智能分类算法在游戏故障告警中的应用①
2018-07-18王月瑶胡琴敏陈乃华
王月瑶, 胡琴敏, 刘 伟, 陈乃华, 程 洁
1(华东师范大学 计算机科学与软件工程学院, 上海 200062)
2(腾讯公司 腾讯公司 IEG, 上海 200233)
3(上海智臻智能网络科技股份有限公司, 上海 201803)
随着游戏产业的蓬勃发展, 各类游戏层出不绝, 游戏用户的选择日渐增多, 稳定的运营与良好的服务渐渐成了游戏能否胜出的重要因素. 而随着人工智能风潮的掀起, 数据挖掘技术在游戏行业中的应用获得了广泛的关注[1]. 越来越多的企业已经意识到了这一点,开始重视起智能化运维服务[2], 从数据中获取有用的信息, 辅助用户与维护人员更好地解决问题.
在企业级游戏运维中, 客服人员每天会对游戏用户的反馈信息进行记录. 由于游戏发生故障时会产生大量的用户反馈, 因此工作人员可以从大量的用户反馈中提炼有效信息, 人工确认后形成游戏故障单, 交由对应的运维人员处理. 每个故障单记录了一个突发的游戏故障告警事件, 在传统的告警处理方法中, 一旦发现故障告警事件就会将所有告警信息发送给运维人员.然而, 由于游戏故障原因的多样性, 告警数据库信息量巨大[3], 故障发生的同一时间会产生各类告警. 这样的处理方式实际上忽略了用户的反馈, 损失了宝贵的信息资源, 同时存在很多告警误判误报的问题. 不相关的告警信息会干扰运维人员做原因诊断, 因而告警信息需要进行分析.
在对告警信息的分析中, 过去的研究者已经取得一定的成果. 但他们的工作主要聚焦于利用关联规则收敛电网的数据[4], 或根据网络异常流量曲线进行网络告警的分类[5]. 当然, 针对用户的反馈信息, 也有研究者根据体验价值、交易成本和服务质量三个维度建立用户服务模型[6], 或从中找出用户忠诚度与价格关系[7].然而, 这些方法都不关注文本信息的分类, 不适用于分析故障的文本信息, 而从用户反馈中提炼出的文本信息是十分重要的.
因此, 我们提出一种面向运维突发故障告警事件的智能分类算法. 首先, 我们分析故障事件文本的各项特征; 然后, 对文本信息利用半自动构建的语义映射工具进行概率计算; 最终将记录突发故障事件的文本自动分为三类: 网络级突发故障、程序主机类突发故障、平台支付类突发故障. 根据判断的类别向运维人员发布该类别相关的告警, 排除大类上的误判, 减少无关告警信息的轰炸.
我们的贡献在于将情感分类的算法创新性地利用在游戏运维的文本分类上, 并提出了一种语义映射工具供后续企业级的故障文本分类使用.
我们在企业近三年的故障单上做了实验, 实验表明: 本文提出的智能分类算法, 对比简单的基准方法决策树算法和朴素贝叶斯算法, 准确率分别有13%和9%的提升. 将此智能分类方法应用到企业级业务故障诊断中, 能实现更有针对性地发布告警, 减少告警的误判, 支撑运维人员更快速准确地去定位故障原因.
1 面向故障告警事件的智能分类模型
本文提出了一种面向故障告警事件的智能分类模型, 去分析描述突发告警事件的文本信息, 从中判断出故障事件的大类, 收敛无关告警, 减少告警的误判, 从而使发布告警更具有针对性. 整个模型的结构如图1所示, 分为以下三个模块, 分别是数据预处理模块, 构建映射工具模块和类情感分类模块. 第一层数据预处理模块主要分为数据清洗和jieba分词. 第二层构建语义映射工具模块指的是从已标注类别的故障告警事件文本中, 抽取三个类别对应的关键词, 建立每个类别下的运维词典, 经过人工确认后半自动构建语义映射工具. 第三层类情感分类模块主要是利用所构建的语义映射工具进行类别分析计算, 选择概率最高的类别作为最终的告警类别, 完成分类过程.

图1 告警智能分类模型
描述突发故障事件的文本经过这个智能分类模型,便可自动分类到以下三类故障中: 网络级突发故障、程序主机类突发故障、平台支付类突发故障. 分类后能收敛无关告警, 以实现告警信息的针对性发布.
1.1 故障告警事件文本的预处理
描述游戏故障告警事件的文本是从用户反馈中提取的信息, 其中包括一些游戏用户的个人信息和相关问题描述. 这些信息包含很多与故障告警无关的内容,因此需要对数据进行清洗, 并进行jieba分词[8,9], 从而最终形成描述该故障事件的词典集合.
假设sentence(j)为清洗后的故障事件j的所有描述语句, word(i)为 sentence(j)中的第 i个描述词, 数据预处理的方法如下:

公式(1)中的clean指的是数据清洗过程, jieba指的是数据分词过程, 通过公式(1), 将所有的故障事件文本数据进行转换, 获得一个分词后的词典集合, 进而提供给下一步构建语义映射工具使用.
1.2 构建语义映射工具
本文构建的语义映射工具是基于已标注类别的故障文本数据, 采用了 Term Frequency-Inverse Document Frequency (TF-IDF)算法[10]提取文本中相应类别的词典, 形成智能分类算法的映射工具. TF-IDF由Salton[10]在90年代提出, 并且在文本检索中不断发挥着重要作用, TF-IDF的主要思想是指一个词在特定文档中出现的频率越高(TF), 并且在文档中出现的范围越广(IDF), 这个词就越关键权重越高. 其经典计算公式如公式(2)所示:
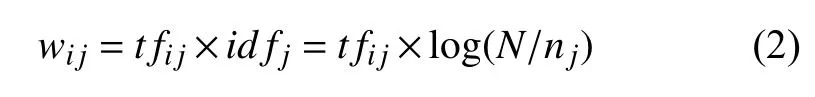
在公式 (2)中, tj是特征项, tfij指的是 tj在文档di中出现的次数; idfj表示逆文档频率, N 表示总文档数, nj表示tj的文档数目. 在本文中利用该算法思想来提取每个类别下每条故障描述中的关键词.
半自动构建语义映射工具的整个过程如图2所示,主要分为两步, 首先针对已存在并已让专家标注类别的故障事件文本, 利用TF-IDF算法提取每个故障事件描述文本中前三名的词, 构建相应类别的词典表述, 确保词典的专业性. 第二步是建立每个类别下的特有词典, 因为在故障表述中, 不同类别下的故障描述内容可能相同, 不同的词典可能包含相同词, 所以需要对比相同词语在不同词典下的TF-IDF值, 将这个词划分到其TF-IDF值较高的类别词典中. 同时采用人工确认的方法, 确保词典的独特性与正确性.
例如网络类的故障描述会涉及到“客户端”这个词,而程序主机类的故障也会频繁地提及“客户端”这个词.因此“客户端”这个词在两个类别下的TF-IDF值都很高, 被同时选入网络类的词典和程序主机类的词典, 这时通过比较得到“客户端”在网络类的TF-IDF总值, 和在程序主机类的TF-IDF总值, 由于“客户端”这个词在程序主机类的TF-IDF总值较高, 这个词被归为程序主机类词典, 依次类推, 再通过人工确认最终确定每个类别下的语义映射工具.

图2 半自动构建语义映射工具
通过以上过程, 我们半自动构建了针对网络类、程序主机类和平台充值类这三个类别的语义映射工具,提供给下一过程的分类使用. 该语义映射工具已可以直接使用, 但后续故障描述如果有更新, 可以通过如图所示的方法将语义映射工具进行扩展.
1.3 类情感分类
情感分类中一种常用算法[11]是利用构建好的情感词典进行情感分类, 分为正向负向和中性的情感. 借鉴这样的思路, 本文在最后一步利用已经构建好的语义映射工具进行类情感分类, 分类过程如公式(3):

应用以上公式进行类情感分类, Pk为每个类别下的概率, k对应各个类别的顺序(网络类顺序为1, 程序主机类顺序为2, 平台充值类顺序为3, Classk为半自动构建语义映射工具中词典的类别, 此处标记网络类词典为Class1, 程序主机类词典为Class2, 平台充值类词典为Class3, Label指最终分类形成的类别.
首先, 将每个故障事件中文本sentencej分词后的词典wordi通过语义映射工具映射, 计算该故障事件文本属于每个类别的概率. 每个类别下的概率Pk是通过映射到每个类别Classk的个数, 除以该故障事件sentencej的长度.
然后, 比较每个类别下的概率Pk大小, 如果是网络类 P1的概率最高, 则判断为网络类, Label为 1. 如果程序主机类概率P2最高, 则为程序主机类, Label为2.如果平台充值类的概率P3最高, 则为平台充值类,Label为3. 如果存在相同的概率, 这样的情况占极少数, 允许这一小部分的容错, 考虑到程序主机类的故障最多, 因而相同概率被标记程序主机类, Label为 2, 由此完成分类的这个过程.
2 智能分类算法的应用
在企业级的应用中, 面向游戏故障告警事件的智能分类算法可以直接应用在游戏运维平台上, 排除大类的故障, 发布与类别相关的告警, 收敛无关告警.
在应用场景中, 接入该智能分类算法作为一层滤网, 运维平台在建立新的故障单文本后, 可以直接利用已构建的语义映射工具, 自动判断平台上新形成的故障单文本类别, 根据类别自动去寻找类相关的告警, 收敛无关告警, 将相关告警推送给运维人员, 整体过程自动化方便快捷, 不需要人工干预, 实现案例见图3.

图3 智能分类算法的应用案例
在后续的使用中, 由于语义映射工具是可更改扩展的, 因而可以根据实际需求, 三个月或半年更新一次语义映射工具, 保证及时性和有效性.
3 实验设置与分析
我们在企业近三年的历史故障事件单上做实验,历史故障单由专家标记类别, 实验数据集为去除专家标记为自定义类别无法区分的单据, 共有2456条故障事件文本. 在该数据集上, 我们应用了本文提出的智能分类算法, 同时与决策树分类算法[12]与朴素贝叶斯分类算法[13]做对比. 实验结果采用了准确率、召回率、F1值这三个评价指标.
3.1 实验前期准备
整个数据集为企业近三年的历史故障事件单, 是企业的私有数据积累, 历史故障事件单由客服反馈收集, 数据集均以文本形式呈现, 包含故障单号、故障来源、故障标题、故障描述、以及发生时间这几个字段.在本文实验中, 我们抽取故障描述与内容作为用户反馈的文本信息进行分类.
实验前期准备为对故障文本数据的预处理, 以及专家需要对故障单人工标记. 数据预处理过程为对数据清洗后, 利用 Python的 jieba包[8]进行分词, 并在分词中加了自定义的词典, 修改了一些错误的分词. 实验的评价指标为准确率(Precision Rate)[14], 召回率(Recall Rate)[15], F1 值[15], 相关的公式如 (4)所示:

公式中, tp是将正类预测为正类数, fn是将正类预测为负类数, fp是将负类预测为正类数.
3.2 实验结果对比
本文在各项评价指标下, 测试了智能分类算法, 以及对比了简单的机器学习算法: 决策树算法与朴素贝叶斯算法.
在文本分类中, 通常采用的做法是对文本进行向量化后, 利用监督学习的算法来分类. 监督学习算法中常用的是决策树算法与朴素贝叶斯算法, 文献[16]介绍了利用决策树进行文本分类的多种方法, 文献[17]阐述了朴素贝叶斯在文本分类中的应用与改进. 这两种方法在文本分类中均被证明了有效性. 因此本文的对比实验首先采用TFIDF文档特征权志表示[18]对文本进行向量化, 然后采用决策树算法与朴素贝叶斯算法. 由于两者均是监督学习, 需要将数据集进行划分, 本文采用四六分. 随机抽取相同60%的数据作为训练集, 抽取相同40%的数据作为测试集.
由于智能分类算法为无监督算法, 因此需要在抽取的相同测试集上验证各项指标, 所有的实验在同一数据集上利用相同评价指标进行. 智能分类与决策树文本分类、朴素贝叶斯文本分类的实验结果如表1所示, 我们将在下一小节对实验结果做出进一步的分析.

表1 智能分类与决策树、朴素贝叶斯分类算法的比较
3.3 实验结果分析
如表1所示, 对比的三个算法在网络类、主机程序类、平台充值类、平均/总体(avg/total)均有对应评价指标的结果, 表格每一列分别对应类别、准确率、召回率、F1值以及所支持的实验数目(Support).Support是实验支持的数目, 相同的测试集共计983条故障文本: 包括网络类文本170条, 主机程序类文本为536条, 平台充值类文本277条. 各项评价指标的结果均在表1中可见.
在较为常用的评价指标avg/total准确率上, 本文提出的智能分类算法比决策树文本分类要高出13%,而比朴素贝叶斯高出9%.
整体的avg/total的实验结果对比如图4所示, 可以看出目前智能分类算法在故障事件文本中的应用是简单而有效的, 智能分类在准确率、召回率、以及F1值上, 均比决策树分类与朴素贝叶斯分类要高.

图4 实验结果对比图
同时, 本文提出的智能分类算法基于半自动构建的语义映射工具, 是无监督的学习算法. 我们可以将智能分类算法应用在全部的数据集上, 测试总体的实验效果. 此时数据集支持的数目为数据集全部数目2456条文本.为了进一步验证智能分类算法的有效性,在这里我们也加入了无监督学习算法的实验对比, 经常被采用的无监督学习算法主要是K-means分类[19]算法和DBSCAN分类算法[20], 由于K-means分类算法需要人工指定类别数N, 若直接将N设置为3加入了太多人工干扰的成分, 因此在这里无监督的对比实验选用DBSCAN分类算法, DBSCAN的参数eps选用比较常用的0.5.
在整个实验集上, 采用相同的评价指标, 智能分类得出的总体结果如表2所示.

表2 智能分类在整体数据集的结果
从上表可以看出, 智能分类算法在整个数据集上的avg/ total准确率为66%, 比无监督的分类算法DBSCAN算法准确率高12%, 进一步证明了智能分类算法的有效性, 并且, 分类错误的主要在平台充值类,由于故障描述来自用户反馈存在语义模糊的问题, 这类问题只有运维专家能够发现, 因而目前的准确率已基本可以在实际场景中应用, 去处理新生成的故障单,减少一部分告警误判.
4 结论与展望
针对故障告警文本, 本文提出一种智能分类算法,创新性地将类情感分类的思路应用在了处理故障文本上, 能够挖掘用户反馈的意图, 减少对告警的误判, 发布更具有针对性的告警, 辅助运维人员做故障诊断. 该算法在企业级的应用中能实现较好的效果, 并具有扩展性. 实验证明本文提出的智能分类算法, 与简单的监督学习算法以及无监督学习算法相比, 更适用于故障事件文本中.
但告警智能分类算法不涉及文本语义上的识别,另外由于游戏故障文本记录并不广泛, 因而采用实验的数据集还不够充分. 在后续工作中, 可以关注文本语义上的问题, 使文本分类结果更准确, 更靠近人类的思维. 同时寻找挖掘更多相关数据集, 进一步分析验证智能分类算法的效果.
