基于用户聚类的二分图网络协同推荐算法*
2018-06-06郑怀宇
郑怀宇
(福建中医药大学 现代教育技术中心, 福州 350122)
随着互联网与无线通信技术的飞速发展,海量数据信息被提供给网络用户.在海量数据和信息面前,用户往往陷入数据信息的汪洋大海,难以精确选取符合定制化需求和个性偏好的项目资源.针对该问题,推荐系统从两方面来为用户推荐个性化的信息、商品和服务:基于内容推荐与协同过滤推荐.在众多推荐方法中,协同过滤应用最为广泛.协同推荐[1-2]首先在用户群体中找到与用户节点偏好相近的邻居用户,综合邻居用户的评价信息,为用户节点推荐其可能喜欢的服务.
协同过滤推荐系统不需要考虑项目的内容,且易于实现,是当前应用最为广泛的推荐技术之一.许多大型的电子商务网站都应用了协同过滤推荐系统,如Amazon、淘宝、当当网等.但协同过滤也面临两大难题[3],即数据稀疏性与邻居用户推荐.
针对上述问题,本文提出了基于用户聚类的二分图网络协同推荐算法.相比传统的协同推荐算法,该算法将协同推荐分为两个阶段:
2) 协同推荐阶段.围绕聚类中心及其所在群组为未评分项目完成预测评分,为用户推荐综合评分最高的Top-n项目.
1 研究背景
除了同一类型节点构成的同质网络,现实世界中还广泛存在着大量具有二分结构(2-mode)的网络[4-5],例如电影与电影评价、上网者与点击网页、论文合著者与其合著论文、在线用户与其加入的兴趣群组等等.二分图网络由两类节点群体及两类节点间的连接组成,同类节点之间不存在连边,前一类节点表示某活动、事件的参与者(用户节点),后一类节点表示所参与的活动或事件.当用户节点与项目节点建立边连接后,拥有共同连接节点的用户节点之间也具有了连通性.
假设推荐系统中有m个用户和n个项目,令G(U,I,E)表示一个二分图网络推荐系统,为m×n阶项目评分权重矩阵,U为用户节点集,I为项目节点集,E为边集.假设用户节点数U=m,项目节点数I=n,则二分图网络节点总数为r=m+n.若用户up对项目iq的评分不为空,则Gpq=1;否则,Gpq=0.
二分图网络除了刻画传统意义上的网络结构特征,还有助于为用户实现精确的协同推荐[6-7].二分图网络示意图如图1所示,二分图网络的特殊结构可以从两方面进行理解:
1) 网络由用户域和项目域共同组成,用户域与项目域间的连接状况反映了用户节点与项目节点间建立连接的倾向与选择性,可认为是用户节点的偏好、倾向在项目节点上的映射;
2) 围绕同一聚类中心的群组节点具有近似的行为模式或连接模式,可以推荐共同关注的项目.

图1 二分图网络示意图Fig.1 Schematic bipartite networks
基于用户聚类的二分图网络协同推荐算法充分考虑了用户之间的邻域关系、用户与项目之间基于邻域和项目的关联,根据协同过滤和用户聚类推荐的思想进行协同推荐.该算法有两个特点:
1) 结合邻域用户的评分行为构建用户相似度,将用户之间的邻域关系与项目关联,离线建模到邻域用户相似度矩阵中,以保证推荐准确性;
2) 使得目标用户的推荐计算量只与用户聚类中心、核心用户的关联项目相关,从而降低方法的复杂度.
2 基于用户聚类的网络协同推荐算法
本文提出了一种基于用户聚类的二分图网络协同推荐算法,在二分图网络中,根据用户对不同项目的兴趣程度进行用户聚类,为目标用户推荐其可能喜欢的项目.通过分析二分图矩阵中用户与项目的评分信息将用户聚类,获取目标用户所在类的评分信息,并基于同类用户实现二分图的协同推荐,提升在稀疏数据集上的推荐效果.本文算法主要包括估算节点中心度、用户聚类、协同推荐等阶段,主要流程如图2所示.
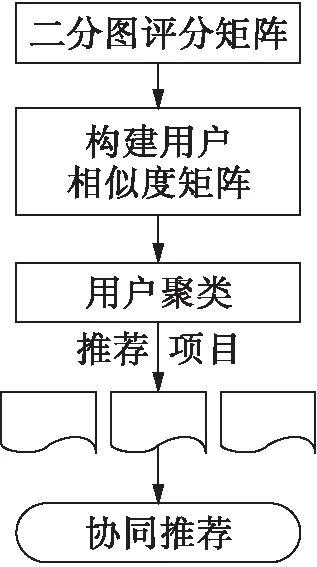
图2 基于用户聚类的协同推荐算法流程Fig.2 Flow chart of collaborative recommendationalgorithm based on user clustering
2.1 基本定义

定义2用户中心度.G={U,O,E}表示某二分图网络,借鉴PageRank算法的中心度定义,将网络G中任意节点i的中心度P表示为
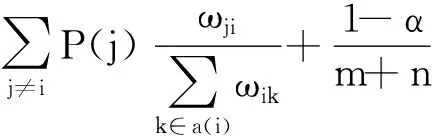
(1)
式中:ωik为连接节点i和k的边eik的权重;a(i)为与节点i有直接连接的所有邻接节点的集合.在原始的PageRank定义中,通常设置α为0.85,α∈(0,1).(1-α)/(m+n)项是为孤立节点设定一个附加值,避免其中心度计算无法收敛.用户中心度刻画了二分图网络中任意用户节点的全局中心度,基于用户中心度可以获取用户的聚类中心,并基于此确定目标用户所在的用户聚类,获取同类用户选择项目节点连接的选择性与倾向,并为一个或多个目标用户推荐可能喜欢的项目.
定义3用户相似度矩阵.二分图网络中用户选定的评分项目往往有重合节点,这些重合节点构成了不同用户间的评分相似性.本文采用Pearson系数来衡量用户间的评分相似度,即

(2)
评分相似度可以衡量任意两用户节点u,t关于项目节点的喜好和选择方面的相似度,sim(u,t)值越大,相似度越高,推荐的项目节点越有可能被喜欢;sim(u,t)值越小,相似度越低,推荐的项目节点被喜欢的可能性越低.
2.2 用户聚类
为了提高协同推荐的有效性和准确性,需要对二分图网络进行用户聚类,从中提取关于目标用户的聚类信息,为下一步的协同推荐奠定基础.常用的聚类算法Kmeans和Kmedodis通过随机选取数据节点作为聚类核心,这类算法对初始节点的选取较为敏感,聚类准确性难以保证.针对该问题,本文采用基于节点中心度的聚类算法对二分图网络进行用户聚类,以克服随机选取初始节点对用户聚类的不利影响.
聚类中心与项目节点集的关系模型如图3所示,在实际二分图网络中,中心度较高的用户节点更有可能成为网络中的聚类中心.但若从全网络范围内计算所有用户节点的中心度,计算复杂度较高,很多节点的计算甚至并不必要.本文设计如下策略:选取大于或等于网络平均节点度的节点作为候选的种子节点.借鉴了图摘要算法的思想,提出了一种简化的中心度聚类算法,该算法首先构建基于用户节点的相似度矩阵,从用户相似度矩阵中选取节点度较高的节点作为聚类核心,然后计算高度数节点在网络中的中心度并排序,以搜索二分图网络中所有的聚类中心,最后围绕聚类核心完成用户聚类.算法的具体步骤如下:
1) 初始化聚类中心节点集为空.
2) 基于用户关联的项目构建并计算用户的相似性,获得用户相似性矩阵Bm×m,bij=sim(i,j)表示用户i与用户j在关联项目评分上的相似度.
3) 选取矩阵B中节点度大于均值的节点作为聚类核心,并围绕其邻居节点聚类.在其跳转范围内,计算所有周围邻近节点的中心度P值.
4) 节点聚类后,计算扩展子团中心度,若中心度增量为正,则将该节点加入对应的用户聚类核心.
5) 重复步骤3)和4),选取中心度为Top-p的节点作为二分图网络的聚类中心.

图3 二分图网络中聚类中心与项目节点集的关系模型Fig.3 Relation model between clustering centers andproject node set in bipartite networks
当满足以下条件,算法终止:1)超过最大的迭代次数;2)所有聚类中心节点的中心度高于某门限阈值.通过中心度聚类算法,最终能够获取二分图网络中所有用户节点的聚类中心.聚类中心选择算法从用户节点集U中获得p个聚类中心,按照各用户节点到聚类中心的距离大小将用户节点划分为p类,分类用户集合表示为C={c1,c2,…,cp}.
2.3 基于二分图网络的协同推荐算法
假设通过聚类中心选择算法从用户节点集U中获得p个聚类中心cp,并进一步得到用户u所隶属的聚类中心及所属类的用户聚类中心cu.基于二分图网络的评分矩阵及协同推荐算法围绕用户u同类的邻居用户进行未评分项目的评分预测,综合比较最终的评分矩阵,并选取其中评分较高的项目推荐给用户集U.算法流程如下:
1) 获取用户聚类中心及每类中心里所有用户推荐的项目集合{o1,o2,…,op},oi表示对应聚类中心ui的所有推荐项目;
2) 采用Pearson相关系数计算目标用户ut与C={c1,c2,…,cp}中每一聚类中心的相似性,选取具有最大相似性的聚类中心类cmax作为ut所在的类;
3) 根据式(2)计算目标用户ut与cmax类中每位用户的相似性,取相似性从大到小排列的前k个用户作为用户ut的最近邻集合U0=(u1,u2,…,uk);
4) 获取与目标用户ut没有直接联系的未评分项目集合,并估算ut对未评分项目i的评分,即
(3)

5) 将目标用户ut所有的评分项目按降序排列,获取前n个项目组成Top-n推荐集{o1,o2,…,on},并输出.
2.4 计算复杂度分析
传统搜寻最近邻的方式是基于整个用户空间搜寻用户节点的最近邻计算,复杂度为O(m×n),因为m和n是同一数量级,所以O(m×n)≈O(n2).而在本文算法的用户聚类阶段,根据关联项目评分的相似性对用户进行聚类,计算复杂度为O(m×t);在协同推荐阶段,比较目标用户与各个用户聚类核心的相似度,计算复杂度为O(p×n).在整个协同推荐过程中,避免了在整个二分图网络范围内进行搜索和计算,整体计算复杂度为O(m×t)+O(p×n).由于t,p都远小于m或n,所以本文算法通过用户聚类二分网络协同推荐,能够大大降低算法的复杂度和计算量.
3 实验结果及分析
为了分析基于用户聚类的二分图网络协同推荐算法的性能,实验将其与当前2个经典的协同推荐算法进行比较,即CF(collaborative filtering)[8-9]和Content-based算法[10-11].其中,CF算法采用类似Top-k思想的协同过滤推荐算法;Content-based算法则采用了基于主题内容相似度的k近邻推荐算法.
本文使用MovieLens数据集7和Netflix数据集13对算法进行评估.MovieLens数据集包含943位用户对1 682部电影的100 000条评分记录,评分值为1~5的正整数.Netflix数据集包含480 189位用户对17 770部电影的100 480 507条评分记录,评分值为1~5的正整数.由于Netflix数据集规模过大,从中随机抽取25 413条评分记录作为实验数据集.表1给出了实验用数据集的基本特征,本文将每一数据集划分为50%的训练集用户和50%的测试集用户.

表1 实验数据集基本特征Tab.1 Basic characteristics of experimental data sets
3.1 稀疏数据条件下推荐性能对比
在社交、购物等网络应用场景下,往往存在着数据稀疏性的问题,数据稀疏度常常低于10%,因此,稀疏数据条件下各种算法的推荐性能很重要.为对比稀疏条件下各种算法的协同推荐性能,将数据稀疏度设置为5%,6.5%,8.5%,12.5%4种情况,对比实际推荐数量与需要推荐数量的比值.实验中设置最大需推荐数量不超过测试集的非零值数量.一般情况下,比值越大,则说明协同推荐算法对数据稀疏性的适应能力越强,推荐效果越好.
表2表示在不同数据稀疏度条件下,4种算法实际推荐数量与需推荐数量的比值.当数据极端稀疏时(稀疏度≤6.5%),4种算法都不能获取足够的推荐数量,CF和Content-based算法推荐数量比值较低,而本文算法的推荐能力受数据稀疏性的影响相对较小,推荐数量比值接近于1;当数据稀疏度≥8.5%时,CF和Content-based算法推荐数量比值有一定的提升,但仍然都小于50%,而本文算法的推荐数量比值为100%,完全能够达到需要的推荐数量.这说明在稀疏条件下,本文算法的推荐效果更好.
3.2 协同推荐的准确性对比
本文引入了Fmeasure和MAP(mean average precision)两项指标来衡量算法协同推荐的准确 性.Fmeasure表示准确率和召回率的调和平均值,该值越高则表明推荐算法的综合性能越好;MAP表示对每个用户推荐结果的平均值,该值越高,表明推荐算法的总体推荐质量越好.

表2 稀疏数据条件下的协同推荐数量对比Tab.2 Quantitative comparison in collaborative recommendation under sparse data condition
(4)
(5)
式中:Fi为标准数据集,将局部社区发现的结果X映射到该标准数据集;r为数据集中被正确划分的节点数在标准数据集所占的比例.
图4和图5分别表示不同数据稀疏度条件下,3种算法协同推荐Fmeasure指标与MAP指标的性能对比.综合图4、5可知,Content-based算法数据的稀疏性并不敏感,但推荐准确率一直保持在较低水平;而本文算法在数据极端稀疏时,仍能保证较高的推荐准确率,并随着数据密集度增大而不断上升.在3种算法中,本文算法在Fmeasure和MAP两项推荐准确率指标上都能获得最优的性能,且相比传统方法具有较为显著的提升.

图4 3种算法协同推荐Fmeasure指标性能对比
Fig.4PerformancecomparisonincollaborativerecommendationofFmeasureindexfor3algorithms
3.3 协同推荐的多样性对比
为对比协同推荐算法推荐结果的多样性,实验通过人工标注,将测试数据集按照项目内容和主题分为16个不同的类别.在冷启动场景下,新加入的用户由于关注的项目较少,推荐结果往往 就被限制在其关注的主题范围内,可推荐的项目也就较少.为避免推荐算法过快收敛,要求推荐算法能够产生更具多样性的推荐结果,并提高跨类别推荐的比例.
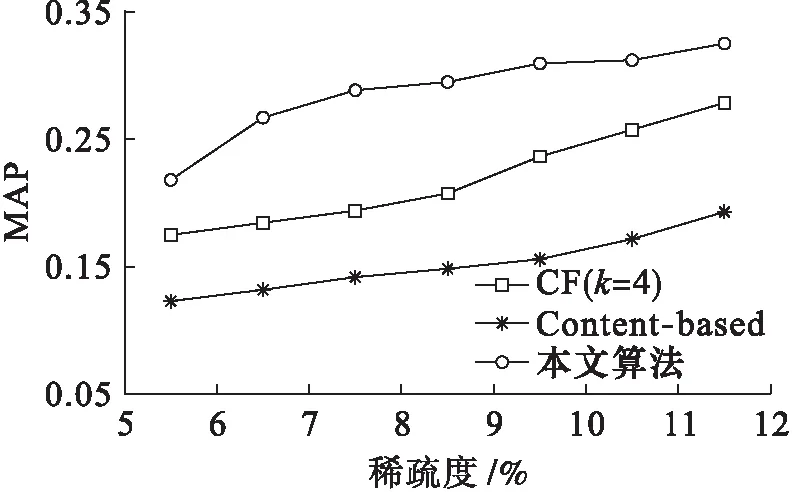
图5 3种算法协同推荐MAP指标性能对比
Fig.5PerformancecomparisonincollaborativerecommendationofMAPindexfor3algorithms
实验中,通过选择性地删除在训练数据集中每个用户对于某类或多类项目的关联信息,来模拟冷启动场景下的数据特点,以此来检验算法跨类别的推荐能力.推荐结果在测试集中被印证,才能称为有效推荐;跨类别的推荐结果在测试集中的被印证,则称为跨类别有效推荐.
表3显示了3种算法协同推荐的多样性推荐数量对比.随着删除类别数量的增多,3种算法的可推荐数量和跨类别的推荐数量都呈下降趋势,推荐的有效数量和跨类别的有效数量也都逐步下降.相比其他2种算法,在相同条件下,本文算法推荐数量更多,跨类别推荐数量也更多,与实际结果相符的有效数量、跨类别的有效数量也更多.这说明相比传统基于内容的推荐方法,本文算法能够产生更高质量的跨类别推荐结果,协同推荐的多样性更高;在冷启动的场景下,跨类推荐的数量和多样性都更优.而基于内容的方法在主题类别缺失较多的情况下,具有极低的推荐多样性,导致推荐结果过快收敛,推荐的范围往往受限.
4 结 论
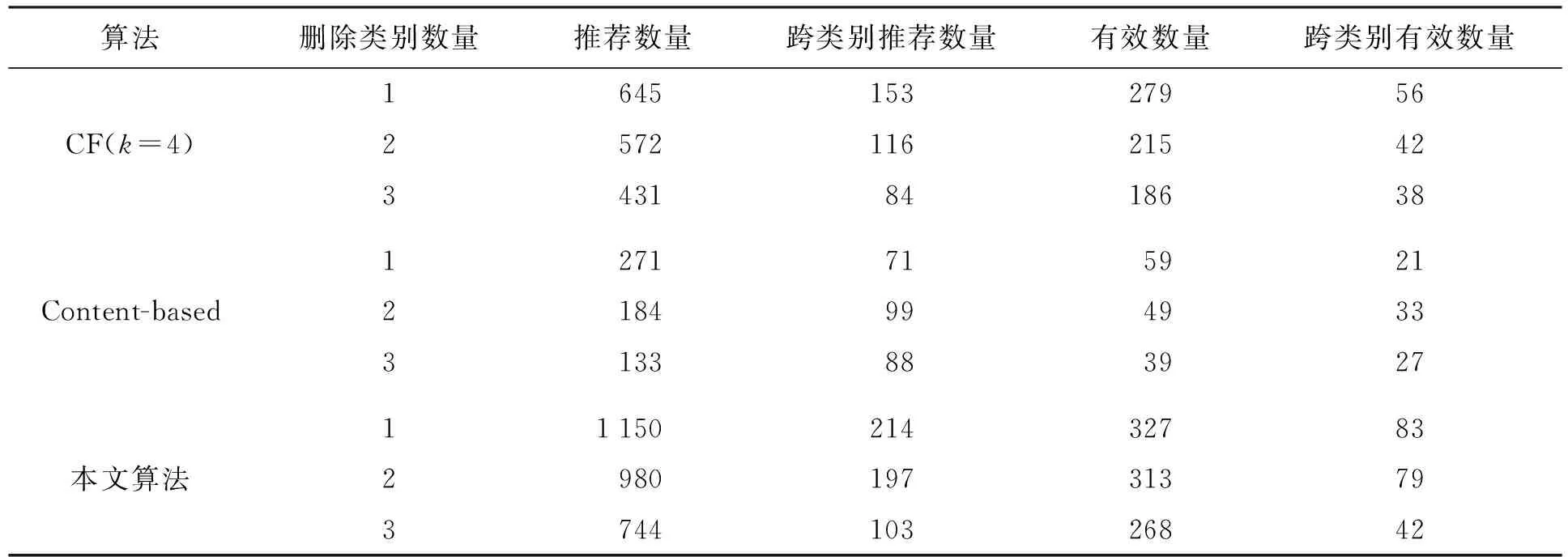
表3 3种算法协同推荐多样性对比Tab.3 Diversity comparison in collaborative recommendation for 3 algorithms
参考文献(References):
[1] 王国霞,刘贺平.个性化推荐系统综述 [J].计算机工程与应用,2012,48(7):66-76.
(WANG Guo-xia,LIU He-ping.Survey of personalized recommendation system [J].Computer Engineering and Applications,2012,48(7):66-76.)
[2] Zhang P,Wang J L,Li X J,et a1.Clustering coefficient and community structure of bipartite networks [J].Physica A,2012,387:6869-6875.
[3] 谭云志,张敏,刘奕群,等.基于用户评分和评论信息的协同推荐框架 [J].模式识别与人工智能,2016,29(4):359-366.
(TAN Yun-zhi,ZHANG Min,LIU Yi-qun,et al.Collaborative recommendation framework based on ratings and textual reviews [J].Pattern Recognition and Artificial Intelligence,2016,29(4):359-366.)
[4] 李霞,李守伟.面向个性化推荐系统的二分网络协同过滤算法研究 [J].计算机应用研究,2013,30(7):1946-1949.
(LI Xia,LI Shou-wei.Research on collaborative filtering algorithm of bipartite network oriented to personal recommendation system [J].Application Research of Computers,2013,30(7):1946-1949.)
[5] Everett M G,Borgatti S P.The dual-projection approach for two-mode networks [J].Social Networks,2013,35(2):204-210.
[6] 吴湖,王永吉,王哲,等.两阶段联合聚类协同过滤算法 [J].软件学报,2010,21(5):1042-1054.
(WU Hu,WANG Yong-Ji,WANG Zhe,et al.Two-phase collaborative filtering algorithm based on co-clustering [J].Journal of Software,2010,21(5):1042-1054.)
[7] 冷亚军,陆青,张俊岭.使用二分图网络提高协同推荐的准确性 [J].计算机科学,2015,42(3):256-260.
(LENG Ya-jun,LU Qing,ZHANG Jun-ling.Using bipartite network for enhancement of collaborative filtering [J].Computer Science,2015,42(3):256-260.)
[8] Kim Y,Shim K.A recommendation system for twitter using probabilistic modeling [C]//Proceedings of the 2012 IEEE 11th International Conference on Data Mining(ICDM).Vancouver,Canada,2012:340-349.
[9] Sakaguchi T,Akaho Y,Takagi T,et al.Recommendations in twitter using conceptual fuzzy sets [C]//Proceedings of the 2013 Annual Meeting of the North American Fuzzy Information Processing Society (NAFIPS).Toronto,Canada,2013:1-6.
[10]陈晓.基于双聚类的图书协同推荐方法 [J].兰州交通大学学报,2016,35(3):72-75.
(CHEN Xiao.Book collaborative recommendation method based on double cluster [J].Journal of Lanzhou Jiaotong University,2016,35(3):72-75.)
[11]郑修猛,陈福才,吴奇,等.一种利用多群组智慧的协同推荐算法 [J].西安交通大学学报,2016,50(10):118-124.
(ZHENG Xiu-meng,CHEN Fu-cai,WU Qi,et al.A collaborative filtering recommendation algorithm using multiple groups intelligence [J].Journal of Xi′an Jiaotong University,2016,50(10):118-124.)
