基于合并影响概率的社交网络影响最大化算法
2018-05-30高茂庭
周 飞,高茂庭
(上海海事大学 信息工程学院,上海 201306)
0 概述
随着互联网技术的迅猛发展,社交网络服务(Social Network Service,SNS)作为互联网应用发展的必备要素,不再局限于信息传递,而是与沟通交流、商务交易类应用融合,借助其他应用的用户基础,形成更强大的关系链,从而实现对信息的广泛、快速传播。鉴于社交网络影响力的传播特性,信息在社交网络传播中具有“口碑效应”,即当某用户接受一新鲜事物时,他通常会将该事物推荐给他的朋友,当他的朋友接受的时候就实现了信息的有效扩散。于是,在日常生产生活中决策者们便利用“口碑效应”在社交网络中进行产品信息宣传,实现影响最大化在网络营销、舆情监控等方面的实际应用。社交网络的流行也为“病毒式营销”提供了天然的营销网络,因此,如何从众多网络节点中寻找若干较少节点,使得影响力能够最广泛地扩散成为一个研究热点。
已知社交网络由M个节点和N条边所组成的有向图G(V,E)表示。社交网络影响最大化问题(Influence Maximization Problem,IMP)由文献[1]提出,IMP问题就是如何从M个节点中选取K个种子节点,让这个K种子节点在初始时刻处于激活状态,通过网络传播模型尝试激活其他当前状态是未激活的节点,最终使得被激活成功的节点数最多的问题。针对该问题,本文提出一种基于合并影响概率的社交网络影响最大化算法。
1 相关研究
为了解决影响最大化问题,文献[2]将影响最大化问题归纳为离散最优问题,并提出了近似可达最优解63%的爬山贪心算法,运用多次蒙特卡洛模拟获得影响范围,取最优解,但对于大规模社交网络,这种贪心算法的时间复杂度太高。针对此问题,文献[3]提出了改进的贪心算法CELF,利用网络传播的子模性,延迟计算边际收益,将时间效率提高了数百倍。在此基础上,文献[4]利用堆特性对CELF 算法做出改进并提出了CELF++算法。文献[5]提出NewGreedy算法,在独立级联传播模型下,以1-p的概率去除原图中的边,再迭代考虑子图的最大影响力。MixGreedy算法[5]结合NewGreedy算法和CELF算法,仿真实验表明,其性能略好于NewGreedy。文献[5]亦在Degree算法[6]的基础上提出DegreeDiscount算法,性能也有所提升。网页排名的PageRank算法[7]也被运用于寻找网络影响力节点中。PMIA算法[8]提供了稳定的传播范围,且运行速度比贪心算法提升了大约3个数量级,但由于在本地计算节点树结构,运行时需要耗费较大内存。文献[9]提出CGA算法,采用分治思想,拆分数据集,对各个子集并行计算。文献[10]在CELE的基础上使用上界逼近法减小了算法响应时间。UGGreedy算法[11]在去除不重要节点简化网络结构后再使用贪心算法求解,但算法时间复杂度依然相对较高。文献[12]提出k-核概念,并考虑节点间影响区域重叠现象提出核覆盖CCA算法,认为影响重叠会使得影响力难以扩散,带来的边际受益很小。CCA算法优先选择距离参数d内影响重叠较少的节点。然而,在独立级联的模型下,重叠部分的节点被影响次数要多于非重叠部分节点,因此,重叠部分节点相对被影响的概率更大,继而可以影响到其他后续节点。文献[13]结合网络在线传播和现实社会中口口相传的特性建立模型,但也正因如此算法扩展性较差。BCIM算法,先使用PageRank选取备用节点,再使用动态规划的方法获取最优解,其不足之处是只考虑到近距离邻居的影响,虽然在算法时间上有较大提高,但是会出现部分影响力在传播过程中丢失的现象。
为了更好地解决影响最大化问题,且考虑到现有算法中存在贪心算法时间复杂度过高,节点间影响区域重叠,算法可扩展性以及在传播过程中只考虑近距离传播而牺牲影响力间接传播来提高算法时间性能等问题。本文在第4节提出基于合并影响概率的社交网络影响最大化算法(Influence Maximization with Combined Impact Probability,CIPIM),在沿用BCIM算法中先使用PageRank选取备用种子节点,再在计算备选种子节点合并影响概率的基础上,使用遗传算法(Genetic Algorithm,GA)解决全局优化问题。
2 传播模型
寻找社交网络影响最大化节点往往需要借助于网络传播模型,通常情况下将社交网络表示为由M个节点和N条边所组成的有向图G(V,E),其中,节点表示社交网络中的个体,有向边表示个体之间的关系,如Twitter中用户之间的关注关系。线性阈值模型(Linear Threshold Model)和独立级联模型(Independent Cascade Model,ICM)是2种常用的网络传播模型。
2.1 线性阈值模型
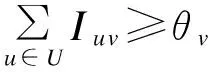
2.2 独立级联模型
在独立级联模型[15]中,任意一条边
3 影响最大化算法CIPIM
影响最大化问题就是要从M个节点中选取影响传播影响范围最大的K个种子节点。但在实际社交网络中存在大量低影响力用户,在信息传播中几乎没有任何贡献,因此,他们不能作为种子节点。从减少种子选取范围上考虑,先使用PageRank算法计算M个节点的PageRank值,从中选取排名靠前的节点作为备选种子集合,再对各备选种子节点进行合并影响概率预计算,最后使用遗传算法进行全局优化挑选出K个种子节点。
3.1 种子选取范围的减少
意见领袖通常是网络社区中的活跃分子,是信息的积极传播者,能够引起大量关注并影响社区中的舆论导向。在线社交网络通常采用PageRank值来表示用户的影响力大小,值越大则影响力越大。社交网络中还存在着大量的信息接收者,但单纯的接受者对信息传播的贡献却非常小。为了分析选取高影响力用户作为备用种子节点的占比规律,对Wiki-Vote数据集[16]7 115个节点按照PageRank值进行排序,归一化处理各节点PageRank值并计算可影响范围占比情况,考虑图像显示效果和方便观察,截取前1 000个节点,如图1所示。1 000位之后的图像延续图1后半段走势,平缓递增与递减。
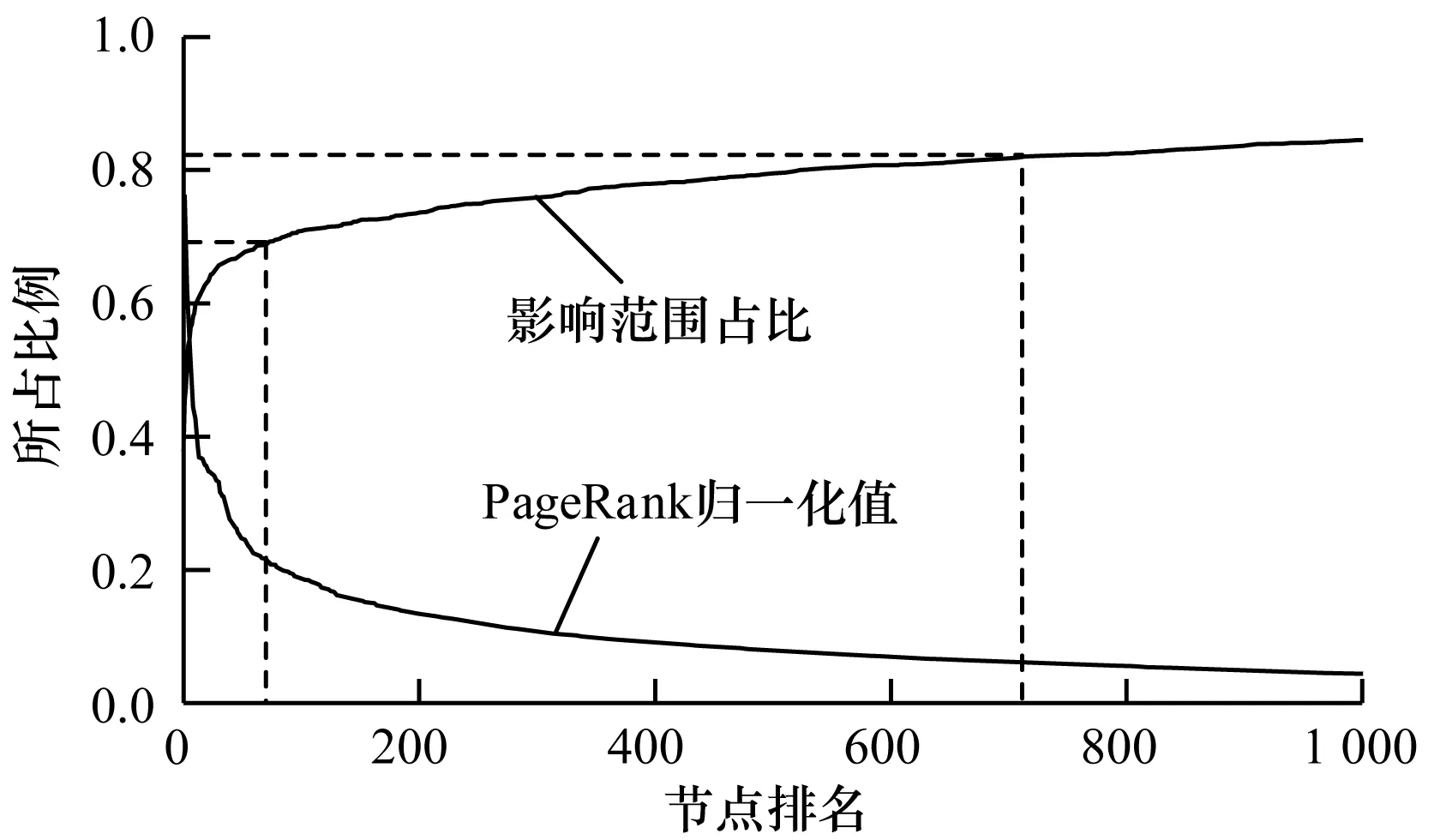
图1 前1 000名PageRank值及影响范围占比情况
图1显示,选取1/10的节点就可达到超过80%的影响范围,仅需1%的节点即可达到60%以上的影响范围。因此,本文从减小种子节点选取范围出发,选取具有较高PageRank值的节点作为备选种子节点。考虑到当K值较小时(比如K=10),并不需要从前500个甚至很多的节点中挑选出10个种子节点,仅从前100个节点来看完全可以达到预想效果。同时,为了防止使用固定数量的备选种子可能会造成的局部最优情况,本文使用线性规则来选取备用种子节点,即选取PageRank值排名靠前的hK个节点作为备选种子节点,为了方便计算在实验中将h值设为10。这样,不仅从数量上减少运算时间,而且在一定程度上消除可能存在的局部最优情况。
3.2 备选种子合并影响预计算
文献[17]在数据集DBLP上证实了六度分割理论猜想:每个人最多通过6个人就可以认识一个陌生人。同样,在社交网络信息传播的过程中,也仅需几次即可将信息传播开。图2是社交网络中种子节点A、B影响传播的局部路径简单传播模型,其中,t表示当前传播次数。
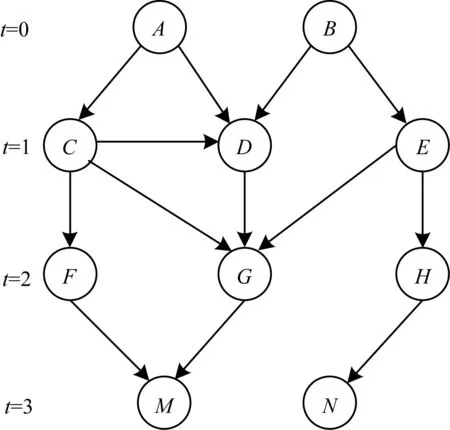
图2 社交网络信息传播路径
在图2中,设每条有向边传播概率相同,为常量p,那么种子节点A通过边
备选种子合并影响预计算,是对备选种子集中每个备选种子进行一次节点自身传播范围内可被激活节点次数及轮次统计。对于种子节点A,其可激活节点集为{C,D,F,G,M},且t=1的有{C,D},t=2的有{D,F,G},t=3的有{G,M},其中,当t=3时有节点G的原因是存在一条A-C-D-G通路。对于种子集合{A,B}来说,由于它们之间有共同影响部分,故它们的影响概率并不是节点A和B的概率简单相加。因此,在最终计算种子集合的影响概率时,先要分别统计各种子节点的预处理结果,再合并计算它们的影响概率。
在不同传播概率p下,若以不同传播次数t分别尝试500次激活,通过公式P=1-(1-pt)500可计算出节点被激活概率。例如,当t=3时,节点被激活的概率为p3,假设该节点被激活500次,则该节点在t=3下被激活概率为1-(1-p3)500,如表1所示。

表1 500次激活下节点被激活概率
如表1所示,当t=3,p=0.01时,仍有万分之五的概率能够激活节点,而当t=3,p=0.06时被激活概率达到约0.1。当t=4,p=0.01时,节点几乎不可能被激活,而p=0.06时也仅仅只有0.006的概率。因此,本文针对文献[13]中只考虑近距离(t=2)传播的问题,将种子节点可影响步数调整为t=3步,虽然在一定程度上加大了算法的时间复杂度,但是其传播概率计算更为准确合理。
设G(V,E)为有向图,seed表示某种子节点,t表示当前传播轮次,该备选种子预处理算法(Alternative Seed Preprocess Algorithm,ASPA)采用图深度优先遍历策略,算法描述如下:
输入t,seed,G(V,E)
输出各种子节点统计信息
执行步骤:
1)如果t>3,返回,否则转到2)。
2)Fseed←节点seed所有未尝试激活的邻居节点,转到3)。
3)SR(seed,times)←Fseed,转到4)。
4)标记节点seed已尝试激活,转到5)。
5)对于∀u∈Fseed,递归计算ASPA(t+1,u,G)。
6)返回SR。
其中,步骤1)、步骤3)、步骤4)的时间复杂度都是O(1),步骤2)的时间复杂度为O(n),G图以类似邻接表的形式存储,在一定程度上降低了算法时间复杂度,以单节点出发的时间复杂度为O(n+e),因此,总体时间复杂度为O(Kn+e)。
3.3 遗传算法全局优化过程
设p表示传播模型传播概率,seedlist表示包含k个种子节点的列表集合,SR表示3.2节计算所得信息集,遗传算法优化过程的适应性函数CountSeed描述如下:
输入seedlist,p,SR
输出这k个种子节点的综合影响概率
1.total_probability←0
2.for t=1 to 3:

4.count=Count(infect_list)
5.for user in count.keys():
6.number←count[user]
7.probability←1-(1-pt)numbers
8.total_probability+=probability
9.return total_probability
该适应性函数CountSeed时间复杂度为O(n),设p为传播模型各边传播概率,k表示一个族群中种子个数,popsize表示种群集合中种群数,elite表示种群集合中精英所占比例,maxiter表示最大迭代次数,vatiprob用来判定族群选择交叉还是变异,CIPIM算法GA过程描述如下:
输入costfunc,k,popsize,elite,maxiter,vatiprob,p
输出k个种子组成的集合
1)生成初始种群POP={P1,P2…,Ppopsize},其中每个族群P都包含k个节点,转到2)。
2)计算种群集每个族群综合影响概率,将种群中CountSeed返回值较大者作为精英保留;如果迭代次数达到maxiter,转到5),否则转到3)。
3)根据vatiprob判断对保留下来的精英族群进行交叉操作还是变异操作,并添加到新的种群集POP'中,转到4)。
4)如果len(POP′)小于popsize,转到3),否则转到2)。
5)返回综合影响概率最高的种子集合。
4 实验结果与分析
4.1 实验数据集
为了全面分析CIPIM算法在不同规模网络环境下影响传播效果、可扩展性及性能,本文选取规模不同的2个真实社交网络数据集Wiki-Vote[16]和Twitter[18],它们的统计特性如表2所示。

表2 属性特征权重
4.2 实验设置
为验证本文算法的性能,选取当前较有代表性的算法进行比较。因为贪心算法在时间复杂度上较高,即便是后续优化后的算法仍然需要较长、甚至数天的时间才能得到结果,所以本文不与贪心算法进行比较,而与DegreeDiscount、PageRank、CCA等算法进行比较。DegreeDiscount算法是一种种子节点对邻居节点进行度折扣的启发式算法;PageRank算法,是Google用于标识网页重要性的算法,本文中将阻尼因子设置为0.85;CCA(d)算法是基于核数层次特征、消除重复影响的一种启发式算法,原文中距离参数d为2时效果更好,因此,本文使用CCA(2)进行比较。本文算法CIPIM中备选种子比例h取为10;种群数一般设置为20~100,本文将种群数popsize设为50;最大迭代数一般取100~500,在本算法中因为对下一层精英选择过程做了特殊处理,算法将加速收敛,因此将最大迭代次数maxiter设为100;同理,精英策略elite设为0.2。
为了讨论传播概率对传播结果的影响,排除实验结果的偶然性,分别将影响传播概率设置为0.01、0.03、0.06进行蒙特卡洛模拟传播,并对每次模拟传播进行1 000次实验,取平均值作为传播结果。
实验硬件环境为macOS,内存8 GB,处理器1.6 GHz Intel Core i5,所有代码均使用Python2.7.10书写。
4.3 结果分析
影响最大化算法的评价通常从影响范围和时间效率2个方面衡量。
4.3.1 Wiki-Vote数据集实验
Wiki-Vote数据集是维基百科的一个投票数据,属于中型数据集。图3~图5为各传播概率下的模拟实验平均被影响节点个数趋势。

图3 Wiki-Vote上p=0.01时被影响节点数

图4 Wiki-Vote上p=0.03时被影响节点数

图5 Wiki-Vote上p=0.06时被影响节点数
从图3~图5可以看出,在k<10时,各种算法在影响范围上结果较为接近,相差不大。但当k>10时,可以明显看出,CCA算法比其他算法在影响范围上要稍稍逊色,且随着k值增大,差异也越来越大。CCA算法为了减少算法运行时间,牺牲掉间接传播这一网络特性,导致其影响范围跟其他算法相比有些差距。CIPIM算法在PageRank的算法基础上进行全局优化,其结果要好于单纯的PageRank算法。随着种子数k和传播概率p的变大,算法之间效果的差异也越来越大。表3为不同传播概率下各算法的平均运行时间。
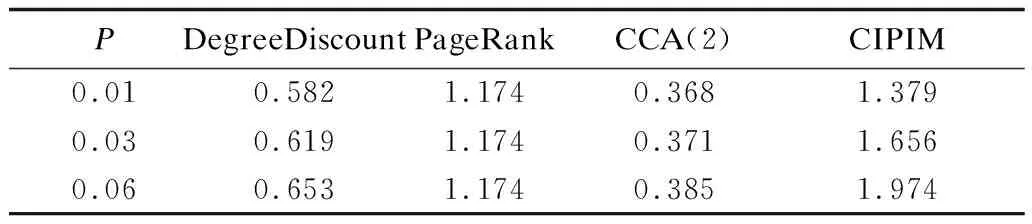
表3 WikiVote数据集下各算法平均运行时间 s
由表3可以看出,CIPIM算法在运行时间上比其他算法稍多一点,但时间差距并不算大,居于相同数量级下。由于种子节点数k对CIPIM算法有一定的影响,因此,随着k值的增大,算法所用时间也会随之稍稍增大。但对于贪心算法而言,CIPIM算法用时已经相当低了。综上,CIPIM算法在数据集Wiki-Vote上有良好表现,算法有效。
4.3.2 Twitter数据集实验
Twitter数据集属于大型社交网络数据集,虽然节点数不到10万个,但是却有着百万级别由关注关系形成的有向边。图6~图8为各传播概率下的模拟实验被影响节点数趋势。

图6 Twitter上p=0.01时被影响节点数

图7 Twitter上p=0.03时被影响节点数
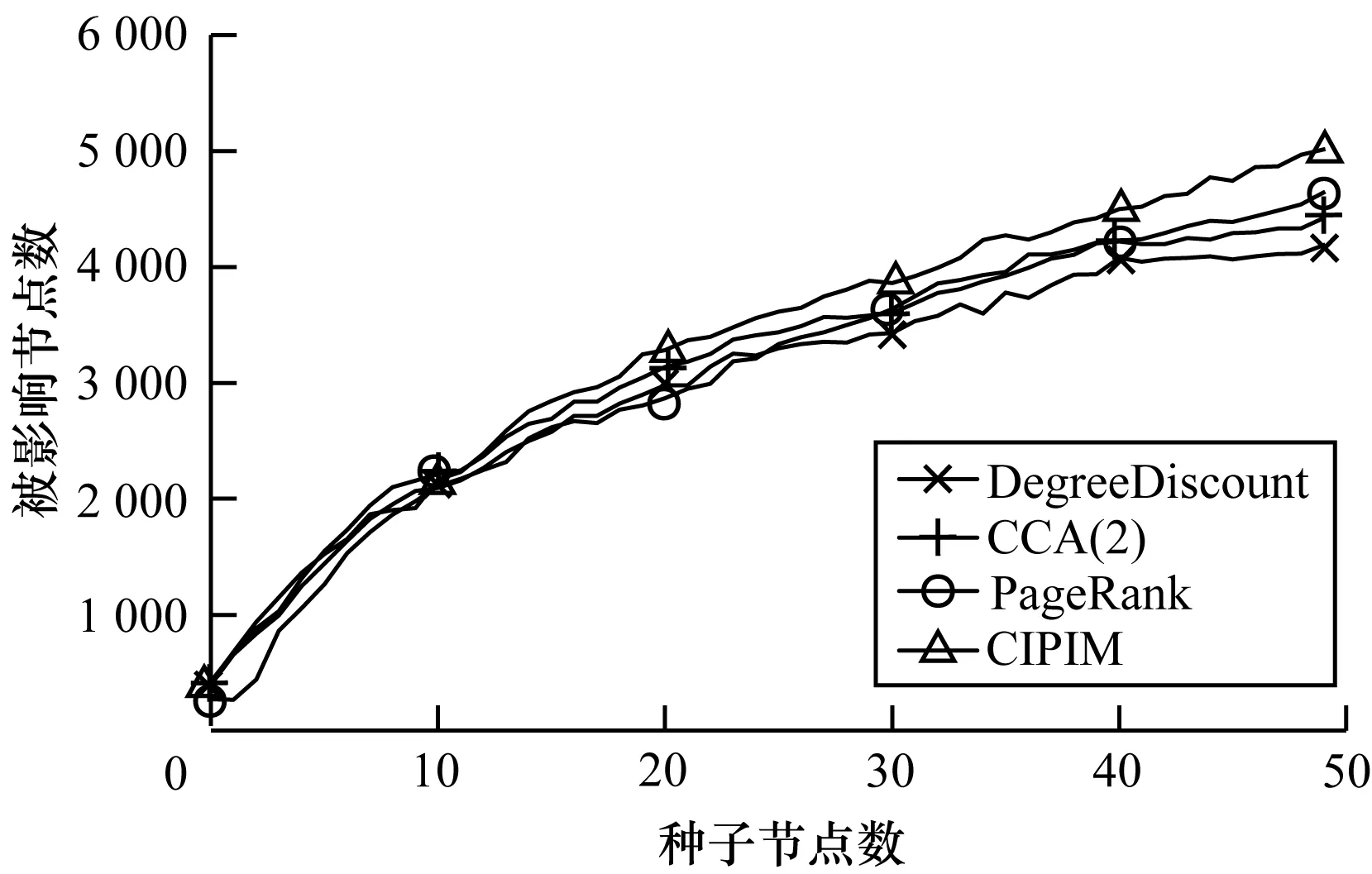
图8 Twitter上p=0.06时被影响节点数
从图6~图8可以看出,在较大型社交网络中,CIPIM算法表现优异。当k值较小时,除了PageRank算法表现一般,各算法相差不大。和Wiki-Vote数据集的运行结果相似,但是在k>10之后,算法之间的差异开始凸显,CCA算法在Twitter数据集上比DegreeDiscount算法要好上一点,说明在真正的社交网络上确实会有影响重叠的现象存在。CIPIM算法是从经PageRank算法排序后的节点中选择有较高影响力的节点作为备选节点,然后再通过潜在被激活节点的综合激活概率优化得到,所以在运行结果上,CIPIM算法始终高于PageRank算法。表4为不同传播概率下各算法的平均运行时间。
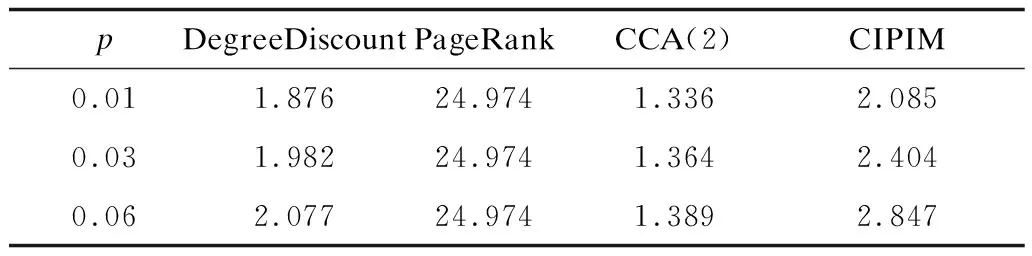
表4 Twitter数据集下各算法平均运行时间 s
从表4可以看出,CIPIM算法在大型数据集上平均运行时间方面仍然表现良好,虽然比一些算法稍稍偏多,但是在影响范围覆盖度上弥补了这些不足。其中需要说明的是,在CIPIM算法中包含PageRank算法,但是只需计算一次,所以,在运行时间内没有包含在里面。
从以上实验结果表明,不管是在Wiki-Vote数据集还是Twitter数据集上,不管传播概率的取值如何,CIPIM算法均表现出较大优势。因为本文算法会在全局上进行优化,所以与直接从节点度或核出发的算法相比在平均时间上要略高,但在节点选取效果上要好于这些算法,且在时间效率上要远远好于贪心算法,能在影响覆盖度和运行时间上取得了较好的平衡。
5 结束语
本文提出一种基于合并影响概率的遗传算法,并利用该算法来解决影响最大化问题,通过缩减种子搜寻范围来减少工作量,使用遗传算法进行全局优化。实验结果表明,CIPIM算法改善了CCA算法在共同影响概率缺失方面的问题,同时与CCA算法、DegreeDiscount算法以及PageRank算法相比影响范围更广,时间复杂度远小于贪心算法。然而,本文算法仍存在不足之处,即各节点间的传播概率都是固定值,但在实际社交网络中并非如此。因此,在下一步工作中,将通过数据挖掘、机器学习等方法综合考虑多个社交网络,使其能够确定用户间不同的传播概率。
[1] DOMINGOS P,RICHARDSON M.Mining the network value of customers[C]//Proceedings of ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York,USA:ACM Press,2001:57-66.
[2] KEMPE D,KLEINBERG J,TARDOSE.Maximizing the spread of influence through a social network[C]//Proceedings of ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York,USA:ACM Press,2003:137-146.
[3] LESKOVEC J,KRAUSE A,GUESTRIN C,et al.Cost-effective outbreak detection in networks[C]//Proceedings of ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York,USA:ACM Press,2007:420-429.
[4] GOYAL A,LU W,LAKSHMANAN L V S.CELF++:optimizing the greedy algorithm for influence maximization in social networks[C]//Proceedings of International Conference on World Wide Web.New York,USA:ACM Press,2011:47-48.
[5] CHEN Wei,WANG Yajun,YANG Siyu.Efficient influence maximization in social networks[C]//Proceedings of ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York,USA:ACM Press,2009:199-208.
[6] WASSERMAN S,FAUST K.Social network analysis[J].Encyclopedia of Social Network Analysis & Mining,2011,22(Suppl 1):109-127.
[7] BRIN S,PAGE L.The anatomy of a large-scale hypertextual web search engine[J].Computer Networks & Isdn Systems,1998,30(1-7):107-117.
[8] CHEN W,WANG C,WANG Y.Scalable influence maximization for prevalent viral marketing in large-scale social networks[C]//Proceedings of ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York,USA:ACM Press,2010:1029-1038.
[9] SONG Guojie,ZHOU Xiabing,WANG Yu,et al.Influence maximization on large-scale mobile social network:a divide-and-conquer method[J].IEEE Transactions on Parallel & Distributed Systems,2015,26(5):1379-1392.
[10] ZHOU Chuan,ZHANG Peng,ZANG Wenyu,et al.On the upper bounds of spread for greedy algorithms in social network influence maximization[J].IEEE Transactions on Knowledge & Data Engineering,2015,27(10):1.
[11] LI Ji,CAI Zhipeng,YAN Mingyuan,et al.Using crowdsourced data in location-based social networks to explore influence maximization[C]//Proceedings of IEEE Conference on Computer Communications.Washington D.C.,USA:IEEE Press,2016:1-9.
[12] 曹玖新,董 丹,徐 顺,等.一种基于k-核的社会网络影响最大化算法[J].计算机学报,2015,38(2):238-248.
[13] MIAO Yu,WU Yang,WANG Wei,et al.UGGreedy:Influence maximization for user group in microb-logging[J].Chinese Journal of Electronics,2016,25(2):241-248.
[14] GRANOVETTER M.Threshold models of collective behavior[J].American Journal of Sociology,1978,83(6):1420-1443.
[15] WATTS D J.A simple model of global cascades on random networks[J].Proceedings of the National Academy of Sciences of the United States of America,2002,99(9):5766-5771.
[16] LESKOVEC J.Wikipedia vote network[EB/OL].[2017-03-10].http://snap.stanford.edu/data/wiki-Vote.html.
[17] ELMACIOGLU E,LEE D.On six degrees of separation in DBLP-DB and more[J].Acm Sigmod Record,2005,34(2):33-40.
[18] LESKOVEC J.Social corcles:twitter[EB/OL].[2017-03-10].http://snap.stanford.edu/data/egonets-Twitter.html.
