基于多层深度特征融合的行人再识别研究
2018-07-10张丽红孙志琳
张丽红,孙志琳
(山西大学 物理电子工程学院,山西 太原 030006)
0 引 言
行人再识别是指无重叠的多摄像头视角下行人匹配问题. 锁定的目标从一个摄像头下消失,当该目标在其它摄像头视角下出现时,系统仍能够依据其特征重新锁定. 视角、光照等变化使得同一行人在不同摄像机下的表观不同,提取稳定且有辨识度的特征难度较大. 行人再识别的主要目的是对不同监控场景的行人进行身份再认,以弥补现有单个摄像机的视觉局限,使得跨时空分析感兴趣目标成为可能[1]. 近几年,行人再识别在智能视频分析、智能视频侦查等公共安全领域应用广泛,已经被作为智能视频分析的一个新课题在计算机视觉领域受到了广泛关注. 光照、姿态、视角以及背景等变化会对行人图像造成较大影响,行人再识别仍然是一个极具挑战性的课题.
现有的行人再识别算法主要分为两类,一是基于度量学习的方法,二是基于特征的方法. 基于度量学习方法是利用机器学习算法得出两张行人图像的最优相似度度量函数,使相关行人图像对的相似度尽可能高,不相关行人图像对的相似度尽可能低,在候选库中找到与检索图像特征相似的图像,并依据相似度由高到低排列输出. 度量学习方法中有通过学习半正定矩阵参数化的马氏距离函数来分辨行人图像对[2],也有通过学习低位投影将行人再识别问题重新定义为子空间学习问题[3]. 基于特征的方法侧重于如何获得稳定且具区分性的特征,常用外貌特征有线特征、颜色特征、纹理特征等,其优点是计算简单、针对性强,缺点是容易受到光照等因素影响[4]. SIFT 等局部特征及步态等动态特征也可用于行人再识别,但动态特征获取复杂且需人工标注[5]. 发型、衣服颜色等是人可直接理解的高级属性特征,其对光照、遮挡、视角变化有较好鲁棒性,但受数据集分辨率低的限制,获取较难. 为了降低获取有效特征的难度并充分利用大部分特征包含的信息,本文采用多层深度特征融合的方法.
1 卷积神经网络
为了提取行人图像中更丰富和更稳定的信息,采用卷积神经网络来提取这些行人图像的深层次特征. 卷积神经网络是一种深度监督学习下的机器学习模型,它的权值共享结构网络使之具有极强的适应性,善于挖掘数据局部特征,提取全局特征和分类[6]. 典型的卷积神经网络由输入层、卷积层、池化层、全链接层、输出层构成,其结构如图 1 所示. 每一层有多个特征图,每个特征图通过一种卷积滤波器提取输入的一种特征. 使用卷积层的原因是通过卷积运算可以使原信号特征增强,并且减少噪音. 在池化层,根据图像局部相关性的原理对图像进行子采样,可以减少计算量,同时保持图像旋转不变性. 采用 softmax 全连接得到的激活值即卷积神经网络提取到的图片特征.
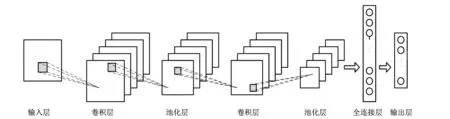
图 1 卷积神经网络结构图Fig.1 Convolution neural network structure
卷积神经网络各层提取到的特征向量维度比较高,不一致,且存在大量冗余信息,维度信息不仅会降低识别速度,而且会降低匹配的准确度. 我们用PCA对卷积神经网络的每一层进行降维,由于网络中每一层特征都包含大量信息,应合理利用,因此,将各层特征融合起来作为用于识别的图像特征,使其更具有表现力,包含更丰富的图像信息.
2 特征的PCA降维
数据集中行人图像在经过卷积滤波之后维数依然很高,高维空间中行人的有效信息分布不紧凑,不利于识别,须通过有效方式对各层图像特征进行降维,提取主要特征. 主成分分析(principal component analysis, PCA)目的是通过线性变换寻找一组最优的单位正交矢量基(即主成份),并用其中部分向量的线性组合来重建样本,使重建后的样本和原样本在最小均方差意义下的误差最小[7]. 这样既可实现对高维数据的降维,又可保持原始数据的大部分信息,具有计算代价小、描述能力强、可辨识度高等特点.
假设行人图像经过卷积之后构成了一个l×d维的图像特征矩阵,可以将图像矩阵向量化为n=ld维的图像向量X.M个特征向量样本组成训练样本矩阵Z={X1,X2,X3,…,XM},其中的每一列代表一个样本维度.μ为训练样本的平均向量,即
(1)
对训练样本Z减去平均列向量得到标准训练矩阵A=[X1-μ,X2-μ,…,XM-μ],训练样本的协方差矩阵为
(2)
对C求降序的特征值矩阵V=[λ1,λ2,…,λn](λ1>λ2>…>λn)及与之对应的特征向量P=[p1,p2,…,pn].λ为协方差矩阵的非零特征值,每一张行人图片可投影到由P张子空间中. 按照特征值所占的能量比例来选取最大的前k个特征向量作为子空间,为
(3)
取α=90%~95%,则W=[p1,p2,…,pk](k≤n),为求得的最优特征子空间.
Y=WTZ.
(4)
这样就将Z的原始维度降到了k维.
3 层间特征融合
深度卷积神经网络模型本质上就是将图片的信息在多层模型中进行逐层映射,在每一层都进行相应的映射特征提取. 在多层网络模型中,底层特征一般为图像中的结构信息,顶层特征则常为图像的抽象语义信息,因此,将各个层次的特征进行融合来进行最终的特征表达,比单纯使用顶层特征更全面、更准确、更具有表现力[8]. 如图 2 所示,本文方法采用特征级联的思想将各层子空间信息进行加权融合,得到更为全面的行人主成分信息.
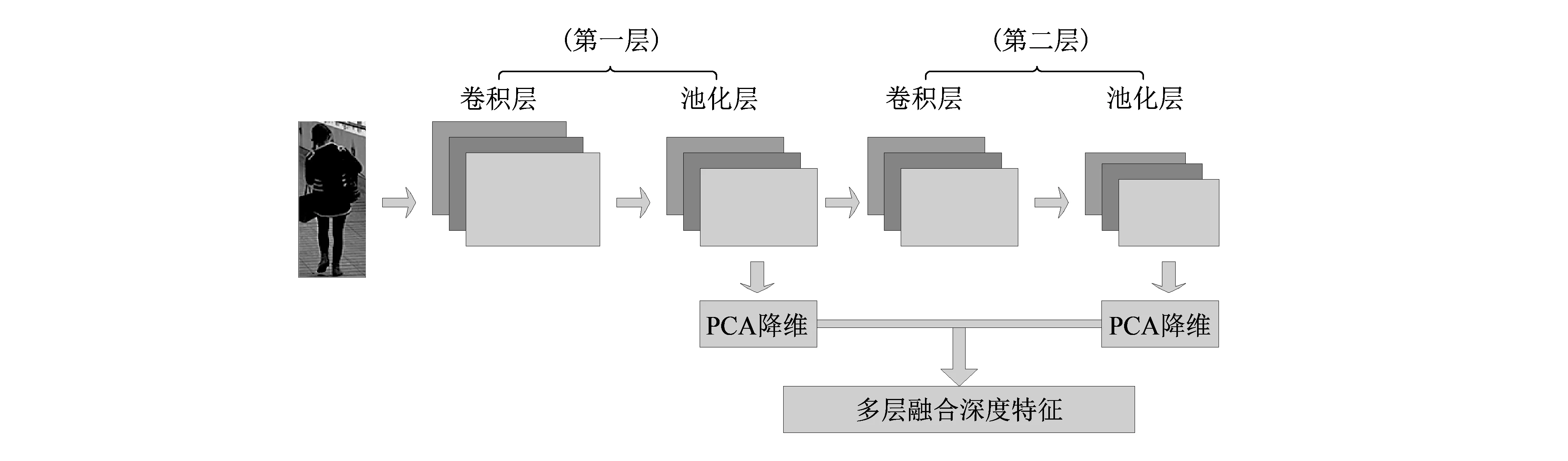
图 2 卷积神经网络多层特征融合Fig.2 CNN multi-layer features fusion
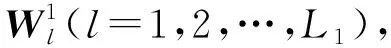
(5)
第二层映射子空间特征可表示为
(6)
将多层特征进行加权融合,得到融合的深度特征为
(7)
对于不同行人的A与B图像经过网络的多层特征融合,分别得到其深度特征FA与FB.
4 相似度度量及评价标准
计算待识别行人与候选行人图像库中每幅行人图片的相似度.d(x,y)是行人图像X与行人图像Y之间的欧式距离.
d(x,y)=‖x-y‖2,
(8)
式中:d(x,y)越小,说明两张行人图像越相似,即两张图像为同一行人的可能性越大.
行人再识别问题的结果度量准则一般都采用累积匹配特性(cumulative match characteristic, CMC)曲线进行度量,累积匹配特性曲线能够显示出结果样本数量的增加与其性能提升之间的关系[9]. 它表示了在前r次匹配中找到正确匹配项的期望. CMC曲线Rank-r识别率表示按照某种相似度匹配规则匹配并排序后,正确的目标行人排名在前r的比例. Rank-1表示首位命中率,Rank-5识别率就是指前五项(按照匹配程度从大到小排列后)有正确匹配.
给定包含M个样本的查询样本集,设T(t1,t2,…,r)是根据匹配度得到的N个测试样本的排序列表. 假设r是测试样本在排序列表T中的序号,累积匹配特性曲线按公式(9)得出.
(9)
5 实验及结果分析
在VIPeR数据集上评估本文方法进行行人再识别的准确性和鲁棒性. VIPeR数据集包含632位行人的1 264张图片,图片由两个视角不重叠的摄像机拍摄获得,其中大多数图像对包含较大的视角和光线等变化[10]. 我们随机地选取p位行人图像用作测试,其余行人图像用于训练. 实验时,视角A下的图像作为查询库,视角B下的图像作为候选行人库,查询图像与候选行人库中的每张图像进行比较,得到相应的匹配排名,然后交换查询库和候选行人库再次测试. 为了获得稳定的识别率,测试过程重复10次,并将平均值作为实验结果.
表 1 将本文算法与已有的行人再识别算法在VIPeR数据集(测试集规模为316)上进行对比. 与其他方法相比,本文方法在四项指标上均表现出了较好的效果. 本文方法的Rank-1匹配率比基于MFA方法上升了9.07,Rank-5匹配率和Rank-10匹配率分别上升了4.47,0.74. 这表明,与通过手动设计稳定特征的算法相比,本文使用最简单的相似度度量准则,仍可从行人图像中获取全面深度的特征信息.
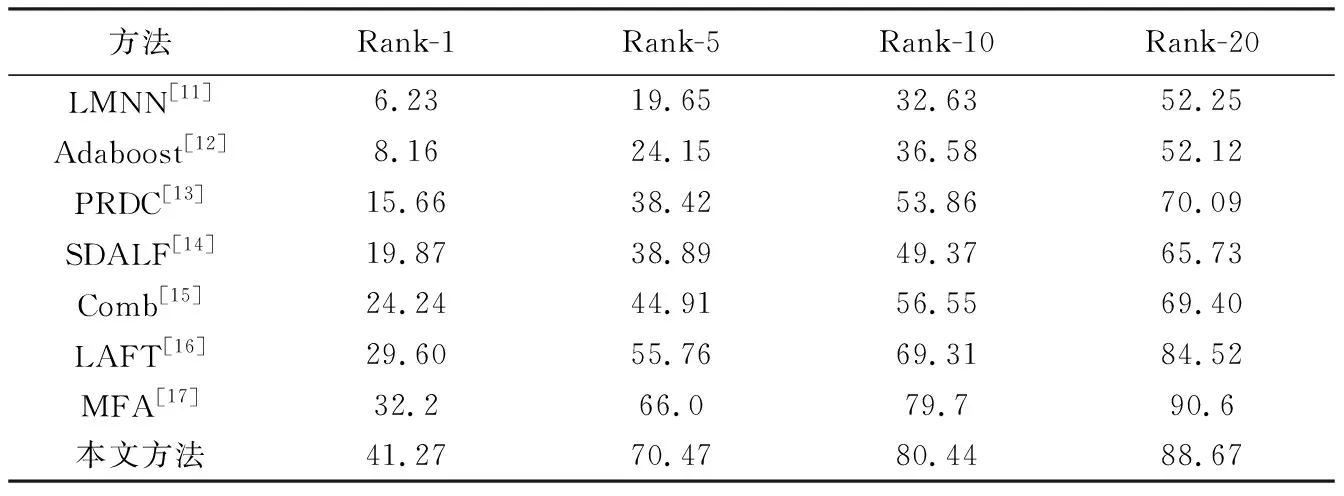
表 1 实验结果对比
表 2 为不同规模测试集上本文方法的识别准确度.

表 2 测试集不同规模对性能的影响比较
当测试集规模为p=316时,Rank-1匹配率为41.27. 当测试规模为p=432和532时,累积匹配率依次整体下降.p=432时,Rank-1匹配率较p=316时下降了0.38,p=532时Rank-1匹配率较p=316时下降了2.48. 这表明,在VIPeR数据集上,测试集规模大小对识别性能有较大影响.p取值越大,即测试样本越多,训练样本越少,训练和匹配都变难,容易造成过拟合现象,使得结果不具有泛化性.
6 结束语
本文利用卷积神经网络对行人图像进行处理,并对网络各层的深度特征主成分分析后将其融合作为再识别的特征依据,采用欧氏距离进行相似度匹配. 实验结果表明: 在VIPeR行人图像数据集上,该方法在只使用欧氏距离分类器进行分类的情况下,对于存在光照、角度、遮挡等干扰的数据图像仍能够达到较高的识别率,并且相对于单层特征提取模型具有更高程度的中层特征提取能力.
