基于PSO-FCM算法的碳酸盐岩储层流体识别
2018-07-10陈钢花王军刘有基张艳梁莎莎
陈钢花, 王军, 刘有基, 张艳, 梁莎莎
(1.中国石油大学(华东)地球科学与技术学院, 山东 青岛 266580;2.中国石油化工股份有限公司胜利油田分公司勘探开发研究院, 山东 东营 257000)
0 引 言
碳酸盐岩储层储集空间多样,非均质性较强,加大了流体识别难度[1-3]。核磁共振等测井新技术能够较好地识别流体,但其测井费用昂贵,在老井中资料较少[4],且核磁共振测井不适用于套管井,因此,非常有必要研究基于常规测井资料的碳酸盐岩储层流体识别方法,提高流体识别符合率,在老井中发现遗漏储层,提升产能。
数据挖掘技术可从海量数据中获取信息,可用于样本数据的分类处理[5-6],因此,在碳酸盐岩储层流体识别中应用广泛。罗利[7]等基于测井和试采资料建立气层及水层样本集,用神经网络法对样本井储层流体性质做了判别,回判符合率达93%;陈科贵等[8]提出一种模糊灰关联模式识别的方法,根据最大隶属原则判别流体类型;于代国等[9]引入支持向量机方法,建立了基于测井参数的流体识别模型;刘得芳等[10]将决策树应用于流体识别,该方法比单一信息判别方法准确性更高;赵军等[11]将样本按相对密度聚类成簇,并利用K近邻投票获得各簇所属类别,识别精度较高,泛化性和鲁棒性强。在诸多算法中,神经网络算法较为复杂,在测井流体识别方面,如果学习样本数量较少,实际应用时容易出现过拟合问题,从而导致准确率下降;决策树法在分类较多时错误率较高。在测井解释中判定流体所用曲线数量以及标准样本数量不大时,使用聚类算法获得较为准确的结果,同时训练量较少,效率较高。减弱聚类初值的影响,尽可能减少训练量,提高运算速度是运用数据挖掘技术识别储层流体的发展方向。
本文利用PSO算法改进FCM算法受初值影响较大的不足,并将其应用于碳酸盐岩储层流体概率计算,结合交会图法确定了流体识别标准,并将识别方法应用于川东北地区礁滩气藏流体识别研究中,取得了良好的应用效果。
1 方法原理
1.1 样本数据矩阵的构建
常规测井曲线隐含着流体信息。为计算流体概率,构建样本数据矩阵Y
Y=WTX
(1)
式中,Y为样本数据矩阵;X为标准化后的测井参数矩阵;W为测井参数的权重矩阵。
各测井参数的权重W由式(2)计算
(2)
式中,P为平均流体指示系数,用以表征各测井参数的流体敏感性[12]

1.2 基于PSO-FCM的流体概率计算
FCM算法用隶属度矩阵给出各对象属于某一类的程度,对于很难明显分类的对象,FCM也能得到较为满意的分类效果[13-15]。由于FCM算法本身是一种局部搜索寻优法,极容易受初值影响陷入局部极小值,从而找不到全局最优解,而PSO算法具有全局寻优、快速收敛的优点,PSO-FCM算法就是利用PSO算法的全局搜索能力对FCM算法进行改进形成的,不论初始聚类中心如何选取,都能保证得到全局最优解。
选取FCM算法的目标函数J(Y,U,V)作为PSO算法的适应度函数
(3)
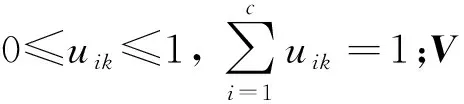
PSO-FCM算法就是求得使适应度函数最小的U和V。引入拉格朗日乘子法可得
(4)
(1≤i≤c,1≤k≤N)
(5)
(6)
PSO-FCM算法的实现步骤:
(1) 设定参数。类别数c、群体规模N、学习因子c1和c2、模糊指数m、权重系数w、迭代次数b,随机选择c个观测样本组成一个粒子,直至产生N个第一代粒子,随机初始化粒子速度。
(2) 按式(5)、式(6)分别计算每个粒子的的隶属概率及聚类中心。
(3) 按式(3)计算每个粒子的适应度值,将每个粒子所在位置作为粒子最优位置pbest,将适应度最小的粒子位置作为全局最优位置gbest。
(4) 按式(7)更新粒子的速度vi及位置yi,产生新一代的粒子
(7)
(5) 如果最后2次计算的适应度值相同或者达到最大迭代次数b,则停止迭代,将最后一代作为最优解,否则转到步骤(3)。
选取样本进行训练,由最优解得到研究区各类流体的聚类中心,根据式(5)可计算得到其他井段储层的流体概率。
1.3 流体识别标准确定
考虑气层、气水同层和水层之间的关联性[16],只计算储层属于气层、水层和干层的概率,采用设置阈值的方式区分气水同层。依据储层的最大流体概率对其流体类型进行初判,干层的识别标准与其初判标准相同,针对试采水层、气层、气水同层3类数据,作气层概率和水层概率交会图,确定气层和气水同层的概率阈值T1、水层和气水同层的概率阈值T2,进而得到流体识别标准
(8)
式中,uw为水层概率;ug为气层概率;ud为干层概率;T1为气层和气水同层的概率阈值;T2为水层和气水同层的概率阈值。
2 实例分析及应用
2.1 研究区概况
研究区二叠统生物礁是在长兴期海侵过程中发育的以海绵—水螅为主要造架生物的海侵礁,长兴组在全球范围内基本表现为海退,但我国南方出现新的海侵。随着这次海侵,带来了晚古生代某些生物(如钙质海绵)的迅速繁殖,并在许多地区形成规模不等的生物礁。由于生物礁常为多孔的岩石,有利于油气聚集,即使厚度不大,对于生产也有重要意义,因为一个潜伏礁体就有可能发育一个油气藏。目标储层由灰岩、生物灰岩、含燧石灰岩、泥灰岩夹次生白云岩及泥岩组成,台缘海绵礁发育。
研究区长兴组储层天然气富集,气藏厚度5.25~85.05 m,岩心样品孔隙度2.86%~9.32%,平均为7.0%,小于12%的样品占97%,基质平均渗透率变化范围在0.002~679 mD*非法定计量单位,1 mD=9.87×10-4 μm2,下同,低于100 mD的样品占98%,低于10 mD的样品占70%。
2.2 应用效果
长兴组储集空间可分为孔、洞、缝3类,均是通过多次溶蚀或构造作用形成,孔隙类型包括有粒间孔、晶间孔、晶间溶孔、粒内溶孔等。原生孔偶见,但大部分原生孔都被后期的胶结物充填。大多数储层属于以次生溶孔为主的裂缝-孔隙型储层,孔隙连通性差,空间喉道细小,因而渗透率低,后期构造裂缝的形成对储层的渗透性具有重要意义,同时也造成了常规测井响应复杂,难以准确识别孔隙度与渗透率,测井电阻率普遍较高,储层之间直接对比测井曲线难以区分流体。通过数据挖掘,基于PSO优化的FCM算法,可以区分不同流体之间的细微差别,进而识别流体。选取自然伽马(GR)、声波时差(AC)、补偿中子(CNL)、深电阻率(Rt)、浅电阻率(Rs)、密度(DEN)等6条测井曲线,选取研究区12口井59个试采层段作为样本。

表1 测井参数权重
根据样本层各测井参数的流体指示系数(见图1),计算得到各测井参数的权重(见表1),进而得到样本数据矩阵。

图1 测井参数流体指示系数
图2是计算过程中适应度函数的取值,迭代7次后适应度函数取得稳定值,即得到最优解。
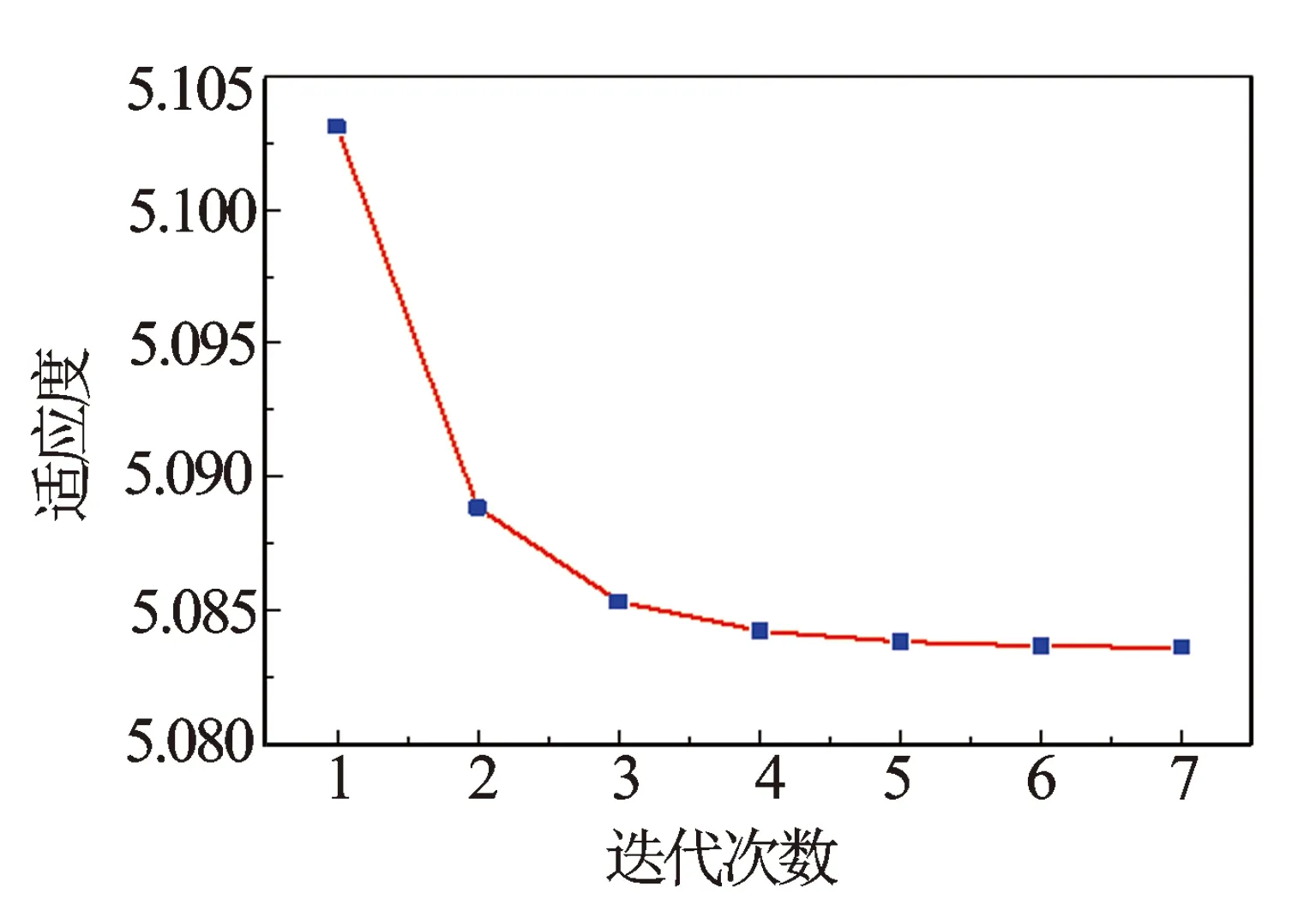
图2 适应度函数取值
图3是聚类分析初判效果,横纵坐标分别是标准化后赋权重的声波时差和浅电阻率数据。显示聚类中心与试采数据分布较吻合,聚类结果与实际情况相符。
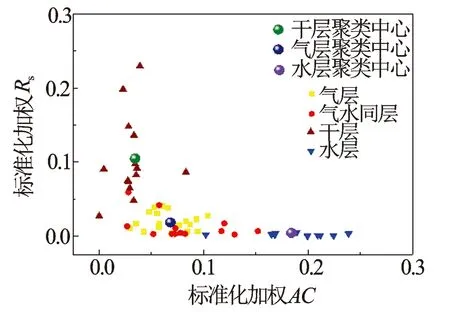
图3 PSO-FCM算法初判效果图
根据上述4类数据的气层概率和水层概率交会图,可得到流体识别阈值确定图版(见图4)。气层和气水同层的概率阈值T1=0.742,水层和气水同层的概率阈值T2=0.683。根据式(8)可确定研究区流体识别标准。
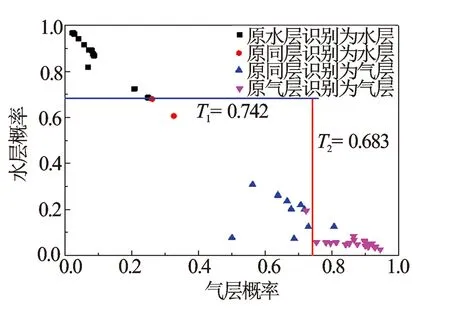
图4 流体概率阈值确定图版
利用上述识别方法对研究区59个试采层位进行回判,仅有4层与试采结论不一致,回判符合率达到93.2%。说明识别方法稳定性较好,可用于研究区其他层位的流体识别。
将识别方法应用于研究区非样本井的12口井的32个储层中,识别结果与试采结论对比,29个层识别结果与试采结论一致,解释符合率达到90.6%。
图5为研究区M19井流体识别测井解释成果。该井段储层特征明显,电阻率较高,补偿密度偏低,补偿中子偏低,具有典型的含气特征。应用该方法判定该储层为气层,2个层段酸化压裂改造后日产气3.49×104m。层段1是高电阻率碳酸盐岩背景下的溶洞发育层段,电阻率减小且成正差异,三孔隙度明显,但电阻率值仍接近100 Ω·m,解释为气层;层段2与层段1测井响应特征相似,但是正幅度差异弱,且GR值较高,溶洞带有泥质充填,产气量低于层段2。

图5 M19井流体识别成果图*非法定计量单位,1 ft=12 in=0.304 8 m,下同
3 结 论
(1) 基于流体指示系数的测井参数权重计算方法,提高了样本数据矩阵对流体变化的敏感性,进而对改善流体识别效果有帮助。
(2) PSO-FCM改善了FCM算法易受初值影响的不足,利用其计算流体概率,结合交会图法确定流体识别标准的方法,迭代次数少,解释符合率较高,为碳酸盐岩储层流体识别提供了有益参考。
(3) 该方法在川东北地区碳酸盐岩的流体识别准确率较高,对于该地区指导生产有一定作用,推广到一般碳酸盐岩储层的适用性需要结合实际进一步分析讨论。
