基于时空采样的卷积长短时记忆网络模型及其应用研究
2018-06-28闭世兰
闭世兰
(中南民族大学生物医学工程学院,湖北武汉430074)
0 引言
近年来,基于机器学习的方法作用于人体动作识别取得了卓越的成效,其中以计算机模拟生物体神经系统视觉感知机制的深度学习法最为有效。然而,人体动作在空域和时域上呈现不可分割性,但现有的动作识别方法主要采用纯粹提取单域信息或时空信息分离处理的技术来实现人体动作识别,从而导致识别性能仍然不太理想。
众所周知,卷积神经网络(CNN)在视觉皮层的多级处理的启发下可以自动学习特征,模拟视频空间相关性效果最好。
Ji Shuiwang等人将传统的CNN扩展到3D-CNN以捕捉视频中的空间时间特征[1],但识别精度不理想且增加了学习的复杂性。
研究者为了提取视频的时域特性,提出将循环神经网络(RNN)[2]及长短时记忆网络LSTM[3]应用于动作识别,V.Veeriah等人在研究中提出微分式循环神经网络dRNN模型[4],使用密集取样的HOG3D特征,并证实了循环神经网络的记忆能力,然而LSTM忽略了帧中局部像素之间的空间相关性。
为了同时利用CNN与LSTM的优势,研究者考虑将RNN或LSTM模型与CNN结合,生成CNNRNN(CNNLSTM)模型,它的基本架构是CNN序列特征作为输入引入到LSTM模型中。
M.Baccouche等人在科研中使用3D-ConvNet+LSTM、3DCNN+Voting两种组合方式,取得了较高的准确性[5]。
虽然这些模型可以解决动作识别的问题,但是在模型的两个不同阶段,它们分别考虑了空间性和时间性,然而空间性和时间性是生物体运动识别不可分割的特性。
为了揭示动作识别的本质特征,专注于时空信息相关性,必须将时间相关的LSTM网络融合到二维CNN中,实现空间和时间不可分割的功能,Shi Xingjian等人将完全连接的LSTM扩展到卷积LSTM[6]。
1 ConvLSTM
为解决RNN梯度消失和记忆衰减的问题,S.Schuster和J.Schmidhuber等人引入了长短时记忆结构(LSTM)[3],模型具有联想和记忆功能,能较好地获取视频序列空间信息在时间上流动的结构特征,在处理时序数据问题上成效非凡,但是由于LSTM的内部接近于全连接的方式,这就带来严重的信息冗余问题,且LSTM将输入数据视为向量,即使它们具有空间结构,忽略帧中局部像素之间的空间相关性,违背了视频的本质。为了解决这个问题,Shi Xingjian等人提出将FC-LSTM的思想扩展到卷积结构中,用卷积运算替换FC-LSTM的input-to-state和state-to-state的点乘运算,最终形成LSTM融合CNN的一种卷积LSTM模型(ConvLSTM[6]单元)。ConvLSTM是对LSTM结构的改进,其信息处理过程展示如图1所示,由输入门、遗忘门、输出门、记忆单元、隐藏门组成,这些门运算过程如式(1)~(5)所示。
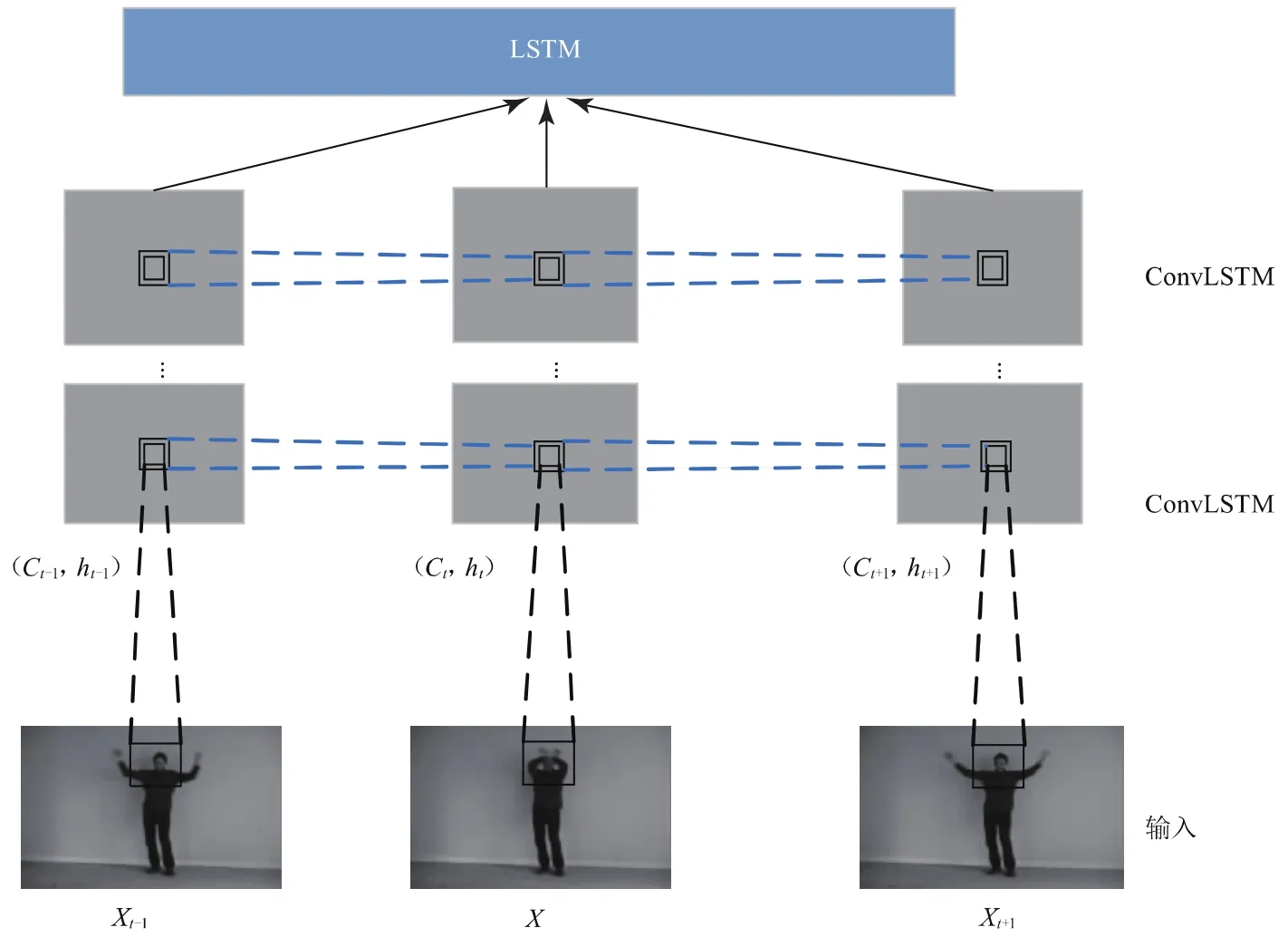
图1 卷积LSTM信息处理过程
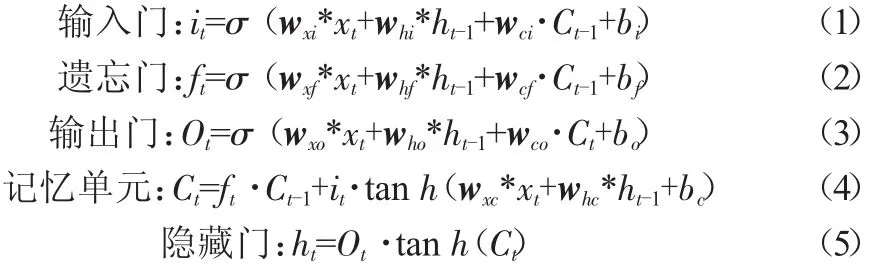
以上公式中,*表示卷积运算;·表示点乘运算;xt代表t时刻的输入图像;it代表t时刻的输入门输出信息;Ct-1代表t-1时刻记忆单元的信息;whi是输入门到遗忘门的权值矩阵,其余矩阵依此类推。
值得注意的是,这里的xt、it、ft、Ot、Ct、ht都是三维的变量,第一维是时间信息,后两维代表行和列的空间信息。
该模型结构既充分发挥了空间卷积神经网络的特性,模拟视觉系统感受野,较好地感知视频中人体动作结构特征,提取图像中的空间局部相关性,又能发挥LSTM模型在长时间序列处理问题上的联想和记忆功能,提取视频的时空特征,获取动作在时间上流动的特征,是一个既有空间深度,又有时间深度的“双重”深度学习网络。
2 状态微分ConvLSTM
虽然卷积长短时记忆网络模型能提取时间和空间上的特征,对任何复杂动力学的时间序列数据进行建模,但不幸的是该模型对输入视频序列隐藏状态的动态演化不敏感,不具备精准分类的能力。
为解决这个问题,本文在ConvLSTM的基础上,提出一个具有时间状态微分的卷积长短时记忆网络模型——状态微分ConvLSTM模型(简称d_ConvLSTM),该模型强调视频帧间运动引起的信息增益,这些信息增益的变化是通过状态导数量化的。
状态微分是对记忆单元Ct进行求导,其值越大表明在相同时间上信息的变化量越大,因此模型对输入序列的时空结构变化很敏感,其结构内的门运算过程见公式(6)~(10),变量信息、各门关系与ConvLSTM相同。

上式中,是记忆单元Ct的n阶导数,状态微分也是时间采样的一种形式,体现了状态Ct在时间上的变化程度,其一阶导数、二阶导数见公式(11)~(12),较高阶的导数可用类似方式求出。为了不放大包含在输入序列中的不必要噪声,本文的离散模型不对输入序列进行求导。
3 网络架构
在搭建网络模型中,需要考虑的是卷积核大小、网络层数、过拟合等问题。
回顾近年来提出的深度学习神经网络框架:从LeNet-5网络架构到AlexNet架构,再到Googlenet[7]网络与VGG网络,最后扩展到NIN[8]网络与darknet-19[9]网络架构。随着模型架构的改进,发现伴随着卷积核的减少,卷积层数的增加,模型在识别问题上表现的性能越来越出色。
因此本文判定结合这些网络结构的优点所搭建的框架也具有从图像提取特征映射的能力,本文模仿Darknet-19的网络结构,并对其进行扩展和简化,通过将其卷积层替换成新模型ConvLSTM单元。在深度方向,本文的模型使用了15个ConvLSTM层、6个池化层,并采取在每层ConvLSTM卷积后增加批量标准化防止网络过拟合。此外,施加在权重上的正则项使用L2正则规范化等初始化方式防止过拟合。
本文的模型框架是ConvLSTM层与池化层堆叠而成的,然后送入LSTM单元,LSTM融合视频序列的所有帧信息,然后将特征向量传送到softmax分类器,为每一个视频生成一个标签。训练采用批量随机梯度下降法(SGD)迭代160次,批量处理大小为10个样本,网络的学习率初始化为0.1,momentum为0.9,权重衰减为0.000 5。
4 实验结果与分析
KTH数据库是评估动作识别算法的基准[10],数据库包含六类动作四种场景,由25个人组成共599个灰度视频。
本文使用其中的20组作为训练集,5组作为测试集,在网络训练之前,首先将图片进行线性插值、减去均值、除方差等预处理。
4.1 基于时间深度的效果
深度ConvLSTM是一种“双深”结构,提取时空特征以识别人体动作。为了证明网络模型的有效性,本文进行了一些探索性实验,选用不同的时间深度T进行不同场景(d1、d2、d3、d4)的测试,用于评估时间深度对动作识别的影响,实验效果如表1所示,识别率(ARRs)是判别网络性能的标准。
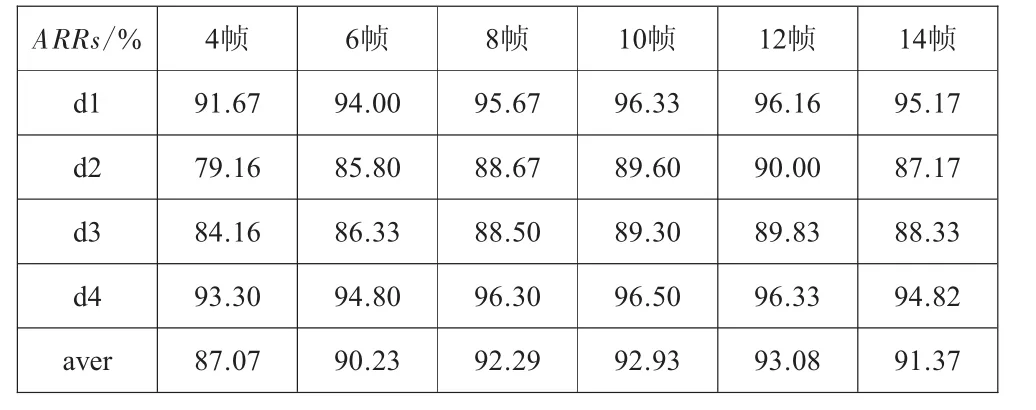
表1 KTH数据库在不同场景不同帧长下的识别率
实验证明在时间深度T<10时,识别精度随着深度(或帧长)增加而增加,当T>10时,精度却呈现微弱的下降。这是因为时间深度越深包含的运动信息越多,越有助于行动识别,当深度值接近动作的循环周期时,识别率最高。
然而,当时间深度大于10时识别率并不能显著提高,与此同时深度的增加特征提取的计算量也成倍的增加,计算负载越重。
4.2 基于时间采样的效果
考虑到传统的网络结构中采样能有效地提高识别精度,加速模型收敛,融合上下文信息。本文的网络结构中,在对视频系列的时间维度进行简单的特征提取基础上,提出了状态微分采样、三维池化、帧间采样三种时间采样方式,并在4.2.1~4.2.3章节中对这三种方式进行实验分析。为了便于理解,利用ConvLSTM模型搭建的框架结构称为对比试验中的原始结构。
4.2.1 状态微分
首先对状态微分进行实验,微分结构d_ConvLSTM替换原始框架结构中的ConvLSTM层,其他框架结构不改变,实验比较状态微分与原始结构在KTH数据库不同实验帧长中的识别效果,实验结果如表2所示。
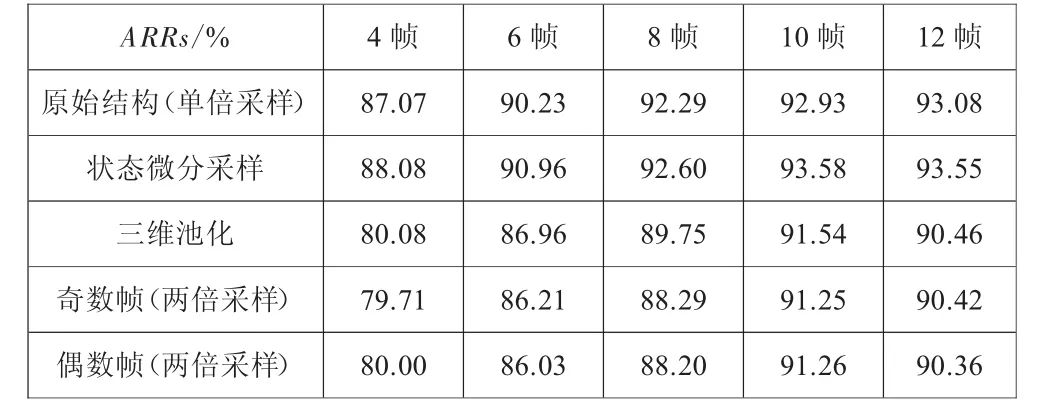
表2 三种时间采样方式与原始结构的对比
在实验结果表2中,注意到d_ConvLSTM模型相比ConvLSTM模型在不同长度的输入序列下动作识别效果好,每个长度的平均识别率都增长了0.5至1个百分点。实验证明状态导数确实对输入的变化量敏感,从而捕获细小的变化,提高识别率。
4.2.2 三维池化
在本文的框架中,使用了六层池化层,但是时空融合在哪一层的效果最好呢?为此,本文进行了探究实验,文章首先选取以10帧图片作为参照标准,在每一层都单独做三维时间池化,实验得出第一层池化精确度91.54%,第二层池化精确度91.87%,第三层池化精确度91.75%,第四层池化精确度92.17%,第五层池化精确度91.34%,第六层池化精确度91.38%。不难发现,当本文的框架选取第四层做三维池化时,实验精度最高。
第二个实验里,我们选取第一层池化层做三维池化,比较不同时间深度T下,三维池化与非池化的动作识别差异,结果见表2,三维池化的平均结果略低于非池化的平均结果,这是因为在时间轴上发生了池化,而时间采样相当于一个模糊滤波器,导致了信息模糊化,运动特征区分性不明显,造成识别精度较低。
4.2.3 帧间采样
KTH实验数据采用等间隔的单倍帧间采样法,当增加间隔的步长,相当于变相地增加了数据样本的距离,使得序列在时间上跳跃性大,帧间信息差别明显,拉大动作的类内差距。
本文第一组实验中先讨论不同的帧间采样方式对动作识别的影响,考虑到当输入序列小于8帧时若选取4倍的采样间隔,实验毫无意义,因此,本文只考虑两倍的采样间隔。两倍帧间采样有奇采样与偶采样的两种不同的采样方式,两种采样方式的实验结果见表2。
通过实验可知奇采样与偶采样两种两倍帧间采样方式对于不同帧长下的实验结果影响并不明显,但是两倍帧间采样的平均识别率低于单倍帧间采样,因此,本文可以得出结论:识别精度与采样方式无关,而与采样步长相关。
4.3 对比实验结果
为了评估本文方法的有效性,将本文的方法与传统的LSTM和最先进的非LSTM方法进行比较,对比结果如表3所示,本文的方法的识别性能要优于其他方法。

表3 在KTH数据集上比较ConvLSTM模型与其他模型算法
5 结语
本文针对视频图像的识别,采用卷积LSTM模型在时域空域方向提取特征,实现动作识别。实验结果证明:本文提出的基于卷积神经网络模型算法在学习时空特征动作识别过程中更优于传统的单独学习空间、时间特征,也优于CNN+LSTM的结构,识别精度获得了较大的提升,微分形式的采样更有利于特征的提取。
[1]JI S W,XU W,YANG M,et al.3D Convolutional Neural Networks for Human Action Recognition [J]. IEEE Transactions on Pattern Analysis & Machine Intelligence,2013,35(1):221-231.
[2]SCHUSTER M,PALIWAL K K.Bidirectional Recurrent Neural Networks [J].IEEE Transactions on Signal Processing,1997,45(11):2673-2681.
[3] HOCHREITER S,SCHMIDHUBER J.Long Short-term memory[J].Neural Computation,1997,9(8):1735-1780.
[4]VEERIAH V,ZHUANG N F,QI G J.Differential Recurrent Neural Networks for Action Recognition[C]//proceedings of the IEEE International Conference on Computer Vision,2015:4041-4049.
[5]BACCOUCHE M,MAMALET F,WOLF C,et al.Sequential deep learning for human action recognition[C]//proceedings oftheInternationalConferenceonHumanBehavior Unterstanding,2011:29-39.
[6]SHI X J,CHEN Z R,WANG H,et al.Convolutional LSTM Network:A Machine Learning Approach for Precipitation Nowcasting [C]//Advances in Neural Information Processing Systems 28(NIPS),2015:802-810.
[7]SZEGEDY C,LIU W,JIA Y Q,et al.Goingdeeperwith convolutions[C]//2015 IEEE Conference on Computer Vision and Pattern Recognition(CVPR),2015:1-9.
[8]LIN M,CHEN Q,YAN S C.Network in Network[C]//International Conference on Learning Representations(ICLR),2014.
[9] REDMON J,FARHADI A.YOLO9000:Better,Faster,Stronger[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition(CVPR),2017:6517-6525.
[10]SCHULDT C,LAPTEV I,CAPUTO B.Recognizing Human Actions:A Local SVM Approach[C]//Proceedings of the 17thInternational Conference on Pattern Recognition(ICPR),2004:32-36.
[11]GRUSHIN A,MONNER D D,REGGIA J A,et al.Robust human action recognition via long short-term memory[C]//International Joint Conference on Neural Networks,2014:1-8.
[12]SCHINDLER K,GOOL L V.Action snippets:How many frames does human action recognition require?[C]//IEEE Conference on Computer Vision and Pattern Recognition,2008:1-8.
