基于Ontology扩展查询的数学表达式检索模型
2018-05-30李新福田学东
李新福,徐 筱,田学东
(河北大学 计算机科学与技术学院,河北 保定 071000)
0 概述
数学表达式检索技术的发展加强了相关人员对数学信息的交流,满足了不同用户的检索需求。为提高数学检索的适用性,扩大使用人群,开发面向语义的数学公式搜索引擎意义深远。
国内外已逐步针对数学表达式检索进行相关研究,并构建DLMF Search[1]、MathDex[2]、MathWeb Search[3]、LeActiveMath[4]、EgoMath[5]、 WikiMirs[6]、MIaS[7]、SFE[8]等原型系统。其中,文献[8]对LaTeX格式的表达式提出了序列化特征提取方法,该方法具有不破坏表达式原有结构的特性,相较于其他检索系统,能高速且准确地检索出表达式的不同层次,满足不同用户的检索需求。
以上检索系统能够实现不同程度的数学表达式检索匹配,检索性能表现良好,但均需借助排版工具将二维的公式转换成更适宜处理的一维表现形式,普通用户并不熟悉排版工具的排版格式,大大降低了系统的使用范围;同时,被检索数学公式脱离了原本的语境范围,不同的语境下不同语义但形式相同的表达式均会被检索出,换言之,未从语义层面对表达式进行区分。
文献[9]在NTCIR[10]-11Math2 Task中,提出将数据集分成公式和公式所在的上下文两组,分别进行特征提取,结合公式的语义和公式结构检索到相关文档。自然语言千变万化,涉及范围较广,该实验中选取的数据集庞大,且在特征选取时只依赖公式前后的3句话,所获取的文本特征不足以表达公式本身的语义。受此启发,建立表达式对应的文本概念及概念之间的联系,可以针对表达式进行不同程度的语义检索。鉴于此,本文将有推理功能且用于多种领域信息检索[11-17]的本体论知识,运用在基于SFE的数学公式检索中作为语义表达的基础。
本体[18]作为一个很好的概念建模工具,曾被Tom Gruber[19]定义为“概念模型(conceptualization)的明确的规范说明”,不仅能从知识和语义上对信息进行描述和组织,还支持满足一定规则的逻辑推理操作,具有代表性的应用有Ontoseek[20]、Swoogle[21]等。文献[22]提出了基于网络本体处理数学公式间的关系,文献[23]以表达式中数学公式部分作为基点归纳出4类数学表达式多元信息的关联关系,使用改进后的通配符表示方法来构建数学表达式本体库,从而实现数学表达式的语义检索。本文在上述研究的基础上,提出一种基于Ontology扩展查询的数学表达式检索方法。
1 基于Ontology的数学表达式检索
基于SFE的数学表达式检索过程加入本体概念可实现语义检索的目的,其实现过程可分为以下4个层次:
1)在领域专家的协助下,运用结构化、半结构化和非结构化的方式抽取数据并建立数学名词与表达式之间关系,整合数据后构建相关的领域本体。
2)利用本体中的概念标注数学名词和表达式资源并以特定的格式存储,结果以RDF文档的方式存储,也可在本体工具中直接查询,并可根据一定的推理规则基于本体进行语义推理。
3)采集的html、xml等格式的数据集要对文本进行样式、格式、分词等预处理,有些网页会提供多种格式的数学表达式,如LaTeX、MathML等,因SFE检索结构针对LaTeX表达式,故提取LaTeX格式数据并预处理,避免因为书写习惯等因素产生噪音对检索结果造成影响。
4)数学表达式经过SFE检索后初步确定的目标文档,结合用户查询词在Ontology中查询扩展后的关联本体,从语义上2次判断该文档与用户查询词的关联性,并将高于一定相关性的文档输出到检索界面。
分析上述基于Ontology的数学表达式检索思想,构建语义检索模型如图1所示,该检索系统的核心在于本体构建、设计匹配规则,下文将详细阐述。

图1 语义检索模型结构框架
2 Ontology构建
表达式或符号是全世界通用的一门数学语言,正因为它能高度抽象地表达一类概念,即过于抽象,往往会在不同的学科领域,或相同学科不同的应用背景下被赋予不同的含义,如表1所示。

表1 不同语境下相同表达式表示的不同语义
此外,数学表达式的变形、推导以及不同的证明方法往往也会导致不同表现形式的表达式具有相同的内在语义,如表2所示。

表2 不同表达式表示的相同语义
无论是表2的哪种情况,在现有的数学表达式检索系统中,如果不加以语义的约束,则往往达不到想要的检索效果,本文引入本体的概念来改善这些问题。
Cuarino[24]从领域依赖程度将本体划分为顶级本体、领域本体、任务本体、应用本体。领域本体指依赖于具有特定含义的概念以及概念之间关系的领域。本文着力于建立数学领域中表达式以及其专有名词概念之间的联系,属于领域本体的范畴,通常领域本体的构建需要依赖领域专家的参与,建立合适且正确的通用联系。本文以权威著作《数学辞海》[25]为参考资料。
本体构建是整个语义检索系统的核心所在,建立合适且全面的领域本体能够提高检索的查全率查准率。下面按照从局部到整体的思路,首先分别从表达式和术语概念2个方面出发建模,然后从整体上建立两者之间的联系,最终建成数学表达式及其概念本体库。
2.1 概念
文献[26]总结认为Ontology一般有如下5种常规建模元语(modeling primitives):类/概念(classes/concepts),公理(axioms),关系(relations),函数(functions)和实例(instances)。类是相似术语所表达的概念集合;公理是确实存在不必证明的逻辑永真式;关系是领域内两概念间相互关系;函数是本体中一种特殊的关系;实例在本体工具中一般也称为个体(individual),是对类或概念的具体化,具有不可再分性。
《数学辞海》共6卷,以第1卷为例,卷中目录分为一级标题(如“平面几何”)、二级标题(如“面积”)和具体条目(如“勾股定理”)。初步规定,一级标题为类,二级标题为一级标题的子类,具体条目作为两者的实例,无论是类还是实例在本体工具中都称为本体On。卷中每个词条都有相应的文本注解和公式,将每个本体On的注解以一个文档的形式存储,形成文档集:
docS=(D1,D2,…,Dn)
(1)
摘录卷中目录为数学专有名词上下位关系表,记为mfn.dct。基于此,表对ICTCLAS分词系统作出改进,并对卷中文本进行分词处理,原子切分之前采用逆向最大匹配算法首先在上下文关系表中匹配。使得程序有效区分数学专业名词术语,又增加了切分数据的准确性。然后依据固定出现的语法句式,如“……即……”“……亦称为……”等编写程序得到数学专有名词同义词表,记为slmt.dct,以及去停用词等操作后提取原子词汇作为本体On的文本特征,记为:
F=(fn1,fn2,…,fnk)
(2)
提取公式集合,记为:
latS=(L1,L2,…,Ln)
(3)
当本体On在文档Dn中有相对应注解的公式Ln时,F也同样作为公式Ln的文本特征项。
采用向量空间模型(SVM)将公式Ln的文本特征表示为Ank,并存入数据库mysql中。
Ank=(fn1,wn1,fn2,wn2,…,fnk,wnk)
(4)
其中,fnk是公式Ln的特征项,wnk是特征项fnk所占权重,这里将fnk的tf(term frequency)值作为其权重wnk的值。以On为关键词在百度搜索引擎反馈页面取TopN条为计算tf值的依据,公式如下:
(5)
其中,Mi代表文档i中总的词汇量,Nik代表在文档i中特征词fnk出现的次数。
2.2 概念间关系
通过以上步骤提取了概念在水平与垂直层级的关系和相应公式以及公式对应的文本特征。但在实际操作中存在以下情况:
1)词条无特定公式注解,如词条“立体几何学”;
2)词条无特定公式注解但有常用的表达式或符号,如“代数余子式”对应Aij,“圆周率”对应π;
3)多个词条对应一个公式,如“勾股定理”“勾股弦定理”“毕达哥拉斯定理”都对应着公式a2+b2=c2;
4)一个词条对应多个公式,如公式a2+b2=c2是公式2ab+(b-a)2=c2进行推演后形成的,也即“勾股定理”对应这2个公式。
因此,在构建本体时不光要考虑到数学名词语义性,还要考虑数学表达式的同义性以及特殊的具有标识作用的符号或子式,在查询词扩展时按照一定策略都可作为关联本体以便有效地扩大检索范围。
本文根据实际需求建立如表3所示的关系。

表3 本体关系
在原有数据的基础上加入以上关系构建本体,其中数学表达式部分采用LaTeX格式进行处理,因其能实现数学表达式从二维结构到一维结构的转化操作,且在这个转化过程中LaTeX完整地保留了数学公式包含的所有信息,每一个确定的数学公式都有唯一的LaTeX公式与其对应,没有语义误差。一段简单的本体片段如图2所示。
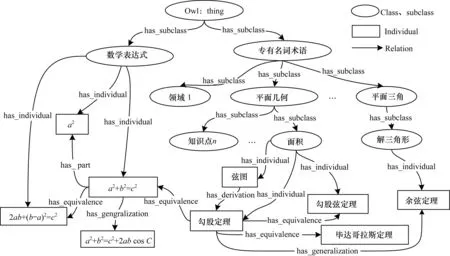
图2 本体关系片段
使用本体将关键字级别的零散的词汇提升为概念级别的关联,不同以往,综合地从关键词以及数学表达式2个方面建模,便于对用户输入查询词进行语义扩展。其中,同义公式以及具有标识作用的符号的加入提高了查全率,再用文本概念及文本特征Ank限定查准率,以期达到更深层次的数学表达式语义检索。
3 改进的SFE检索匹配
3.1 SFE特征提取原理
序列化特征提取(SFE)表达式特征提取方法认为一个表达式的结构特征(s)可分为以下3种:运算结构特征(o),常量结构特征(c),变量结构特征(v)。其中,运算结构特征由公式中的运算符及所有符号在公式二维结构内的位置信息构成,常量结构特征由表达式中的数字构成,变量结构特征由表达式中的字符性符号构成。3种特征分量的不同组合可以实现不同层次的表达式特征匹配,特征提取的流程如图3所示。该程序还对LaTeX符号指令自定义了编码字典,避免因解析过程中指令内字符的干扰而匹配到有误的检索结果。
与传统提取方式相比,基于SFE特征提取的检索系统使得检索范围更准确,检索结果层次性更好,获得的匹配公式与查询公式相似度高,但该方法不涉及公式所在文档与查询公式的语义关联性。故在此特征提取的基础上进行扩充,加入本体知识判断语料库中公式与其所在文档的关联程度,进一步限定检索范围,使得查询结果偏于语义化。
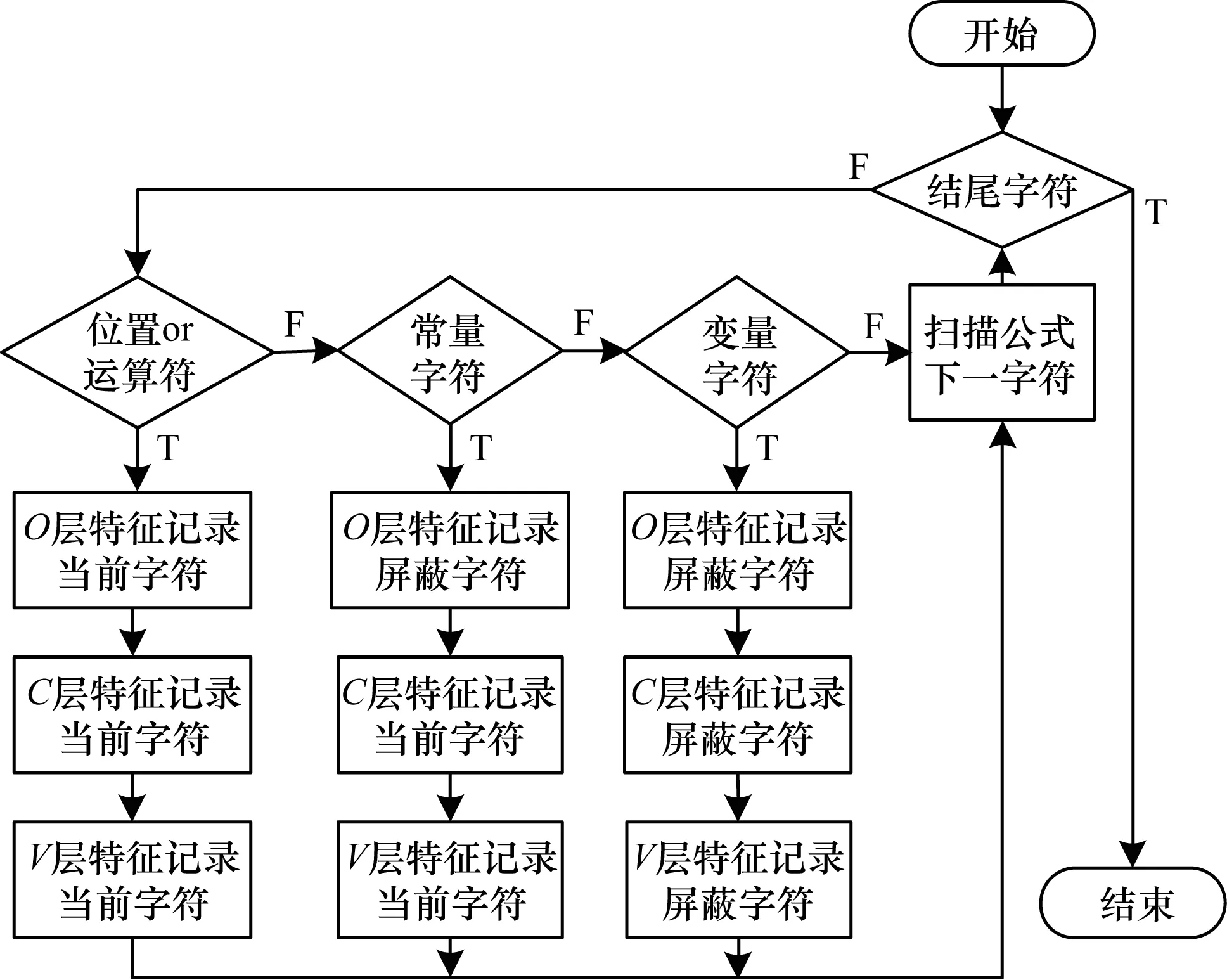
图3 特征提取原理流程
3.2 查询词扩展及数据预处理
本文运用斯坦福大学的Protégé5.2构建本体,并用Jena实现推理机制。对用户的查询请求通过查询转换器按照ontology将其转换为规定格式,并进行查询词扩展。也可用Protégé自带的可视化工具OntoGraf进行可视化查询扩展,当检索一个关键词时有多种查询模式可供选择以满足不同查询需求,生成的图存为DOT文件,由于涉及诸多中文,选择utf8进行转码即可查看。
用户输入的查询词qW在本体库中按照关系查询扩展后的关联本体为:
relO=(o1,o2,…,on)
(6)
找出与查询词qW最相关的表达式Lr以及“has_part”部分的子式Lj和“has_equivalence”的同义公式Lk,再从数据库中找出向量Ark表示的表达式Li的文本特征:
Ark=(fr1,wr1,fr2,wr2,…,frk,wrk)
(7)
数据集以单个文档方式存储到数据库中,记为:
Docmn=(d1,d2,…,dn)
(8)
对每篇文档dn的每一段落pn进行改进后的分词处理、去停用词,并对出现的原子及其在该段落的词频使用向量Bnj进行语义标注,记为:
Bnj=(pn1,wn1,pn2,wn2,…,pnj,wnj)
(9)
3.3 改进SFE的检索匹配
考虑到以往的数学表达式检索系统中,用户被要求输入相应排版格式的数学公式,不熟悉该排版格式的用户无法正确输入要查询的表达式导致用户体验差,用户群体局限等问题。本文系统在查询入口做了更适宜用户操作的改变,实现步骤如下:
输入自然语言或LaTeX格式表达式
输出含LaTeX格式表达式的文献
步骤1用户输入查询词qW,若匹配Ontology执行步骤2;否则执行步骤5。
步骤2qW在Ontology中进行查询扩展出关联本体集合relO,关联公式Lr和同义公式Lk以及Lr的特征集Ark,执行步骤3。
步骤3对Lr和同义公式Lk进行SFE三层特征提取并初次筛选语料库dn,得到目标文档dq。找到目标文档dq中公式所在段落pq,提取pq的标注Bqj并与关联本体集relO匹配,若满足{x|∃x=pnj∩on}则认定相关并执行步骤8;否则执行步骤4。
步骤4将Bqj按照Lr的文本特征Ark进行修改:将Bqj中满足{x|x=(pnj∩frk)}的特征项保留,其余剔除;在Bqj中添加满足{x|x=frk-(pqj∩frk)}的特征项并令其权重为0。修改后的向量记为:
(10)

(11)
从而算出段落pq对关联公式Lr的语义关联度:
support(pq,Lr)=cosθ+φ
(12)
其中,φ代表文档中其他影响因子,视所有文档中影响因子都为相等值φ。
当support(pq,Lr)>α时,认定该文档与原始查询词是相关的,执行步骤8。
步骤5判断查询词qW是否为公式,若是则执行步骤6;否则执行步骤7。
步骤6对qW进行SFE特征提取并检索语料库dn,执行步骤7。
步骤7对语料库进行关键字检索并检索语料库dn,执行步骤8。
步骤8输出最终被检索的相关文档并结束。
4 实验结果与分析
为了验证基于Ontology和SFE判断数学表达式与文档的关联关系的有效性和可行性,收集了中学数学、化学和物理学科的课本、试卷和习题等相关资料,共获得含LaTeX公式的文档为7 268篇。这里针对实际情况设定如下前提条件:
1)因数据涉及多种学科领域,待检索的语料库中通常不会完全出现整个公式,而是存在包含、内嵌等情况,故被检索表达式经过SFE三层特征匹配命中的文档都认为与原查询公式形式相关。
2)如果通过支持度计算出被检索段落与查询词相关,则认为该文档与查询词相关。
4.1 评价标准的建立
本文根据常见检索系统性能指标和评定标准,对系统进行查全率和查准率比较,并按照实际情况规定扩展率。
例如:语料库M,当检索样本A时,语料库中与A相关的文档数为relD;普通的数学公式检索(这里模拟SFE检索)命中的文档数为DSsfe,其中与查询样本A确切相关的文档数为DStrue;经由本体改进后的系统检索文档数为DOontology,其中与查询样本A确切相关的文档数为DOtrue。其中,relD、DSsfe和DOtrue均采用人工统计方法。据此给出如下评价指标的定义:
定义1查准率为检索结果集内判断正确的文档数量与检索结果集内的文档总数的比值。
设SFE系统的查准率为:
(13)
设本文系统的查准率为:
(14)
定义2查全率为检索结果集内正确的文档数量与检索结果集内实际正确的文档数量的比值。
设SFE系统的查全率为:
(15)
设本文系统的查全率为:
(16)
定义3扩展率(Extension ratio,E)为基于本体查询扩展后结果集内增加的正确文档数量与扩展后结果集内总文档数量的比值。
设系统扩展率为E:
(17)
例如:语料库M,当检索样本A时语料库中确切相关的文档总数为relD=550;模拟SFE检索后得到文档总数DSsfe=2 500,其中,与A语义相关的有DStrue=200,样本A在基于本体检索后得到的文档总数DOontology=500,与查询样本A确切相关的文档数为DOtrue=450。参考以上评价标准,计算相应参数如表4所示。

表4 样本A评价参数 %
4.2 实验对比分析
因为本文系统可以输入自然语言,在验证自然语言时,基于SFE的查询,找到自然语言相应的标准表达式再做验证。数据集中类似“y=ax2+by+c”的标准样式表达式数量极少,本文选用的样本尽量简化为常出现在公式中的局部表达式、符号或字母。实验样本选取如表5所示。

表5 实验样本选取
在数据集中分别模拟SFE检索和基于Ontology的数学表达式检索,对以上选取的样本返回结果进行数据统计并记录如表6所示。

表6 实验数据
对上述数据计算得到评价标准如表7所示。

表7 实验数据评价值 %
图4所示为以柱状图形式,分析4个样本经过改进后检索系统中扩展率在检索结果集上的分布情况。为进行直观有效对比,在展示扩展率E的同时,统计改进前检索正确的相关文档占改进后检索的总文档的百分比,记为保持率,和改进后检索的错误文档占总文档的百分比,记为错误率。其中,横坐标为样本编号,纵坐标为以上3类在结果文档中所占比例。4个样本的检索结果如表8所示。

图4 基于Ontology的数学表达式检索结果分布

%
从表7可以看出,改进后的系统无论从查全率还是查准率均比原系统有所提高,尤其是查全率接近百分百。影响查全率RO的因素在于,文档中有一部分与待检索查询词确实有关联,但只出现查询词或相关查询词并未出现对应表达式,在初次检索中已经被错误地过滤掉,属于该系统中的不可控因素。
从图4可以看出,每个样本在有一定保持率的前提下,均有不同程度的扩展,说明经过本体查询扩展后扩大了原系统的查询范围,使得最终检索结果中与初始查询词语义相关的文档增多,进而显示出本体查询扩展的必要性。图4错误率占比较少,表明改进后的系统并不单纯地匹配表达式形式,对可能涉及多种学科多种领域的返回文档使用本体进行语义限定:将初次检索文档中表达式形式相同但表示其他学科语义的文档剔除,或者将表达式相同也在数学领域但表示不同概念的文档加以区分,使得最终结果语义关联性大、正确率高。
5 结束语
本文提出一种基于Ontology扩展查询数学表达式的检索方法。依据本体在查询扩展中的优势同时对查询词进行不同程度的词汇和表达式扩展,在检索阶段达到输入自然语言或LaTeX格式表达式匹配不同的检索策略,从而实现与初始查询词语义相关的表达式所在文献的输出。实验结果表明,基于本体改进的数学表达式检索效率比基于SFE的检索系统在语义检索方面更优,在查全率、查准率上均有提升,一定程度上扩大了查询范围,在语义上限设定了检索范围,使得检索语义明确且集中,更倾向于了解用户检索意图,提升用户检索体验。下一步将增加与完善数学表达式中本体之间的关系构建,并对最终输出结果集进行相关性排序。
[1] MILLER B R,YOUSSEF A.Technical aspects of the digital library of mathematical functions[J].Annals of Mathematics and Artificial Intelligence,2003,38(1-3):121-136.
[2] MathDex search tool [EB/OL].[2017-04-13].http://www.mathdex.com/8080/mathfind/search.
[3] Math Web search [EB/OL].[2017-04-13].http://kware.eees.iu-bremen.de/.
[4] LIBBRECHT P,MELIS E.Semantic search in leactivemath[C]//Proceedings of the 1st WebALT Conference.Eindhoven,Holland:[s.n.],2006:97-109.
[5] MISUTKA J,GALAMBOS L.Mathematical extension of full text search engine indexer[C]//Proceedings of the 3rd International Conference on Information and Communication Technologies:From Theory to Applications.Damascus,Syria:[s.n.],2008:1-6.
[6] HU X,GAO L,LIN X,et al.WikiMirs:a mathematical information retrieval system for wikipedia[C]//Proceedings of the 13th ACM/IEEE-CS Joint Conference on Digital Libraries.New York,USA:ACM Press,2013:11-20.
[7] SOJKA P,LISKA M.Indexing and searching mathematics in digital libraries[C]//Proceedings of Conference on Intelligent Computer Mathematics.Berlin,Germany:Springer,2011:228-243.
[8] 李 彬.基于SFE的LaTeX表达式检索系统[D].保定:河北大学,2017.
[9] PINTO J M G,BARTHEL S,BALKE W T.QUALIBETA at the NTCIR-11 math 2 task:an attempt to query math collections[C]//Proceedings of the 11th NTCIR Conference.Tokyo,Japan:[s.n.],2014:103-107.
[10] NTCIRmath 2 wikipedia task[EB/OL].[2017-01-27].http://ntcir11-wmc.nii.ac.jp/index.php/NTCIR-11.
[11] DRAGONI M,PEREIRA C D C,TETTAMANZI A G B.A conceptual representation of documents and queries for information retrieval systems by using light ontologies[J].Expert Systems with Applications,2012,39(12):10376-10388.
[12] KARA S,ALAN O,SABUNCU O,et al.An ontology-based retrieval system using semantic indexing[J].Information Systems,2012,37(4):294-305.
[13] 孟红伟,张志平,张晓丹.基于领域本体的文献智能检索模型研究[J].情报杂志,2013,32(9):180-184.
[14] 张 胜.一种基于领域本体的语义检索模型[J].软件导刊,2014,13(3):18-20.
[15] REMI S,VARGHESE S C.Domain ontology driven fuzzy semantic information retrieval[J].Procedia Computer Science,2015,46(2):676-681.
[16] 王旭阳,尉醒醒.基于本体和局部共现的查询扩展方法[J].计算机科学,2017,44(1):214-218.
[17] RUY E B,GUIZZARDI G,FALBO R A,et al.From reference ontologies to ontology patterns and back[J].Data and Knowledge Engineering,2017,109 :41-69
[18] 邓志鸿.Ontology 研究综述[J].北京大学学报,2002,38(5):730-737.
[19] GRUBER T R.A translation approach to portable ontology specifications[C]//Proceedings of Japanese Knowledge Acquisition for Knowledge-based Systems Workshop.Tokyo,Japan:[s.n.],1992:89-108.
[20] NAVIGLI R,VELARDI P.Learning domain ontologies from document warehouses and dedicated websites[J].Computational Linguistics,2004,30(2):151-179.
[21] DRUMOND L,GIRARDI R.A Survey of ontology learning procedures[C]//Proceedings of IEEE Workshop on Ontologies & Their Applications.Washington D.C.,USA:IEEE Press,2008:427.
[22] ANNAMALAI M,STERLING L.Dealing with mathematical relations in web-ontologies[C]//Proceedings of IEEE OAS’03.Washington D.C.,USA:IEEE Press,2003:1-8.
[23] 王小龙.基于本体的数学表达式检索技术研究[D].重庆:重庆大学,2014.
[24] GRUBER T R.A translation approach to portable onto-logies[J].Knowledge Acquisition,1993,5(2):199-220.
[25] 《数学辞海》编辑委员会.数学辞海(第一卷)[M].太原:山西教育出版社,2002.
[26] PEREZ A G,BENJAMINS V R.Overview of knowledge sharing and reuse components:ontologies and problem-solving methods[C]//Proceedings of Workshop on Ontologies and Problem-Solving Methods.Washington D.C.,USA:IEEE Press,1999:1-15.
