一种融合多种信息的Web文档分类方法
2018-06-28段国仑郭蕾蕾王晓莹
段国仑,谢 钧,郭蕾蕾,王晓莹
(1. 陆军工程大学 指挥控制工程学院,江苏 南京 210007;2. 陆军工程大学 通信工程学院,江苏 南京 210007)
0 引言
如今互联网发展快速,在互联网信息过载、大数据的复杂背景下,网页数量呈现指数级别的增长,手动网页分类变得不切实际,于是便产生了网页文本自动分类技术[1]。网页文本分类技术具有广泛的商业前景和发展潜力。网络搜索引擎需要根据主题寻找到相关的文档,网络中的信息过滤[2]、垃圾邮件分类[3]以及目前应用广泛的数字图书馆建设等,都可以使用Web文档分类技术实现,因此Web文档分类具有很好的研究价值。
随着网络的快速发展,各种信息元素在网络中不断丰富,Web文档中蕴含的不仅仅是正文文本信息,还包含着图表信息、URL信息、多媒体信息以及网页中的隐含信息等。这些信息都可用于Web文档分类。但是当前许多Web文档分类系统都是基于正文文本。本文提出一种融合Web文档多种信息的文档分类方法,结合智能优化算法,能有效实现Web文档自动分类,并提升分类精度。
1 相关工作
1.1 向量空间模型
文本向量空间模型的主要思想是:将每一个文本表示为向量空间的一个向量,并以每一个不同的特征项(词条)对应为向量空间中的一个维度,而每一个维度的值就是对应的特征项在文本中的特征值[4]。向量空间模型就是将文本表示成为一个特征向量:
V(d)=((t1,a1),(t2,a2),…,(tn,an))
其中,ti为文档d中的特征项,ai为ti的特征值,一般取为词频的函数。有了这样的表示以后,就可以用分类器对样本分类。
1.2 支持向量机
支持向量机(Support Vector Machine,SVM)是一种在缺乏先验知识的条件下,以最小化结构风险为目标,对有限样本进行学习的机器学习方法。支持向量机的基本思想是寻找一个最优超平面或最优超曲面,使得不同类样本之间的间距达到最大[5]。
支持向量机是目前文本分类中使用较多的分类器。支持向量机最大的特点是解决小样本、高维度的分类问题,而文本分类就是一个高维度的分类问题,所以支持向量机相对较优。
2 融合多种信息的Web文档分类方法
针对当前Web文档分类大多采用的是正文文本作为分类的语料,本文提出一种融合多种信息构建语料库,在不改进分类算法的前提下,可以有效提升Web文档分类精度的方法。首先从网络中爬取包含多种信息的Web文档,构建自己的语料库。然后使用TFIDF (Term Frequency-Inverse Document Frequency)计算各个特征的特征值,计算时为不同种信息设置不同的权重w。最后使用支持向量机对Web文档进行分类,使用遗传优化算法,根据分类精度,不断调整各个信息的权重w,最终找到一个最优的信息融合方式。
2.1 网络爬虫构建语料库
目前大多数语料库只包含了Web文档的正文文本,没有包含相关的多种信息,如中科院自动化所的中英文新闻语料库,搜狗的中文新闻语料库,李荣陆老师的中文语料库[6],谭松波老师的中文文本分类语料库等。
本文通过网络爬虫爬取网页中的多种信息,如正文、描述信息、关键字、图片相关文本、标题以及文章中加粗等特殊字体的文本等,构建语料库。图1是凤凰网中文化专题中的一篇Web文档示例,显示了6种信息。为获取以上信息,使用Python语言编程从网络中进行爬取,并将爬取的内容进行存储,关键代码如下:
{
title=soup.select (’# artical_topic’)[0].text
// title
des=soup. find (attrs= {”name”:”description”})
// description
kwords=soup. find (attrs={”name”:”keywords”})
// keywords
for p in soup. select (’#main_content p’)[:-1]:
if (p.select (’span’)):
picIntro. append (p.text.strip())
// picIntro
else:
article. append (p.text.strip())
// article
bold=soup. find_all (’strong’)
// boldwords
}

图1 Web文档中的多种信息
2.2 基于遗传算法的权重优化
如上所述,语料库中包含6种信息,每种信息对于分类的贡献不同,因此需要对各部分的权重进行设置。在计算各个特征值的时候,一般采用TFIDF进行计算,计算公式如下:
TFIDF(t,d)=TF(t,d)*IDF(t)
(1)
(2)
其中,TF(t,d)表示特征项t在文档d中的词频数,IDF(t)表示特征项t的逆文档频率,N表示总的文档数量,nt表示包含特征项t的文档数量。由于采用多种信息用于分类,特征出现在各种信息中贡献不同,因此式(1)中的词频将采用加权词频数,计算公式如下:
(3)
其中,wi为第i种信息的权重系数;tfi(t,d)表示在文档d中,特征项t在第i种信息的词频数;n表示信息种类数,本文中n=6。对于(w1,w2,w3,…)值的选择,本文采用遗传算法(Genetic Algorithm,GA)来进行寻优。
遗传算法的实现过程实际上就像自然界的进化过程[7]。首先寻找一种对问题潜在解进行“数字化”编码的方案。然后用随机数初始化一个种群,种群里面的个体就是这些数字化的编码。接下来,通过适当的解码过程之后,用适应性函数对每一个基因个体作一次适应度评估。用选择函数按照某种规定择优选择。让个体基因交叉变异。然后产生子代,最终获得问题的局部最优解。
本文中,将6种信息对应的6个权重值(w1,w2,w3,w4,w5,w6)进行编码。每三位代表一个w,于是得到一个长度为18的二进制序列。使用选择、交叉、变异的方式更新编码值,个体的适应度使用的是该权重下的Web文档分类精度值。遗传算法关键代码如下:
{
pop= geneEncoding(pop_size,chrom_length)
for i in range(pop_size):
obj_value=calobjValue(pop,chrom_length)
best_individual,best_fit=best(pop,obj_value)
results.append([best_fit,best_individual])
selection(pop,fit_value)
crossover(pop,pc)
mutation(pop,pm)
}
在分类过程中采用支持向量机作为分类器,通过使用遗传算法最终找出分类精度最高的权重值。算法流程如图2所示。

图2 遗传算法流程图
3 实验结果
为了验证本文方法的有效性,分别用正文文本和融合多种信息进行Web文档分类实验。实验的语料库主要从凤凰网和新浪网上爬取数据建立。语料库包含9类:文化(487)、娱乐(1 182)、财经(934)、健康(1 097)、历史(269)、军事(797)、体育(943)、科技(905)、社会(897),共7 511个Web文档。按照2:1的比例将语料库分为训练集和测试集。实验过程中,在训练集采用3次三折交叉验证方法计算分类精度来寻找最优权重值,在测试集上比较了只使用正文文本和融合多种信息两种方法的分类结果。本文实验在Anaconda环境下调用sklearn、matplotlib、numpy、BeautifulSoup等函数库实现,所有的实验结果均是在一台2.50 GHz Intel Core(TM) i7-4710MQ处理器、8 GB内存的笔记本电脑上测试获得的。
将特征维数设置为700,通过使用遗传算法,求得(w1,w2,w3,w4,w5,w6)的最优参数值为(1,7,5,5,4,5)。表 1给出了本文遗传算法所使用的实验模型参数及测试结果。

表1 GA参数设置及测试结果
实验使用支持向量机作为分类器,本文选用的是Python工具包svm.SVC的线性分类器,损失函数选用squared hinge loss,使用L2正则化,二类向多类的推广采用的是“一对多”的方式。
通过训练集获得了模型参数以及多种信息的权重,然后根据测试集分别对两种方法进行测试。图3显示的是随着特征维数增加,使用SVM对两种情况进行分类得到的准确率曲线图,召回率和F1度量值曲线图与准确率曲线图走势基本一致。

图3 不同特征维数下的准确率曲线图
表2给出了特征维度为700时,两种方法下各类的分类准确率、召回率、F1度量值对比结果。
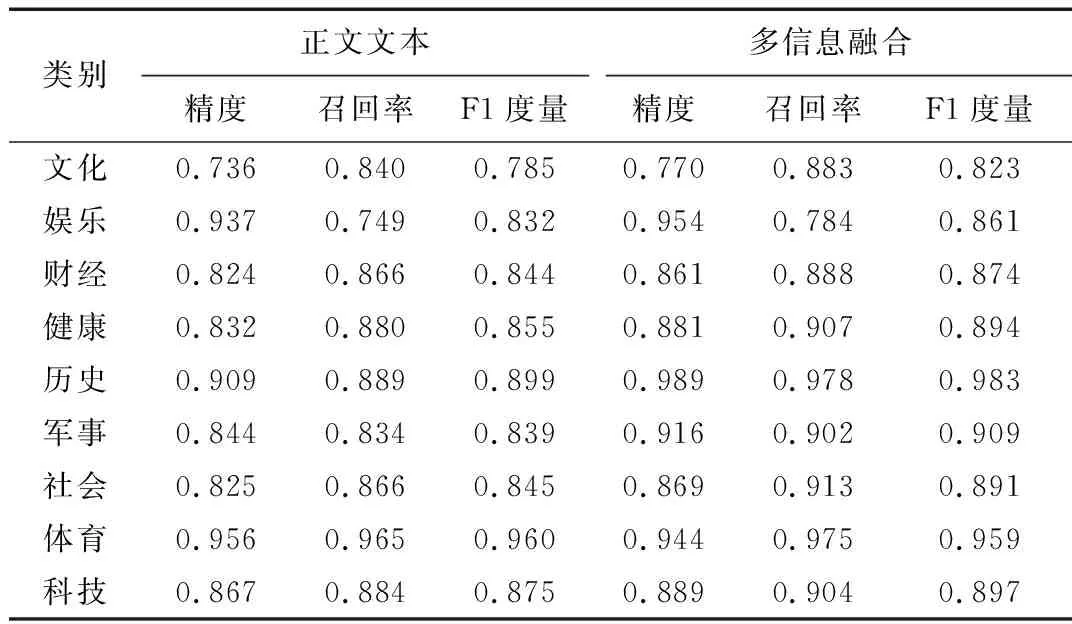
表2 Web文档正文与多信息分类实验结果
为了便于观察,将表2的数值用直方图来显示,可以更加直观地发现使用多种信息带来的分类性能提高。图4~图6分别显示了分类精度、召回率、F1度量的对比实验结果。
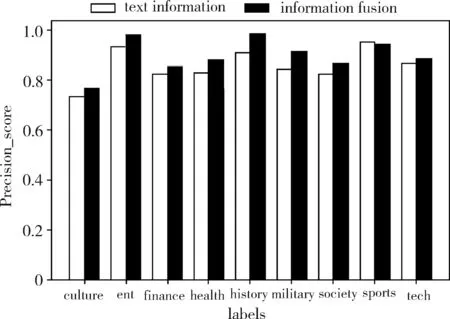
图4 分类精度对比实验
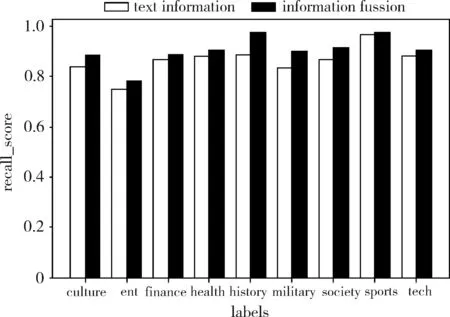
图5 召回率对比实验

图6 F1度量对比实验
实验结果显示,融合多种信息,并设置合适的权重,确实可以有效提高分类精度、召回率以及F1度量。从图3可以看出,随着分类特征的增加,使用多种信息的分类准确率始终高于仅使用正文文本。在相同维数下,时间复杂度并未增加,但是分类精度却得到了提升。如表2所示,本文提出的方法可将分类精度平均提高3个百分点左右。
4 结论
本文提出了使用多种信息进行Web文档分类,并对各个部分的信息进行加权处理,从而提高分类精度。首先从网络中爬取包含多种信息的文档建立语料库,然后给各个信息设置一定的权重,最后使用SVM对Web文档进行分类。在设置权重时,采用遗传算法来寻找最优解。本文方法思路简单,易于实现,且能有效提高分类精度。当然,本文方法主要针对那些Web信息比较丰富或者尽可能多地包含多种信息的网页,对于一些只包含正文的网页,相当于又退化为原有的方式。
[1] 靳小波. 文本分类综述[J]. 自动化博览, 2006, 23(S1):24-29.
[2] 牛洪波, 丁华福. 基于文本分类技术的信息过滤方法的研究[J]. 信息技术, 2007(12):100-102.
[3] 王金森. 文本分类算法在垃圾邮件过滤中的研究与应用[D].长春:吉林大学, 2006.
[4] 庞剑锋, 卜东波, 白硕. 基于向量空间模型的文本自动分类系统的研究与实现[J]. 计算机应用研究, 2001, 18(9):23-26.
[5] CRISTIANINI N, SHAWE-TAYLOR J. 支持向量机导论[M].李国正,等,译.北京:电子工业出版社, 2004.
[6] 李荣陆. 文本分类及其相关技术研究[D]. 上海:复旦大学, 2005.
[7] 周明, 孙树栋. 遗传算法原理及应用[M]. 北京:国防工业出版社, 1999.
