用于短文本关键词抽取的主题翻译模型
2018-06-19秦永彬闫盈盈
王 瑞,秦永彬,2,张 丽+,闫盈盈
(1.贵州大学 计算机科学与技术学院,贵州 贵阳 550025;2.贵州大学 贵州省公共大数据重点实验室,贵州 贵阳 550025)
0 引 言
短文本关键词抽取对于用户检索和定位符合自身需求的信息非常重要。然而,由于短文本特征过度稀疏,关键词抽取存在两个问题:①词汇差异问题:关键词在短文本中出现次数不多,甚至不出现。②主题相关性问题:由于短文本缺乏足够的上下文信息,很难保证抽取的关键词与短文本主题相关。针对以上两个问题,本文提出一种用于短文本关键词抽取的TTKE主题翻译模型。与传统方法相比,该模型能够有效地抽取短文本关键词。
1 相关工作
目前,关键词抽取方法主要分为两类:无监督方法和监督方法。
无监督方法首先选取一些候选关键词,然后通过一定策略对候选关键词进行排序,选择其中排名靠前的若干作为最终关键词。李鹏等利用了基于图模型的TextRank方法,该方法认为一个词语的重要程度由指向它的其它词语的重要程度决定,将图节点作为候选词,边作为词与词之间的共现关系,根据PageRank算法选出排名最高的若干作为关键词[1]。文献[2,3]提出的关键词抽取算法都是对TextRank的改进。
在有监督的方法中,关键词抽取被视作一个分类任务,首先使用训练数据来学习关键词抽取模型,其次,在测试数据上进行文本关键词抽取。Liu等提出利用决策树学习方法进行文本关键词抽取[4]。文献[5,6]分别提出了基于支持向量机和神经网络的关键词抽取方法。Zhang等利用条件随机场实现关键词的自动标注[7]。
上述两类方法仅依靠词汇的统计信息,未考虑文本内容与关键词的词汇差异问题以及主题相关性问题的影响。文献[8,9]利用LDA(latent dirichlet allocation)主题模型进行关键词自动抽取,解决主题相关问题,但未考虑词汇差异问题。Koeh和Knight考虑词汇差异问题,提出了IBM model-1方法,该方法能够有效学习词语和关键词的对齐概率,但忽视了主题相关问题[10]。Ding等考虑以上两类问题,提出TSTM(topic-specific translation model)主题翻译模型,该模型利用LDA进行主题发现,再计算词语与关键词的对齐概率[11],但是由于短文本的特征稀疏性问题,导致上述方法主题发现效果不佳,进而影响了关键词抽取的精度。因此,本文提出的TTKE主题翻译模型利用长文本降低短文本的特征稀疏,解决上述两类问题,提高短文本关键词抽取的效果。
2 TTKE模型
2.1 符号与定义
(1)一个词w是文本的基本单元,是词汇表 {1,2,…,V} 中的一项。
(2)一个关键词t是关键词词汇表 {1,2,…,T} 中的一项。
(3)一个主题k是 {1,2,…,K} 中的一项。
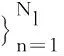
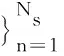
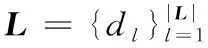
2.2 TTKE模型
TTKE模型是一个结合主题模型和翻译模型优点的关键词抽取模型。图形化表示如图1所示,流程如图2所示。

图1 TTKE模型的图形化表示
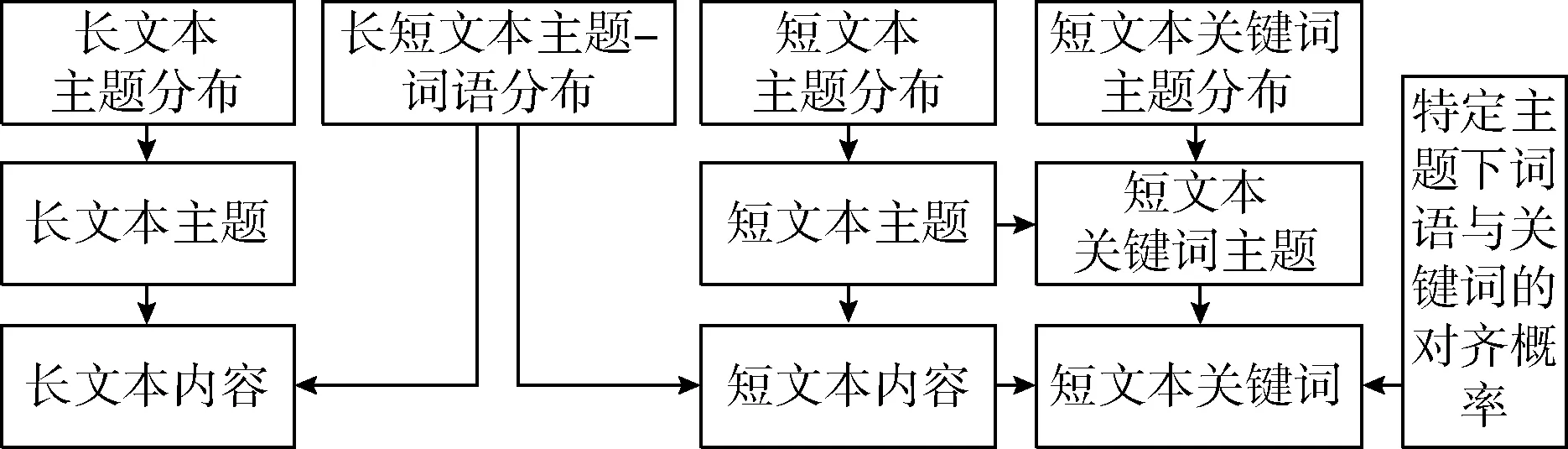
图2 TTKE模型的生成流程
该模型包括以下3个方面:
(1)与LDA主题模型相结合。TTKE模型认为:用户写一篇短文本s时,首先根据主题分布θs选择若干主题,然后根据每个主题下的词语分布φk选择词语。为短文本s标注关键词时,从该短文本的主题中选择若干主题,然后综合考虑选定的主题和短文本词语,进而标注关键词,保证了短文本与关键词的主题的一致性。
(2)与统计机器翻译模型相结合。TTKE模型基于短文本和关键词的主题一致性原则,学习特定主题下词语与关键词的对齐概率Q,实现为未标注关键词的短文本生成关键词的目的。
(3)利用与短文本主题相关的长文本。TTKE模型引入了辅助长文本降低短文本数据的稀疏性。长短文本共享相同的主题空间K和每个主题下词语的分布φk,将长文本丰富的词语信息迁移到短文本,改善短文本主题发现效果,进而影响对齐概率Q,提高短文本关键词抽取的效果。
根据图1和图2,TTKE模型假设如下的生成过程:
(1)对于每一个主题k:选择φk~Dirichlet(β);
(2)对于每一篇长文本dl:
1)选择Nl~Poisson(ξ);
2)选择θl~Dirichlet(α);
3)对于Nl中的每一个词wln:①选择主题zln~Multinomial(θl); ②选择wln~Multinomial(wln|zln,φ)。
(3)对于每一篇短文本ds:
1)选择Ns~Poisson(ζ)
2)选择θs~Dirichlet(α);
3)对于Ns中的每一个词wsn:①选择主题zsn~Multinomial(θs); ②选择wsn~Multinomial(wsn|zsn,φ)。
4)对于Ms中的每一个关键词tsm:①选择主题csm~Multinomial(ηs); ②选择关键词tsm~P(tsm|ws,csm,Q)。
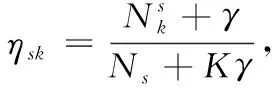
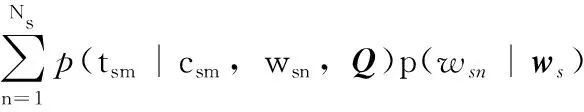
(1)
式中:p(wsn|ws) 是短文本ws中每个词语的权重,本文采用IDF(inverse document frequency)方式计算。
p(L,S,zL,zS,T,cS|α,β,γ,Q)=
p(zL|α)p(zS|α)p(L|zL,β)·
p(S|zS,β)p(cS|zS,γ)p(T|cS,S,Q)
(2)
3 参数估计以及推理
3.1 TTKE模型的学习
首先,采用Collapsed Gibbs方法给训练短文本集中的词语和关键词采样。
(1)对于长文本wl∈L中第n∈[1,Nl] 个词语,通过以下公式选择一个主题zln∈[1,K]
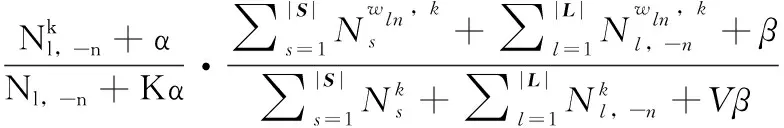
(3)
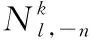
(2)对于短文本ws∈S中第n∈[1,Ns] 个词语,通过以下公式选择一个主题zsn∈[1,K]
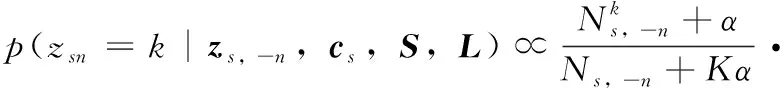
(4)
式中:Msk是短文本ws中主题为k的关键词的个数。其余符号解释与式(3)类似。
(3)对于短文本ws∈S中第m∈[1,Ms] 个关键词,通过以下公式选择一个主题csm∈[1,K]
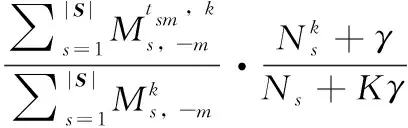
(5)
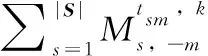
其次,当短文本中词语和关键词的主题稳定后,通过如下的公式估计特定主题下词语与关键词的对齐概率
(6)
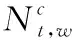
3.2 短文本关键词的抽取
首先,采用Collapsed Gibbs方法给测试短文本集中的词语进行主题标注
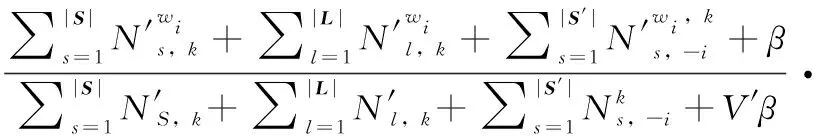
(7)
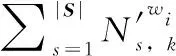
其次,短文本的词语的主题稳定之后,得到第s′篇短文本的主题分布
(8)
最后,利用主题分布和特定主题下的词语和关键词的对齐概率Q,通过如下的公式给测试数据集抽取关键词,第s′篇短文本中关键词m的概率为
(9)
4 实验结果与分析
4.1 实验数据集
为了验证TTKE模型的有效性,本文从新浪微博爬取了4个主题共53 171条包含用户标注关键词的微博作为短文本集,主题分别为“北京马拉松”、“iPhone6s”、“亚洲杯”、“花千骨”。在这些微博中,有12 121(22.79%)条微博包含网页链接,可访问的链接为9438(17.75%)条,因此,爬取这些可访问链接的内容作为长文本集。
本文随机选择12 000条微博,并选择与其主题相关的8000条辅助长文本组成实验所用的数据集WeiboSet,其中,10 000条微博作为短文本训练数据集,2000条作为短文本测试数据集。
对数据集进行分词、去停用词等文本预处理。数据集总结见表1。

表1 数据集介绍
注:L:长文本篇数;S:短文本篇数;K:主题个数;V:词汇库大小;T:关键词库大小;Nt:平均每条短文本的关键词的个数。
4.2 评价指标
本文采用准确率Precision,召回率Recall和综合指标F-measure作为关键词抽取效果的评价标准。计算公式如下所示
(10)
(11)
(12)
其中,Ncorrect为抽取正确关键词的数目,Nextract为抽取的关键词总数,Nall为文档标注的关键词数目。Precision和Recall的取值范围是0-1之间。越接近1表示结果越好,F-measure 为Precision和Recall的调和平均值。
4.3 对比实验及分析
TTKE模型初始化α=0.5,β=0.1,γ=0.5,K=4,每次实验的迭代次数为2000次,词语的IDF值为短文本词语重要度。本文将TTKE模型与LDA主题模型,IBM Mode-1翻译模型,TSTM主题翻译模型进行比较。LDA和TSTM的初始化设置与TTKE相同,IBM Mode-1使用GIZA++(http://code.google.com/p/giza-pp/)训练。
图3展示了不同关键词抽取方法的Precision-Recall曲线。曲线上的每个点表示抽取不同个数关键词的实验结果,由右至左的5个点表示抽取的关键词个数分别为1-5。一条Precision-Recall曲线越靠近右上方,说明该方法的效果越好。
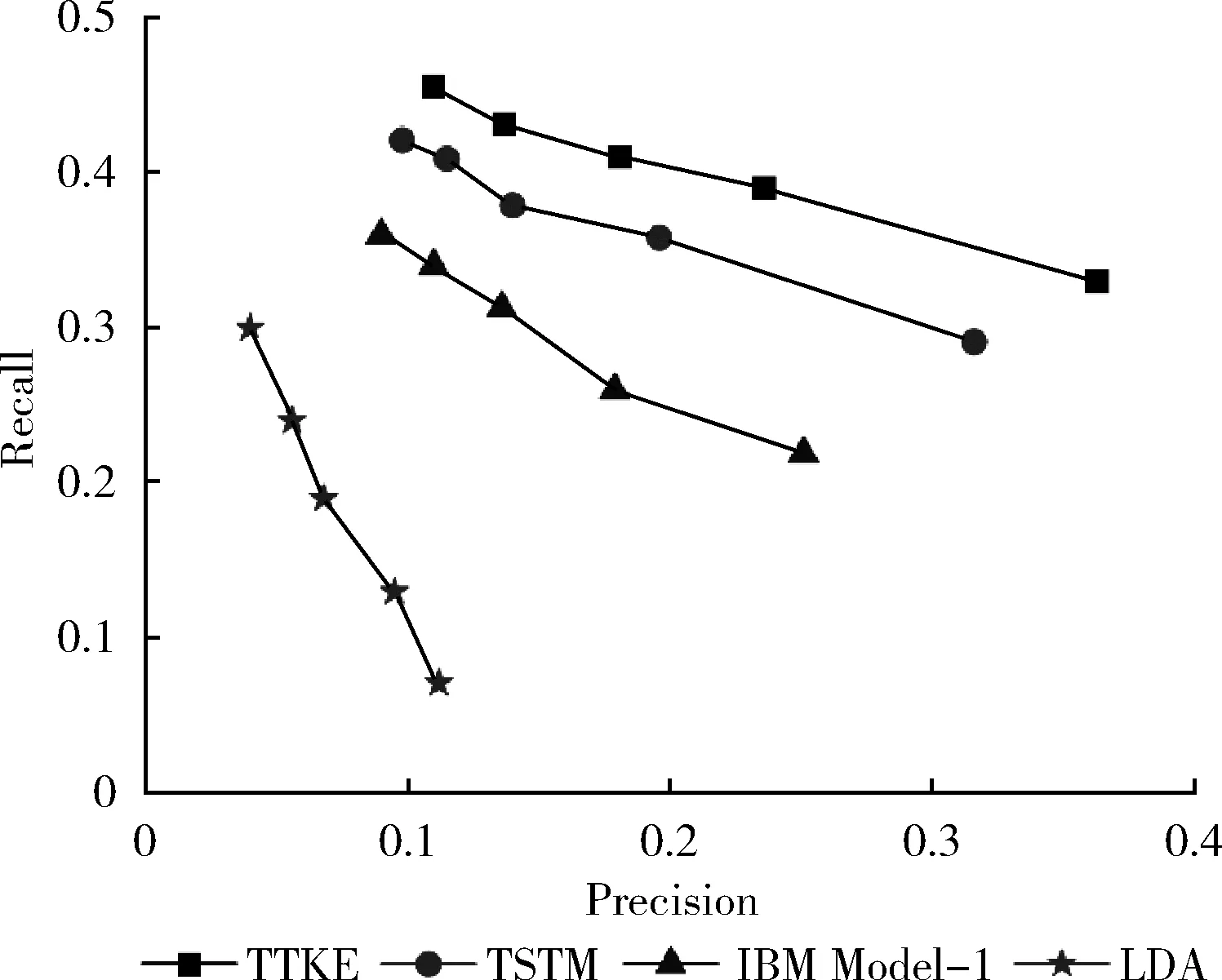
图3 不同关键词抽取方法的Precision-Recall曲线
由图3我们可以看出:当关键词个数由5下降为1时,所有模型的Precision-Recall曲线呈现下降趋势。原因是WeiboSet数据集每篇短文本平均关键词个数是1.08个,当为每篇短文本抽取出的关键词个数下降时,各模型抽取出的关键词会包含更少的文档已标注好的关键词,召回率降低,准确率升高。当抽取出的关键词个数固定时,TTKE实现了最好的短文本关键词抽取效果,其余依次为TSTM,IBM Mode-1和LDA。
与TSTM模型相比,TTKE模型在做短文本关键词抽取时,曲线最接近右上角,因此表明实验效果最好。其原因是TSTM直接利用LDA对短文本进行主题发现,但是由于短文本字数较少,特征过度稀疏的问题,主题发现效果一般,影响模型学习特定主题下词语与关键词的对齐概率。而本文所提出的TTKE模型利用长文本辅助短文本进行主题发现,在主题发现效果上得到提升,并使得模型学习到的特定主题下词语与关键词的对齐概率更为精准,提高了短文本关键词抽取的精度。
IBM model-1模型的曲线位于TSTM和TTKE的下方,说明它比TSTM和TTKE模型的效果差。因为IBM model-1仅依赖于统计词语和关键词的共现次数,忽略了短文本词语与关键词的主题不相关问题。在短文本中,由于短文本字数少,词语与关键词的翻译过程容易出现歧义,从而导致主题不相关问题。而TSTM和TTKE模型中,引入的主题模型可以使抽取出的关键词与原文本主题一致,提高关键词抽取的效果。
LDA模型的曲线位于最下方,相较于以上3种模型斜率较大,说明当抽取的关键词个数变化时,LDA的抽取效果变化较大,稳定性差,并且整体的抽取效果最差。造成这种结果的主要原因是LDA根据特定主题下的关键词分布对候选关键词排序,忽视了短文本中具体的词语信息。所以LDA模型只能抽取泛化的关键词,但泛化的关键词显然不是我们想要的结果。
4.4 参数影响
由于TTKE使用LDA的过程中,主题个数需要在实验前给定,因此我们考虑了主题数对于实验结果的影响。针对WeiboSet数据集,我们讨论当主题个数K取2,4和10时,TTKE模型对于关键词抽取的效果。实验结果见表2。
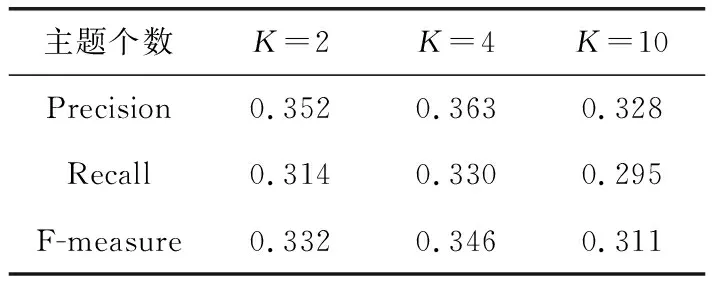
表2 主题个数对TTKE模型关键词抽取的影响
由表2可以看出,当主题个数K被设置为真实主题数目时,即K=4时,TTKE模型取得了最好的效果。而当主题的个数小于真实主题数目时,效果会相对较差,原因是较少的主题个数导致主题泛化,特定主题下词语与关键词的对齐概率不精准,抽取到的关键词很可能与原短文本的主题相关性不大。当主题个数大于真实主题数目时,TTKE模型的关键词抽取效果下降,主要原因是计算特定主题下短文本词语和关键词的对齐概率时,较大的主题个数会加剧数据的稀疏性,计算的对齐概率也同样不精确,降低关键词抽取效果。
此外,TTKE模型假设长文本与短文本的主题是相关的。因此,我们讨论长文本与短文本主题相关度变化时,对短文本关键词抽取效果的影响。本文使用相关度不同的5种数据集,分别为Weibo_1,Weibo_2,Weibo_3,Weibo_4和Weibo_5。其中,Weibo_1数据集中,长文本与短文本的相关度为0.2,即主题相关的长文本数量占WeiboSet中长文本数量20%,其余为主题不相关的长文本。同理Weibo_2,Weibo_3,Weibo_4的相关度分别为0.4,0.6和0.8,Weibo_5使用WeiboSet全部的长文本集,即相关度为1.0。5种数据集中的短文本集与WeiboSet相同。本实验设置抽取的关键词个数为1,利用F-measure衡量短文本关键词抽取的效果。
由图4我们可以看出:长文本与短文本的相关度越高,实验的F-measure值越高,即短文本关键词抽取效果越好。实验结果表明使用长文本辅短文本进行关键词抽取是有效的。
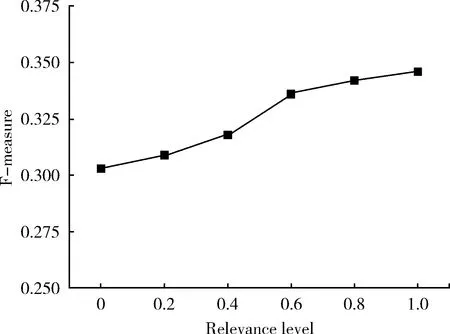
图4 不同长短文本主题相关度的关键词抽取效果
4.5 实例分析
以“iPhone6S真机曝光:厚度略上升摄像头仍突出”这条微博为例,展示LDA,IBM model-1,TSTM,TTKE这4种模型在短文本关键词抽取中的效果。本文列举了各个方法抽取到的5个关键词,使用(×)来表示抽取出的不合适的关键词。由表3,我们可以看出LDA模型抽取出的关键词大多以苹果手机为主题,抽取出了苹果,iPhone6SPlus,iPhone6,虽然这些关键词主题相关,但与这条微博所要讲的真实内容关系不大。IBM model_1模型也会抽取出一些质量不高的关键词,原因是该模型仅考虑到词语和关键词的共现关系,而没有考虑短文本主题的信息,其中关键词“苹果”是由词语“iPhone6S”翻译而来,外观是由“厚度略上升摄像头仍突出”翻译而来。TSTM模型对关键词抽取的结果较好,但由于短文本的特征稀疏性问题,直接使用LDA模型对短文本进行主题发现导致抽取出了主题相关但内容与这条微博不相关的关键词,例如“ios”。TTKE模型的关键词抽取效果最好,抽取出的关键词在主题上与内容上都与这条微博相关度更大,这表明本文提出的TTKE模型能够有效地解决由短文本特征稀疏问题导致的短文本内容和关键词的词汇差异与主题不一致性问题。
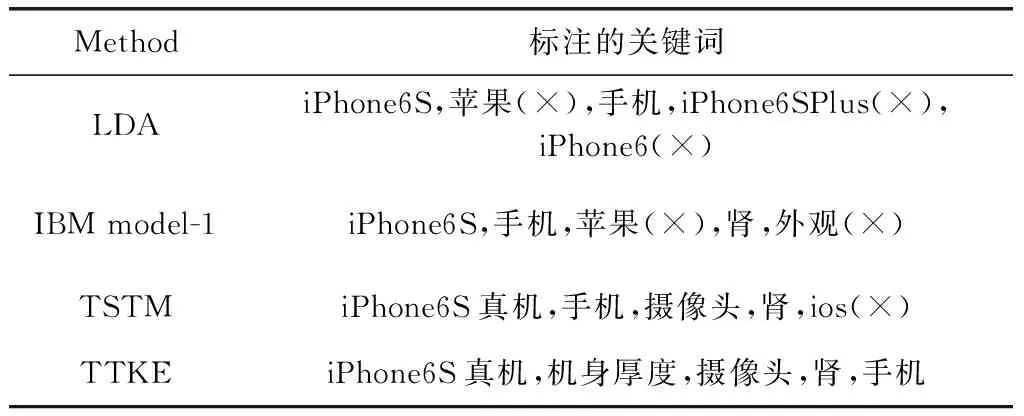
表3 不同关键词抽取方法的标注
5 结束语
本文提出了一个用于短文本关键词抽取的TTKE主题翻译模型。该模型与LDA模型相结合,利用辅助长文本提高短文主题发现效果,并与翻译模型相结合,提高特定主题下词语与关键词对齐概率的精准度。大量的实验结果表明,TTKE模型能够有效提高短文本关键词抽取的效果。在未来,我们将研究短文本关键词抽取在实际中的应用,以及如何使用关键词抽取技术构建领域知识图谱。
参考文献:
[1]LI Peng,WANG Bin,SHI Zhiwei,et al.Tag-TextRank:A webpage keyword extraction method based on Tags[J].Journal of Computer Research and Development,2012,49(11):2344-2351(in Chinese).[李鹏,王斌,石志伟,等.Tag-TextRank:一种基于Tag的网页关键词抽取方法[J].计算机研究与发展,2012,49(11):2344-2351.]
[2]GU Yijun,XIA Tian.Study on keyword extraction with LDA and TextRank combination[J].New Technology of Library and Information Service,2014,30(7):41-47(in Chinese).[顾益军,夏天.融合LDA与TextRank的关键词抽取研究[J].现代图书情报技术,2014,30(7):41-47.]
[3]NING Jianfei,LIU Jiangzhen.Using Word2vec with Text-Rank to extract keywords[J].New Technology of Library and Information Service,2016(6):20-27(in Chinese).[宁建飞,刘降珍.融合Word2vec与TextRank的关键词抽取研究[J].现代图书情报技术,2016(6):20-27.]
[4]Liu J,Zou DS,Xing XL,et al.Keyphrase extraction based on topic feature[J].Application Research of Computers,2012,29(11):4224-4227.
[5]Danilevsky M,Wang C,Desai N,et al.KERT:Automatic extraction and ranking of topical keyphrases from content-representative document titles[J].Computer Science,2013.
[6]Zhang Q,Wang Y,Gong Y,et al.Keyphrase extraction using deep recurrent neural networks on twitter[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing,2016:836-845.
[7]Zhang C.Automatic keyword extraction from documents using conditional random fields[J].Journal of Computational Information Systems,2008,4.
[8]LIU Xiaojian,XIE Fei.Keyword extraction method combining topic distribution with statistical features[J].Computer Engineering,2017,43(7):217-222(in Chinese).[刘啸剑,谢飞.结合主题分布与统计特征的关键词抽取方法[J].计算机工程,2017,43(7):217-222.]
[9]Cho T,Lee JH.Latent keyphrase extraction using LDA model[J].Journal of Korean Institute of Intelligent Systems,2015,25(2):180-185.
[10]Koehn P,Knight K.Statistical machine translation[P].US:US7624005,2009.
[11]Ding Z,Zhang Q,Huang X.Automatic hashtag recommendation for microblogs using topic-specific translation model[C]//Coling:Posters,2012:265-274.
