基于微信公众平台的招生咨询智能聊天机器人
2018-07-13刘蓉,陈波
刘 蓉,陈 波
(南京师范大学计算机科学与技术学院,江苏 南京 210023)
0 引言
咨询服务是高校招生工作中的重要环节之一,其一方面为考生提供各种报考所需要的信息,另一方面也是高校展示自身办学实力的重要平台。根据中国研究生招生信息网的统计,2018年全国硕士研究生招生考试中,报考人数再创新高,达到238万人[1]。越来越多的人选择读研深造,随之而来的招生宣传工作给各高校带来了难题:如何充分地开展招生宣传工作并且及时回复考生对报考、笔试、复试和录取工作等方面的问题。
传统的招生咨询方式大致可分为三种:一是考生在目标学校的官方网站上寻找学校所公布的一些文件和介绍;二是直接打电话咨询;第三种方式则是由考生通过在社交网站发帖或向亲朋好友询问等途径获得所需要的信息。前两种方式的信息可信度较高,但官方网站公布的文件可能并不能完全解决考生的困惑。而直接向招生办老师咨询时,大部分考生询问的问题大多相似,如招生专业、参考书籍或历年录取分数线等,考生与老师的一对一交流,在人力、物力、财力方面的耗费都很大[2];对于第三种方式,由于信息的获取是来自于网络上的陌生人,或考生的私人朋友,并非是高校的工作人员,信息来源不可信,信息价值不高。
随着计算机技术的快速发展,人们越来越习惯于从网上获取自己所需要的信息,深度学习和人工智能的发展更是推动了自然语言处理技术的进一步提高。招生咨询智能聊天机器人在此背景下应运而生。该机器人构建的模式是将考生经常询问或老师经常遇到的问题植入到语料库中,使得考生能够直接与机器人对话,并快速获取其想要咨询的问题答案。这种方法不但节省了考生查找报考信息的时间和精力,同时也将招生办老师从单调的答疑工作中解放。由于语料库中的招生信息都来自于高校招生办,信息的可信度不言而喻。
本文首先介绍聊天机器人的相关概念和关键技术,然后分析招生咨询机器人的发展现状与不足,并提出一种基于微信公众平台的招生咨询智能聊天机器人的方案设计,最后详细介绍各个功能模块的技术实现。
1 相关工作及本文思路
1.1 聊天机器人研究现状
聊天机器人是一种使用自然语言与人类进行对话的软件机器人,又被称为对话系统[3]。当前学术界对于聊天机器人的研究主要产生了两种模型:基于检索的模型(检索模型)和基于生成的模型(生成模型)。检索模型主要依赖于知识库、检索技术和排序特征的提取,而生成模型则依赖大量的训练数据,能够表示出自然语言的语义特征[4]。由IBM开发的DeepQA系统采用了海量并行和基于证据的概率模型架构,整个系统体现了高级自然语言处理、信息检索、知识表示、自动推理和机器学习等开放式问答技术[5]。
聊天机器人作为一种对话问答系统,集成了多年来自然语言处理(Natural Language Processing)
研究与应用的各种成果,包括词法分析、词性标注、浅层或深层句法分析、命名实体识别、指代消解、词义消解、文本检索、信息抽取(包括关系抽取)、机器学习、本体知识获取、知识挖掘、知识表示、逻辑推理等。由于中文不似英文有空格之类的词语分隔符,句子是由连续的词语组成,必须先进行中文分词才能进一步处理。此外,中文中没有疑问词的区分,不能像英文那样根据疑问词确定问题类型。这些都导致了自然语言处理在国内的研究和应用落后于国外,也使得聊天机器人的研究进展较慢。
1.2 招生咨询机器人研究现状
随着自然语言处理技术的深入发展与研究,人们逐渐将自动问答机器人技术应用于多个行业,招生问答领域的自动问答机器人应运而生。目前国内的招生问答机器人研究较少,并且多以ALICE作为基本模型。ALICE(Artificial Linguistic Internet Computer Entity)是由美国宾夕法尼亚州Lehigh大学的Richard S.Wallace博士开发的一个基于经验的人工智能聊天机器人,其最初版本支持英语、德语、法语等语言,却不支持中文。
冯德虎等人[6]在全面分析基于GPL的开源产品ALICE源码的基础上,引入并修改现有中文分词技术,使其能够对专业领域内的中文词语进行准确分词。最终采用Java EE的SSH2框架开发了一套基于B/S的招生咨询机器人WEB系统,但这一系统中机器人的知识库是由AIML(Artificial Intelligence Markup Language)语言构建的,在用户的易用性与 AIML标签的复杂性之间存在一定的矛盾;其次,智能聊天机器人的管理用户很难理解系统的运行原理,对语义不同的问句设置了相同的关键词,导致机器人不能做出准确的回答;第三,这一系统尚未涉及语义分析、同义句归并等,对中文自然语言的处理不够成熟。周建设等人[7]对开源机器人ALICE进行了改进,实现自动回答考生的问题,但其用AIML语言构建知识库给普通管理用户带来一定难度。
近年来,国内智能聊天机器人技术也取得了一定进展,基于Deep QA技术的图灵机器人号称是中文语境下最智能的大脑,在中文自然语言处理方面具有强大的优势。此外,图灵机器人的知识库可以由用户手动输入,或者通过 Excel文件批量导入,与ALICE相比具有易操作、零门槛的特点。吴志霞等人[8]利用图灵机器人平台,开发了基于 Android的招生咨询平台。然而,这种咨询系统尚未接入语音系统,并且需要用户下载额外的APP,从用户便利性角度来看不够友好,有待进一步改进。
1.3 本文思路
本文将图灵机器人接入微信公众平台,使用微信公众平台客户端作为用户界面,实现消息的接收与推送;公众号服务器由第三方服务器组成,当接收到用户发送过来的消息后,对用户消息进行解析并根据消息内容将消息传送到图灵机器人平台或目标网站处理后反馈给用户;图灵机器人平台将公众号服务器推送过来的信息进行解析,并查询知识库,将匹配的内容反馈给用户。其中,知识库中数据的来源有二:一是通过爬虫的方式从高校的招生网站抓取相关信息;二是由负责招生的老师手动添加信息。知识库中的数据都可以手动修改。具体技术流程如图1所示。
当前,微信用户已达 10亿[9]。微信公众平台(https://mp.weixin.qq.com/),简称公众号,通过公众号,服务提供者与用户可以实现与特定群体的文字、图片、语音、视频的全方位沟通、互动。相较于Android和iOS APP应用,微信公众平台可以跨越手机型号和操作系统的限制,实现各种服务和功能的展现,从而推动信息的传播和服务的应用[10]。除了简单的编辑模式外,目前微信公众平台还支持开发者模式:开发者可以调用各种网络 API,对接数据库,开发出更多编辑模式不包含的高级功能[11]。
基于微信订阅号的功能,使用开发者模式创建聊天机器人,不但能够服务于更多的用户,同时在与众多用户对话的过程中,机器人的学习能力不断增强,自身积累的语言素材不断扩大,在与用户进行下一次对话时,其语言表达能力将得到进一步的提升,回答的内容更加智能。
2 开发环境搭建
2.1 微信公众平台的开发者模式通讯机制
微信公众平台消息接口为开发者提供了与用户进行消息交互的能力。当用户向公众号发送消息时,实际上这条消息首先发送到微信后台,由微信后台向我们的公众号服务器发起另一个请求。当我们在公众号服务器上处理后,再返回这个请求的结果,最后由微信后台将请求结果转发到微信客户端,供用户查看。用户、微信后台和我们所需要开发的公众号后台的服务器三者之间的交互关系如图1所示。
图 1中的微信后台即为腾讯公司的微信服务器,它负责接收用户从微信客户端向公众账号发送的消息,并按照相应的对接规范对用户的消息进行解析和转发;公众号服务器接收到微信后台转发过来的消息后,解析消息格式,得到用户的消息内容。根据具体的消息内容,在公众号服务器端调用聊天机器人模块,对用户的消息做出应答,然后封装消息处理结果,返回给微信后台;微信后台将公众号服务器发来的消息转发给用户的微信手机客户端,用户就可以在客户端看到机器人的消息回复内容。
2.2 开启开发者模式
为了在微信公众平台实现聊天机器人功能,首先要注册一个微信公众号。微信提供了服务号、订阅号、企业号和测试号给用户使用,本文在此选择注册个人订阅号。账号注册成功后,在公众平台的开发者中心开启开发者模式。当开启开发者模式后,编辑模式的功能将失效,所有的功能必须由开发者在公众号服务器实现[12]。服务器配置过程中,需要填写URL(服务器地址)和Token(令牌),验证开发者是否拥有自己的服务器资源。此处填写的URL即为代码部署在公众号服务器上的路径。Token是微信公众平台的身份标识[13-14],开发者可以任意填写,以作为身份签名,但必须与代码中的Token值一致。当用户向公众账号发送信息后,微信后台将向公众号服务器发送GET请求,该请求中包含四个参数(signature、timestamp、nonce 和 echostr),开发者通过对signature的校验,判断此消息的真实性。若确认 GET请求来自微信服务器,将返回 echostr参数内容,表明接入生效,可进行下一步处理;否则接入失败[15]。
2.3 事件响应和消息处理
微信公众平台在处理消息时,需要先判断事件类型,如用户关注或取消订阅号、发送消息、扫描二维码等,这些都会由微信服务器发送到所填写的URL,因此在公众号服务器模块中必须对不同类型的事件做出不同的响应。当用户向微信公众订阅号发送消息时,微信服务器会将消息转换为特定的XML结构,并将XML结构的信息POST到公众号服务器上,然后在公众号服务器上处理信息,再返回给微信后台服务器。用户发送的消息类型主要包括文本消息、图片消息、语音消息、链接消息和视频消息等。对于每一个消息,公众号服务器在处理之前,必须先判断消息类别,提取出消息内容后交给聊天机器人模块进行处理,在发送响应包时返回特定的XML结构。

图1 技术流程图Fig.1 Technical process
2.4 公众号服务器接入
微信公众平台上服务器配置中需要填写代码部署位置的URL,以实现公众号服务器的接入。本文使用新浪云的云应用(SAE)作为微信公众号服务器。SAE支持通过Git、SVN和本地上传三种方式部署代码,并提供日志中心方便查看代码的运行情况,从而在代码出错时及时找到错误原因。
2.5 系统开发环境
(1)硬件环境
服务器端:Inter® Core™ i5 CPU 3.20GHz,Windows 10专业版64位,4G内存,500GB硬盘
客户端:装有微信6.6以上版本的智能手机
(2)软件环境
服务器端:装有IIS的Windows操作系统;新浪云SAE;python2.7;pycharm3.6
客户端:装有微信6.6以上版本
(3)开发语言
python 2.7
3 服务系统功能设计与实现
3.1 系统功能设计
基于微信公众平台开发的聊天机器人主要由招生咨询、生活服务和其他服务三个功能模块组成,具体功能如下。
(1)招生咨询:本文开发的聊天机器人以南京师范大学研究生院招生官网为数据来源,能够回答考生最关心的一些招生问题,节省有意报考的考生自己查找信息的时间和精力。
(2)生活服务:目前支持天气查询、快递查询和火车票查询等功能,为用户提供当天的天气预报和快递的物流信息,在火车票查询功能中支持直接跳转至去哪儿网订票。
(3)其他服务:聊天机器人还提供一些其他功能,如为用户提供当天的头条新闻、识别图片中人物的性别和年龄、与用户进行日常聊天等,是用户休闲娱乐的助手。
3.2 功能实现
3.2.1服务器配置和Token认证
微信公众平台的个人订阅号申请成功后,首先在新浪云SAE平台创建一个空应用,开发语言选择Python2.7。这里选择使用 web.py来进行服务器搭建,如果本地没有web.py库的话,可以通过pip命令进行安装。之后需要新建一个项目,并编辑如下三个文件。
(1)config.yaml
name: chatter
version: 1
libraries:
- name: webpy
version: "0.36"
- name: lxml
version: "2.3.4"
...
config.yaml文件中填写项目开发中用到库名称和版本号,必须与实际开发时使用以及SAE平台支持的版本保持一致。
(2)index.wsgi
# coding: UTF-8
import os
import sae
import web
from wechatInterface import WechatInterface
urls = (
'/wechat','WechatInterface'
)
app_root = os.path.dirname(__file__)
templates_root = os.path.join(app_root, 'templates')
render = web.template.render(templates_root)
app = web.application(urls, globals()).wsgifunc()
application = sae.create_wsgi_app(app)
index.wsgi是web.py的基础配置文件之一,将URL结构和模板告知web.py,方便服务器处理用户的请求。
(3)wechatInterface.py
# -*- coding: utf-8 -*-
import hashlib
import web
import lxml
import time
import os
class WechatInterface:
def __init__(self):
self.app_root = os.path.dirname(__file__)
self.templates_root = os.path.join(self.
app_root, 'templates')
self.render =
web.template.render(self.templates_root)
def GET(self):
data = web.input()
signature=data.signature
timestamp=data.timestamp
nonce=data.nonce
echostr = data.echostr
token="lenona" #这里改写微信公众
平台里输入的token
list=[token,timestamp,nonce]
list.sort()
sha1=hashlib.sha1()
map(sha1.update,list)
hashcode=sha1.hexdigest()
if hashcode == signature:
return echostr
wechatInterface.py文件用于实现微信公众平台功能,需要将代码中的 token修改为在微信公众平台的开发者配置中填写的 Token,从而实现微信平台的认证。在平台认证的过程中,只需要使用GET方法,但在之后发送消息时则需要使用POST方法。
将上述三个文件部署到SAE平台后,将生成本项目的URL。打开微信公众平台的开发者配置页面,填写刚才获得的 URL,EncodingAESKey选择随机生成,然后提交认证即可。
3.2.2消息回复机制
根据微信公众号开发文档可知,用户与公众号之间的消息交互类型分为文本、图片、语音、视频、小视频、地理位置和链接等,本文中主要用到文本、图片和语音三种消息类型。当用户向公众号发送消息时,其消息内容将以 XML的形式传送至搭建好的服务器中。在处理用户消息时,需要先解析XML信息,获取出需要的信息内容,然后再对用户的信息进行回复。不同消息类型的 XML结构中都包括ToUserName、FromUserName、CreateTime、MsgType和MsgId五个字段,但文本XML中还包括Content字段,图片XML中含有PicUrl和MediaId字段,语音XML中则还有Format和Recognition字段。因此在处理用户消息时,必须先获取消息类型(MsgType),然后再按照相应的规范得到消息内容。消息处理的部分代码如下:
defPOST(self):
msgType=xml.find(“MsgType”).text
ifmsgType==’text’:
content=xml.find(“Content”).text
elifmsgType==’image’:
img=xml.find(“PicUrl”).text
elifmsgType==’voice’:
voice= xml.find(“Recognition”).text
else:
pass除了文本类 XML可以直接得到消息内容外,图片类XML中PicUrl字段提供的是图片的地址,而对于语音类消息,微信会在XML数据包中增加一个Recongnition字段,当开启语音识别功能后,可以直接从Recongnition中获取用户消息的文本内容。
获取到用户发送的消息后,需要考虑如何给用户发消息,此时需要定义一个消息模板,同样以XML结构回复消息,并在相应的功能最后设置返回值即可。
消息模板定义如下:
$def with (toUser, fromUser, createTime, content):
4 聊天机器人设计与实现
4.1 招生咨询模块
4.1.1创建招生问答语料库
由于招生报考的最可靠资料来源于高校的招生网站,本文以南京师范大学研究生招生网站为例,将该网站上招生问答模块的内容爬取下来,作为招生问答语料库的来源之一。此外,关于学校和专业的介绍,以及历年录取情况等,也是考生密切关注的信息,因此将这些信息囊括在问答语料库中。
招生问答语料库的主要数据来源于高校招生网站的咨询和问答模块,在对网站信息进行爬取之前,需要先分析网页请求,确定相应的网页请求参数[16]。利用 Fiddler抓包后发现,目标请求网页的 url为http://yz.njnu.edu.cn/homepage_display.jsp?wid=ABF 05B06504A2565E04077CAA4682CCE&wid2=E58A3 159A2941CC4E04077CAA46871F4。同时,由于网站设置了反爬虫机制,会检查网页请求的来源,因此在模拟请求时必须设置 user-agent、refer和 host等参数,当返回的状态码为200时,表明网页请求成功,可进行下一步解析操作。
BeautifulSoup是Python的一个库,其最主要的功能是从网页爬取需要的数据。BeautifulSoup能够将html形式的网页源码解析为对象进行处理,全部页面转变为字典或者数组。相对于正则表达式的方式,这种解析方式可以大大简化处理过程。在网页请求成功后,利用BeautifulSoup解析网页源码,解析后的网页源码如图2所示。通过观察发现,所有的问答内容都是用标签包含。在进行问答内容提取的时候,只需要对
标签内的数据进行处理。此处可以使用正则表达式进行匹配,也可以直接调用BeautifulSoup封装的函数。图3是爬取到的部分招生咨询的问答内容,分为问题和相应的答案。
通过查询图灵机器人的开发者文档可知,开发者在创建自己的语料库时,可以使用手动逐条添加或者批量导入的方式添加语料,并支持开发者手动修改问题和答案。此外,对于同一个答案,开发者可以添加相似问法,从而使图灵机器人能够更加准确地理解用户询问意图,给出满意的答案。为了进一步提高图灵机器人的回答准确率,开发者可以修改问答匹配度。由于需要添加的语料数据较多,此处选择使用批量导入的方式创建语料库。图灵机器人官网提供了语料库模板,需要导入的数据都必须先按照模板将数据处理成所需要的形式。所有数据保存在excel文件中,每一行的第一列为问题,文本长度不超过64个字符;第二列为答案,文本长度不超过600个字符。同时,为了提高机器人回答的准确率,可以从第三列起添加相似问法。处理后的数据如图4所示。

图2 使用BeautifulSoup解析网页Fig.2 Use BeautifulSoup to parse web pages

图3 爬取到的部分招生问答内容Fig.3 Part of the crawled recruiting questions and answers

图4 处理后的问答数据Fig.4 Question and answer data after dealing
我们认为,问答语料库中除了包含上述招生网站公布的信息之外,还应该咨询招生办的老师,请他们根据多年的工作经验继续添加考生经常咨询的问题,从而进一步完善招生问答语料库,使考生能够得到更加全面的招考信息。这种方式得到的数据量较小,可以直接采用手动逐条添加问题和答案的方式,在此不再赘述。
4.1.2招生问答功能实现
为了调用图灵机器人 API,必须先在图灵机器人官网注册一个账号。注册并成功登录后,开发者可以对所创建的机器人设置相关属性,如姓名、性别、年龄等,同时开发者将得到一个 API Key。图灵机器人提供多种接入方式,如微信公众平台接入、API接入、SDK接入等。由于微信公众平台接入是直接接入图灵机器人提供的链接,而不是之前搭建的服务器,对公众号来说将有许多定制功能方面的限制,因此本文选择API接入。
根据图灵机器人提供的接入API和API Key,使用如下方式接入图灵机器人。
url = 'http://www.tuling123.com/openapi/api'
da = {"key": "9868d1a5d1e342a394921687-0fc894e1", "info": content, "userid": userid}
data = json.dumps(da)
r = s.post(url, data=data)
同时需要修改wechatInterface.py文件,将得到的用户消息内容传送给图灵机器人。
content = xml.find("Content").text
try:
msg = talk_tuling.talk(content, userid)
return self.render.reply_text(fromUser,
toUser, int(time.time()), msg)
except:
eturn self.render.reply_text(fromUser,
toUser, int(time.time()), '换个话题吧')
根据用户询问的问题,图灵机器人将在语料库中进行匹配,当匹配达到所设定的问答匹配度时,它将把答案返回给用户,完成一次问答过程。若语料库中无法找到满足问答匹配度的答案,开发者可以自己设定图灵机器人的默认回答。
4.2 生活服务
(1)天气查询
图灵机器人API提供天气查询功能,当用户发送天气查询指令时,图灵机器人将自动返回相应的天气情况。但是,用户发送天气指令时,必须包含要查询的地点和“天气”关键词,否则机器人可能无法正确理解用户的意图。
(2)快递查询
本系统从考生查收录取快递函件等日常需要出发,提供了快递查询功能。用户在向聊天机器人发送消息时,需要包含“快递”关键字和相应的快递编号。服务器接收到这一消息后,先根据关键字“快递”判断出这是一条查询快递的指令,然后将得到的快递编号作为请求参数,调用快递100的查快递接口,向“快递100”网站发送查询请求。当服务器获取到该快递的物流信息后,再通过微信服务器,将具体的物流信息传递到用户的微信客户端,供用户查看。
(3)火车票查询
考虑到考生的出行,本系统提供火车票查询功能。在聊天界面中,用户只需要发送带有“火车票”关键字的消息即可使用车票查询功能。当聊天机器人接收到这一消息后,将主动询问用户希望的出行日期。与日常对话一样,用户回复日期后,机器人将自动调用去哪儿网的网站接口,为用户查询相应日期的火车班次。需要注意的是,每一次消息的发送都视为一次单独的机器人调用,很可能出现机器人消息回复的上下文不匹配。比如,当用户回复目的地为“南京”时,机器人回复的是对南京的介绍,而并非是用户所需要的车次列表。因此,在使用图灵机器人API时,还要传入用户的userid,从而保持上下文对话的语境一致。关于userid的获取,通过查询微信公众平台开发文档,发现之前使用的 FromUserName字段即可作为userid。由于userid只支持0-9和字母,而 FromUserName中带有下划线,所以在使用之前必须做一些简单的处理。例如取 FromUserName的前16位作为userid。具体操作如下:
fromUser=xml.find(“FromUserName”).text userid=fromUser[0:15]
4.3 其他服务
(1)新闻服务
图灵机器人在接收到用户发送的信息后,会根据消息中的关键字,自动将消息分为不同类别,如文本类、链接类、新闻类等。因此,当用户发送带有“新闻”关键字的时候,图灵机器人将此请求判定为新闻类消息,除了返回当前的头条新闻标题外,还会把相应新闻的链接一起发送给用户,供用户详细阅读相关内容。
(2)识图功能
本文开发的智能聊天机器人还增加了识图功能。当用户向公众号发送带有人脸的图片时,聊天机器人能够使用图像处理算法,识别出图片中人物的年龄和性别。微软小冰是微软人工智能三条全球产品线之一,它是基于微软于2014年提出建立的情感计算框架,通过算法、云计算和大数据的综合运用,采用代际升级的方式,逐步形成向 EQ方向发展的完整人工智能体系。虽然目前并没有公布可以直接调用的 API,但可以通过抓包分析的方式,向目的网址发送请求。
打开Fiddler并登录http://how-old.net/,任意上传一张图片后,浏览器先发送一个GET请求,将本地上传的图片上传至微软服务器;之后浏览器继续发送 POST请求,目的 url为 https://how-old.net/Home/Analyze?isTest=False&source=&version=howold.net,同时将 GET请求中得到的图片地址作为POST请求的参数一起发送。请求成功后,服务器返回一系列 JSON格式的数据,其中包括图片中人物的gender(性别)和age(年龄)。考虑到当用户向公众号发送图片时,已经得到了图片文件的地址,因此在编写代码时可以直接用 GET请求获取图片内容,再将图片内容作为参数向目的网址发送POST请求。微软服务器会校验Cookie,所以先用requests包构建一个 session,requests.session会自动处理Cookie,保持会话,然后再发送各种请求。
(3)日常聊天
作为中文语境下智能度最高的机器人大脑,图灵机器人除了能提供各种功能性服务外,它还能与人类交谈,完成日常对话。与传统的机器人只能回答生硬单调的文字不同,图灵机器人的回答更加幽默和口语化,且能与时代潮流趋势保持一致。图灵机器人在创建时已经设定了姓名、年龄、性别等信息,甚至连星座、父母亲姓名都有设置,这就意味着它具有一些人类才有的身份特征,明显区别于传统的聊天机器人。而这些设定的身份属性,在聊天过程中能够得以体现。例如用户可以询问它的姓名等,聊天对话的友好性进一步提升,更加符合真实人类对话的情景。拥有一套完整自学习体系的图灵机器人,能够在与用户的交流中不断学习新的知识,回答的内容更加智能。
5 聊天机器人使用实例
当用户关注公众号之后,进入公众号,即可使用聊天机器人提供的各种服务。图5是招生咨询界面,用户直接在后台输入自己想要咨询的问题,机器人会根据语料库中的内容回答用户。生活服务方面,用户可以直接发送带有关键字的指令,机器人收到消息后将根据关键字判断该消息的类型,并进行回复。如图6所示,用户可以向聊天机器人询问天气情况以及查询快递的物流状态。
此外,该聊天机器人还提供火车票查询、热点新闻查询功能,只要用户发送消息时包含“火车票”和出发与目的地点、“新闻”等关键字即可,操作界面分别如图7、图8所示。图8中还演示了识图功能。当用户向公众号发送图片时,聊天机器人能够识别出图中人物的性别和年龄。

图5 招生咨询功能Fig.5 Recruiting and consulting function

图6 天气查询和快递查询功能Fig.6 Weather and express consulting function
如图9所示,本文开发的聊天机器人可以与用户进行日常聊天,并且回复内容贴近正常人类的语气,具有一定的智能性。
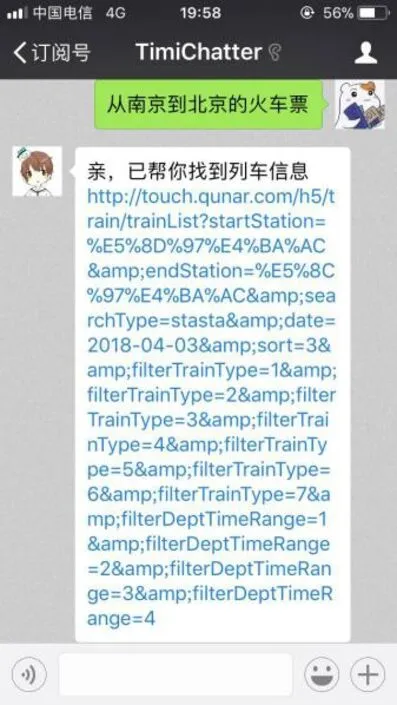
图7 火车票查询功能Fig.7 Train ticket consulting function

图8 识图功能Fig.8 Picture recognition function
6 结论
本文设计实现的基于微信公众平台的聊天机器人能够为用户在招生咨询和日常生活中带来极大的方便。首先基于微信平台,用户不需要再去下载额外的APP占用手机资源;其次,通过微信聊天咨询,考生能够及时从公众号中得到准确的招考信息,既节约了考生的时间和精力,也提高了高校的宣传效率和结果;此外,用户能够从公众号中直接得到天气、新闻、快递和火车票等信息,给日常生活带来极大的便利;最后,聊天机器人能够与用户进行对话,是用户休闲娱乐的好帮手。
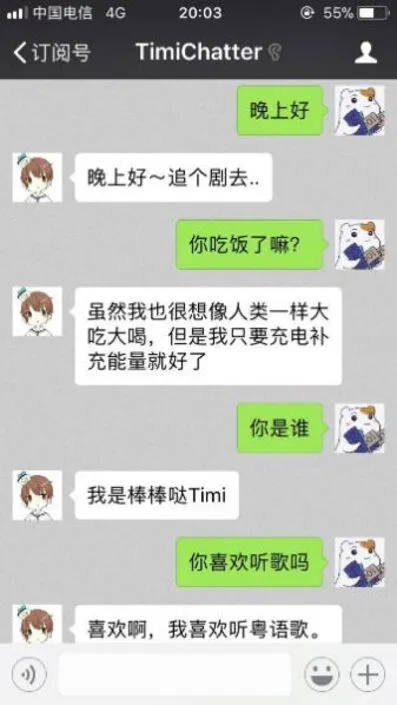
图9 日常聊天功能Fig.9 Daily chatting function
