基于歌曲标签聚类的协同过滤推荐算法的研究
2018-07-05赵宇峰李新卫西安工业大学计算机科学与工程学院陕西西安710021
赵宇峰 李新卫(西安工业大学计算机科学与工程学院 陕西 西安 710021)
0 引 言
随着近几年来移动互联网的发展,智能手机变得越来越普及,智能手机这种随时随地上网的特性使得数据量爆炸式的增长,随之而来的是数据怎样才能供用户消费,怎样提供用户感兴趣的信息,成为了一个需要迫切解决的问题。搜索引擎作为一种用户主动查询信息的模式已经变得越来越被动,它只能提供用户主动需要的信息,而不能挖掘用户潜在感兴趣的信息并提供。而推荐系统恰好能够做到根据用户的行为挖掘用户感兴趣的内容并推荐给用户[1]。
1 传统算法介绍
目前应用比较广泛的推荐算法包括基于内容的推荐、协同过滤推荐和混合推荐三种,其中协同过滤推荐算法应用最为成功,协同过滤推荐算法也是最早被提出的[2]。基于内容的推荐算法源自于信息获取领域,通过对推荐对象内容中的特征提取并计算出推荐对象的内容相似度进行推荐。这种推荐算法简单直观、容易理解、不需要领域知识,但它只能处理文本内容,像视频、歌曲这种信息就不能够通过分析内容进行推荐,即使可以分析视频图像和音频信息也非常费时,可行性不强。协同过滤推荐算法又分为基于用户的协同过滤(User-CF)和基于商品的协同过滤(Item-CF)[2]。
2 相关工作
2.1 传统基于用户的协同过滤推荐算法
传统的基于用户的协同过滤推荐算法是通过与此用户兴趣最相似的几个用户,然后从这几个相似兴趣用户中推荐用户没有听过的歌曲。具体方法是通过用户相似度算法找到每个用户最相似的一些用户,再汇总相似用户听歌记录,从其中找出目标用户没有听过的歌曲,再根据相似用户的相似度来排序,求得每一首歌的偏好度,对这些歌曲进行排序,从而给目标用户进行推荐[4]。具体的算法步骤如下:
(1) 构造用户- 歌曲数据表示矩阵。行向量表示用户,列向量表示每一首歌曲,矩阵值表示用户是否听过此首歌曲,0代表没有听过,1代表听过,它是一个0-1矩阵。
(2) 生成最近邻居集。根据用户- 歌曲矩阵使用用户相似度算法进行用户相似度计算,从而找到与目标用户最近的用户集。
(3) 产生推荐。找出离目标用户最近的几个用户中目标用户没有听过的歌曲,并统计这些歌曲的个数,然后通过这些歌曲中每个歌曲的个数与用户相似度相乘,从而得出此歌曲的推荐值,最后将每个歌曲在每个用户中推荐值统计求和,排序推荐值最高的几首作为目标用户的推荐结果。
2.2 传统算法的不足
传统的基于用户协同过滤算法是对所有的用户进行计算并求相似用户,现在一个音乐系统的用户高达几亿,计算起来效果很差,而且很多用户都是相似度很低的,不需要进行计算。为了解决这个问题,可以先对用户进行聚类,使相似的用户归为一类再进行协同过滤,使计算量大大降低。0-1矩阵只表示了用户是否听过这首歌,而不能表示用户对这首歌的喜好程度,对用户的分类效果较差。
2.3 引入k-means聚类优化推荐算法
聚类是在没有人工标注的基础上,将具有相似属性的数据聚集到一起的无监督学习方法,它使具有相似性的数据集中到一起,处于同一组内数据具有相似性,处于不同组内的数据彼此不同。本文改进的协同过滤推荐算法就是在相似度高的用户基础之上进行推荐,使得算法具有更好的推荐效果。相似计算直接制约着聚类效果的好坏,从而影响到最终的推荐结果。算法原理如下:假定有一组用户User,用户总数是m,记作U(U1,U2,U3,…,Um),每个用户Ux都有n个属性,记作Ux(Cx1,Cx2,Cx3,…,Cxn),聚类的原理就是在集合User的基础上对比每一个属性,完成相似用户的分组。k-means算法核心思想就是将给定的一组用户User分为k组,每组都设定一个聚类中心,计算每个数据离此中心的距离,距离最小的归为此组[6]。具体步骤如下:
(1) 用户兴趣标签模型建立[8]。模型从用户听歌日志出发,最终定位用户的兴趣标签,步骤如图1所示。

图1 用户兴趣标签建模步骤
用户听歌日志采集,在此测试算法中只取部分用户作为数据集,大约有2 000用户,听歌记录10万条左右,格式如表1所示。

表1 用户听歌记录
歌曲标签表示了此歌曲的类型。本文使用的数据集中,歌曲标签的初始标签是歌曲上传者添加的,听歌用户也可以自行添加描述标签,数据格式如表2所示。

表2 歌曲标签表
用户兴趣标签,这一步就只将用户听过的歌曲的标签映射到用户兴趣属性列上,如表3所示。

表3 用户标签模型
标签值表示此用户听歌记录中此标签的出现次数。考虑到用户某一天内对某一标签的集中行为有可能会拉偏此用户的兴趣点,因此添加了tag数量的衰减因子[5],衰减因子计算公式如下所示:
I(u,t)=log(1+c(u,t))
(1)
式中:c(u,t)表示用户u中标签t的数量,从而得到用户标签矩阵U-T,如表4所示。

表4 用户标签矩阵
(2) 生成聚类。对U-T矩阵进行k-means算法聚类,聚类中心随机选取k个,距离函数使用欧式距离进行计算。计算每一个用户向量到k个中心点的距离,然后将此用户归类到距离值最小的中心点,所有用户计算完一次后再对每一类坐标求平均,得到新的k个中心点,再迭代计算直到中心点不变或变化小于设定的阈值,则聚类结束。
(3) 对得到的k个用户类中每一类都使用基于用户的协同过滤算法计算推荐结果。
2.4 k-means聚类算法改进[6]
(1) 游离点的去除。在所有数据点中,游离点是那些与其他所有点距离较远的点,它们的存在会导致所属类中中心点的偏离,从而影响到分类的效果。本文去除游离点的过程如下:
设用户总数为m,所有用户到其他用户的总路径条数为:
(2)
则所有用户之间的距离和为:
(3)
gap(Ci,Cj)=
(4)
式中:Ci1,Cj1,…,Cin,Cjn是用户Ci与Cj的n个属性。根据L和D求距离平均值:
(5)
式(5)为所有用户距离的平均值,对每一个用户U计算出与其他所有用户的距离LU=(Ui,Uj),如果所有的LU≥EMV,则把此用户归为游离点,单独一个分类,如果游离点的个数较少,则无法分为一类进行协同过滤,这样可以将它分到距离某类中心点最近的类。
(2) 随机点的选取对分类结果也会产生影响,会陷入局部最优解。为了解决此问题,本文所采用的方法是采用聚类的改进算法:二分聚类。二分聚类的思想是:首先将所有点作为一个簇,然后将该簇一分为二(k=2的k-means聚类),之后选择能够最大限度降低聚类代价函数的簇再次进行一分为二,直到聚类个数等于k结束。聚类代价函数定义为聚类的误差平方和,如式(6)所示,某个类的误差平方和最大,就说明此类中的点距离中心点的距离之和最大,就需要对此类进行再一次划分。
(6)
3 实验和评价
在数据集一样的情况下,分别对传统基于用户的协同过滤算法、引入k-means聚类后的推荐算法和改进聚类后的推荐算法三种算法进行了多次重复试验,并选取相对稳定的结果数据进行对比分析。
3.1 数据集
本实验采用的数据是从网络上采集来的,包括用户名、用户听歌记录和歌曲标签数据,取其中2 000名用户,听歌记录近10万条,标签数据730条构成数据集进行试验。实验环境:Intel i5-4590 处理器,主频3.30 GHz,内存8 GB,windows7 64位操作系统,PyCharm编程环境,python2.7。
3.2 评价指标
评价指标使用准确率(Precision)和召回率(Recall),对每一个用户的听歌记录时间进行降序排序,采用前80%作为训练集,后20%作为测试集进行实验评价。
式(7)和式(8)分别为准确率(Precision)和召回率(Recall)的计算公式[2,7]。
(7)
(8)
3.3 三种算法的对比
对三种算法分别计算出不同分类个数k值时的准确率与召回率,变化关系如图2、图3所示的折线。
如图2所示,引入k-means聚类算法后准确率要比传统的基于用户的协同过滤算法要好一些,当k值为4的时候,准确率提高0.65%左右,为最好分类。而对聚类算法进行优化后,k值为5的时候,准确率比未优化时提高近0.15%。

图2 三种算法的准确率随分类个数k的变化图
图3是三种算法的召回率变化图,引入k-means聚类算法后准确率要比传统的基于用户的协同过滤算法要好,当k值为4的时候,召回率能够提高0.65%左右。而对聚类算法进行优化后,当k值为5的时候,召回率又增加近0.15%,但当k值增大时,优化后的聚类又会比未优化的聚类算法低,当用户量一定时,去除游离点后,每个分类均受影响,有的分类个数非常少,推荐结果就不准确,从而影响整体推荐算法效果。
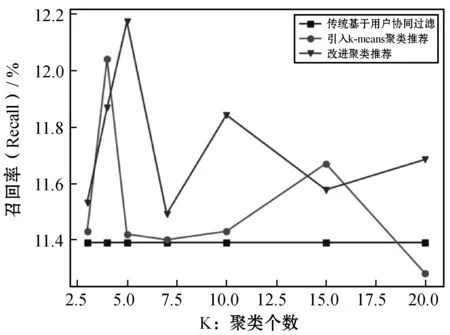
图3 三种算法的召回率随分类个数k的变化图
4 结 语
为了提高推荐结果的准确率和召回率,本文先对用户进行聚类,根据用户听歌曲的标签进行分析,建立了用户- 标签模型,进而使用k-means聚类对用户进行聚类,从而兴趣品味相近的用户分到了一组,分组后再使用协同过滤算法进行推荐排名,使用户的兴趣分组更加准确,从而推荐效果更好,也使得系统过滤推荐的计算量降低,从而有更好的性能与结果。最后,算法使用从网络上采集到的真实数据进行试验,实验结果表明,经过改进优化的推荐算法比传统的基于用户的协同过滤算法在准确率和召回率上都有明显的提高。
[1] 刘旭东,陈德人,王惠敏.一种改进的协同过滤推荐算法[J].武汉理工大学学报(信息与管理工程版),2010,32(4):550- 553.
[2] 王国霞,刘贺平.个性化推荐系统综述[J].计算机工程与应用,2012,48(7):66- 76.
[3] 秦雨,余正涛,王炎冰,等.基于特征映射的微博用户标签兴趣聚类方法[J].数据采集与处理,2015,30(6):1246- 1252.
[4] 荣辉桂,火生旭,胡春华,等.基于用户相似度的协同过滤推荐算法[J].通信学报,2014,35(2):16- 24.
[5] 常晓雨,余正生.引入时间衰减项的兴趣点推荐算法[J].杭州电子科技大学学报(自然科学版),2016,36(3):42- 46.
[6] 吴泓辰,王新军,成勇,等.基于协同过滤与划分聚类的改进推荐算法[J].计算机研究与发展,2011,48(S3):205- 212.
[7] 朱郁筱,吕琳媛.推荐系统评价指标综述[J].电子科技大学学报,2012,41(2):163- 175.
[8] 陈洁敏,李建国,汤非易,等.融合“用户- 项目- 用户兴趣标签图”的协同好友推荐算法[J].计算机科学与探索,2018(1):92- 100.
