浅析关联数据的数字图书馆资源聚合与服务设计
2018-07-12徐晖武汉商学院图书馆
徐晖 武汉商学院图书馆
引言:图书馆对于每个大学来说都是重要的知识宝库,每个在校的学生都可以通过在图书馆的学校来获得进步。因此,图书馆建设的好坏关系着万千学子的成长与发展。面对日新月异的科学技术,线上的数字图书馆也逐渐进入人们的视线。同时,大学生是对新兴事物的接受能力是最强的,已经有很多大学生通过线上图书馆进行学习查找资料。因此,数字图书馆项目的建设也越来越重要,对其中的各种图书资源也需要合理的进行归类和分类。这就需要关联数的数字图书馆资源聚合方法,并且对服务系统进行合理的设计。提高用户的体验感受,优化数字资源的合理利用,提高资源的利用率,扩大图书的使用效率,这一直是我国的数字图书馆所追求的目标,同时也是当前对于数字图书馆资源聚合研究的热点问题。
当今世界,各国各方面的现代化建设规模不断扩大,在我国亦是如此。不仅是在工程建筑领规模扩大,在信息科技方面的进展也是日新月异的,特别是对待科学教育方面,更是走在前列。因此,对于数字图书馆资源聚合与服务设计领域的研究也越来越重视。同时还有用到很多关联数据,通过对这些信息数据进行整合优化,可以建立起一个优化的模拟模型,为下一步的建设工作提供客观的信息。
1 数字图书馆建设
随着科技的发展,各行各业的信息化程度逐步提升,信息化也已成为当今社会的一个主要特征。社会中的各行各业都因网络技术和智能电子技术的应用而得到更好的发展。对于高校的教育事业也不例外。现在网络信息技术和数据检索技术水平越来越高,对于各大高校中的数字图书馆建设也带来了巨大的好处和便利。
1.1 数字图书馆建设背景
国外对于图书馆的智能化信息模型的建设和应用起步较早。由于国际形式变化越来越快,各个的教育问题也因此受到了很大的关注。例如教育的普及率,教育资源的利用率,学生的成就等一系列问题。因此,学生的教育问题是一个重要的问题。国外对于各种教育资源的利用率一直处于较高的行列。对于图书馆的资源聚合与服务设计,国外一些学者聚焦于复合图书馆的研究,这个符合图书馆的原理是通过统一的界面来为用户提供多样化的服务,并且可以提高资源的利用率,另外这个认证的网关也是唯一的。即可以保证资源的安全性和重复性,不会被外界所干扰,是处于一种安全的模式之下,保障了数字图书馆庞大数据库的安全性。
1.2 数字图书馆建设概述
我国的大多研究均是从数字聚合资源模型的定义这个角度出发,构建出适合各种类型数字图书馆。目前,可以在管理领域建立合适数据信息模型,利用数据信息模型技术进行项目成本优化等探索。基于此,对我国已经建设成功的数字图书馆进行评估和成本计算。将合适的服务设计导入新的数据信息模型库中,利用程序方程得出成本的预算流程,从而达到节约成本的目的。另外,还可以进行基于成本预算流程对整个项目系统的软件框架设计和功能设计,为数据信息模型在成本预算方面的应用提供了进一步研究提供基础。
现阶段,相比于国外数字图书馆建设的研究状况,我国是仍是处于落后状态的。但是,我们的研究是在一定方向和基础上开展的,进行了针对性的研究。从关联数据的信息管理的角度,利用大量的时间来分析各种具有不同特点的资源聚合,进而可以指出目前国内存在的数字图书馆信息模型的优点和不足,通过信息集成的方法,将优点继续发扬,对缺点进行优化改进。
2 数字图书馆协同信息推荐模型和聚合方法
2.1 基于关联数据的模型推荐
对于关联数据是一种大型模型设计。基于此的协同信息推荐的主要工作和关键点在于观察大多数用户经常检索的数字资源,得到客户需求的规律,并对查找内容进行资源评价。随后,可以利用大数据库对近期所被查找的内容进行总结,再进行数据的录入和输出。
此处推荐的模型是采用比较的方法来对用户之间的相似度评价进行计算。基础此,我们选用皮尔森相关相似性计算法,用户i和j对项目C的评分是用ri,C和ij,C来表示的,用户j对共同评分过的项目的平均评分用ij来表示,而用户i和j对项目评分平方的平均值用ri2和ij2;来表示,则用户i和用户j之间的相似性Sim(i,j)的计算公式如下:
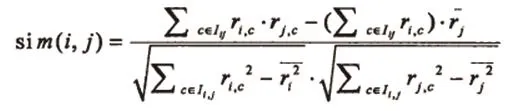
根据上述皮尔森相关相似性的计算公式,对所有用户与当前用户U的相似性进行具体计算,这些计算出来的结果就构成了当前用户U的最近邻居集合,如下表达式所示:
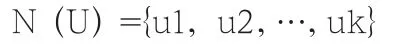
其中 sim (u,uk) 这样一轮下来,先对项目的预测评分进行排序,选择预测评分最高的n项目并将其推荐给用户,这一过程就是TOP-N推荐。 数字图书数字资源聚合方法是多种多样的,针对不同的图书馆类型有着不用的聚合方法。在进行计算和模拟的时候,需要根据所属的条件进行二次筛选,以便选到合适的类型,在此,我们列举了一些常用那个数字资源聚合方法,以供参考: (1)基于OPAC系统的数字资源聚合; (2)基于跨库检索、异构数据源的数字资源聚合; (3)基于数字资源导航的聚合; (4)基于链接导航的数字资源聚合。 我们所处的时代是一个信息化的时代,生活中的各个环节都离不开信息的推送,可以说如果失去了信息,那么就像失去了双眼一样。各种各样的信息推送组成如今信息化的世界。同时,个性化的信息推送了随之而来。而在数字图书馆中,我们也可以进行个性化的信息推送。因此,在数字图书馆中,对于数据的管理运用是非常重要的一个环节。如何对关联数据进行整合归类,关系着个性化信息推送的命脉。在日常的资源利用中,资源的聚合可以扩大资源的利用率,同时我们可以通过对关联数据的整合,了解用户最新的需要和最想找到的资源有哪些,从而可以的主动地向用户或读者提供其所需的数字资源及相关检索意见。更为重要的是,对于用户搜索的内容,可以进行一定的定位追踪,然后就可以为用户提供一些解决问题的方法和一些特定服务,这些就是关联数据和资源聚合而实现对读者的服务设计内容。 由于共同出现的查询词具有某种程度的语义相似性,如果能够对查询的相似度进行定量计算,则可通过数值反映出查询词之间的语义联系。因此,为了体现查询词之间关系,首先需要对查询条目进行分词处理。 进行标准化之前,应该统计查询词的出现频率,在所有 询词中确定了a个待选核心查询词,这样能把日志条目中的所有查询词按照a个待选核心 询词按按主题进行查询词的相似度分析,一定程度上保证相似度计算的准确性。接着按某种属性对a个核心查询词分成P类,然后确定o/p个核心查询词。每个核心查询词可以代表同一属性的查询词集合,对于每个集合而言,不是所有的核心查询词的共现 询词都适合做后续处理,比如一些与其它查询词共现频率不高,原则是根据该查询词的频率以及共现频率。经过上述处理,可以得到反应不同属性的查询词集合。例如,有四个查询条目(A,B,C,D),(A,C,D),(B,C,D,E,F),(D,E,F),则可构造出如下所示的6*6对称矩阵 W(i,j): 在该矩阵中,Wij表示第i个查询词与第j个查询词一起出现的频率。我们需要将基于共现频率的相似矩阵转化为基于共现频率的标准化相似矩阵。现有多种转化公式,本文采用相似距离公式,如下所示, 其中有2个参数n和k。n表示可视化空间的维度,一般情况下,n取2或3。k只能取正整数。当k=l时,表示两个点上在标准坐标系上的绝对轴距总和;当k=2时,公式1变为欧氏距离公式,它能测量在m维空间中两个点之间的真实距离;当k趋近正无穷时,变为确界距离。公式2中的参数c为非0的正小数。当01时,S (X,y)值处于(0,1)之间,C越小,S (x, y)的值越趋近1;当0 本文是从关联数据的角度,介绍数字图书馆的资源聚合和服务设计等方面。研究了国内外对于数字图书馆的研究方向。在基于关联数据、资源聚合、服务设计等思维标准下描述了数字图书馆的一个含义、原则和方法。首先介绍了数字图书馆研究的现状、资源聚合概念、关联数据结构,使对这个数字图书馆有一个具体的了解。同时介绍了一个资源聚合的模型实例,并可以从中检索出有用的数据信息,从而进一步使数字图书馆得到更好的应用和发挥,使数字图书馆的使用率、重复率和资源利用率等功能更好的展现出来。数字图书馆对学校的教育事业的发展是功不可没的,在提高学生学习查阅资料速度和学习效率的同时,还能节约各方面的成本,提高学生的积极性,可操作性和便捷性。针对各个方面存在的问题都可以及时的进行预测和优化调整。以后的研究和发展可以向更多有效的数据信息的获取方面进行探究,争取获得更精准详细的数据,建立起完善的数据库系统,为日后数字图书馆信息模型的建立打下良好的基础。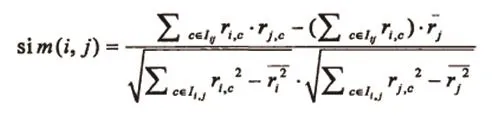
2.2 数字图书数字资源聚合方法
3 基于关联数据的数字图书馆创新服务
3.1 基于关联数据的信息个性定制与推送
3.2 数字图书馆数据格式标准化

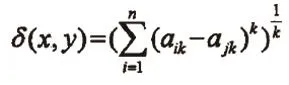
4 结束语
