基于案例推理的地铁施工事故案例库的建立与评价
2018-07-02赖芨宇易紫妮李晓娟
王 勇,赖芨宇,易紫妮,李晓娟
福建农林大学交通与土木工程学院,福建 福州 350108
随着我国城市经济飞速发展,尤其是20世纪90年代以来,城市基础设施的建设与完善,城区建设规模不断扩大,吸引着来自各地的管理、技术、劳务等各种人才,使得人口总量逐年增加。截止2017年,我国城区人口超过500万的城市共11座[1-3]。面对如此大的人口规模,传统的交通运输工具难以负担如此大的交通流量,而且过多的汽车尾气排放,严重影响城市环境[4]。因此城市轨道交通运输系统开始修建,并逐渐完善,以有效、便捷地缓解目前城市公共交通运输压力。
图1为我国近15年来发生的323起地铁施工事故统计[5-7],在 2003-2017年间,我国的地铁施工事故总量呈现出两段增长期。2005-2010年呈一快速增长期,2010年达到历年最高,共38起,死亡人数达27;2008年死亡人数为历年最高,为36。从2011年至今,又处于一段增长期,且平均每年事故数量超过21人,平均每年事故死亡人数超过19人;预计未来几年内,施工事故总量依旧会呈现增长趋势。通过数据分析其原因:前期由于我国部分城市首次修建地铁,施工技术与经验不足,且相关法规与标准不完善;后期主要是一二线城市的不断发展,促使获批修建地铁城市大量增加,造成事故不断增多。

图1 2003-2017年我国地铁施工事故统计Fig.1 Statistics of subway construction accidents in China from 2003 to 2017
根据海因里希法则,在一起死亡或重伤的事故后,隐藏着29起轻伤事故以及300起无伤亡事故,甚至无数的不安全的操作行为,即三者之比为1∶29∶300[8]。在本次统计的 248 起具有较为详细记录的事故中,三者之比为161∶11∶76,这表明仍有大量的事故数据未能统计到。基于此,建立全面的地铁施工事故信息搜集系统,运用基于案例推理(case-based reasoning,CBR)机制的方法构建地铁施工事故案例库,检索的相似案例出现时,不仅可以为施工组织方案的制定提供参考,增加其安全性,还可以基于施工过程中出现的事故,预测施工高危险系数的环节容易发生的安全事故,以降低其发生的可能性。
1 基于CBR的地铁施工案例库的构建
CBR作为三种主要的推理机制之一,起源于1977年,发展历程已近 40年[9]。CBR机制机理主要是对过去事故建立案例库,当遇到新问题时,可以通过相似案例搜索,力求找出与以往最相似的事故,解析其发生的过程与解决方案,为新问题提供有效的参考[10],因而是一种利用以往相似经验去推理解决新问题的方法[11]。若从案例库中选取的实例相似度低,则可以整理本次案例,将其作为新案例输入库中,作为以后的参考样本。这种方法广泛应用于计算机工程、分类与诊断、交通运营等各种行业[12-13]。
自1965年北京地铁一号线开工以来,我国已经开始进入现代城市交通时代。特别是在20世纪90年代,我国地铁修建开启了第一个高潮,但在地铁施工过程中,由于其工程量大、施工复杂难度高,安全管理不到位等原因[14],产生大量的施工事故案例。若将CBR方法运用至地铁施工事故案例库的建立中,建设方从中提取有效信息选项,案例库系统可以从中导出相对应的往年事故,并对与此相关的案例进行分析评价。而地铁施工单位作为案例库的主要参与者,可以将施工案例搜集并整理,导入到案例库中,以此扩充数量,使得以后选取与导出的案例更充分、评价信息更加完善。当施工单位在制定施工组织时,可以先依据工程标段的各类信息,如事故发生的时间点、事故发生段位及地理位置、施工过程中的施工方法和人员素质情况、事故结果及处理结果等,从案例库中调取相似案例的所有信息,既可以在施工前做好应急预案,也可以在事故发生后采用相似且比较成功的处理措施,其机制见图2。若在案例库中检索不到相似度较高的案例,则可以调整事故的信息类型,然后将其整理好,作为新案例重新输入到案例库系统中,为以后的事故处置提供经验。

图2 基于CBR的地铁施工事故案例库的运行机制Fig.2 Operation mechanism of CBR-based casework database for subway construction accidents
2 相似度的计算
每一地铁施工事故的发生过程可以由许多基本词语描述,因此可以将案例包含的信息概念化,而不同深度的概念以及同一深度的不同概念的相互交织,可以形成概念树[15],并以此做为案例库建立的数据模型。在一概念树中,逻辑关系包括继承关系、组成关系、扩展关系。在一案例中,一个概念可以继承和扩展出更多的小概念。地铁施工事故扩展出不同概念,如发生地点包括特大城市、一二线城市,事故发生类型扩展出坍塌、高处坠落等。继而以坍塌为例,扩展出其他概念,形成地铁施工坍塌事故的完整体系,最后扩展出最底层的概念,如土质疏松、支护体系破坏、导洞影响等,如图3所示。在每一次的扩展中,概念树形成具有层次性的概念。
2.1 数相似度的概念及其特征
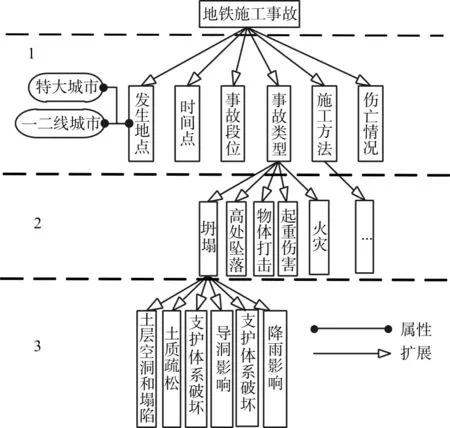
图3 地铁施工坍塌事故概念树示意图Fig.3 Conceptual tree diagram of subway construction collapse accident
在概念树中,每个概念所处的层次称为概念层次,用l表示,maxl称为树的深度,记为m。此外,概念之间的最短路径条数之和,称为概念距离,用d表示,则c1和c2的树相似度可以表示为St(c1,c2),其计算公式为:
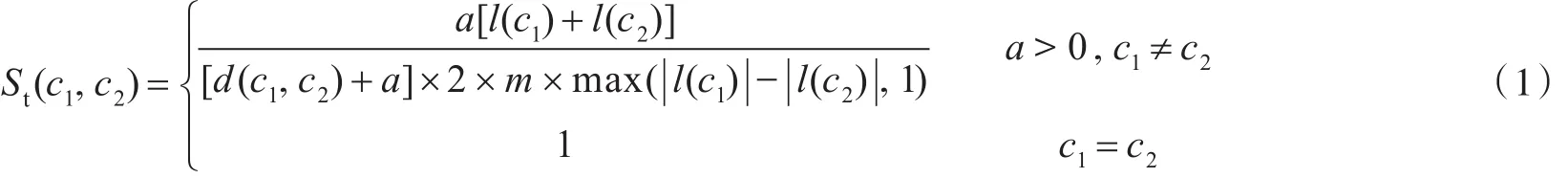
其中设l(c1)和l(c2)分别c1和c2的概念层次;a为正数,表示调节参数;St(c1,c2)=1表示概念c2和c2具有等价关系。从公式中可以发现,由于概念树深度与调节参数均是固定值,概念树的相似度主要受概念的概念层次和概念距离影响。若概念层次深度越大,概念距离路径越少,则两个概念之间的概念相似度则越大。
在图4中,概念树共有3层,m=3;发生地点和坍塌的概念距离为3,深度分别为1和2;发生地点和坍塌的概念相似度计算得:

图4 概念树示意图Fig.4 Schematic diagram of concept tree

2.2 嫡系相似度的计算
在概念树中,前一层概念称为父概念,它表示该层引出的概念之间的相似度,称为嫡系相似度,记为Ss(),其表达方式可以用公式(1)计算。
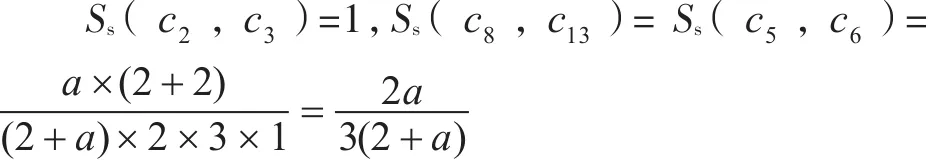
2.3 概念相似度的计算
在概念树中,若c1,c2为两个不等价的概念,则其概念相似度可以表示为Sc(),其计算公式可以表达为:
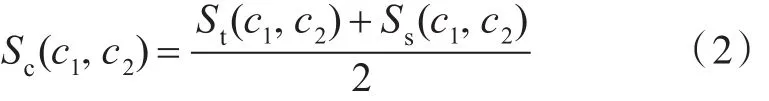
2.4 属性相似度的计算
概念的属性也表达着概念的某些特征,因而概念的属性相似度也影响着案例相似度,记属性相似度为Sb(),其计算方法与公式(1)类似。
3 相似度的计算过程
在评价两个案例的相似度时,不同的概念,受到多种因素的影响,因此还应根据其权重来计算。设案例库中检索的案例X和输入系统的事故Y,案例X包含了n个概念{c11,c12,c13,…,c1n},r个数值类型属性{b11,b12,b13,…,b1r}和h个对象类型属性{b21,b22,b23,…,b2h};案例Y包括m个概念{c21,c22,c23,…,c2m},k个数值类型属性{b31,b32,b33,…,b3k}和j个对象类型属性{b41,b42,b43,…,b4j}。
①求概念相似度矩阵其中
②从矩阵S中选取maxλmn,将其所在的行与列的值,形成新的矩阵S′,如此不断循环,到该矩阵为空的时候停止。然后将每次计算得到的maxλmn记为w={f1,f2,f3,…,ft0},式中t0=min(m,n)。
③ 进而再求w={f1,f2,f3,…,ft0}的加权平均表示概念i的权重值。
④依据数值类型和对象类型两种类别,将概念的属性进行分类,然后分别构造出两种类型的相似度矩阵M和N:
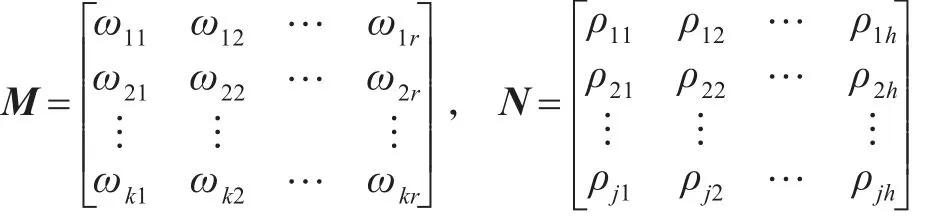
其中,数值类型矩阵中的两属性之间的间接相似度wkr=Sb(b1r,b3k),而对象类型之间的属性的间接相似度可以表示为ρhj=Se(b2l,b4h),可由公式(2)计算得到。
⑤同①的计算过程方法相似,从矩阵M中选取maxωkr,并清除其所在行和列中的值,然后形成新的矩阵M′,不断循环计算,直到 M′矩阵为空的时候停止。每取得maxωkr时候,记z={x1,x2,x3,…,xt1} ,式中t1=min(k,r)。同理可知,在计算矩阵 N中,可以得到v={y1,y2,y3,…,yt2},同样t2=min(h,j)。
⑥ 计算z={x1,x2,x3,…,xt1}和v={y1,y2,y3,…,yt2}各自的加权平均值:
S,式中ϕi是其权重值;,式中εi为其权重值。
⑦将上面两种加权平均值结合起来,可以得到概念属性相似度,表示为Sb(X,Y),其公式表达为:

⑧结合概念相似度与概念属性相似度,按照各自权重,计算出案例的相似度,可以表示为S(X,Y),即:
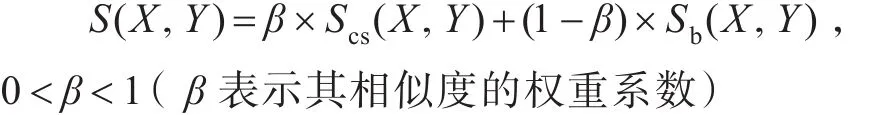
最终根据设置的相似度阈值,判断该案例的相似度是否符合要求,是否在系统中通过。
若,(其中a为调节参数)则表示X和Y两个案例具有较高的相似度;
若,则表示X和Y两个案例具有极高的相似度;
若S(X,Y)=1,则表示X和Y案例完全一致,属于等价关系。
如图4中概念树中的第二层发生地点与伤亡情况的嫡系相似度Ss(c2,c7)=1,表明两个概念的父概念相同。
4 案例相似度计算的应用
以2起地铁施工坍塌事故为例,通过计算两案例之间的相似度,确定两者之间是否有参考价值。
案例X:2014年12月17日17时20分,南京地铁四号线TA06标段在安排1号竖井内钢筋绑扎时,未按照要求,导致钢筋笼架在施工过程中发生坍塌,造成4死3伤的施工事故。
设计案例Y:2013年8月18日21点左右,某市郊区在建的轨道交通,某区间工地发生坍塌,造成2死4伤的施工事故。
从这2个案例中,在第二层中选取发生地点、发生时间、伤亡情况、事故类型4个概念,进而扩展出郊区与车站、上下午、事故级别、坍塌等概念,所有的概念及其属性一起形成地铁施工事故的概念树,如图5所示。在这个案例设计中,设取a=1,δ=0.5,β=0.5,案例之间相似度计算过程如下:
由①可计算案例X、Y的概念相似度矩阵S1:

然后取概念的权重μi(i=1,2,…6)=0.2,由前面计算过程②和③,可得Scs(X,Y)=0.714。再根据计算过程④,可分别得到案例X和案例Y之间的数值类属性的相似度矩阵M11,和对象类属性相似度矩阵N12:

然后选取概念的属性权重ϕ1=ϕ2=0.5,ε1=1,再按照前面的计算方式⑤至⑦,可以计算出数值型和对象型的各自加权平均:

最后依据计算步骤⑧,可以计算出两个案例的相似度:S(X,Y)=β×Scs(X,Y)+(1-β)×Sp(X,Y)=0.534
由于计算结果显示:这表明两个案例具有较高的相似度,南京地铁施工事故案例可以为设计案例提供较高的参考价值。若在案例库检索中,与之相似度有更高值,应按照从大到小依次排列。此外,由于我国幅员辽阔,不同地区的地理环境不同,施工场地条件、人员素质、技术设备等因素也有所差异,使得计算的相似度结果会有所偏差。因此,在案例库检索时,概念树的第一层深度应建立得更加精确、详细,以提高相似度的准确性。

图5 地铁施工事故概念结构图Fig.5 Conceptual structure of subway construction accident
5 结 语
案例库的建立和完善,可以使不同单位、不同地区的地铁施工事故案例相互联系,降低传统施工案例之间较强的独立性。若能将每个地铁施工事故案例输入案例库中,通过计算机计算其相似度,可以有效地将它们结合起来,提高案例的参考价值,相互借鉴而不是仅仅将它存在于档案库中。
通过引入概念树,特别是概念和属性同时考虑在计算中,具有一定的合理性及应用意义,可以快速地判断事故之间的相似性。若相似度较高,则可以将其应用到本施工组织规划中,避免事故的发生。但是目前案例库的建立,还存在许多困难,这需要政府与相关企业进行合作,不断充实案例库的总量,发挥其借鉴与指导作用。
[1]2017中国城市人口排名名单13个城超1000万[EB/OL].(2017-8-11)[2017-12-7].http://mnw.cn/news/china/1813680.html.
[2]李晓娟.地铁运营安全风险分析[J].工程管理学报,2017,31(1):83-88.
[3]李志东.地铁运营安全的风险评估与管理[J].价值工程,2017(23):54-56.
[4]万国胜,梁晖,周华杰.地铁运行引起环境振动的评价方法[J].武汉工程大学学报,2009,31(5):25-28.
[5]邓小鹏,李启明,周志鹏.地铁施工安全事故规律性的统计分析[J].统计与决策,2010(9):87-89.
[6]李凤伟,杜修力,张明聚.地铁工程建设施工事故统计分析[J]. 地下空间与工程学报,2014(2):474-479.
[7]李皓然,李启明,陆莹.2002-2016年我国地铁施工安全事故规律性统计分析[J].都市快轨交通,2017,30(1):12-19.
[8]谢东升,钱七虎,戎晓力.地铁工程建设安全风险管理研究[J].土木工程与管理学报,2012,29(1):61-67.
[9]李晓辉,刘妍秀.基于实例推理机制(CBR)综述[J].长春大学学报,2006,16(4):68-70.
[10]孙锋.CBR中的相似算法[J].重庆工学院学报,2008,22(4):67-72.
[11]严爱军,钱丽敏,王普.案例推理属性权重的分配模型 比 较 研 究[J].自 动 化 学 报 ,2014,40(9):1896-1902.
[12]陆莹,李启明,高原.基于案例推理的地铁运营事故案例库的构建[J].东南大学学报,2015,45(5):990-994.
[13]张春晓,严爱军,王普.一种改进的案例推理分类方法研究[J].自动化学报,2014,40(9):2015-2021.
[14]丁烈云,吴贤国,骆汉宾,等.地铁工程施工安全评价标 准 研 究[J].土 木 工 程 学 报 ,2011,44(11):121-127.
[15]向东,赵勇,陈阳.面向语义信息案例知识表达与相似度计算方法研究[J].计算机工程与科学,2011,33(12):159-166.
