基于机器学习的骨干网路由参数模型构建方法
2018-07-03郝铮李晓良赵培尹长川
郝铮,李晓良,赵培,尹长川
(1.北京邮电大学信息与通信工程学院,北京 100876;2.中国移动通信集团设计院有限公司,北京 100080)
1 引言
以WDM(Wavelength Division Multiplexing,波分复用)/OTN(Optical Transport Network,光传送网)为主导的光传送网作为基础承载网络,为大颗粒业务、数据网和移动网提供了透明灵活的承载平台。随着国家“宽带中国”战略工程及战略方案的逐步推进实施,我国宽带网络基础设施建设已进入高速发展时期,骨干网规模呈几何级数增长。传统的网络设计是以CAD和EXCEL表格为基础的。CAD数据是非结构化的,受幅面影响,表达内容有限,难以查询和统计;EXCEL数据不规范,难以统一管理,易错难审校,且数据间的关联关系通过公式和引用实现,易错且效率低下。随着网络规模的不断扩大,网络资源数据的不断增长,以人工方式对网络进行规划优化和运营维护的速度和效率已经陷入瓶颈,网络规划设计工作的软件化、工具化和自动化已经势在必行。
但是,传送网规划,尤其是WDM/OTN的路由选择和资源分配工作,需要针对网络整体做多目标设计,要根据网络资源、业务情况灵活地配置。如何能让不具备通信方面的专家级知识、缺乏网络规划经验的计算机程序设计人员编写出能够紧密结合业务与网络发展情况,充分考虑网络规划整体思路、工作流程与业务需求的网络规划工具软件,是一个非常具有实际应用价值并且富有挑战的问题。
2 骨干传送网路由规划简析
骨干传送网规划通常是在多约束、多需求的条件下的决策过程。规划工作的约束性体现在,网络的传输技术、现网拓扑结构、容量限制等会对业务电路的配置起到制约和限制作用;需求性体现在,网络规划建设是业务驱动的,电路规划的根本目的是要满足承载用户的需求。如图1所示,如果将规划过程看做一个决策函数,那么网络的约束和业务的需求都可以作为输入参数传入,而决策函数的输出即是优化或最优的网络规划。
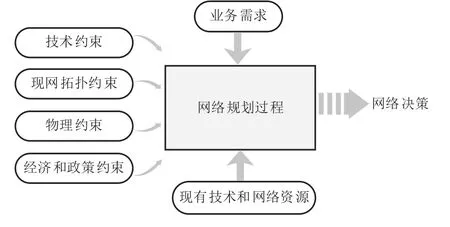
图1 网络规划决策函数
一般来说,规划过程约束因素主要有:技术约束、现网拓扑约束、物理约束、经济和政策约束等。另外,网络规划还会受业务的实际需求影响,主要包括:带宽需求、保护方式和QoS等。
在路由选择和资源分配中,通常使用网络费用或其他性能参数(例如可扩展性、可靠性等)作为目标函数,最终做出的路由规划决策应当是在给定约束下以最小代价满足传输需求。不过,有时难以量化所有的技术标准和设计约束,对于一个结构复杂的网络,过于理想化的自动规划设计方案,往往会使规划问题得到多个满足条件的解。另外,实际的路由规划决策往往依赖于设计人员的经验,其决策过程很难准确详实地传达给软件开发人员,也很难被抽象为逻辑程序,所以在此类软件的设计研发过程中,难免会遇到设计决策难以软件化的情况,软件开发人员与网络设计人员之间存在着“信息鸿沟”。
针对这种问题,本文提出以机器学习分类算法为工具,从历史设计决策中提炼各约束因素权重系数,构建路由参数模型,从而实现路由选择的智能化。
3 骨干传送网的资源数据和历史路由数据
一般来说,骨干传送网的资源数据可以分为三个层级:传输局站层、复用段层、波长层,其关系如图2所示:

图2 骨干传送网资源数据层级
除了基础资源数据,还需要建立一套用于描述业务需求与规划结果的数据结构,至少应包括以下几部分:
(1)业务光通路需求。即骨干网中大业务颗粒的光通道业务需求,主要包含光通道编号、起始节点局站、带宽需求、保护方式和业务类型等属性。
(2)路由。一个路由对象对应了一条完整的规划好的链路,但它不描述具体的路由链路内容,只描述路由的基本信息,主要包括所属光通道是工作路由还是保护路由等属性。
(3)路由链路段。描述一条路由中的一段链路,主要包括所属路由、链路序号和使用波道等属性。
4 网络数据的预处理
为了使网络的资源数据、需求数据和规划结果数据转变为适合机器学习的样本,需要对其进行预处理工作。如图3所示,本文提出利用原始数据,生成两类样本数据:拓扑影响样本和资源影响样本。
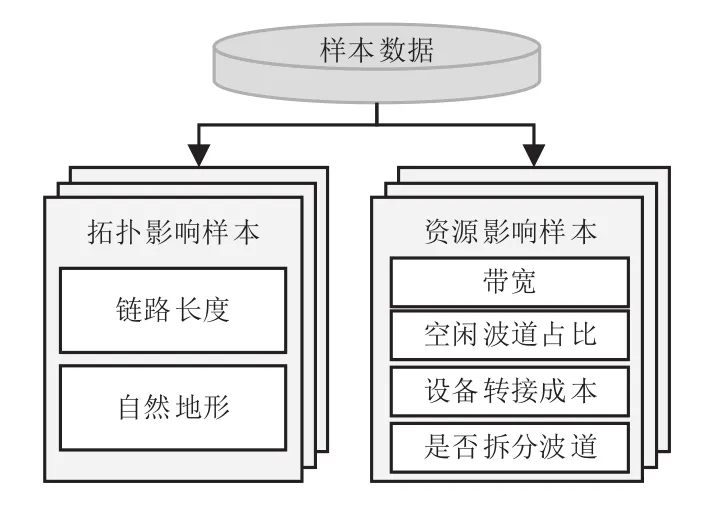
图3 样本数据的组成
其中,拓扑影响样本主要描述了链路长度、自然地形等拓扑特性对决策的影响,以拓扑特征作为属性,以选择结果作为分类标签。形象地讲,拓扑影响可以类比为道路交通中的道路方向、长度、坡度等特性,即“朝什么地方走”。
资源影响样本主要描述了链路中带宽、空闲波道占比、设备转接难度、跨域成本和是否需要拆分波道等资源特性对决策的影响,以资源特征为属性,以选择结果为分类标签。资源影响也可以与道路交通类比,它相当于在选定了“朝什么方向走”后,该选择什么样的交通方式走过去,即“该怎么走”。
基于上述分类原理,结合将规划人员路由决策参数化这一指导思想,本课题提出按照以下思路进行数据预处理:
(1)历史路由的每一条链路的光纤复用段对应一组样本数据,该样本包含了此决策的业务需求数据以及该光纤复用段的资源信息,并以此作为资源影响样本的属性,由于该光纤复用段是被最终选定用于路由的,所以分类标签置为1。
(2)对于同局站段下没被选择的每条复用段,也将其整理成为一组资源影响样本,其分类标签置为0,表示未被选择。
(3)历史路由的每一条链路的局站段对应于一组样本数据,该样本包含了此决策的业务需求数据以及该链路的拓扑信息,并以此作为分类样本的属性。由于该局站是最终选定用于路由的,所以分类标签置为1。
(4)设(3)中所述被选中的局站段起始端局站为A站,终止端为B站,则路由行至A站时会有一条或多条局站段可以选作下一跳链路,没被选择的每一条局站段即可生成一组拓扑影响样本,其分类标签置为0。
以中国移动十一期工程网络数据为例,选取若干比较典型的影响因素进行数据预处理,拓扑影响样本与资源影响样本的表结构如表1和表2所示:
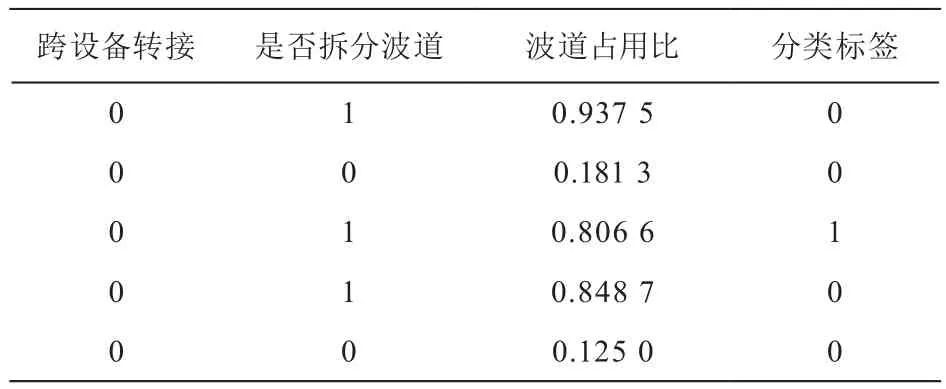
表1 拓扑影响样本示例
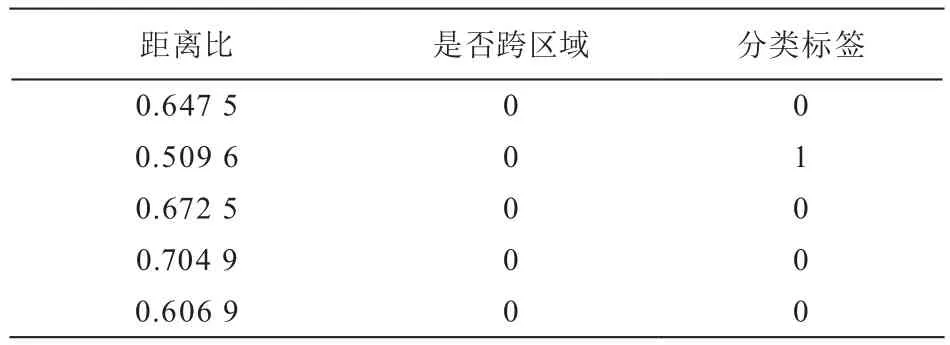
表2 资源影响样本示例
5 机器学习分类模型仿真及性能分析
5.1 朴素贝叶斯分类器基本原理及模型构建
贝叶斯分类器(Bayes classifier)是一种基于贝叶斯决策论的分类器,是概率框架下实施决策的一种典型算法。其基本思想是基于样本和分类标签,利用贝叶斯定理求解使后验概率最大化的参数模型。
假设有N种可能的分类标签,记为Υ={c1, c2, ……,cN},样本记为x,则令后验概率最大化的贝叶斯分类器为:

在实际应用中,常常假定样本具有“属性独立性”,从而可以将联合条件概率的求解简化为每个属性条件概率的乘积,这就是朴素贝叶斯分类器。
基于朴素贝叶斯分类器,可以构建波长路由的拓扑决策和资源决策概率参数模型。采用无监督的等深分箱法将连续型数据离散化,然后将样本数据采用朴素贝叶斯分类算法进行分类器参数计算,可以得到对应于所有属性及分类标签,即P(xi|c)及P(c)。表3展示了距离比(DIST_RATIO)这一拓扑影响因素的参数模型:
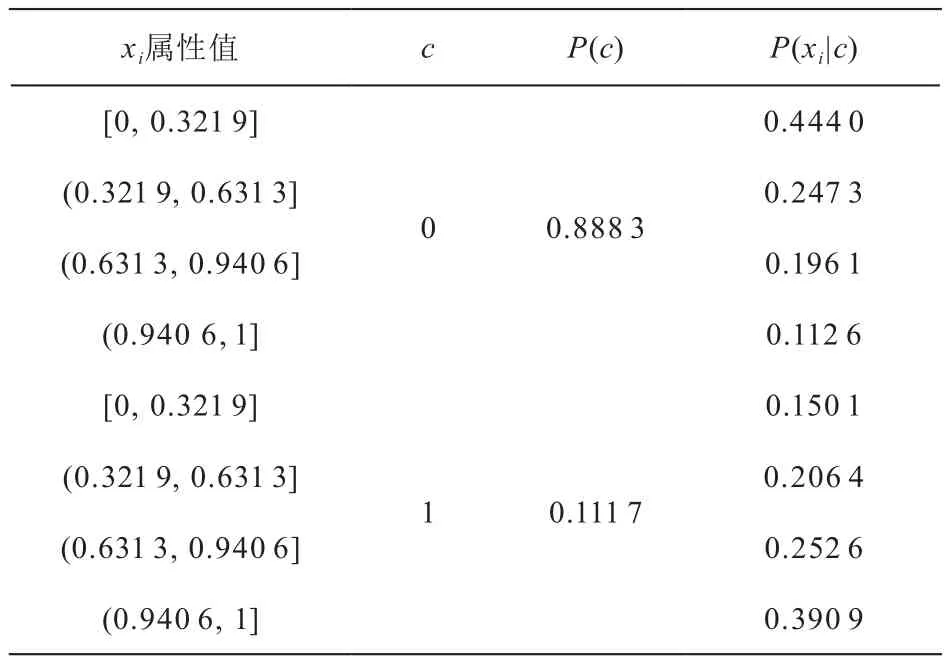
表3 距离比(DIST_RATIO)的朴素贝叶斯分类器参数模型
可以看出,随着距离比的增大,P(xi|c=0)呈现下降趋势,而P(xi|c=1)呈现减小趋势,这也与实际的规划思路相吻合:如果下一跳决策使得路由朝着离业务通路终点很远的地方行进,那么这个决策很有可能是不合理的,不被采用的。同理,其他属性也可以按照同样思路分析,从而构建出完整的概率参数模型。
5.2 决策树基本原理及模型构建
决策树算法是以样本示例为基础的归纳学习算法,它从一个无序的样本集合中归纳出一组基于树结构表示的分类规则。决策树的每个非叶子结点对应于一个属性测试,每个子结点对应于一个分类结果。每个非叶子结点包含的样本集合根据这个结点的测试判定结果,将样本集合划分到相应的子结点中。典型的决策树算法有ID3、C4.5和CART。
基于决策树算法,集成后剪枝算法,可以构建波长路由的拓扑决策和资源决策的决策树模型,如图4所示:

图4 决策树参数模型
5.3 Logistic回归分类器基本原理及模型构建
Logistic回归分类器属于广义线性回归模型,虽然名称中含有“回归”两字,但其本质是一种二分类算法。Logistic回归分类器具有十分简洁的算法表达式:

对于一组样本x,将其输入分类函数hθ(x),若输出大于0.5,则将该样本分类为1,否则分类为0。Logistic回归分类器的构造方法就是求出特征参数向量θ。
基于Logistic回归算法,采用梯度下降法求取特征参数向量θ,可以构建波长路由的拓扑决策和资源决策的Logistic回归分类器模型,如表4所示。
该参数模型即资源影响的特征参数向量θr。通过上表可以明显看出,需要设备转接、需要拆分波长以及低波道空闲率等因素的θ值均为负数,说明如果这些属性值为1,则对分类为0有帮助。对应于实际的工程选路,这些因素都会造成额外的设备成本,规划设计人员会尽量避免这种情况发生。

表4 Logistic回归分类器参数模型

表5 三种分类算法特点比较分析
5.4 算法性能分析
三种分类算法自身的优劣势以及与骨干传送网路由规划的契合度如表5所示。
另外,经平台仿真计算,三种分类器在资源影响样本和拓扑影响样本上的性能如表6所示:
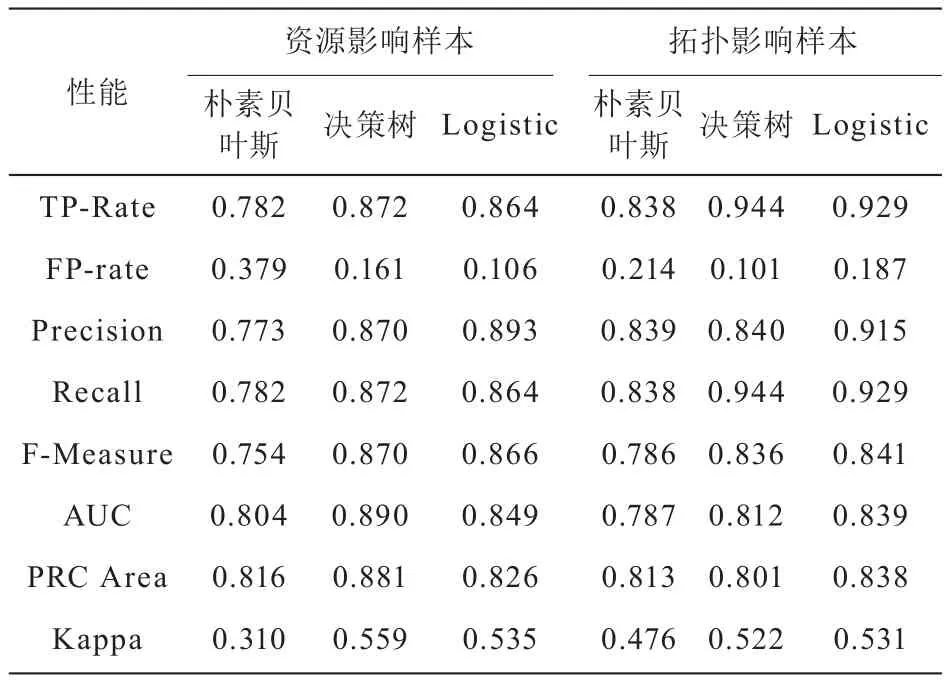
表6 三种分类算法性能比较
由以上结果可知,虽然决策树整体性能比其余两种算法好,但决策树算法自身与骨干传送网路由规划算法的契合度不高,所以不宜采用。虽然Logistic回归分类模型在中国移动十一期工程的网络数据较朴素贝叶斯分类模型有着一定的优势,但二者差距不大,在选型时可针对实际性能进行灵活地选择。
6 参数模型测试及结果
6.1 参数模型的运用
参数模型构建完成后,可运用参数模型,基于概率或边权重进行路由规划和资源分配。例如,构建Logistic回归分类器参数模型,然后利用拓扑影响参数,基于KSP算法计算出若干备选路由,再利用拓扑影响参数和资源影响参数,针对每一条路由求取目标函数总和,从而选择使函数最大化的路由作为结果路由。
6.2 测试方法及结果
在实际网络数据下,利用上述建模方案构建参数模型,完全模拟前期工程网络环境和需求环境,进行历史路由重排,所得结果与历史真实选路结果进行比对验证,主要以路径重合率和资源命中率两个指标对验证结果进行评估。
路径重合率的定义为:

式(3)中,NL∩L'表示软件选路结果与历史路由重合的局站链路段数量,NL表示系统选路结果局站链路段数量。
资源命中率Rr的定义为:

式(4)中,NR∩R'表示重合局站段中的资源命中数量,NL∩L'表示重合局站段数量。
基于中国移动九到十一期骨干传送网工程数据,依照本文所述参数模型构建方法,结合有效路由算法,通过以上验证方式得到的结果如图5所示:

图5 历史路由重排准确率
7 结束语
本文针对WDM/OTN骨干传送网路由规划设计软件平台在开发过程中遭遇的参数化困难问题,提出了一种基于机器学习分类算法的路由参数模型构建方法。经实际工程数据验证,结合专业设计人员分析评价,该方法实现了软件路由规划逻辑与设计人员决策过程的高度拟合,基本可以替代传统人工选路工作,大幅提升了网络规划工作的效率。并且,考虑到机器学习可以使参数模型不断迭代优化这一特性,该方法有助于提升规划软件平台的智能化和开发过程的高效化。
[1] 黄善国. 光网络规划的与优化[M]. 北京: 人民邮电出版,2011.
[2] 王健等. 光传送网(OTN)技术、设备及工程应用[M].北京: 人民邮电出版社, 2016.
[3] 史培明,周奎翰. OTN规划探讨[J]. 电信技术, 2017(8):65-68.
[3] 刘海涛,杨斌. OTN网络建设规划[J]. 电信工程技术与标准化, 2010,23(4): 58-61.
[4] 吴春祥,孙立矗. 我国OTN标准化现状及发展趋势[J]. 硅谷, 2011(22): 23.
[5] 李勇. OTN技术在长途传输网中的应用探讨[J]. 邮电设计技术, 2012(12): 71-75.
[6] Alwayn V. Optical network design and implementation[M].Cisco Press, 2004.
[7] H Holler, S Vosz. A heuristic approach for combined equipment-planning and routing in multi-layer SDH/WDM networks. Feature Cluster: Heuristic and Stochastic Methods in Optimization[J]. European Journal of Operational Research, 2006.
[8] 徐海峰. OTN系统规划和应用探讨[J]. 中国新通信,2017,19(10): 72-73.
[9] 李萌. OTN的规划与设计[J]. 邮电设计技术, 2013(6):63-66.
[10] 周志华. 机器学习[M]. 北京: 清华大学出版社, 2016. ★
