Kinect与二维激光雷达结合的机器人障碍检测
2018-06-11肖宇峰
肖宇峰,黄 鹤,郑 杰,刘 冉
(西南科技大学信息工程学院 四川 绵阳 621010)
作为移动机器人感知环境、自主导航的基础,障碍物检测是实现正确运动控制的重要依据。传统的障碍物探测通常采用激光传感器、超声传感器或红外传感器等非视觉器件,具有抗干扰能力强、可全天候工作的优点,然而这些传感器采集的数据单一,机器人很难准确探测周围环境的三维信息[1-2]。作为无人驾驶系统中环境感知的重要功能单元,三维激光雷达可较好地检测周围环境三维信息,但因其成本较高,目前较难大范围应用[3]。
相比之下,基于视觉的环境感知技术具有成本低、信息丰富的优点,并得到了广泛研究[4-5]。然而,视觉传感器易受环境影响、检测精度低:基于单目视觉的环境感知方法具有受环境影响较大、检测精度低和视野范围小的缺点[6];而基于双目视觉的环境感知方法易出现多义性[7-8]。鉴于这些问题,有研究者把视觉和激光检测方法结合起来,在增强环境适应性的同时提高检测精度[9]:文献[10]把车载相机和二维激光雷达结合起来,较好地探测了障碍物位置和形状,以较低成本辅助智能车无人驾驶;文献[11]把二维激光雷达与视觉融合起来,较好地解决了车轮打滑时的位姿丢失问题,并能较好检测出地面负障碍物。
相比单目和双目相机,Kinect相机能以简捷方式和较低成本提供环境深度数据[12]。利用这一优点,本文提出在移动机器人上同时安装二维激光雷达和Kinect相机,把激光扫描和深度图像结合起来检测障碍物。这种障碍物检测方法不仅具备二维激光雷达平面探测范围广、精度高、实时性好的特点,而且兼有Kinect深度相机三维探测的优势。具体步骤是:首先,二维激光雷达与深度相机分别从周围环境中获取二维激光数据和三维深度图像;然后,将深度图像转换成虚拟二维激光数据;最后,对虚拟二维激光数据与二维激光雷达数据进行融合,得到障碍物的三维位置。本文通过实物测试验证了该方法正确有效,可用于移动机器人对环境障碍物的判断。
1 整体系统框架
图1为本文的研究平台,在改造的Turtlebot机器人平台上搭载一台Kinect相机,并在其上方安装一台Hokuyo UTM-30LX激光雷达。激光雷达和Kinect相机结合的工作思路如图2所示,Kinect相机从周围环境中采集深度图像,经过“深度图像转换模块”转换成虚拟激光测距数据;二维激光雷达从周围环境中采集二维平面的激光测距数据;“测距数据融合”模块把虚拟激光测距数据和激光测距数据整合得到障碍物位置,并提交给“机器人导航模块”。

图1 系统工作平台

图2 系统工作思路
2 二维激光雷达与Kinect相机联合标定
对于环境中的障碍物,二维激光雷达和Kinect相机各有不同的表示形式。图3给出了同时处在激光雷达坐标系(OLXL YLZL)与Kinect相机坐标系(OKXK YKZK)的目标点P,坐标分别为(xL,yL,zL)和(xK,yK,zK),P点在图像平面坐标系(XPOP YP)中的投影P′坐标为(u,v)。通过标定找到激光雷达坐标系与Kinect图像坐标系之间的关系,才能准确融合激光雷达测距数据与Kinect深度图像数据。

图3 激光雷达与Kinect相机坐标系
2.1 激光雷达坐标系与Kinect坐标系的关系
P点在(OLXL YLZL)下的坐标为(xL,yL,zL),根据激光雷达坐标系与Kinect坐标系的几何关系,得到坐标关系为:

式中,R是旋转矩阵;T是平移矩阵。Kinect相机采集得到的数据不是P点坐标(xK,yK,zK),而是P′点像素坐标(u,v)和对应的深度值zK;激光雷达采集得到的不是P点坐标(xL,yL,zL),而是距离r和角度α。可以通过下面两小节分析得到(xK,yK,zK)与像素点三元组(u,v,zK)的对应关系、(xL,yL,zL)与测距点二元组(r,α)的对应关系。
根据经典相机模型[6],P点在(OKXK YKZK)下的坐标为(xK,yK,zK),其在图像平面投影为P′,用像素表示坐标为(u,v),可以得到Kinect坐标与像素点三元组的关系为:
2.2 Kinect坐标与像素点三元组的关系

式中,fx、fy是X轴和Y轴方向上以像素为单位的等效焦距;cx、cy是基准点。这些都是相机参数,可以采用标准的相机参数标定方法计算出。
2.3 激光雷达坐标与像素点三元组的关系
综合式(1)与式(2),可以得到像素点三元组与激光雷达坐标的关系为:

对于激光雷达,保持极坐标系与平面直角坐标系(OLXLZL)在同一个平面内,原点同为激光雷达中心,激光束与ZL轴正向夹角为极坐标角度α(激光束偏角值),激光束测距值为极坐标径向值r(激光雷达当前测距值),如图4所示。

图4 激光雷达的直角坐标与极坐标关系
激光测距点二元组(r,α)与直角坐标(xL,yL,zL)的关系为:

对于像素点P′的图像坐标(u,v),保持激光雷达坐标原点与Kinect相机坐标原点在Y轴方向的垂直高度差为l,则有像素点三元组(u,v,zK)与激光雷达测距点二元组(r,α)的关系为:

在确定相机参数后,把多对像素点三元组和测距点二元组代入式(5),通过求解线性方程组得到未知的R、T矩阵,进而确定激光雷达坐标系与Kinect相机坐标系的旋转平移关系,完成联合标定。
3 深度图像转换
本文中,Kinect相机采集得到深度图像后,深度图像转换模块把图像中转换窗口的每个像素列上深度值最小的像素点距离和角度提取出来,相当于将部分或者全部深度图像向中心平面压缩,在中心平面上形成一系列虚拟激光点。图5a为Kinect相机采集到的RGB图像;图5b为深度图像与转换窗口,s表示窗口第一个转换像素行号,h表示转换窗口高度(单位为像素行),RGB图像 (u0,v0)点对应深度图像的(u,v)点。
假设当前需要转换的像素在第u个像素列,该列所有像素点被转换成一个虚拟激光点,该点在所有虚拟激光点中的序号是j,激光点距离值为:
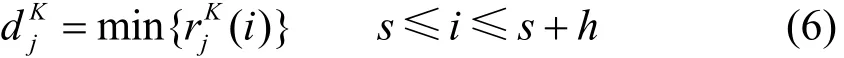
式中,表示OK与目标点P的虚拟激光点(P点在中心平面上的投影)距离,具体计算方法参照图6所示模型。P在深度图像的对应点P′(u,v),其在中心平面的投影点A就是虚拟激光点,C是OK的投影,那么,线段AO的长度就是。

图5 Kinect相机图像
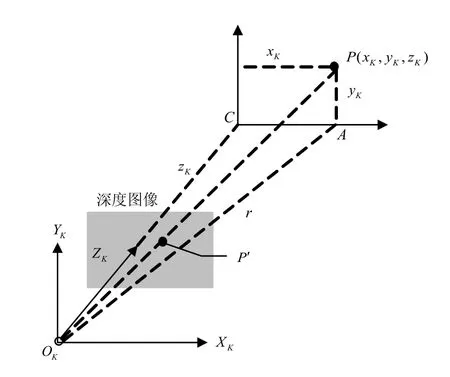
图6 Kincet相机的虚拟激光测距
具体计算(i)的步骤如下:
1) 获取P在 Kinect坐标系下坐标P(xK,yK,zK),zK是P′的深度值;
2) 计算直线AOK和COK夹角β为:

3) 二维激光点的计算。
如果Kinect相机观测角范围为 (βmin,βmax),沿AC轴向可转换成M个虚拟激光点,那么,P对应虚拟激光束的序号为:

4) 计算A到相机原点KO的距离为:
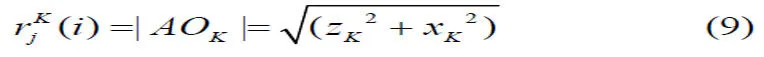
4 深度图像与二维激光雷达数据融合
设激光雷达扫描得到的测距二元组集合为DL,融合Kinect采集得到的三元组信息后的测距二元组集合为DF。图3中,P为DL中第i个测距点,其测距二元组为(dL,α) ,由式(1)和式(4)可得P在(OKXK YKZK)下的坐标为:

利用第3节的方法,由(xK,yK,zK)得到P对应虚拟激光雷达测距数据d。于是,可得到融合后第i束激光测距二元组为:

当Kinect相机与二维激光雷达同时工作,按照上述方法得到所有融合后的测距二元组集合DF。一般情况下二维激光雷达的激光测量角度大于Kinect相机观测角度,即 [βmin,βmax]⊂ [αmin,αmax],从而DF为:式中,Δβ表示Kinect相机的虚拟二维激光角增量;Δα代表激光雷达的角增量。深度图像与二维激光雷达数据融合算法伪代码为:

输入:DL//原始激光扫描二元组集合
输出:DF//融合Kinect数据的二元组集合


其中,FuseRangeKinect()是主框架;GetNextElement()为从原始激光扫描点集LD返回下一个二元组;LaserTOKinect()实现式(10);Insert()向融合激光点集FD中添加一个二元组。
5 实验测试
为验证本文方法正确有效,在图1的机器人平台上实现了上述环境障碍检测算法:主控计算机处理器为酷睿六代i7,主频为2.5 GHz,操作系统采用Ubuntu并运行了ROS系统;二维激光雷达为Hokuyo UTM-30LX,最大测距值30 m,角分辨率是0.25°,测距精度能达到30 mm,最大扫描角度是270°。
图7给出了本文方法的测试结果,图7a为Kinect相机采集的环境RGB图像,图7b为相机采集的深度图像。本文通过4组测试对比二维激光雷达、Kinect相机和本文方法的障碍物检测结果。
1) 第1组测试:图7c表示h=50的测量区域,此时转换窗口很小,只能检测到桌面上的物品;图7d表示h=50的障碍物边缘比较图,其中点划线为激光雷达检测到的障碍物边缘(来自LD),点线为Kinect相机检测到的障碍物边缘,细实线为融合得到的障碍物边缘(来自于FD)。对比可发现,因为Kinect相机检测角度小于激光雷达,其检测出的障碍物边缘范围也小于激光雷达和融合方法;因为转换窗口很小,融合方法跟激光雷达一样没有发现桌子边沿、垃圾桶和纸箱。
2) 第2组测试:图7e表示h=100的测量区域,转换窗口高度有所增大,检测到了桌面弧形边沿,图7f表示h=100的障碍物边缘比较图。对比可发现,随着转换窗口增大,融合方法和Kinect相机可发现桌子边沿,但激光雷达依然不行。
3) 第3组测试:图7g表示h=180的测量区域,转换窗口高度继续增大,检测到纸箱;图7h表示h=180障碍物边缘比较图。对比发现,随着窗口继续增大,融合方法和Kinect相机可发现地面纸箱,相比Kinect,融合方法还能检测更宽的范围。

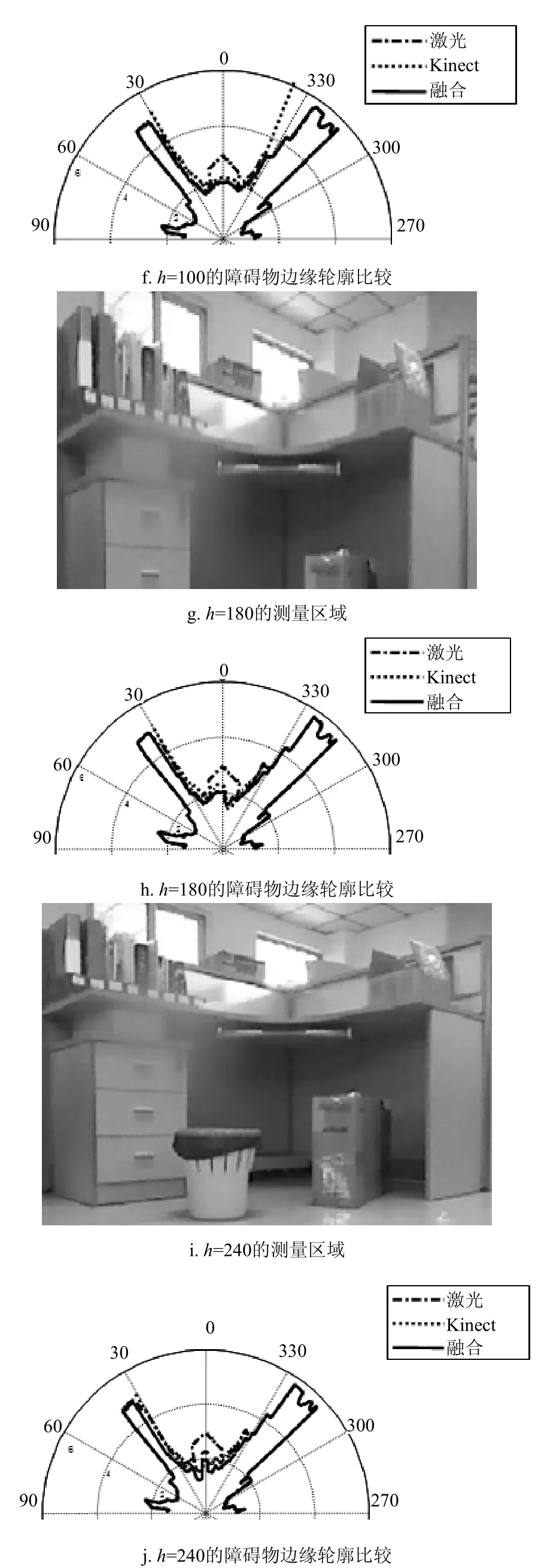
图7 障碍物检测实验
4) 第4组测试:图7i表示h=240的测量区域,转换窗口高度进一步增大,进而检测到地面垃圾桶;图7j表示h=240的障碍物边缘比较图。对比可发现,随着转换窗口进一步增大,融合方法和Kinect相机可发现地面纸篓,相比Kinect相机,融合方法还能检测更宽的范围。
由4次实验对比可见,本文的融合方法不仅能更准确地检测到环境中的障碍物,而且还具有较宽的检测范围,是一种成本较低的三维障碍检测方法,适合移动机器人在局部区域移动时避障。
6 结束语
针对现有视觉传感器探测障碍物时易受环境影响、检测精度低的问题,本文提出了一种结合Kinect相机和二维激光雷达判断障碍物的方法,具备了二维激光雷达平面探测范围广、精度高、实时性好的特点,同时兼有Kinect相机廉价的三维测量优势。在改造的Turtlebot机器人平台上,验证了该方法的正确性和有效性。
[1]MANSOUR S M B, SUNDARAPANDIAN V, NACEUR S M. Design and control with improved predictive algorithm for obstacles detection for two wheeled mobile robot navigation[J]. International Journal of Control Theory &Applications, 2016, 9(38): 37-54.
[2]彭梦. 基于多传感器融合的移动机器人障碍物检测研究[D]. 长沙: 中南大学, 2007.PENG Meng. Research on obstacle detection of mobile robots based on multi-sensor information fusion[D].Changsha: Central South Uuniversity, 2007.
[3]邹斌, 刘康, 王科未. 基于三维激光雷达的动态障碍物检测和追踪方法[J]. 汽车技术, 2017(8): 19-25.ZOU Bin, LIU Kang, WANG Ke-wei. Dynamic obstacle detection and tracking method based on 3D lidar[J].Automobile Technology, 2017(8): 19-25.
[4]KELLER C G, ENZWEILER M, ROHRBACH M, et al. The benefits of dense stereo for pedestrian detection[J]. IEEE Transactions on Intelligent Transportation Systems, 2011,12(4): 1096-1106.
[5]YU Q, ARAUJO H, WANG H. A stereovision method for obstacle detection and tracking in non-flat urban environments[J]. Autonomous Robots, 2005, 19(2):141-157.
[6]李启东. 基于单目视觉的机器人动态障碍物检测与壁障方法研究[D]. 长春: 吉林大学, 2016.LI Qi-dong. Research on robot dynamic obstacle detection and obstacle avoidance method based on monocular vision[D]. Changchun: Jilin University, 2016.
[7]冯瑾. 基于双目立体视觉的移动机器人障碍物检测技术研究[D]. 徐州: 中国矿业大学, 2015.FENG Jin. Research on technology of mobile robot obstacle detection based on binocular stereo vision[D]. Xuzhou:China University of Mining and Technology, 2015.
[8]MANE S B, VHANALE S. Real time obstacle detection for mobile robot navigation using stereo vision[C]//Proceedings of the International Conference on Computing, Analytics and Security Trends. [S.l.]: IEEE, 2016: 101-105.
[9]CHEN X, REN W, LIU M, et al. An obstacle detection system for a mobile robot based on radar-vision fusion[C]//Proceedings of the 4th International Conference on Computer Engineering and Networks. [S.l.]: Springer International Publishing, 2015: 677-685.
[10]张双喜. 基于雷达与相机的无人驾驶智能车障碍物检测技术研究[D]. 西安: 长安大学, 2013.ZHANG Shuang-xi. Research on obstacle detection technology based on radar and camera of driverless smart vehicles[D]. Xi’an: Chang’an University, 2013.
[11]汪佩, 郭剑辉, 李伦波, 等. 基于单线激光雷达与视觉融合的负障碍检测算法[J]. 计算机工程, 2017, 43(7):303-308.WANG Pei, GUO Jian-hui, LI Lun-bo, et al. Negative obstacle detection algorithm based on single line laser radar and vision fusion[J]. Computer Engineering, 2017,43(7): 303-308.
[12]薛彦涛, 吕洪波, 孙启国. 基于Kinect深度数据的移动机器人障碍检测方法研究[J]. 计算机测量与控制, 2017,25(2): 61-63.XUE Yan-tao, LÜ Hong-bo, SUN Qi-guo. Mobile robot obstacle detection method based on depth data of Kinect[J]. Computer Measurement & Control, 2017, 25(2):61-63.
