企业级大数据平台框架设计方法研究
2018-07-06尹航谢汶姝刘俊涛喆单崇何枫
尹航,谢汶姝,刘俊涛喆,单崇,何枫
(1.北京宇航系统工程研究所,北京100076;2.中国人民解放军91515部队,海南三亚572000;3.航天新长征大道科技有限公司,北京100070)
0 引言
大数据技术的发展给企业数据应用和价值提升带来了前所未有的新局面,越来越多的企业引进大数据技术,在业务战略指引下,识别业务需求并评估数据分析能力,从现有的和新的数据来源中获取新的洞察力,挖掘新的价值攀升空间,实现企业发展战略[1]。本文针对大数据技术在企业级的应用,提出了一种大数据平台框架设计方案,目的是对企业内部现有的多个应用系统进行整合升级,为企业数据的应用提供新的手段,同时为企业规划大数据架构设计、关键技术攻关、数据处理和分析方法提供一些借鉴。
1 系统组成
大数据平台的系统组成如图1所示。大数据平台包括分布式文件系统、分布式数据库、关系型数据库、分布式计算框架、数据服务平台和平台管理监控6个部分。大数据平台的数据源由数据采集平台提供,同时为企业级上层各业务应用系统提供数据管理、处理与分析手段,提供数据挖掘、数据可视化及数据深度应用的大数据增值服务。

图1 大数据平台系统的组成
2 系统功能
系统各部分提供的主要功能如下:
①分布式文件系统:提供稳定可靠的分布式存储、数据的多冗余备份、不同服务器间负载均衡及存储空间的水平扩展功能;
②分布式数据库:实现基于多服务器的分布式数据库系统,提供分布式数据库WebService形式的访问接口及数据库的水平扩展、负载均衡和故障恢复能力;
③关系型数据库:提供常用关系型数据库,支持ODBC/JDBC等接口,提供数据库备份服务;
④分布式计算框架:提供对大数据量的数据分块、计算任务调度、数据与任务相互定位功能,实现“分而治之”计算模式,同时提供计算任务优化及故障处理机制,保障分布式计算的有效性;
⑤数据服务平台:提供分布式算法库、数据库基础接口和WebService形式的数据访问接口;
⑥平台管理监控:提供对大数据硬件集群的监控与大数据平台服务的监控。
3 系统设计
3.1 分布式文件系统
分布式文件系统将文件分布存储在多台服务器的存储空间中,通过统一的接口对外提供文件系统服务,包括文件打开、关闭、读取及写入等。分布式文件系统能够自动实现数据的多冗余备份、虚拟机节点的故障检测与恢复以及负责均衡和水平扩展。这些功能对用户完全透明,用户可以按照访问本地磁盘的方式来使用分布式文件系统,同时能够得到高质量的文件服务。分布式文件系统的结构图如图2所示,具备以下能力。
(1)具备冗余备份能力
文件系统将文件分块存储在多个数据节点中,存储的同时为每一个文件块生成2个备份(共3份),3份文件块分别存储在不同的数据节点中,即使有2台服务器同时发生故障也不影响任何文件的完整性和正确性。
(2)具备故障检测与恢复能力
管理节点通过数据节点发送的心跳数据感知其运行状态,当某个节点发生故障,管理节点将切断与该节点的连接关系,不再让其执行文件访问操作,并认为其中存储的数据已经丢失。此外,文件系统会定期检查文件的备份情况,当由于节点故障而导致备份丢失时,文件系统会再将文件备份到其他节点上,以保持数据同时在3个节点存储的状态。
(3)具备负载均衡与水平扩展能力
文件系统定期检查各节点存储空间的负载情况,当某些节点负载率过高或过低时,文件系统将自动执行负载均衡,将文件块移至负载率较低的节点上。当文件系统中有新的数据节点加入时,系统会利用负载均衡机制,将一些文件块移至新的数据节点,实现存储空间的水平扩展。

图2 分布式文件系统
3.2 分布式数据库
分布式数据库用于存放半结构化的业务数据、数据分析与挖掘的中间数据。分布式数据库底层基于分布式文件系统构建,继承其具有的可靠性、高性能和可扩展性。同时,分布式数据库采用面向列的存储架构,可以对TB级记录进行快速随机查询与筛选,同时支持异构数据的管理,可灵活适应数据结构的变化。为了使数据便于分析和挖掘,系统需将原始数据进行预处理,以提高特定算法执行速度。利用分布式数据库可存储数据预处理的结果,加快分析挖掘算法的数据访问速度,分布式数据库结构如图3所示。
分布式数据库基于分布式文件系统构建,集成了文件系统的冗余和扩展机制:
①利用分布式文件系统存储多个复本的元信息,利用Zookeeper选举机制实现管理节点的多机备份[2];
②利用分布式文件系统存储数据表的多个副本,实现数据的冗余存储;

图3 分布式数据库
③数据库表到达一定规模后会根据Key值自动分裂,分布到多个节点,实现负载均衡。
该平台的分布式数据库实现数据库镜像机制,创建镜像时,数据库能够保存信息的副本,并对元信息指向的全部底层文件进行保护,防止文件在后续操作中被删除或移动。通过镜像机制,能够在数据库损坏时恢复到某一时刻的状态。
3.3 关系型数据库
大数据平台提供关系型数据库,用以存储基础数据、管理数据及建模数据。该平台是基于MySQL提供关系数据库服务的。MySQL是最流行的关系型数据库管理系统之一,在Web应用方面,MySQL是较好的一款关系数据库管理系统(Relational Database Management System,RDBMS)应用软件[3]。MySQL支持ODBC/JDBC等接口,提供数据库备份服务。在大数据平台安装了ODBC/JDBC驱动,在权限控制允许的范围内,为上层应用信息系统提供读取、写入和操作关系型数据库的接口。
大数据平台提供的MySQL关系型数据库实现了数据库的冗余备份。冗余备份的工作原理是使用2台服务器,一台作为主服务器,运行应用系统来提供服务;另一台作为备机,安装完全一样的应用系统,但处于待机状态。当主服务器出现故障时,通过软件诊测将备份机器激活,保证应用在短时间内恢复正常使用。
作为主服务器Master,会把自己的每一次改动都记录到二进制日志Binarylog中。作为从服务器Slave,会用主服务器Master上的账号登陆到Master上,读取Master的Binarylog,写入到自己的中继日志Relaylog中,然后自己的Sql线程会负责读取这个中继日志,并执行一遍,主服务器上的更改就同步到从服务器上了。在MySql上可以查看当前服务器的主从状态。即当前服务器的Binary状态和位置,以及其RelayLog的复制进度。
3.4 分布式计算框架
分布式计算框架是一种新的编程模式,它主要的思想是“分而治之”。大数据平台通过Map和Reduce这2步实现任务在大规模计算节点中的调度和分配[4]。分布式计算框架由3个模块组成,分别是客户端、主节点和工作结点。客户端用于将用户撰写的并行处理作业提交给主节点,再由主节点自动地将用户作业分解为Reduce任务和Map任务,并将任务调度到工作结点上,工作结点向主节点请求执行任务,同时多个工作节点组成的分布式文件系统用来存储输入和输出数据,分布式计算框架的结构如图4所示。
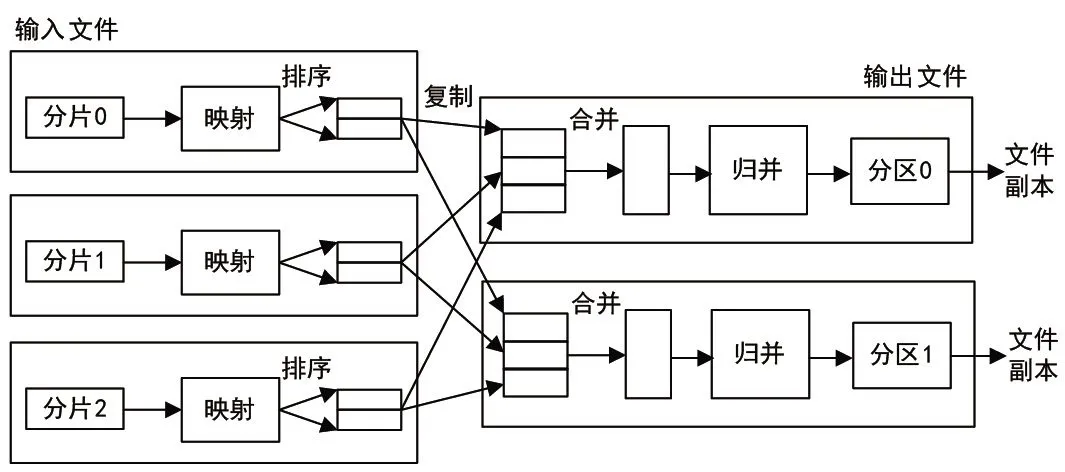
图4 分布式计算框架
分布式计算框架模型的主要优点就是它的高度抽象性,体现在映射函数Map、聚集函数Reduce和键值对<key,value>3个核心概念上。Map函数和Reduce函数对一组输入的键值对(key/value)进行计算,得出另一组输出键值对,即

由式(1)可知,用户定义的映射函数Map的功能是接收一组输入键值对 <key,value>,即(K1,V1),经过处理产生一组中间的(K2,V2)键值对,分布式计算框架函数库聚合所有相同的中间键K2的相应值,产生关于K2键的值集合list(V2),这个处理过程称为“分组",在形式上可以认为具有相同key值的Value处在同一个组中。接下来再把处理得到的这个新键值对发送给由用户提供的归并函数Reduce;由式(2)可知,Reduce函数的功能是:读入新的键值对(K2,list(V2)),再进一步处理、合并该中间键的值集合,最后形成一个相对较小的键值对集合list(K3,V3)。该处理过程称为“合并”,它不仅是简单的累加过程,还包含具有很强依赖关系的复杂运算。
3.5 数据服务平台
数据服务平台以分布式计算框架为支撑,向上层应用提供数据访问和处理服务。该平台采用模块化组件开发,按功能可分为分布式数据检索模块、分布式数据处理模块、分布式数据分析模块及分布式数据挖掘模块等几方面内容。企业需根据应用系统具体业务需求对该平台进行功能开发。例如针对运载飞行器测试数据分析与评估应用需求,该数据服务平台开发了以下功能:
(1)分布式算法库
提供数据处理、分析、挖掘算法的分布式算法库,将复杂算法转化为可由分布式计算框架直接执行的分布式算法。算法主要包括数据转换算法、多维数据分析算法、关联分析算法、回归算法、分类算法及聚类算法等[5]。
(2)任务处理模块
任务处理模块将各应用的数据处理请求转化为实时或后台处理任务,并对后台处理任务进行调度和控制。其处理的任务包括生成数据物化视图、数据预处理、数据挖掘及统计分析等[6]。
(3)数据访问接口
向上层应用提供基于WebService的数据访问和服务访问接口,接口包括测试数据访问接口、文件访问接口及业务内容查询接口等。
3.6 平台管理监控
平台管理监控以Web服务方式提供大数据平台的维护管理功能,在该项目中,平台管理监控系统提供了2个方面的监控服务:①对大数据硬件集群的监控:包括硬件服务器节点管理、集群运行状态管理、服务器CPU、内存及网络运行情况实时监测等;②对大数据平台服务的监控:包括对Hadoop平台进程监控、虚拟机运行状态监控、分布式文件系统对CPU、内存、网络资源占用率监控以及数据备份、系统扩展和故障恢复情况的监控等。
4 平台实施部署
以大数据平台实施途径和部署方式为例,平台的整体架构及技术选型如图5所示。平台的部署采用10台云计算服务器搭建集群,具有数据中心管理服务、大数据存储服务、关系型数据库服务、数据分析挖掘服务、数据库备份服务及Web服务等功能。在大数据平台基础上,运行了平台管理监控系统、全寿命周期信息管理系统、测试数据分析系统及大数据分析与挖掘系统等应用。
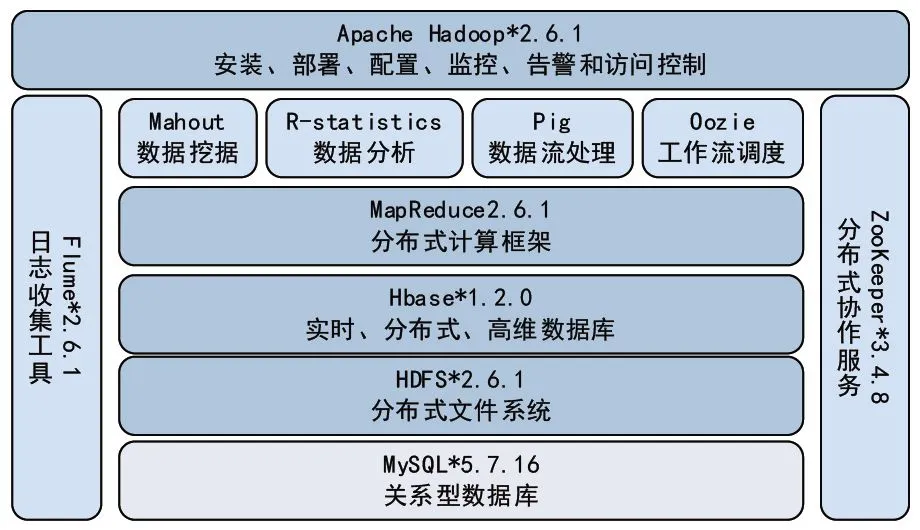
图5 大数据平台整体框架及技术选型
5 结束语
本文从传统的企业级应用系统向大数据技术背景下多应用系统融合升级需求出发,介绍了企业级大数据平台框架设计方法,从系统组成、系统功能、系统设计及实施部署等几个方面进行论述,该方法可实现稳定可靠的分布式存储、分布式数据检索、分析、处理与挖掘的数据服务,以及对平台软硬件运行的监控。借鉴已有项目实施经验,基于10台云计算服务器集群,给出实施部署示例,针对大数据企业级多系统应用底层构架设计提出可行方案,具有一定的应用创新性,为企业级应用系统集成的基础平台建设提供借鉴
[1]赵刚.大数据:技术与应用实践指南[M].北京:电子工业出版社,2013.
[2]Junqueira F.Zookpeeper:Distributed Process Coordi-nation[M].O'Reilly Media,2013:210-333.
[3]卢湘江,李向荣,宴子.MySQL高级配置和管理[M].北京:清华大学出版社,2001:8-9.
[4]Dean J.Ghemawat S.MapReduce:Simplified Data Processing on Large Clusters[J].Communications of the ACM,2008,51(1):107-113.
[5]Han Jiawei,Micheline K.数据挖掘概念与技术[M].范明,孟小峰,译.北京:机械工业出版社,2007.
[6]Rajaraman A,Ullman J D.大数据:互联网大规模数据挖掘与分布式处理[M].王斌,译.北京:人民邮电出版社,2012.
