大数据环境下高校图书馆馆藏图书优化配置模型研究*
2018-06-25龚自振
龚自振
(深圳职业技术学院图书馆,广东 深圳 518055)
随着时代的发展,图书馆传统馆藏建设模式越来越不适应图书馆的转型与发展。在图书价格上涨、读者阅读习惯改变、大数据运用日益广泛、图书馆经费不足及馆藏空间有限的情况下,高校图书馆采取相应的措施优化馆藏图书配置、精选图书以提高图书的使用效率。从馆藏发展政策的制定到近年来讨论的读者决策采购(patron-driven acquisition,简称PDA),都将馆藏图书的配置作为重点问题来对待。事实上,作为图书馆资源建设的主要内容,馆藏图书配置在电子化阅读环境下仍然占有重要地位。一是因为馆藏图书的配置经费虽然在下降,但仍然占据全馆文献资源购置总费用的较大比例[1],二是最近发布的研究报告指出,我国成年国民人均纸质图书阅读量大于电子图书阅读量[2],三是在我国现有政策下,馆藏图书还是高校图书馆考察的一个重要指标。因此,在大数据时代,馆藏图书配置仍不能忽视,而应转变思路,加快转型与创新,以适应新的要求与挑战。本文将从大数据的视野出发,对这一问题进行分析与探讨,以期引起图书馆界的重视。
1 当前馆藏图书配置问题分析
笔者通过文献检索发现:近十年来,学者对馆藏建设的关注与研究越来越少,而阅读推广方面的研究快速增加。也就是说,在图书馆转型发展过程中,馆藏建设这一块业务逐渐被压缩,越来越不被重视,因此,大多数图书馆的采购模式仍然停留在传统图书配置上。图书馆常用的读者荐购[3]、学科馆员及专业馆员[4]选书等手段,对提高图书配置的科学性和图书利用率所起的作用有限。传统模式的图书配置将直接或间接地影响图书的流通与阅读。统计表明,美国大学图书馆藏书平均十年才被使用一次的图书居然达到50%比例[5],我国大学图书馆近年来图书的流通量也在逐年下滑[6]。造成这种现象的原因除了传统阅读受互联网阅读冲击比较大外,还有一个重要因素就是当前的馆藏图书配置没有很好地利用图书馆大数据。
归纳起来,馆藏图书配置的问题主要有以下几点:(1)以电子书目选订和现场选购的图书配置模式不能有效地覆盖学校的学科专业,经常会造成图书收藏的遗漏,而有些学术性图书一旦错过收藏,若干年后再无法购买。所以,传统征订模式无法完全满足读者教学科研及学习的需求,因为这种图书配置模式完全依赖电子书目的质量和采购人员的个人经验。(2)以图书荐购、学科馆员及专业馆员选书为辅助的图书配置模式因为荐购数量少,无法完成图书馆规模化的年度购书任务,这种模式的工作局面经常会先热后冷,重复荐购。并且由于反馈信息不及时,无法保证荐购的持续性,只能是采访馆员配置图书的一种补充。(3)PDA模式目前主要运用于电子书的采购,在国外也只是应用在馆际互借及OPAC检索中的MARC数据发现和购买[7],并没有在馆藏纸本书配置中全面推行。所以,目前的纸本书PDA模式仅能满足一小部分读者个性化的需求,也不能完成馆藏图书配置的任务。在这种情况下,图书馆需要转变观念,探索新的馆藏图书配置模式。
2 馆藏图书优化配置的大数据及影响因子
2.1 馆藏图书优化配置模型的大数据构成
大数据具有“4V”特性,即容量(Volume)巨大、处理速度(Velocity)快、价值(Value)巨大和类型(Variety)繁多[8]。根据这四个特性,从数据所处的环境来说,影响馆藏图书配置的大数据可分为两类:一类是图书馆内部数据,包括纸质资源、电子资源、网络资源、图片、音视频等各种内容和载体形式的馆藏资源数据,图书流通数据,图书采访数据,编目加工数据,信息咨询数据,专题服务数据等业务工作数据;另一类是图书馆外部数据,与图书馆业务密切相关的数据,主要包括学科专业数据、核心科研人员数据、出版社书目数据、研究热点数据、学校科研项目数据等。这些数据具有较大的规模,如果能对其进行整理、分析,就能寻找到与配置图书相关的依据,优化馆藏图书结构,提高图书利用率。从数据的可用性与价值来说,馆藏图书优化配置还需要考虑有关读者的大数据。按读者行为来分,高校的读者数据包括静态数据与动态数据。读者静态大数据主要包括读者的年龄、兴趣、专长、专业等背景信息,而动态数据则包括读者在微信、微博、博客、论坛等新媒体上发表的对阅读的评论等信息,以及在网店、网站等平台上发表的读书互动、购书行为记录、消费行为记录等数据。在构建馆藏图书配置模型时,要弄清这些数据构成与特性,以便分类整理与研究。
2.2 馆藏图书配置大数据的挖掘分析及工具模型
简单地说,数据挖掘(Data Mining)是指从大型数据库或海量数据仓库中提取隐含的、潜在的、有用知识的方法和技术。它与数据库密切相关,又可称为数据库知识发现(Knowledge Discovery in Databases,KDD) ,数据挖掘涉及的学科较复杂,包括统计学、机器学习、数据库等学科领域,还包含了可视化、信息科学等内容。数据挖掘需要运用多种现代技术与方法来解决问题,如统计学中的回归分析、判别分析、聚类分析以及置信区间等技术,机器学习中的决策树、神经网络等技术,数据库中的关联分析、序列分析等技术。
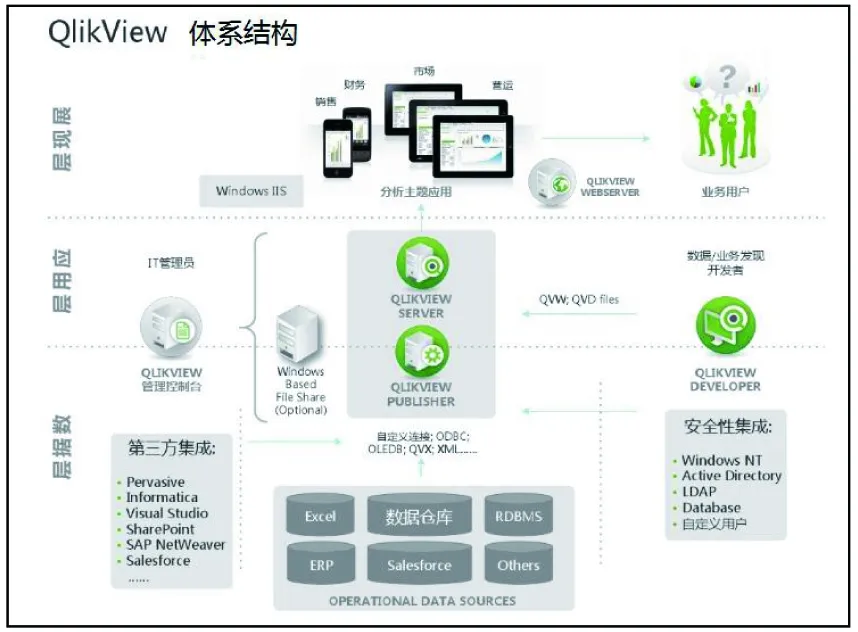
图1 QlikView的体系结构图
从商业化的运作来讲,数据挖掘就是BI(商业智能)。QlikView作为一个完整的商业分析软件[9],
不同于传统BI通过ETL过程处理数据,它通过内存数据引擎,能够直接查询外部数据库,将大量的所需要分析的数据存储在内存中,及时返回分析需求,提高了数据访问和分析的效率。其体系结构如图1所示。
笔者利用QlikView分析工具,构建图书馆大数据分析模型,通过数据导入与运算,生成的部分图书馆流通数据,能清楚地分析借阅量(如图2所示)。从图2可以看出.图书馆年度流通数据、分类流通数据、学院、班级及个人的借阅数据,并对比流通图书的出版社来分析馆藏结构、学生借阅报告,从而关联到班级及学风建设。

图2 QlikView图书馆流通数据分析示例图
2.3 图书优化配置模型的影响因子
影响图书优化配置的数据因素较多,不同的学者从不同的角度加以分析与论述。笔者通过中国期刊网期刊全文数据库,分别按篇名关键词“图书采购”或“图书采访”进行检索,然后再用影响因素的关键词按“主题”进行二次检索,得到关于图书配置的各个影响因素的关键词研究记录数据,进行归纳整理,总结如表1所示。
从表1数据可以分析出,研究文献关注的影响馆藏图书配置的主要因素有出版社、采购人员、流通率、研究领域、专业(学科)设置、荐购、学科(专业)馆员。其中出版社、研究领域、专业(学科)设置、荐购、学科(专业)馆员、采购人员是馆藏配置工作的前期影响因素,而流通率则是评价馆藏配置的影响因素之一。这些因素相互关联,影响馆藏图书的配置。
出版社提供的书目是馆藏配置的基础,在此基础上,采购人员的业务水平、选书风格、文化知识、工作态度以及学科(专业)馆员推荐工作的质量等对馆藏配置起决定性作用。而图书流通率、研究领域分析、专业(学科)设置、荐购情况等数据则对馆藏配置的结构偏离起到校正与完善作用。因此,研究图书优化配置模型的影响因子时必须考虑这些因素的权重区分比例大小,进行量化研究。

表1 影响图书配置因素的关键词统计表
3 大数据环境下馆藏图书优化配置模型的构建
在大数据环境下,构建一个科学合理的馆藏图书配置模型,主要分为四个步骤:
(1)图书馆大数据的收集、整理与建库。收集本校图书馆微博、微信,电子邮件、新书推荐网站、图书流通率、专业馆员与专业教师推荐目录、OPAC检索词、出版社书目、当前研究热点关键词、核心科研人员研究领域关键词、学校专业(学科)设置类别的关键词、共建共享文献库书目,形成大数据库集,以表格形式储存,保留主要字段,便于各表格数据的关联与发现。如出版社书目表格中的字段为:ISBN、书名、作者、出版社、分类号。那么,读者借阅数据表格中的字段则对应为:读者证号、ISBN号、书名、作者、出版社等,这两个表格中的字段能有效关联和揭示,通过数据对比,挖掘读者的阅读兴趣与图书出版的关系,提高图书配置的可读性。
(2)利用数据关联规则寻找数据的共性与个性,找出影响图书配置主要因素的关联性。关联规则是分析数据集在事务集合中出现的频度关系[10]。简言之,数据挖掘中的关联规则技术能推导出一种从甲到乙的模式,即当甲事件发生时,乙事件会伴随发生,称为一种甲与乙的关联关系。如一个读者的借阅记录能反映他的阅读倾向,但一个专业或者一个班级的读者的借阅记录则能反映出他们共同的研究领域或阅读范围,此为多维关联技术。通过多维数据关联技术研究,能发现各个维度的关联度,找出影响馆藏图书配置因素的潜在关系,预测读者未来的阅读倾向或阅读领域,可以提前科学地配置图书。
(3)采用德尔菲法确定图书配置的影响因子权重。德尔菲法(Delphi)又名专家意见法,是依据系统的程序,采用匿名发表意见的方式,即团队成员之间不互相讨论,不发生横向联系,只与调查人员发生关系,通过多轮次调查专家对问卷所提问题的看法,经过反复征询、归纳、修改,最后汇总成专家基本一致的看法,并作为预测的结果。笔者通过德尔菲法预测图书优化配置模型的影响因子权重,得到的图书优化配置的主要影响因子及权重如表2所示。

表2 图书优化配置的主要影响因子及权重
(4)构建图书优化配置模型。根据影响因子、图书流通分析数据、读者分析数据和《中国图书馆分类法》,按馆藏图书22个大类,构建图书配置比例模型(见表3),并在图书配置实践中检验。运用此模型配置图书,对比图书借阅数据和采集到的其他读者数据来修正此模型,使之更符合馆藏图书建设。

表3 图书配置比例模型及实证表
4 图书优化配置服务创新机制
在大数据环境下,需要跨界思维,推进图书馆“互联网+”,再造图书馆图书资源配置与服务新流程。打破传统图书配置、图书阅读、图书推荐相脱节的弊端,通过读者大数据的挖掘、书目大数据的分析,建立图书馆新书推送机制及反馈机制,形成图书优化配置与推送服务的新格局。依靠大数据分析系统,将获取并分析的读者数据反馈给图书馆,优化图书配置模式,完善图书配置工作。通过数据的推送将图书配置结果发送给读者,读者在手机APP、电子邮箱、微信、新书网站、阅读推广QQ群等新媒体上能及时获取信息,解决目前图书采购、阅读、荐购相脱节的问题,实现图书服务的机制创新、读者借阅的智能创新、图书馆业务部门间协同创新,让图书馆服务更加智能化与合理化,从而形成图书优化配置与服务创新机制(如图3所示)。

图3 图书馆大数据的馆藏图书优化配置模型及图书优化配置服务创新机制
5 结语
挖掘并利用图书馆大数据是优化图书资源配置的有效途径。大数据内容丰富、结构复杂,不仅仅是一堆数字,隐含的更是技术,是思维和理念。大数据分析与研究,能捕捉现在信息,预测未来趋势,挖掘出更多的隐性价值,传统图书配置方法与模式无法做到这一点,因而无法面对现代社会对图书阅读的冲击。只有创新图书配置服务与工作流程,才能跟上时代潮流,满足读者需求,缓解图书阅读率逐年下降的趋势。
挖掘并利用读者大数据将改变图书馆与读者的信息交互模式,创新图书阅读服务模式,实现图书的精准购买与精准推送,让导读服务工作更专业。通过大数据获取读者的阅读偏好,分析读者的研究领域和方向,开展O2O服务,既可节约读者的时间,帮助他们及时完成学习、教学及科研工作任务,又可促进图书馆馆藏的转型与升级。未来馆藏图书配置工作的特点将呈现少而精、少而准、少而快的特点,而这一特征的实现,需要图书馆同仁不懈地努力和对大数据的深入研究与运用。
[参考文献]
[1]王波等.2015年高校图书馆发展概况[EB/OL].[2017-03-20].http://www.scal.edu.cn.
[2]中国新闻出版研究院.第十三次全国国民阅读调查数[EB/OL].[2016-04-09],http://cips.chinapublish.com.cn.
[3]王文君.重庆市高校图书馆读者荐购情况的调查与分析[J].图书馆学研究,2017(11):45-48.
[4]龚自振.近十年高校图书馆学科馆员参与选书研究综述[J].图书馆学刊,2014(6):129-131.
[5]刘华.“读者决策采购”在美国大学图书馆的实践及其对我国的启示[J].大学图书馆学报,2012(1):45-50.
[6]汪志莉,李欣,于亚秀.高校图书馆馆藏利用现状及对策数据评估—以华东师范大学图书馆为例[J].图书馆论坛,2017(3):116-122.
[7]史丽香.纸本图书PDA:境外图书馆的实践及其启示[J].图书馆杂志,2013(11):83-87.
[8]严雷风,张德馨.大数据研究[J].计算机技术与发展,2013(4):168-172.
[9]孟晓冬.电站锅炉大数据分析系统开发与应用[J].电站系统工程,2017,33(1):79-80,82.
[10]张炜.读者借阅行为的关联知识发现实证分析[J].图书馆工作与研究,2010(12):38-41.
