基于深度卷积神经网络的多任务细粒度车型识别
2018-07-12王海瑶沈振辉
王海瑶,唐 娟,沈振辉
基于深度卷积神经网络的多任务细粒度车型识别
王海瑶1,唐 娟2,沈振辉1
(1. 福建江夏学院工程学院,福建 福州 350108;2. 安徽工程大学管理工程学院,安徽 芜湖 241000;)
车型识别,尤其是细粒度车型识别是现代智能交通系统的重要组成部分。针对传统车型识别方法难以进行有效的细粒度车型识别的问题,以AlexNet、GoogleNet及ResNet等3种经典深度卷积神经网络架构作为基础网络,引入了车辆的类型分类作为辅助任务,从而与细粒度车型识别任务一起构成了一个多任务联合学习的模型。通过在一个包含281个车型类别的公开数据集上对模型进行训练及测试,在无需任何车辆的部件位置标注及额外的3D信息的情况下,验证了该模型在在细粒度车型识别任务上表现出的优异性能,同时多任务学习策略的引入可使得模型性能相比任一单任务学习时的性能均有所提高,最终实现了一个简洁高效的细粒度车型识别模型,基本满足实际应用需求。
智能交通;细粒度车型识别;深度学习;神经网络
随着社会生活的不断发展,人均可支配收入稳步提升,人均拥有汽车数逐渐增多,交通承载状况和日益增长的汽车数量之间的冲突不断提升,并因此产生了交通拥挤、道路环境恶化等一系列社会问题,对于城市的正常运行造成了不小的压力。车型识别作为现代智能交通系统的重要组成部分,对于高效监控交通情况,及时处理突发交通意外,以及判定相关交通事故责任都有着不可估量的作用。
传统的车型识别方法主要关注的是车辆制造商识别(vehicle make recognition),或是识别广义上的车型(轿车、货车、越野车等)[1-2]。其主要流程一般包括:①采用人工设计的特征提取方法(如SIFT[3]、LBP[4]、HOG[5]等)将输入的车辆图片转换为一组特征向量;②再基于该特征向量和机器学习中的分类算法(如SVM、Adaboost、随机森林等)来训练模型。然而,在细粒度车型识别问题上,不同车型类别间的差别往往很细微,而人工设计的特征提取方法在应对此问题时对强辨识信息的提取能力很有限,为了弥补手工特征在提取强辨识信息能力方面的不足,也有一系列文献[6-7]尝试引入车辆的3D信息来建立模型,从而改善识别的性能。但这些方法加大了整体模型的复杂度,计算耗时也更大,不利于实际的应用,且仍然受到了人工特征在对强辨识信息提取的能力弱、对特定问题适应性差等方面的限制。
近年来,得益于大数据、硬件计算能力的提升以及算法的改进,深度学习在语音处理和计算机视觉领域等诸多领域都取得了巨大的成功,显著提升了语音识别、图像分类、物体检测、视频分析、人脸识别、行人检测、语义分割、机器翻译等众多智能处理任务的性能[8]。如在图像分类领域的ILSVRC挑战赛上,基于深度学习的方法AlexNet[9]、GoogleNet[10]及ResNet[11]等均在性能上相比传统方法取得了很大的突破。相较于传统方法,深度学习最大的优势就在于其可以通过层级连接的方式进行对原始输入信号到期望输出信息的复杂非线性建模,从而获取数据更抽象、更本质的表征,实现了一种“端到端(end-to-end)”的学习,完全是数据驱动,而不依赖于专家知识来针对特定领域设计人工特征,普适性更强。
在细粒度图像识别领域,也有许多基于深度学习的方法开始被广泛采用,并在性能上远远超过了传统基于人工特征的方法[12-14]。这些方法大多从如何对待识别图像的局部判别区域进行定位与对齐的角度出发,通过将深度卷积神经网络所提取到的全局特征与局部特征相结合来改善细粒度识别的性能。而在更具体的细粒度车型识别领域,也有不少基于深度学习的研究成果。如文献[15]建立了一个大规模的车辆数据库“CompCars”,并在此数据集上使用深度网络进行训练,并将结果用于车型分类、车型验证和车辆属性研究。文献[16]将全局特征和局部特征结合起来进入卷积神经网络反复训练,输出的特征显示出对子类别有更强的判别能力。文献[17]将监控视频中获取的车辆3D信息送入卷积神经网络作为一个额外的信息,结果显示得到了更好的分类效果,尤其是在车型的验证上尤为显著。为减少复杂背景信息对识别结果的干扰,文献[18]首先结合视觉显著性及车辆的位置信息来对图片中的车辆进行精确定位,然后再对车型识别及车辆的视角分类这两个任务进行联合优化,从而引入更多信息来应对场景中车辆视角变化的问题。文献[19]引入了车辆各部件位置的标注信息来设计了对车辆的关键部件进行检测的模型,并通过一个投票机制来结合车辆的全局特征与局部部件的特征以提高细粒度车型识别的准确率。
与以上工作不同的是,本文将从实际应用的角度出发,旨在开发一套简洁高效的细粒度车型识别方法,在无需部件位置标注及车辆3D信息的情况下仍能准确地对交通监控场景下的车辆前脸图片进行有效识别。由于所针对的细粒度车型识别任务中车辆的视角变化并不大,该方法并未把车辆的视角信息引入到网络的学习中,而是引入了车辆的类型信息来构建多任务学习的网络。实验证明,车辆的型号及类型间在语义级别上存在着一定的关联,通过对二者进行多任务的联合学习,在保持较高识别效率的同时,可实现最终的识别准确率相比各自单任务学习时均有提高。
1 方法
1.1 深度网络简介
本文分别采用AlexNet、GoogLeNet、ResNet等3种深度卷积神经网络模型来进行车型细粒度识别任务,并对比分析其各自性能的优劣。这些模型都是深度学习在视觉领域发展史上的里程碑,基本反映了深度神经网络中层数越深,性能越佳的规律(图1)。

图1 ILSVRC 历年的 Top-5 错误率
1.1.1 AlexNet
AlexNet是由Hinton及其学生Alex Krizhevsky等在2012年提出的一个深度学习网络架构,并摘得视觉领域竞赛 ILSVRC 2012 的桂冠,在百万量级的ImageNet 数据集合上,其错误率比使用传统方法的第2名参赛队低了约10%。该网络结构图如图2所示,包含5个卷积层和3个全连接层。相比于之前的神经网络,其主要有以下几个创新点:
(1) 引入新的非饱和型激活函数ReLU替代了之前普遍采用的饱和型激活函数(如Sigmoid、tanh等),实践表明ReLU可以有效缓解训练过程中的梯度消失现象,有利于更快速地收敛,减少训练时间。
(2) 通过dropout技术在训练过程中将中间层的一些神经元随机置零,提高模型的泛化性能、减轻过拟合。
(3) AlexNet在多个GPU上训练,往往单个GPU的内存不足以支撑在其上训练网络的最大规模,多个GPU并行计算使得深度网络的训练成为可能。
(4) 通过随机裁剪、平移变换、水平翻转、灰度值扰动等方式扩充训练样本集,减轻过拟合。这些数据增扩的方式也在之后许多深度卷积神经网络的实践中广为使用。

图2 简化版的AlexNet
1.1.2 GoogleNet
GoogLeNet (图3)是Google公司的Christian Szegedy等人于2014年提出的卷积神经网络,网络层数达到22层,其中提出了很多新颖的结构和想法,并在ILSVRC 2014中获得了分类和检测第一的成绩。相比于AlexNet,该网络在设计上受到了Hebbian学习规则的启发,同时基于多尺度的处理方法对卷积神经网络进行了改进。一般而言,加深网络层数将增加网络所需要学习的参数量,从而加大了过拟合的风险,同时也增加了模型的计算复杂度,为此,GoogLeNet采用了以下几个解决方法:
(1) 引入了Inception结构(图4),此结构拥有多个不同尺度的卷积核,可通过多尺度的卷积操作提取响应图中的多尺度信息并进行融合,从而增强卷积模块对目标多尺度变化的处理能力。但是多尺度卷积核会带来计算复杂度的增加,为此,网络采用了1×1卷积核来先对输入的特征图进行降维,然后再用多尺度卷积核来分别处理降维后的特征图,最后再通过拼接操作来对不同尺度的特征进行融合,成倍地降低了参数数量,从而减轻了过拟合。
(2) 将传统神经网络在最后分类时常采用的全连接层替换为了全局平均层。在传统以全连接层作为最终的全局特征聚合及分类的网络中,超过80%的参数都是位于全连接层,然而通过全局平均层即可极大地降低这一部分参数的消耗,且同样可实现全局特征聚合及分类的功能,最终也减轻了过拟合的风险。
(3) 在网络中加入了两个辅助分类器,从而在网络的中间部分也为模型提供梯度反馈。深层网络最大的弊病就是当网络变深时会产生梯度消散,而一旦在浅层加入了辅助分类器,就会一定程度上对梯度进行弥补,让网络的训练更有效。
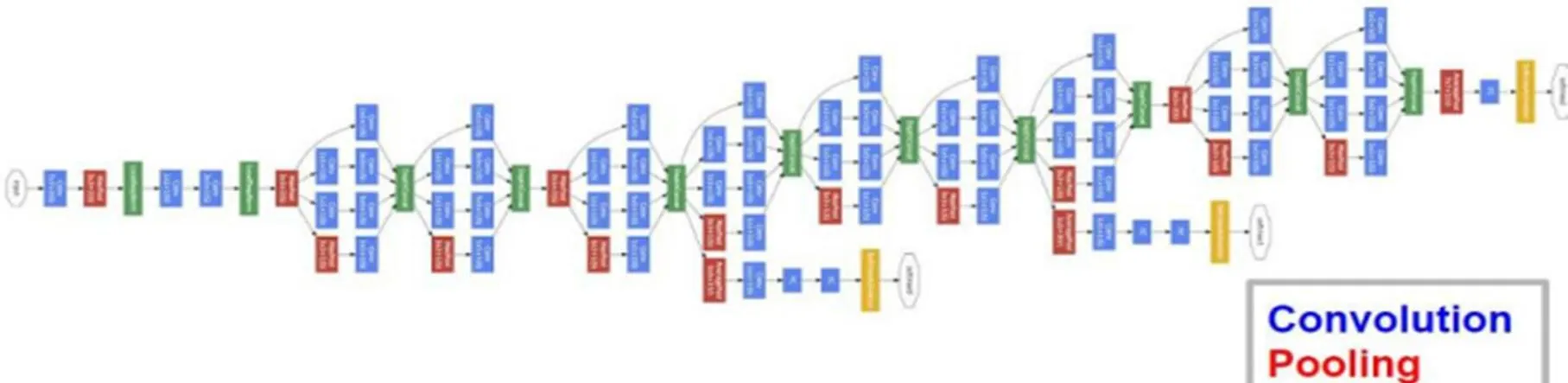
图3 GoogleNet模型结构图

图4 Inception结构
1.1.3 ResNet
ResNet (deep residual network)的全称是深度残差网络,是何恺明等人于ILSVRC 2015竞赛上提出的深达152层的深度卷积神经网络架构,并以绝对优势获得图像分类、图像定位、图像检测3个项目的冠军,其中在图像分类的数据集上取得了3.57%的错误率。该网络基于残差学习的思想,在传统卷机模块的基础上引入了一条shortcut,从而构成了一个残差模块,解决了在直接增加网络深度时会出现的模型“退化”问题(图5)。
该残差模块的输出为输入信号与卷积层输出结果()的叠加,即卷积层仅需要去学习网络最终输出结果与其输入信号之间的残差值。其好处主要在于:使得网络的反向梯度传导过程更加顺畅,减轻了在对深层网络训练时常出现的梯度消失或是梯度爆炸问题。在简单堆叠传统卷积模块所构成的深度网络中,梯度的反向传导是以乘法的方式进行的,随着层数的加深,传递到网络浅层的梯度信号都会难以避免地受到更大的衰减或是扩张,从而导致了对网络浅层的训练失效或是不稳定的问题。而通过堆叠残差模块来构成深度网络即可将梯度的反向传导转换为以加法的方式进行,存在有多条路径可将网络的梯度信号传递到浅层,且其中一条路径是完全直通的,使得在训练深度网络时梯度的传递更顺畅、更稳定,从而使性能得到了进一步的改善。
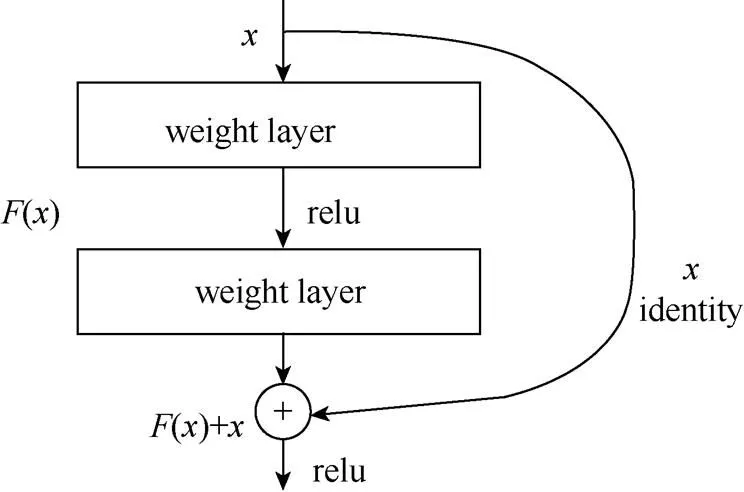
图5 ResNet中的残差模块示意图
1.2 多任务细粒度车型识别网络
本文所提出的多任务细粒度车型识别网络主要包含:①分别以AlexNet、GoogleNet或ResNet等深度卷积神经网络所构成的特征提取模块;②结合了细粒度车型识别以及车辆种类分类所构成的多任务损失函数模块,其中虽然车辆种类分类任务主要是作为一个辅助任务来为细粒度车型识别任务提供更多信息,从而达到正则化的效果,但任务本身也具有不错的应用前景,且细粒度车型识别任务同样可为其提供更多信息,即两个任务之间相互促进,共同为其共享的特征部分提供梯度信息。其多任务损失函数为
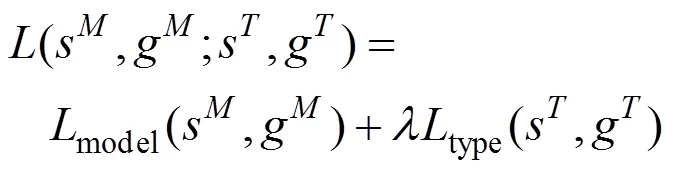
2 实验
2.1 实验数据集
为了能更好地与之前的工作进行对比,本文所采用的数据集来自于CompCars数据集中“suveillance- nature”部分的数据。图6展示了从该数据集中随机取出的一部分图片,均直接采集自高速公路上的监控摄像头,因为光照、天气等因素,图片质量受到了很大的影响,使得细粒度车型识别任务更具挑战性,并且也更具有现实意义。
本次实验使用了该数据集中所有的44 481张车辆前脸图片,并将其按7:3的比例划分为了训练集(31 148张图片)和测试集(13 333张图片),训练集和测试集包含有同样的281个类别的细粒度车型以及6个类别的车辆种类,且数据类别的分布都是一致的。为了更便于网络的训练,将所有图片的分辨率都调整为了256×256大小。

图6 CompCars数据集样例图片
2.2 实验细节说明
在训练多任务细粒度车型识别网络时,采用了在ILSVRC2012的分类数据集上预训练好的caffe[20]模型作为网络的初始化值,然后再针对特定数据集对模型进行微调,原因是ILSVRC2012数据集是一个种类繁多、变化复杂的大规模图像分类数据集,通过在该数据集上进行预训练,可使模型学到一些泛化性强、适用于多种任务的通用特征,通常可帮助加速模型在其他特定任务上的训练进程,且提高模型的性能,尤其是当特定任务的数据量比较少时。通过采用这样一个预训练策略,最终测得一个网络的训练时间仅需要约2 h,其中GPU配置为GeForce GTX TITANX,CPU配置为Intel® Xeon® CPU E5-2683 v3。
在对预训练完毕的模型进行微调时,将分类层原先的1 000路输出改为了并行的281路输出及6路输出,分别代表281个类别的细粒度车型及6个类别的车辆种类,并从均值为0、方差为0.001的高斯分布中采样来对新的分类层进行初始化。在学习率方面,将初始全局学习率设置为了0.001,并将其应用于新加入的分类层,对预训练的模型部分,则是采取衰减10倍后的学习率,且每训练10个epochs,将全局学习率衰减10倍。权重衰减系数设置为0.000 1。在评价指标方面则采取了top-1准确率,即以模型对测试集预测正确的样本数来除以测试集的总数,即
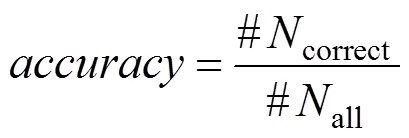
2.3 实验结果分析
本部分将首先对不同网络结构下的多任务细粒度车型识别网络的识别性能进行对比,接着再比较多任务的学习机制相比单任务学习之间的性能差异,最后分别在细粒度车型及车辆类型分类这两个任务上,将本文方法与近几年的一些相关工作进行性能对比分析。
表1定量展示了分别基于AlexNet,GoogleNet及ResNet等3种网络结构的多任务细粒度车型识别网络间的性能对比,数据结果表明,随着网络层数的增加,模型在细粒度车型识别以及车辆类型分类上的性能也在逐步改善,尤其是50层的ResNet相比8层的AlexNet,其在两个任务上的识别准确率都提高了约5个百分点。说明在有效缓解了过拟合及梯度消失等诸多问题后,更深的模型在细粒度车型识别及车辆类型分类方面具有更强的非线性建模能力及特征表达能力,因而也更适于应对这类问题。
为了进一步探究多任务学习的性能,本文还以AlexNet为基础网络架构,比较了细粒度车型识别与车辆类型分类的不同组合下所训练得到的模型性能(表2)。由表2中数据可知,通过多任务的联合学习,可使模型进一步挖掘不同任务间隐藏的共有数据特征,从而使得完成每个任务上的准确率都能提升1至2个百分点,结果表明在引入多任务机制在解决上述两个特定问题上是有效的,主要在于细粒度车型识别与车辆分类任务之间存在有一定的相关性,如宝马X系列一般都为运动型轿车、而奥迪A系列则一般为轿车。
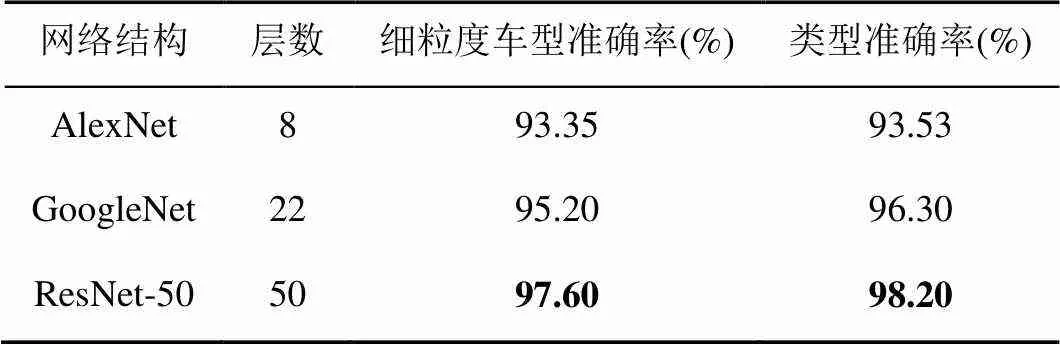
表1 基于不同网络结构的模型的识别准确率对比

表2 单任务模型与多任务模型的识别准确率对比
表3则将本文所提出的方法与近几年在细粒度车型识别任务上取得state-of-the-art的方法做了对比,所有方法的准确率均是在CompCar数据集中的“survelliance-nature”上评估得出的,以保证对比结果的公平及合理。其中,文献[21-22]等都是基于人工特征的方法,可见受到人工特征对辨识信息提取能力弱、对特定问题适应性差等方面的限制,这些方法在应对类别数较多(281类)、变化因素较复杂的细粒度车型识别任务时,性能与基于深度特征的方法间还有很大差距。文献[16]的方法虽然在性能上比本文方法略优一些,但采取的是一个多阶段的评估流程,即需要分别对车辆全身与车辆部件进行处理才能得到最终结果,而本文方法则仅需要对车辆全身进行处理即可得到一个较优的结果,因而更加简洁高效。

表3 不同方法在细粒度车型识别任务上的对比
图7展示的是本文模型的一些定性识别结果。第一行是识别正确的图片,第二行是识别错误的一些例子,通过分析,可以看出识别错误主要集中在几种情况:①同一品牌同一系列的不同年款的车型如宝马X系列;②外观极其相近的车型,此类情况更多地发生在SUV这一种车辆类别中;③一些训练图片较少的小众车型容易识别为其他类别,此类情况可以通过加大样本量来提高识别率。

图7 部分细粒度车型定性识别结果
3 结束语
本文将经典的几种深度卷积神经网络引入到了细粒度车型识别的应用中,并结合多任务学习的思想引入了车辆类型分类的辅助任务来进一步提高模型的性能。通过在一个包含281种细粒度车型的公开数据集上进行实验,验证了深度特征相比人工特征具有更强的辨识信息抽取能力,更适用于细粒度车型识别等较为复杂的分类问题,且随着深度卷积神经网络的容量及非线性建模能力的增加,模型性能也能得到进一步改善。辅助任务车辆类型分类的引入,可帮助模型挖掘到不同任务间的关联信息,提高了其在任一单任务上的性能,且仍然保持了很高的效率。最终所实现的方法简洁高效,日后将这一技术应用于道路监控设备对道路车辆进行实时识别具有一定的指导意义。
[1] ZHANG B. Reliable classification of vehicle types based on cascade classifier ensembles [J]. IEEE Transactions on Intelligent Transportation Systems, 2013, 14(1): 322-332.
[2] PENG Y, JIN J S, LUO S H, et al. Vehicle type classification using data mining techniques [C]//The Era of Interactive Media. New York: : Springer-Verlag, 2013: 325–335.
[3] 汪宇雷, 毕树生, 孙明磊, 等. 基于SIFT, K-Means和LDA的图像检索算法[J]. 北京航空航天大学学报, 2014, 40(9): 1317-1322.
[4] LIU, L X, ZHANG H G, FENG A P, et al. Simplified local binary pattern descriptor for character recognition of vehicle license plate [C]//2010 Seventh International Conference on Computer Graphics, Imaging and Visualization (CGIV). New York: IEEE Press, 2010: 157-161.
[5] DALAL N, TRIGGS B. Histograms of oriented gradients for human detection [C]//IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2005.New York: IEEE Press, 2005: 886-893.
[6] PROKAJ J, MEDIONT G. 3-D model based vehicle recognition [C]//2009 Workshop on Applications of Computer Vision (WACV). New York: IEEE Press, 2009: 1-7.
[7] RAMNATH K, SINHA S N, SZELISKI R, et al. Car make and model recognition using 3d curve alignment [C]//2014 IEEE Winter Conference on Applications of Computer Vision (WACV). Los Alamitos: IEEE Computer Society, 2014: 285-292.
[8] 山世光, 阚美娜, 刘昕, 等. 深度学习: 多层神经网络的复兴与变革[J].科技导报, 2016, 34(14): 60-70.
[9] KRIZHEVSKY, A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks [J]. Communi Cations of the ACM, 2017, 60(6): 84-90.
[10] SZEGEDY C, LIU W, JIA Y Q, et al. Going Deeper With Convolutions [C]//The IEEE Conference on Computer Vision and Pattern Recogntion. New York: IEEE Press, 2015: 1-9.
[11] HE K M, ZHANG X G, REN S Q. Deep residual learning for image recognition [C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2016: 770-778.
[12] ZHANG N, DONAHUE J, GIRSHICK R, et al. Part-based R-CNNs for finegrained category detection [C]// European Conference on Computer Vision.Cham: Springer, 2014. 834-849
[13] GUILLAUMIN M, KÜTTEL D, FERRARI V. ImageNet auto-annotation with segmentation propagation [J]. International Journal of Computer Vision, 2014, 110(3): 328-348
[14] LIN D, SHEN X Y, Lu C W, et al. Deep LAC: deep localization, alignment and classification for fine-grained recognition [C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2015. 1666-1674
[15] YANG L J, LUO P, LOY C C, et al. A large-scale car dataset for fine-grained categorization and verification [C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2015: 3973-3981.
[16] FANG, J, ZHOU Y, YU Y, et al. Fine-Grained vehicle model recognition using a coarse-to-fine convolutional neural network architecture [J]. IEEE Transactions on Intelligent Transportation Systems 2016, 18(7): 1782-1792.
[17] SOCHOR J, HEROUR A, HAVEL J. BoxCars: 3D boxes as cnn input for improved fine-grained vehicle recognition [C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2016: 3006-3015.
[18] HU B, LAI J H, GUO C C. Location-aware fine-grained vehicle type recognition using multi-task deep networks [J]. Neurocomputing, 2017, 243: 60-68.
[19] WANG Q, WANG Z, XIAO J, et al. Fine-grained vehicle recognition in traffic surveillance [C]//PCM 2016 17thPaeific-Rim Conference on Advances in Multimedia Information. New York: Springer-Verlag. 2016: 285-295.
[20] JIA Y Q, SHELHAMER E, DONAHUE J, et al. Caffe: convolutional architecture for fast feature embedding [C]// Proceedings of the 22ndACM International Conference on Multimedia. New York: ACM Press. 2014:675-678
[21] HSIEH J W, CHEN L C, CHEN D Y. Symmetrical SURF and its applications to vehicle detection and vehicle make and model recognition [J] IEEE Transactions on Intellingent Transportation Systems, 2014, 15(1): 6-20.
[22] ZHANG B L. Reliable classification of vehicle types based on cascade classifier ensembles [J] IEEE Transactions on Intelligent Transportation Systems, 2013, 14(1):322-332.
Multitask Fine-Grained Vehicle Identification Based on Deep Convolutional Neural Networks
Wang Haiyao1, Tang Juan2, Shen Zhenhui1
(1. School of Engineering, Fujian Jiangxia University, Fuzhou Fujian 350108, China; 2. School of Management Engineering,Anhui Polytechnic University, Wuhu Anhui 241000, China)
Vehicle identification, especially fine-grained vehicle identification, is an important part of modern intelligent transportation system. Aiming at the problem that it is difficult to effectively recognize fine-grained vehicle using traditional vehicle identification methods, we take three classic deep convolutional neural networks (such as AlexNet, GoogleNet and ResNet) as the basic networks, and introduce the classification of vehicle types as the auxiliary task, together with fine-grained vehicle identification task to constitute a multitask joint-learning model. By training and evaluating our model on a public data set which contains 281 vehicle types, we have demonstrated the excellent performance of this model in fine-grained vehicle identification task with no need of annotations about vehicle parts’ location and additional 3D information. Besides, with the introduction of multitask learning strategy, the performance of this model can be improved, compared with that of any single-task learning model. Our model is simple and efficient, and can basically meet the demand of practical applications.
intelligent transportation;fine-grained vehicle identification; deep learning; neural networks
TP 391
10.11996/JG.j.2095-302X.2018030485
A
2095-302X(2018)03-0485-08
2017-08-27;
2017-09-28
福建省中青年教师教育科研项目(JAS160616)
王海瑶(1976-),女,安徽固镇人,讲师,硕士。主要研究方向为智能调度、流程优化等。E-mail:723570259@qq.com
