基于生物特征的声纹识别算法及实现
2018-07-12马意彭王震董雨楠钟雅婷南京邮电大学电子与光学工程学院
马意彭 王震 董雨楠 钟雅婷 南京邮电大学电子与光学工程学院
引言:声纹信息是生物特征的一项重要组成部分,具有数据易取性、身份认证准确性等特点。这些特点使得声纹识别技术具有较高的研究价值。本文在声纹识别算法研究的基础上,对已有的声纹识别算法进行了改进,并取得良好的识别效果。
1 语音信号预处理
说话人发出的语音信号既有声纹特征又有说话内容。,所以为了提高声纹识别的准确性,必须对说话人发出的语音信号进行预处理。其步骤如下:
1.1 语音信号的采样和预加重
原始语音信号为模拟信号,经ADC采样及量化后可转换为离散的数字信号。由于语音信号受声门激励和口鼻辐射的影响,所以800HZ以上的高频分量会有所衰减。为了使得频谱平坦,所以采用预加重的方法提高高频分量。
1.2 加窗分帧和短时能量分析
经采样和预加重处理后的信号依旧是一个时变信号,所以只有在一个极其短的时间内才能表现出较稳定的声纹特征。故我们将语音信号在8ms~22ms的短时间内作为一帧,采用汉明窗对语音信号进行提取。为了提取对声纹识别有效的声段,我们采用了短时能量分析的方法。只有当某一帧内语音信号的平均幅度高于某一阈值时,才将其作为有效帧进行声纹特征提取,这样可以提高识别效率。
2 语音信号CS-MFCC特征提取
2.1 MFCC特征参数
美 尔 频 标 倒 谱 系 数(Mel Frequency Cepstrum Coefficient,MFCC)是基于Mel 频标的非线性谱的倒谱,具有识别能力强、抗噪能力强等特点。Mel 谱可以由Mel频率滤波器组获得。MFCC以傅里叶变换和倒谱分析为基础,对音频帧上的每个频点进行能量计算,即可得到MFCC。
2.2 CS-MFCC特征参数
本设计采用压缩感知-美尔频标倒谱系数(Compressed sensing- Mel Frequency Cepstrum Coefficient , CS-MFCC)作为语音信号的特征。由于语音信号在正交空间具有稀疏性所以可以采用压缩感知的方法对信号进行重构,这样可以大大降低采样信号的频率,提高采样效率。
3 基于GMM-UBM的说话人识别算法
3.1 GMM模型
高斯混合模型(Gaussian Mixed Model,GMM)指的是多个高斯分布函数的线性组合,理论上GMM可以拟合出任意类型的分布,通常用于解决同一集合下的数据包含多个不同的分布的情况。由于每个说话人的语音信号的特征分布是不同的,故可以采用GMM模拟说话人的语音信号特征分布并作为说话人的识别依据。
3.2 GMM-UBM模型训练框架
由于注册时说话人的数据具有稀疏性,所以通常使用通用背景模型(Universal Background Model,UBM)和少量的说话人数据对说话人模型进行训练,然后通过自适应算法得到目标说话人模型。一般情况下,当GMM-UBM模型的每个混合对象得到100帧左右的训练样本时,就可以得到较高且较稳定的识别率。
3.3 声纹识别算法设计框图
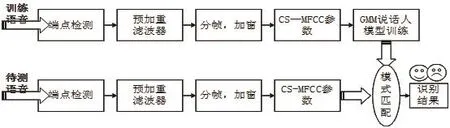
图1 声纹识别算法设计框图
4 声纹识别系统绩效评估
本系统采用中、英、法三种语言进行测试,其效果如图2所示。由图2可知,CS-MFCC32阶GMM具有较好的识别效果,证明本系统的有效性及实用性。
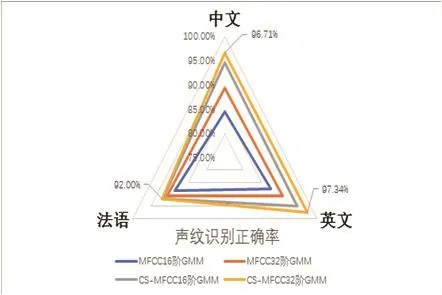
图2 声纹识别系统绩效评估
5 结论
本文在声纹识别算法研究的基础上,提出了CS-MFCC声纹特征提取方法及基于GMM-UBM说话人识别算法,并取得了良好的识别效果,为声纹识别算法的发展提供了新的思路。
