古代疫病中方剂核心药物的发现算法比较
2018-06-09黎钲晖郑晓梅刘迪
黎钲晖,郑晓梅,刘迪
(南京中医药大学信息技术学院,江苏 南京 210023)
0 引言
疫病,即现代医学中所说的流行病,而古代疫病则是古代传染疾病的总称,在人类的疾病斗争史上曾留下浓墨重彩的一笔。对于各种自然史资料,古代疫病的文献资料就是其中很重要的组成部分之一。
20世纪90年代以来,与以往通史性的、单一疫种流行史的研究不同,研究者不再局限于粗略的历史考察,而是深入于某一地区,对疫病流行的时空规律进行研究,或者将某次大疫置于自然和社会背景中进行考察,探讨疫病暴发和流行的深层次原因。[1]同时,同种或者相似疫病的用药也成为了研究的重点之一。对相似疫病的社会背景、时空和用药规律进行深入研究,不仅可以找出古代疫病的核心药物,也对现代医学用药配伍提供了重要的借鉴作用[2]。
现在越来越多的研究人员将数据挖掘方法运用到中药方剂的挖掘中。这些研究包括药物组合规律、症状组合规律等。然而中药数据主要运用自然语言描述且经历各个历史朝代变化和累计,导致挖掘面临许多困难,归结起来主要分3点。第一点:中药方剂数据存在很多不规范的地方,如同种药物有多种药名。第二点:中药方剂数据库的数据量很大。第三点:中医方剂数据中存在大量的冗余数据[3]。
核心药物指的是在给定病症x的前提下,对治疗该病症起重要作用的药物。这类药物一般在治疗x病症的方剂中使用较多,在其他方剂中使用较少[4]。核心药物的发现不仅可以发现某种疫病的用药规律,更为其他病症的药物配伍规律提供了参考和借鉴。
如今,中药核心药物的发现算法主要以基于效用度的挖掘算法为主,基于药物效用度的核心药物发现算法、基于带药对效用度的点式互信息(pointwise mutual information with herb pair ED,PMIED)的药物组网算法、基于重叠社团的高效药物配伍规律发现算法等。本次研究采用的是网页排名研究中常用的PageRank算法与文章核心词汇研究中常用的逆词频算法。前者易于发现不同药物在同种疫病中相对于其他药物的等级和重要性,后者易于发现不同药物在某种疫病中相对所有疫病的特殊性,通过两种算法的比较分析可以有效分析出某种疫病的常用和特殊药物组合。
从挖掘单一关系到挖掘多关系,数据挖掘技术实现了研究方法的巨大飞跃。同样,对于数据集合来说,数据容量更加庞大,存储结构更加复杂,数据种类也不再单一。[5]核心药物的发现对于我们研究核心药物与疫病影响因素的显著性分析奠定了基础,多角度、多维度对数据进行挖掘有利于揭示更深层次的中药规律。
1 资料与方法
1.1 数据来源
收集《万病回春》、《简明医彀》、《古今医统大全》等古代医书籍中提取和疫病有关的部分,将其分组归类,对描述的方式进行归一化、标准化,最终的数据库中包含的年代、病名、地域、季节、环境、病因、病例数、年龄、体质、性别、症状、证型、病机、治法、方剂、剂型、组成及剂量、用法、其他疗法、疗效。所有的字段都以古代疫病为基础从医书中找出的的相关影响因素。
1.2 数据预处理
(1)去除冗余数据。本次分析研究只针对古代疫病的方剂数据以及各种影响因素,从分析所需的规范数据考虑,去除古书中无关的数据,如疫病的治疗过程、方剂的配置过程、某种药物的采集过程等等。
(2)数据规范化。因为书籍记录并不是十分完整,所以我们需要对其进行规范化,将各种不同的专业描述统一为现代的描述方式,将残缺的数据分类,少量残缺可以用中值或平均值进行填补,大量的残缺则从标准库中删除。
规范化后的数据只有疫病名称、疫病来源、疫病的发生朝代、病因、疫病的方剂数据(详细药物信息,包括药物名称、用量)。
2 实验方法
2.1 PageRank算法
2.1.1 概述
PageRank算法是一种在研究网页重要性排名中常用的算法。这种算法运用了传统文献引文的分析思想,提出了一个假设,即网页的重要性和质量可以通过其他网页对其超文本链接的数量来衡量。具体来说,假如网页A有一个指向网页B的链接,则意味着网页A认为网页B是重要的。假如有10个网页指向网页A,而指向网页B的链接却只有2个,则说明网页A比网页B更加重要[6]。
一个页面的得票数由所有链向它的页面的重要性来决定,到一个页面的超链接相当于对该页投一票。一个页面的PageRank是由所有链向它的页面(链入页面)的重要性经过递归算法得到的。一个有较多链入的页面会有较高的等级,相反如果一个页面没有任何链入页面,那么它没有等级[7]。
PageRank的基本思想比较简单,一个网页的重要性由数量和质量共同决定:
(1)数量:在网页排名算法中,指向某一个页面的网页数量如果越多,则说明这个网页越重要。
(2)质量:网页的权重也受到指向它的页面的质量的影响,一般而言一个网页由越重要的网页指向它,则说明该网页也很重要,质量较高。
基于中药方剂中药物的关联性,网页排名的方法也可运用到核心药物的发现上,同种疫病中一种药物的重要性由药物在这种疫病的所有方剂中出现次数和与这种药物和其他药物的搭配规律共同决定。
原理:事先初始化所有代排序的网页的PR值,PR值很大程度上代表了一个网页被访问的概率,初始值一般是1/N(N为网页总数),即网页个数的倒数。此外,所有待排序的网页PR值和为1。
初始化完成,通过一种基于特征量的算法循环迭代,直到每个网页的值趋于稳定区间内,最终得到待排序网页的PR值,也就是各个网页的重要度。
2.1.2 计算
(1)初始化:假设有4个待排序的网页,ABCD,那么每个网页的初始PR值置为1/4,如果其中指向A的有BD,则A的PR为PR(A)=PR(B)+PR(D)。
假设C指向BCD,而D指向AC,则PR(A)=PR(B)+PR(C)/3+PR(D)/2;
为了准确表示网页权重,我们在计算某个网页PR值的时候通常用该网页的PR值除以它所指向的所有网页个数。计算公式如下(其中L(x)代表x所指向的所有网页个数):
PR(A)=PR(B)/L(B)+PR(C)/L(C)+PR(D)/L(D)[8];
(2)修正:增加阻尼系数,把没有任何指向 的 网 页PR置0。PR(A)=(PR(B)/L(B)+PR(C)/L(C)+PR(D)/L(D))*Q+1-q[8];

(3)计算:P1,P2,P3,……PN是待排序的页面,M(pi)是指向pi页面的数量,L(pj)是pj指向的所有页面的数量,而N是待排序的所有页面的数量。PageRank值是一个特殊矩阵中的特征向量。
1)这个特征向量为:

每个网页指向下图
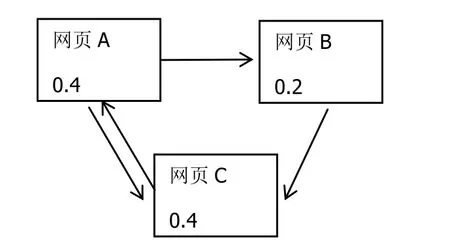
用一个矩阵表示网页之间的指向关系,如果页面i有指向页面j,则pij=1,否则pij=0。如下图所示,如果所有待排序的网页个数为N,则矩阵的大小为N*N。
我们把方剂中的每种药物看成一个网页,同一个方剂中的药物都两两建立起连接,如一个方剂中有药物a,b,c,则表示药物的邻接矩阵中pab,pba,pac,pca,pbc,pcb都置 1。
然后将每一行除以该行非零数字之和则得到新矩阵P’(概率矩阵),如图3所示。这个矩阵记录了每味药物在一种方剂中出现的概率,即其中i行j列的值表示i药物和j药物同时出现在一种方剂中的次数。

将P’转置得到概率转移矩阵
2)eet/N为:

3)A矩阵为:q×P+(1-q)*eet/N=0.85×P+0.15*eet/N[8]

初始每味药物的PageRank值均为1,即X~t=(1,1,1)[8]。
然后是循环迭代计算PageRank的过程[8]

因为X与R的差别较大。继续迭代[8]。

直至最后两次的结果差距在允许误差范围内,R趋于平稳,则循环迭代停止。最终R矩阵中的值就是待排序页面(药物)的PR值[8]。
2.2 基于效用度的核心药物发现算法
挖掘中药方剂的核心药物、配伍规律,有利于了解中药精髓,并进一步发现中药的药理作用。利用效用度研究方法挖掘核心药物,可将药物配伍规律的研究范围明显缩减至所发掘的核心药物,减少计算量[9]。文档关键词的检索正借鉴了这种方法。
关键词是指文档中具有专指性且能够反映文档主题的词语或短语。采用自动化技术从文档中抽取出关键词的过程称为关键词自动抽取。关键词自动抽取是文本自动处理中分类、检索和文摘等工作的基础与关键技术之一[10]。
在信息检索中常常用词频tf和逆文档词频idf的乘积来表示一个词在某篇文档中的重要性[10]。一般而言,如果某个词在某篇文档中出现次数比较多,它也许比较重要;如果某个词在所有文档中出现次数也很多,那么它的重要性也许不高。如果一个词在某篇文档中出现次数较多,而同时它在所有文档中出现次数较少,则我们可以认为这个词在这篇文档中的重要性比较高。我们可以把这种思想运用到不同方剂找核心药物中:如果某味药在某种疫病的方剂中出现次数较多,而在所有疫病的方剂中出现次数较少,我们则可以认为这味药对于这种疫病比较重要,可以作为这种疫病的关键或者核心药物。
词频tf即是某个词在某篇文档中出现的次数,逆文档词频则是某个词在所有文档中出现次数的对数的倒数。一个词的权重可以用它的词频tf和逆文档词频idf的乘积表示
count(a)表示a味药在所有方剂中出现的次数,则a药的逆词频公式表示如下:
idf(a) = 1/log(count(a))
则a药的权重可以用公式表示如下:
W(a) = tf(a) * idf(a) = tf(a) * 1/log(count(a))
3 实验结果
由于古代疫病数据过多,在此只展示瘟疫的部分方剂中根据PageRank算法迭代100次找出的pagerank值较高的药物,见表1。

表1 瘟疫方剂中pagerank值较高的药物
可以发现,PageRank算法可以找出在瘟疫方剂中出现频次较高且与其他药物搭配频繁的药物,得出了瘟疫方剂中药物的重要性排名。但也存在一些百搭药物或者辅助药物排名也十分靠前,如甘草、连翘等。
同样的,以瘟疫方剂为例,找出在瘟疫方剂中出现次数较多而在所有方剂中出现次数较低的药物(表中数字单位为次),见表2。

表2 在瘟疫方剂出现次数较多而在所有方剂中出现较少的药物
按权重计算公式得出各种药物的权重如下,见表3。

表3 各种药物的权重计算
可以发现,某些药物如荆芥、牙皂、蓝叶等虽然在瘟疫方剂中出现次数不多,但是在所有方剂中出现次数同样很少,这些药可以认为对瘟疫有独特的、不可替代的作用。
4 结论
通过两种不同算法得出的结果比较分析可以得出:
两种算法得出的核心药物出现了9味不同的药。PageRank算法确实可以得出瘟疫方剂中相对重要的药物,如甘草、连翘、黄芩、川芎、人参、薄荷等,而基于效用度的算法则可以找出相对低频但是比较有效的药物,如荆芥、牙皂、蓝叶。
PageRank算法会受到KD(阻尼系数)选取的影响,而权重计算方法也会受到整体方剂数据量的影响,同时PageRank偏重于输入顺序相对在前的方剂药物,不同古代典籍中疫病药物选取也可能受朝代、病因的影响。
而基于效用度的权重算法,可以有效发现相对某种疫病使用较多的药物,但如果方剂数据中存在较多类似药物搭配,也会使实验结果相对偏向这类搭配的药物。
综上可见,PageRank算法可以发现瘟疫方剂中使用频数较高的核心药物,但其中也不乏像甘草这样的百搭药物,而基于效用度的算法则可以发现较针对瘟疫这种疫病的低频但有效的药物,使药物的权重排名不仅仅依赖于该药物在瘟疫方剂中出现的频率。相较而言,基于效用度的算法更准确地发现针对瘟疫的核心药物,因此对两种算法的核心药物求交集,结果再与基于效用度的算法做并集,则能较为准确地反映瘟疫中的核心药物为川芎、薄荷、牛蒡子、前胡、大黄、升麻、麻黄、石膏、羌活、栀子、防风、独活、荆芥、牙皂、蓝叶。
至此,运用两种不同算法从70多个瘟疫方剂中发现了核心药物,两者结果分析结合,得出瘟疫常用的核心药物。其中大部分药物证实对瘟疫治疗有显著效果,但个别药物的药性以及用法可能与其他药物存在冲突,任有待对其中的药性以及用法用量进行进一步分析,最终得到的结果更加科学合理。
下一步工作是按照上述研究方法,同样的对黄胆、霍乱、痢疾等方剂数据量较多的疾病运用核心药物发现算法,找出其中的核心药物。然后,以核心药物为基础,对不同疫病的朝代、病因、症状等影响因素进行显著性分析。希望通过对不同疫病的研究分析,进一步得出不同朝代、症状的疫病的用药规律,为现代医学提供借鉴。
[1] 单联喆.明清山西疫病流行规律研究[D].中国中医科学院 中国中医研究院,2013.
[2] 彭丽坤.明清中医疫病发病、症状与用药相关性数据挖掘研究[D].南京中医药大学,2009.
[3] 周伟.中药方剂核心药物及其配伍规律挖掘[D]. 南京大学, 2013.
[4] 周伟,王峰,王崇骏,等.利用效用度挖掘核心药物及配伍规律[J].计算机科学与探索, 2013, 7(11):994-1001.
[5] 张健.基于链接的分类算法的研究[D].燕山大学,2009.
[6] 吴淑燕,许涛.PageRank算法的原理简介[J].图书情报工作,2003(2):55-60.
[7] 《网络(http://blog.csdn.net)》- 2013, PageRank算法 - 思考,思考,再思考~ - 博客频道 - CSDN.NET.
[8] 《网络(http://blog.csdn.net)》-2017,pagerank 算法简介 - 博客频道 - CSDN.NET.
[9] 蔡春艳.中药方剂核心药物及其配伍规律分析[J].亚太传统医药,2014,10(20):131-132.
[10] 肖根胜.改进TFIDF和谱分割的关键词自动抽取方法研究[D].华中师范大学,2012.
