基于改进投票专家算法的专有协议模糊测试方法
2018-06-26刘津霖付光远李海龙汪洪桥
刘津霖,付光远,李海龙,汪洪桥
火箭军工程大学 信息工程系,西安 710025
1 引言
近年来,专有协议(proprietary protocol)的应用越来越广泛,尤其是在工业控制领域。工控系统在逐渐变得更加信息化、自动化和智能化的同时,也埋下了安全隐患。工业控制系统不同于传统信息系统,一旦遭受攻击,会对国家安全造成重大打击,如:核电站爆炸、电力系统瘫痪、城市交通停运等。因此,研究工控系统安全关乎国家的战略安全,研究意义重大。提升工控系统安全的主要方法是漏洞挖掘,防患于未然。其中,模糊测试被公认为是最有效的漏洞挖掘方法,但是由于工控系统涉及的协议组成十分复杂,存在大量厂商自己定义的专有协议[1],这些专有协议没有公开的资料说明,对协议的结构和会话过程等信息无法轻易获悉,给模糊测试造成了巨大的挑战[2-3]。
针对专有协议的问题,可以采用协议逆向技术,获得专有协议的报文格式和协议状态机,将专有协议转化成“公有协议”,再结合模糊测试技术对被测目标进行漏洞挖掘。对于协议逆向技术的研究已经有了很多丰硕的成果,如:PI工程和它的改进方法Discoverer[4]采用生物信息学序列比对算法逆向协议的报文格式,为专有协议逆向解析提供了新思路,但是得到的分析结果缺少语义信息;Prospex[5]、ScriptGen[6]等方法充分考虑到了报文的语义信息,定义报文的关键字作为协议的语义信息,使逆向的报文格式和协议状态机更加完整。因此,协议关键字提取质量的好坏直接影响协议的逆向结果。目前提取关键字应用最多的方法是n-gram算法[7],即用一个大小为n的滑动窗口将报文划分成等长的子序列。然而,这种方法会使大于n字节的协议关键字被分割,或者使小于n字节的协议关键字混入噪声,从而影响协议逆向的效果。
本文提出的专有协议模糊测试方法,首先需要对流量数据进行流测度和分类预处理,并且提取协议关键字。为解决n-gram方法只能将所有报文划分为等长子序列的局限性,本文利用投票专家(Voting Expert,VE)算法提供更为准确的关键字提取,并且针对VE算法在处理协议数据时存在节点空间爆炸的问题,基于有损计数算法对VE算法进行了改进。在成功获取协议的关键字后,采用因果态分割重建算法重建未知专有协议的报文格式ε机。然后从每个会话中提取可以代表该会话的报文类型,将会话过程表示为一个报文类型序列,将所有的状态转换序列融合成一个确定有穷自动机,即协议的状态机。最后,根据逆向得到的有关协议的报文结构和协议状态机信息生成模糊测试用例,并对测试目标进行模糊测试。
2 改进的投票专家算法
2.1 投票专家算法
投票专家算法[8],属于局部贪心算法,主要是通过一个相对较小的滑动窗口,选择最有可能的边界位置对单词分区。本文利用VE算法代替传统的n-gram算法,提取被测专有协议的关键字。
为了实现滑动窗口大小为L的VE算法,用一个深度为(L+1)的单词查找树(Trie)来保存数据流中所有可能发生的字节组合。
例如,字符序列为“abcabd”,窗口大小为2时,可以生成深度为3的树,如图1所示。从图中可以看出子字符串ab出现两次,并且每次a出现时,b都是紧随其后。bc和bd各出现一次。
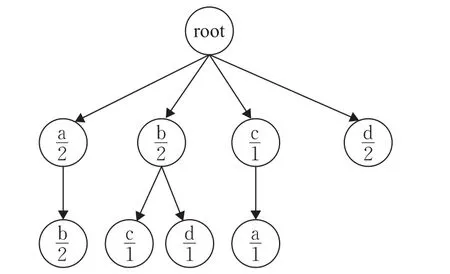
图1 单词查找树示意图
VE算法根据两项指标划分单词,一个是内部熵(Internal entropy)用HI表示,代表该子序列在数据流中总是作为一个整体出现,应作为整体得到保留,表达式如式(1)所示:

其中,w代表子序列,而P(w)则表示该子序列出现的概率。HI的值越小,代表子序列w越常作为一个整体出现。
另外一个指标是边界熵(Boundary entropy)用HB(w)表示,若后续字节序列经常变化,则认定该字节后为一个词之间的边界,表达式如式(2)所示:
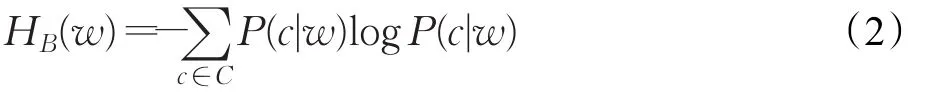
为了计算不同长度的子序列,需要对表达式进行标准化。

VE算法可以分为两个阶段,第一个阶段为投票阶段(Voting phase),在大小为L的滑动窗口内对可能是边界的位置进行投票。xIi和xBi分别表示在i处的内部投票点(internal voting point)和边界投票点(boundary voting point),j在0到L之间取值:
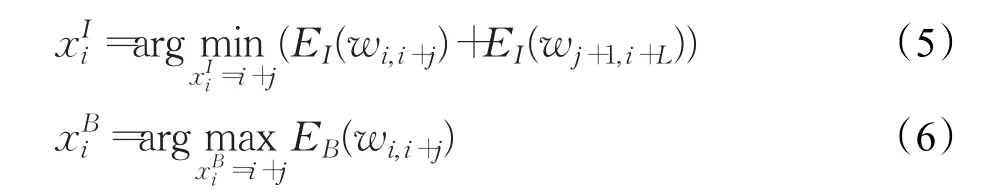
每个点x存在一个选票分数(Vote Score)用V(x)表示,其计算规则如式(7)所示,1(·)代表一个指示函数,如果x=y函数的值为1,否则为0。
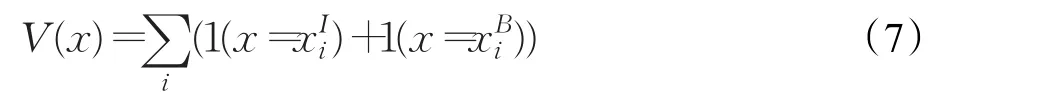
第二个阶段为判决阶段(Decision phase),在判断点x处为词边界时遵循以下两条规则:
(1)点x得到的票数比相邻点更多;
(2)得票数大于设定的阈值T。
通过VE算法可以得到字节序列中可能的词边界,将字节序列按一定的语义信息进行划分。
2.2 存在的局限性
虽然VE算法在自然语言处理中得到了很好的分词效果,但是在处理网络流量时存在一些缺陷。如,节点空间爆炸问题。在处理自然语言时,由于传统的组合习惯会限制某些子序列的发生,以英语为例,如当出现“tio”时,后续的字符极有可能是“n”,这在某种程度上减少了子树的数量,节省了存储空间。但是在处理网络协议数据,特别是纯二进制数据时,网络流量中子序列的分布概率更稀疏,往往会产生更多新的字节组合,从而导致占用大量存储空间。
2.3 改进方法
尽管VE算法在处理协议时会导致节点空间爆炸,但是通过观察发现,大多数节点的频率非常低。因此,虽然捕获所有节点需要一个巨大的存储空间,但是只需要关注有足够高的频率的子集即可。
为了解决VE算法在处理协议时存在的问题,本文通过有损计数算法(Lossy Counting Algorithm,LCA)[9]对单词查找树进行剪枝操作,删除频率非常低,不太可能是关键词的后继节点,从而节省空间。
LCA算法是一种近似计算算法,可以通过定期消除低频数据的方式,利用有限的内存从数据流中返回高频率数据项,在处理实时大数据流上的频率统计问题中得到了广泛的应用。本文的方法是利用LCA算法在修剪期内,对出现频率低于设定阈值的子序列进行剔除。LCA算法最为关键的参数就是最大错误率e,低错误率会保留更多的子序列但是会增加内存的压力,高错误率可以减少超出内存的风险但是可能会在剪枝操作中剔除一些有用的子序列,因此需要在两者之间找到平衡。另外,虽然通过剪枝操作可以在单词查找树中剔除低频的子序列,但是在计算选票分数时需要考虑所有子序列,因此,本文增加了补偿环节,即将没有出现在单词查找树中的子序列的出现频率统一设定为e/2。
文中已给出改进的投票专家算法ImproveVE的伪代码(图2)。算法的参数分别为P:流量数据;M:剪枝期处理字节数;L:滑动窗口大小;T:决定阶段阈值。ImproveVE函数首先调用BuildTrie函数计算子序列的频率(第6~16行),在各个剪枝期对低于频率阈值的子序列节点进行剔除(第17~21行)。构建单词查找树,然后计算树中所有子序列的熵值(第28~29行),并且补偿被剪切子序列(第33行),计算相应的熵值(第34行)。最后计算投票分数,确实可能的词边界(第36~41行),提取所有的候选关键字到集合W中(第42行)。
3 模糊测试
3.1 提取关键字
通过ImproveVE算法得到的只能称之为候选关键字集合,所谓的关键字是指那些可以区分应用协议的字节子序列。目标是根据权值对候选关键字集合中的关键字进行降序排序,提取排名靠前的子序列作为协议的关键字。因此,排序规则对特征词的选取起决定性作用。
本文利用信息检索与数据挖掘的常用加权技术——词频逆文档频率TF-IDF[10-11](Term Frequency-Inverse Document Frequency)作为特征词排序的评判标准。该标准需综合考虑频率与位置两方面的信息。因为,在报文格式中,存在如源地址、目的地址等信息,虽然出现的频率会很高,但是对报文格式的表达没有任何意义。
通过TF-IDF计算所有候选特征词的权值后,选取排名在前k的子序列作为协议的关键字,用于协议的逆向解析过程。
3.2 协议逆向分析
3.2.1 报文格式

图2 改进的投票专家算法ImproveVE的伪代码
在得到目标协议的关键字集合后,利用ε机表示协议的报文格式。因为协议可以看作是一个随机过程,构成协议的字符串以一定的概率出现,协议的内部状态与某些字符串的集合之间存在对应关系。而隐马尔科夫模型(Hidden Markov Mode,HMM)是一种只通过可观察状态就能求得系统隐藏的内部状态的统计模型。因此,可以运用求解HMM的思想得到专有协议的报文结构状态机模型。ε机是一种特殊的隐马尔科夫模型,可以对随机过程进行最小最优预测,由因果态方程ε和状态转移矩阵T构成[11]。所谓的因果态方程指的是历史与历史集合之间的一种映射关系。其定义如式(8)所示:
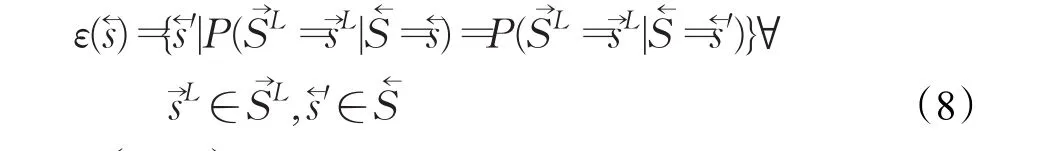
其中,和分别代表一个随机过程的历史和未来两个部分,SL和SL分别表示历史状态的最后L个字符和未来状态的最初L个字符。
目前,有几种重建算法可以用于推断ε机。如,因果态分割重建算法[12](Causal-State Splitting Reconstruction,CSSR)、状态合并ε机推断算法(State-merging ε-Machine Inference Algorithm)等。因果态分割重建算法与状态合并ε机推断算法最主要的区别是CSSR会利用一些关于因果态的状态属性来指导搜索和自动机建设,并且收敛速度更快。CSSR的核心思想是分割——将一个有限的符号集分割成多个因果态。其伪代码如图3。

图3 CSSR伪代码
其总体思路:首先做零假设(Null Hypothesis),假设该随机过程中的所有事件属于同一个状态。然后计算下一个事件的未来分布,通过Kolmogorov-Smirnov对零假设进行假设检验,如果假设不被拒绝,新的分配被认为与现有分布状态相同,该事件被添加到这个状态,如果有任意一个事件不满足于假设条件,则被分离出来构成新的状态。最后得到的状态有可能数量十分庞大,但其中大部分是瞬时状态。通过删除瞬时状态,保留循环状态,得到最终的报文格式ε机。
具体过程如伪代码所示,首先Initialization函数初始化(第1行),然后Sufficiency函数构建因果态(第11~28行),最后Recursion函数用于消除瞬时状态,确定因果状态机并填充转换表(第11~28行)。在Sufficiency和Recursion函数中均调用了TEXT函数(第30~37行)和MOVE函数(第39~43行),分别用于进行测试零假设和状态的移动、合并操作。参数W代表用于构建报文格式马尔科夫模型的字母表,即提取的协议关键字集合;xˉ表示从W中提取的长度为N的序列,Lmax表示估计因果态时最大的历史长度,α表示假设检验的置信度。通过该算法可以重建协议的报文格式ε机。
3.2.2 协议状态机
网络通信是由一个潜在的状态机驱动,当某些事件触发某些反应时进行状态交换。报文格式信息仅仅可以反映协议的语法和语义信息,缺少揭示协议行为特征的时序信息。推断协议的状态机模型可以了解报文之间的相互关联,进一步完善模糊测试器。
获得协议报文格式后,需要对所有会话(Session)进行分析,从每个会话中提取可以代表该会话的报文类型,将会话过程表示为一个报文类型序列,构建APTA(Augmented Prefix Tree Acceptor)树。
然后采用红蓝节点框架[13-15]对APTA树进行简化,最后最小化马尔科夫模型为一个有限状态自动机(Deterministic Finite Automaton,DFA),即如果将所有的状态转换序列融合成一个确定有穷自动机,那么这就是协议的状态机。
另外,对于只能解决单项报文的专有协议模糊测试器,得到的协议状态机显然是不全面的。为了能够应对双向报文,本文对事件序列进行标记,用以区分是来自客户端或者是服务器端。将来自同方向的报文构成一个转换条件或者一个状态,这样可以把会话中的消息看作是一个状态转换序列。例如,将服务器端到客户端的方向的报文定为状态机模型的边(edge),将客户端到服务器端的方向的报文定义为状态机模型的节点(node),反之亦可。具体的做法是采用大小为k的序列滑动窗口进行标记,例如,假设观察到的事件序列为a、b、c、d,并且是从客户端和服务器端交替生成的,则k=2时,得到的结果如式(9)所示:
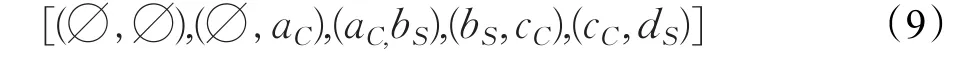
3.3 生成模糊测试用例
模糊测试是通过向测试目标输入非预期的数据并监测输出数据中的异常来发现测试目标中可能存在的漏洞的方法[16]。生成测试用例就是产生这些用于测试的输入数据的过程。
协议逆向阶段可以得到有关协议的报文结构和协议状态机信息,这些信息可以用来生成模糊测试阶段的测试用例。报文结构可以用于构造完整的数据包,对于报文中的固定部分通常不会造成漏洞,更多的是关注变长部分,确定生成模糊测试用例的测试点。而协议状态机可以明确协议的交互行为,控制协议的接收与发送。协议逆向工程与模糊测试技术的完美结合可以针对特定协议生成模糊测试用例,并且对测试目标进行漏洞挖掘。
本文采用基于文法驱动[17-18]的模糊测试用例生成技术,根据逆向得到的专有协议报文格式及状态机信息,利用文法模型自动化生成测试用例。其流程如图4所示。
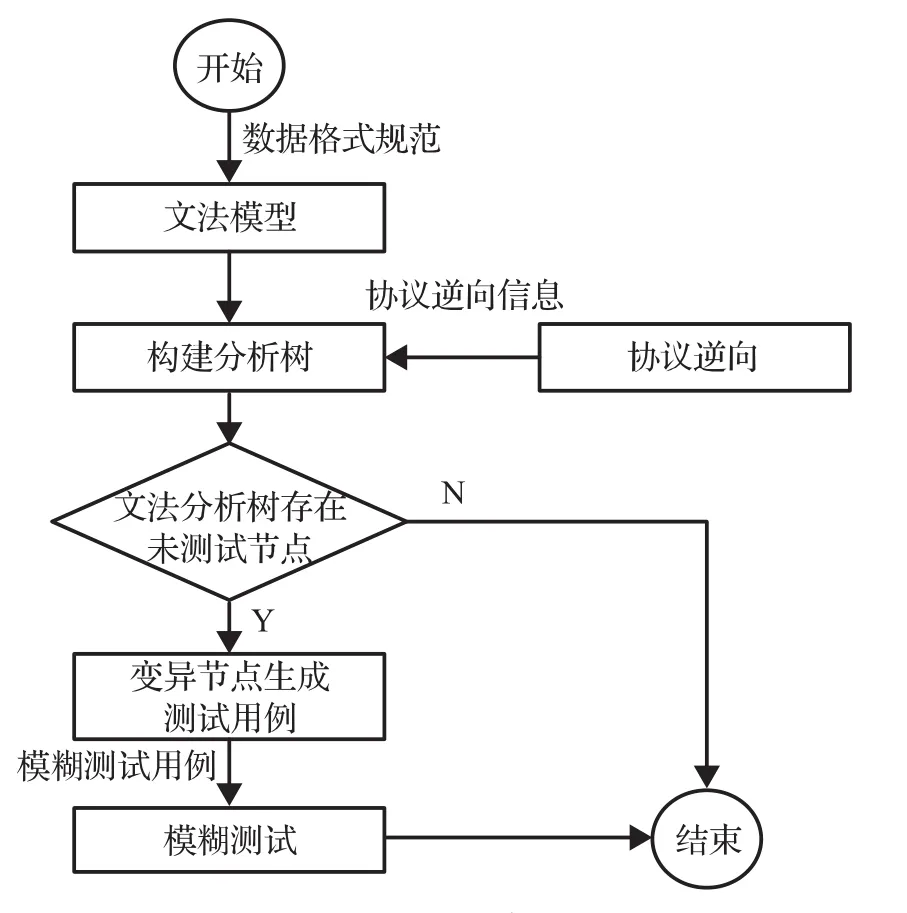
图4 生成测试用例流程图
根据数据格式规范构建文法模型,结合通过协议逆向工程得到的协议信息构建文法分析树。再利用模型中的属性规则对文法元素实施选择变异,进而生成测试用例进行模糊测试[19]。
4 实验分析
本文从三个方面进行实验分析验证:首先,利用公有协议FTP、HTTP和SMTP对ImproveVE算法提取关键字的性能进行实验分析;其次,通过逆向Modbus TCP协议,并与已有协议规范比对,检验逆向的效果;最后,用本文方法对专有协议WDB RPC进行逆向分析,并且针对WDB RPC协议对嵌入式实时操作系统VxWorks进行漏洞挖掘。
首先利用ImproveVE算法和传统的n-gram算法分别对协议规范已知的公有协议FTP、HTTP和SMTP提取关键字,统计在一系列候选关键字集合排名前k项中提取的关键字数量,根据提取的关键字与真正关键字之间的百分比评判算法的优劣。在实验参数的选取上,选择最为常用的n=3作为n-gram算法的窗口大小,VE算法的滑动窗口大小、阈值以及剪枝期处理字节数分别取值10、6和10 000 000。
如图5的实验结果所示,ImproveVE算法相较于n-gram算法对报文子序列的划分更为合理,提取的协议关键字更接近于真实情况。尤其是对FTP协议关键字的提取,其准确率已接近98%,准确地提取协议关键字更有利于对协议进行逆向分析。
另外,针对VE算法处理协议数据时存在节点空间爆炸,占用大量内存的问题,本文利用LCA算法对VE算法进行了改进。图6是分别采用VE算法和改进后的ImproveVE算法处理SMTP协议时所产生的节点数量比对。从直观上不难发现,改进后的算法明显降低了节点数量。值得注意的是,虽然改进后的算法ImproveVE和VE算法相比减少了生成的节点数量,但是和n-gram相比,所占用的内存空间仍然较大,这就需要在准确性和资源占用两者之间做权衡。根据本文的目的,对专有协议进行模糊测试,显然提取关键字的准确性是首要因素。另外,通过对VE算法的改进,节省了大量内存,对内存资源的占用完全在可承受的范围之内。因此,准确性这一指标更为重要,ImproveVE算法能较好地完成针对专有协议的关键字提取任务。
对改进的VE算法的性能进行对比实验分析后,需要进一步验证本文方法对专有协议的逆向效果。首先对公有协议Modbus TCP进行逆向分析。
Modbus是用于工业现场的总线协议,属于应用层报文传输协议。Modbus TCP属于Modbus标准的一种,属于工业控制网络范围,是一种公有协议,Modbus TCP的报文格式与通过本文方法得到的报文格式ε机如图7所示。

图5 提取关键字的准确率
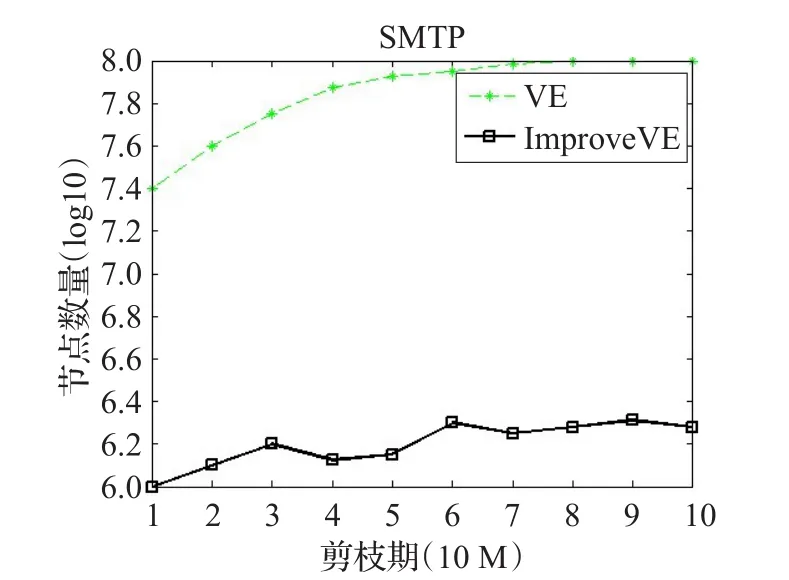
图6 ImproveVE算法减少节点数量
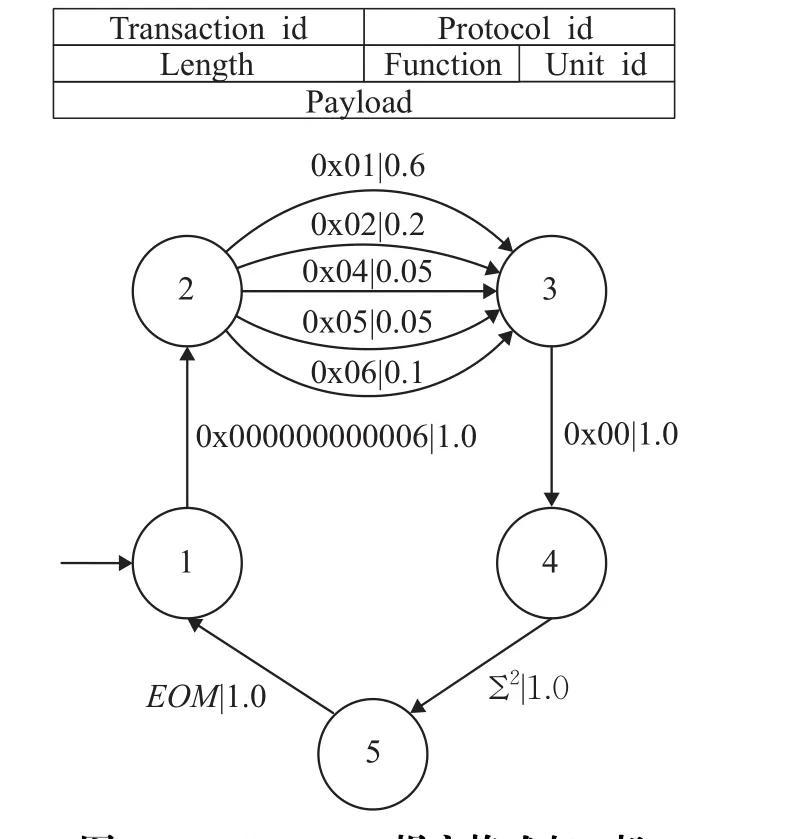
图7 Modbus TCP报文格式与ε机
根据已有的Modbus TCP的报文格式,可以获悉该协议由事务标识符、协议标识符、长度字段、功能字段、单元标识符和负载构成。该协议对应的隐马尔科夫模型由报文头创建的6个状态和相邻状态之间的转换构成,其中Σn代表n个连续的字节,EOM代表消息是完整的,并准备转发。接下来通过300条流量数据对Modbus TCP协议进行逆向分析,得到该协议的ε机。可以发现,前三个字段被分配到了同一状态,这是因为它们的取值是固定的,因此在学习过程中自然被分配到同一状态。虽然得到的ε机与真实的报文格式有所差异,不完全匹配,但却是一个合理的分组,是完全基于观察到的统计信息得到的结果。因为本文的方法是一个增量学习的过程,如果有足够多的训练数据,字节将被分配到正确的字段。
另外,可以观察到,通过因果态分割重建算法不仅很好地重建了Modbus TCP协议的报文结构ε机,并且区分出了不同的功能字段,如表1所示。
接下来利用本文的方法对专有协议WDB RPC进行实验分析。WDB RPC属于嵌入式实时操作系统VxWorks的专有协议,利用WDB RPC协议既能直接访问系统的内存,又能对VxWorks所有组件的工作状态进行监控,如果组件发生异常,TAgent会利用WDB RPC协议自动告知当前连接的调试器。WDB RPC属于典型的专有协议,没有公开的文档说明,公司外部人员对该协议的结构一无所知。WDB RPC目前有两个版本,本文所研究的是WDB RPCv2,用于VxWorks 6.6及以上版本。本文通过500条WDB RPC流量数据对报文结构进行逆向分析,得到WDB RPC报文结构的ε机如图8所示。

表1 Modbus TCP部分字符与相对应的功能
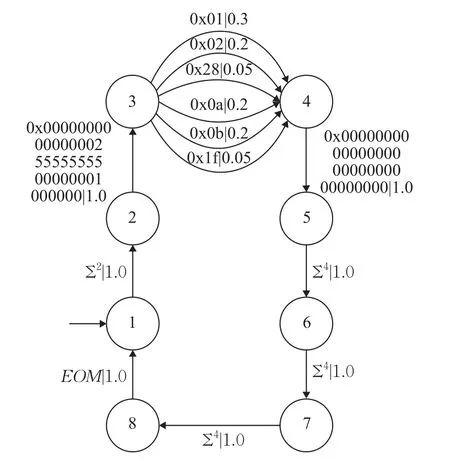
图8 WDB RPC的ε机
通过协议逆向分析,可以获得协议的报文格式和协议状态机等信息,这些信息可以用于协议识别、异常检测和智能模糊测试等诸多领域。本文主要是将协议逆向分析用于模糊测试,以解决由于工控领域存在大量专有协议给模糊测试带来的实际困难。利用协议逆向阶段得到的有关协议信息,生成模糊测试阶段的测试用例,并对测试目标实施漏洞挖掘。本文利用上述的VxWorks专有协议WDB RPC对嵌入式实时操作系统进行模糊测试。VxWorks是由美国风河(Wind River)开发的一款嵌入式实时操作系统,该操作系统以其良好的可靠性和卓越的实时性被广泛应用于工业控制领域。
通过本文的专有协议模糊测试方法成功发现,WDB RPC存在整数溢出漏洞,允许攻击者修改设备内存,存在安全隐患。当攻击者不断地进行写内存操作会造成系统崩溃。图9为VxWorks操作系统正常的启动画面,以及当利用WDB RPC的漏洞写入大量的内存后,造成系统的崩溃。造成图中所示现象的原因可能是在显示的过程中正好出现了系统的崩溃。
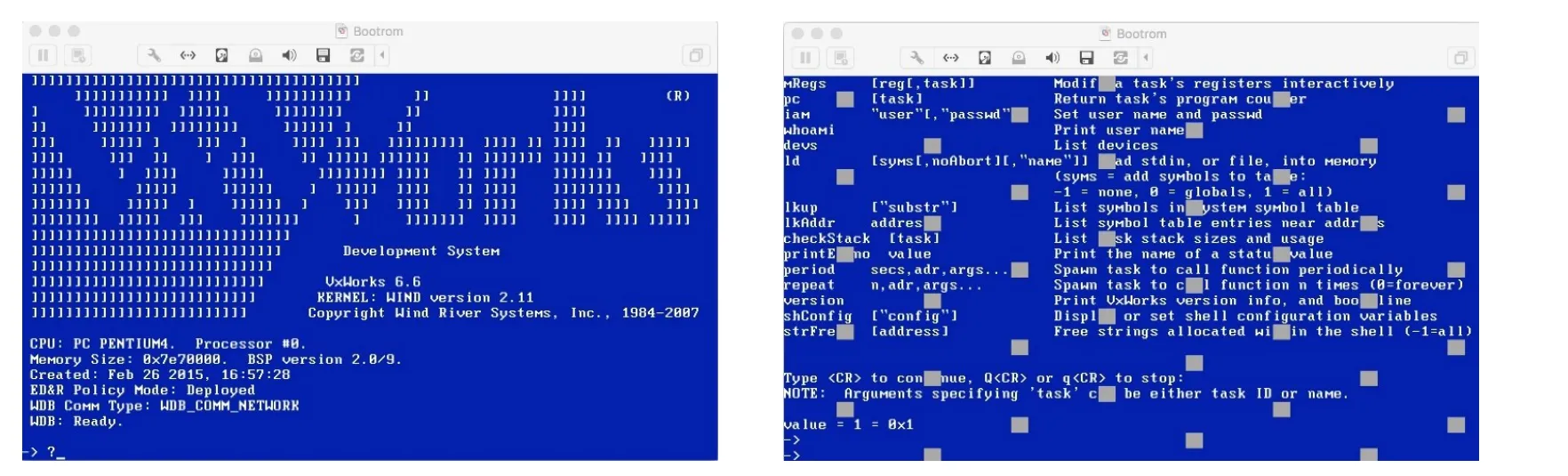
图9 VxWorks系统正常启动及造成崩溃的画面
5 总结与展望
本文将自然语言处理的知识拓展到网络协议领域,采用投票专家算法替代传统的n-gram算法,使协议关键字的提取过程更加精确。另外,利用有损计数算法对投票专家算法进行了改进,节省了对内存资源的占用。本文的方法提升了关键字提取精度,使逆向的协议信息更接近于真实值。并且,通过与协议逆向工程技术的结合运用,克服了模糊测试中专有协议缺少协议规范的问题,适用于存在大量专有协议的环境,如工业控制系统,有助于提升工业控制系统的安全性和防护能力。但本文的方法仍存在一些不足,需要在今后的研究中加以完善,如ImproveVE算法处理文本协议时效果十分理想,但在处理纯二进制协议时关键字的提取精度有待进一步加强。另外,在内存资源占用方面也可以进一步优化。
[1]熊琦,彭勇,伊胜伟,等.工控网络协议Fuzzing测试技术研究综述[J].小型微型计算机系统,2015,36(3):497-502.
[2]Gascon H,Wressnegger C,Yamaguchi F,et al.Pulsar:Stateful black-box fuzzing of proprietary network protocols[M]//Security and Privacy in Communication Networks.[S.l.]:Springer International Publishing,2015.
[3]Bermudez I,Tongaonkar A,Iliofotou M,et al.Towards automatic protocol field inference[J].Computer Communications,2016,84(C):40-51.
[4]Cui W,Kannan J,Wang H J.Discoverer:Automatic protocol reverse engineering from network traces[C]//Usenix Security Symposium,2007.
[5]Comparetti P M,Wondracek G,Kruegel C,et al.Prospex:Protocol specification extraction[C]//IEEE Symposium on Secuity&Privacy,2009:110-125.
[6]Leita C,Mermoud K,Dacier M.ScriptGen:An automated script generation tool for Honeyd[C]//Computer Security Applications Conference,2005:203-214.
[7]Jamdagni A,Tan Z,He X,et al.Review article:RePIDS:A multitier real-time payload-based intrusion detection system[J].International Journal of Computer&Telecommunications Networking,2013,57(3):811-824.
[8]Cohen P,Adams N,Heeringa B.Voting experts:An unsupervised algorithm forsegmenting sequences[J].Intelligent Data Analysis,2007,11(6):607-625.
[9]艾佳.海量数据上基于抽样的模式挖掘研究[D].哈尔滨:哈尔滨工业大学,2014.
[10]Fang H,Tao T,Zhai C X.A formal study of information retrievalheuristics[C]//InternationalACM SIGIR Conference on Research and Development in Information Retrieval,2004:49-56.
[11]Zhang Y,Xu T,Wang Y,et al.A Markov random field approach to automated protocol signature inference[M]//Security and Privacy in Communication Networks.[S.l.]:Springer International Publishing,2015.
[12]张淑清,李盼,师荣艳,等.复杂系统建模的ε机理论方法及应用研究[J].仪器仪表学报,2014(8):1758-1765.
[13]孙芳慧.基于Net-Trace的未知协议格式逆向技术研究[D].哈尔滨:哈尔滨工业大学,2015.
[14]Bahr A,Thompson J D,Thierry J C,et al.BAliBASE(Benchmark Alignment dataBASE):Enhancements for repeats,transmembrane sequences and circular permutations[J].Nucleic Acids Research,2001,29(1):323-326.
[15]Lang K J.Faster algorithms for finding minimal consistent DFAs[J].oai:CiteSeerX.psu:10.1.1.29.7130,1999.
[16]萨顿,格林,阿米尼.模糊测试:强制发掘安全漏洞的利器[M].北京:电子工业出版社,2013.
[17]梁姝瑞.基于FSM的Zigbee协议模糊测试算法[D].北京:北京邮电大学,2014.
[18]侯莹,洪征,潘璠,等.基于模型的Fuzzing测试脚本自动化生成[J].计算机科学,2013,40(3):206-209.
[19]吴礼发,洪征,潘璠.网络协议逆向分析及应用[M].北京:国防工业出版社,2016.
