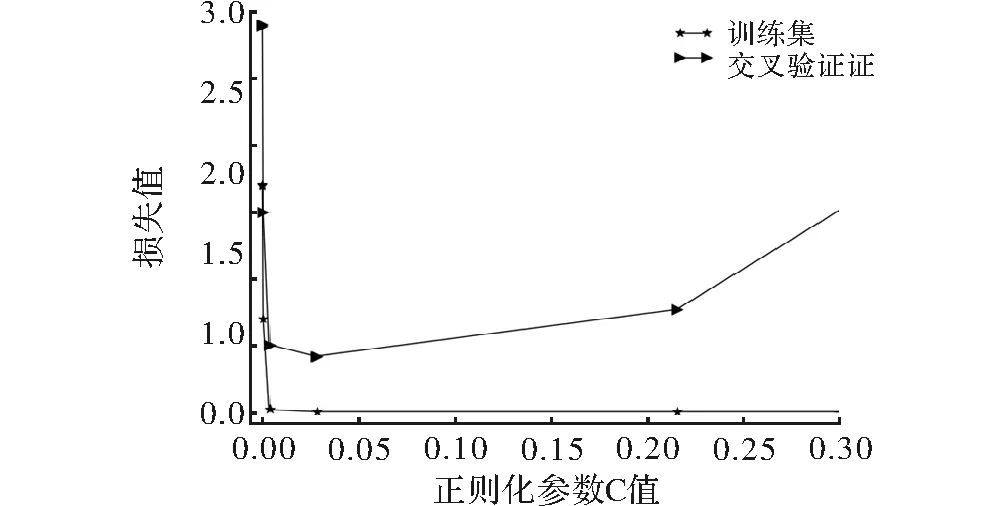
图6 不同参数C的损失值
由图可知,当正则化参数取0.1时训练集和交叉验证集的在SVM模型下的损失值最小,因此,实验选取的SVM模型的正则化参数为0.1。
4.3 实验结果对比
将实验所得的车脸图像分块数4×4和正则化参数C值0.1作为实验的基准,在相同的实验环境下,用VAR/LBP特征与SVM分类器对比HOG特征与集成分类器、纹理特征与最小距离分类器、SURF特征与最近邻匹配算法,得到4种不同算法的准确率及平均识别时间,不同算法的准确率实验结果如表1所示,不同算法的平均识别时间实验结果如表2所示。

表1 不同算法的准确率

表2 不同算法的平均识别时间
分析表1和表2可知,本文提出的VAR/LBP特征与SVM分类器方法相比较HOG特征与集成分类器、纹理特征与最小距离分类器、SURF特征与最近邻匹配3种算法,识别时间有所降低,识别准确率有所提升,准确率可达98.6%,说明VAR/LBP特征与SVM分类器方法在车脸识别方面应用的可行性。
5 结束语
本文针对传统LBP特征不具有旋转不变性且特征编码维数相对较高的问题,采用VAR/LBP特征不仅降低了特征的维数,而且增加了车脸图像对旋转和光照的鲁棒性。实验表明,对于不同的光照条件和一定的旋转角度下的车脸图像,训练出的SVM分类器对其都有着较好的分类效果,证明了VAR/LBP特征与SVM分类器方法对对光照变化、视角变化都具有较好的鲁棒性。本文所提出的方法对无牌照或者牌照遮挡的车辆的识别方面具有一定的实用价值。
