机器学习聚类组合算法及其应用
2018-05-28王琳璘谢忠局陈永权王琦
王琳璘,谢忠局,陈永权,王琦
机器学习聚类组合算法及其应用
王琳璘1,谢忠局2,陈永权3*,王琦4
1. 国网能源研究院有限公司, 北京 102209 2. 北京汇通金财信息科技有限公司, 北京 100031 3. 华北电力大学, 北京 102206 4. 国网国际融资租赁有限公司, 北京 100020
本文首先分析了电力负荷的特点,并对现有的负荷特性指标做了分类,然后在详细分析系统聚类法和K-means聚类算法的基础上,结合电力负荷特性的特点提出了一种基于系统聚类与K-means相结合的组合分类方法,该方法可以用于电力负荷特性分类,也可以用于现金流量历史数据的特性分类以及负荷预测的数据分析。最后,应用某产业园区电子企业的日负荷数据对算法做了算例验证,算例结果表明该方法能够对用户的负荷特点做出较为准确的判断。
系统聚类; K-means; 电力用户; 负荷分类
电力工业中,无论是大比例的可再生能源的消纳还是对用电能效的管理都需要对负荷特性做精细化的分类,并做准确的判断。但是,面对群体庞大的电力用户,是没有可能对每个用户都去分别建立模型,而是需要通过对典型用户类别的准确描述,然后用典型用户类别类推其它用户,从而类推确定与之同构的用户的综合负荷特性[1,2]。本文将机器学习中的系统聚类法和K-means聚类方法按照各自的特点有效的组合在一起,构成了新的组合聚类法[3,4]。该方法能够对电力用户的负荷类型进行分析,也可以应用到电价制定、负荷预测等多项工作中。
1 用户负荷特性指标
根据历史发展和现状我国已经形成一套负荷指标体系。该指标体系包含指标有的是曲线型指标有的是数值型指标,考虑实用性本文对指标体系分类如表1所示[5,6]。
2 系统聚类法与K-means算法
2.1 系统聚类算法
系统聚类是将多个样品分成若干类的方法,其基本思想是:通过选择类与类之间的最小距离,把距离最近的类合并,直到合并成一类为止,算法步骤如下[7]:
第一步:建立个自成一类的初始模式样本,即建立类,1(0),2(0),…,Y(0)。然后计算类与类之间的距离。
第二步:距离矩阵()已知的条件下,则求()中的最小元素。当它是Y()和Y()类之间的距离建立新的分类:1(+1),2(+1),…,l(+1)。
第三步:计算合并了的新类别的距离,得到(+1)。计算Y(+1)与其它暂未合并的1(+1),2(+1),…,l(+1)之间的距离,可使用不同的距离计算方法加以计算。
第四步:如果还没有获得期望的聚类结果,则重新迭代返回第二步。
总结来看,系统聚类法最大优点是系统自己根据数据之间的距离来自动列出类别。
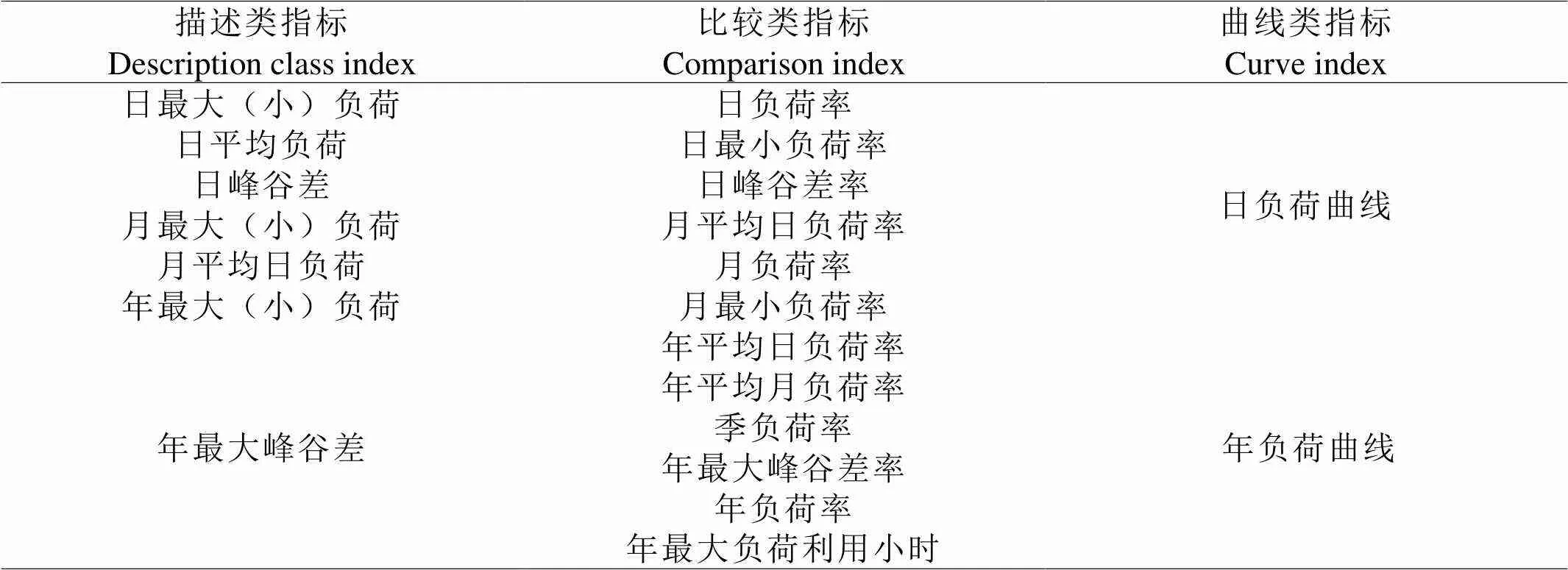
表 1 负荷特性指标分类
2.2 K-means聚类算法
最小最大聚类算法是一种综合考虑各个簇之间簇内方差值关系的聚类目标函数,提出在最小化个簇中的最大簇内方差值来进行聚类,即将公式(1)聚类最小化,被称为最小最大聚类方法[8]。
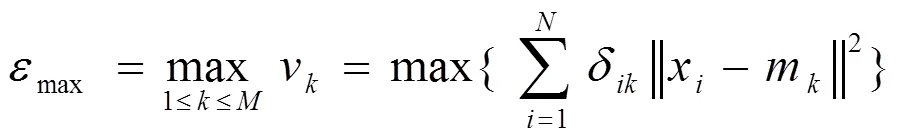
将公式(1)通过迭代的方式,松弛化为公式(2)。
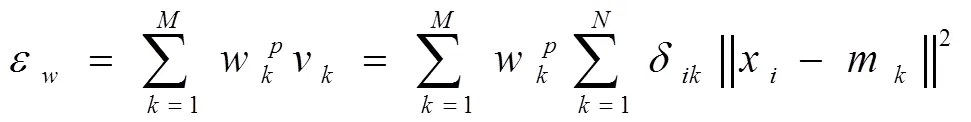
采用拉格朗日乘子法求解,经过运算可以得到如下的解:
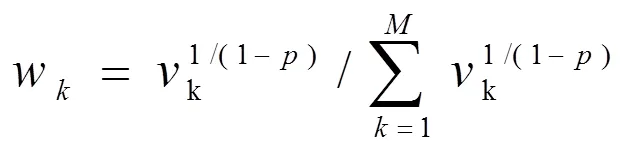
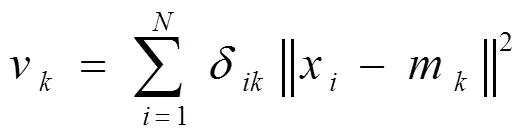
聚类过程就是簇和聚类中心不断更新的过程。随着权重的增加,接近聚类中心的样本才被划分到簇中。聚类中心的更新公式为(6)。

由于0<=<1,1/(1-)>0,方差越大则权重越大。
3 组合算法设计
3.1 组合算法构建
由于电力负荷的样本数量较大,特征向量维数较多,若单独采用一种聚类方法,效果往往不是很理想。因此为了更客观准确的识别样本类型,提高分类效率,必须找到一种可以适合大样本、高维度的聚类算法进行负荷特性聚类[9]。观察各个聚类算法的特点可以发现,初始聚类中心的设置对聚类算法的聚类效果影响很大,导致其结果不稳定,而系统聚类法虽然在处理大样本时,重复性步骤较多,但却是一种过程简单、原理直观,分类快速且无需初始设定的经典聚类算法,同时传统聚类算法的聚类结果容易陷入局部最优解,因此本文采用二次组合聚类法对用户负荷特性进行分类研究,即一次聚类采用系统聚类法对负荷特性进行分类;二次聚类采用最小最大均值聚类算法,聚类中心由初次系统聚类结果提供[10]。既可避免传统聚类算法对初始参数的敏感性,又能取得分类准确客观的聚类效果,图1为组合聚类算法流程图。
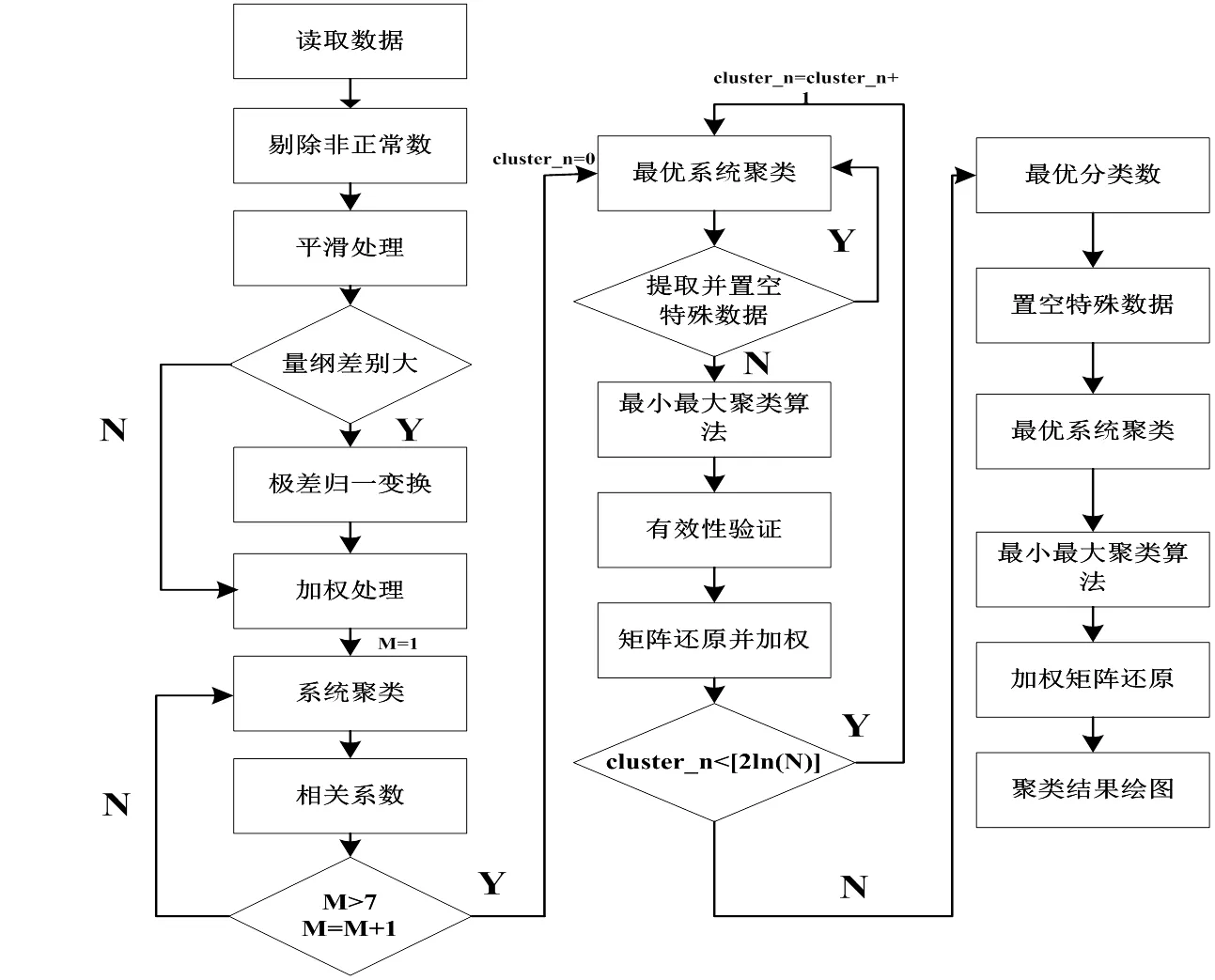
图 1 机器学习聚类组合算法流图
3.2 机器学习聚类组合算法程序流程
本文提出的机器学习聚类组合算法的执行分为三部分,第一部分负责数据导入、预处理以及特征向量提取,第二部分为改进的组合聚类算法执行,第三部分显示聚类效果,提取聚类结果中的特殊数据组[11,12]。执行流程如图2所示。

图 2 简化的程序流程图
4 算例分析
本算例选取某工业园区中的某电子元件制造企业进行每日负荷数据的组合聚类分析。选取某电子元件制造企业2010年4月及6~9月的每日24点负荷数据作为聚类的特征向量,一共152组数据,剔除非正常数据后剩余130组,分为6类,且提取出三组特殊数据[13,14]。聚类结果分为见下图所示。
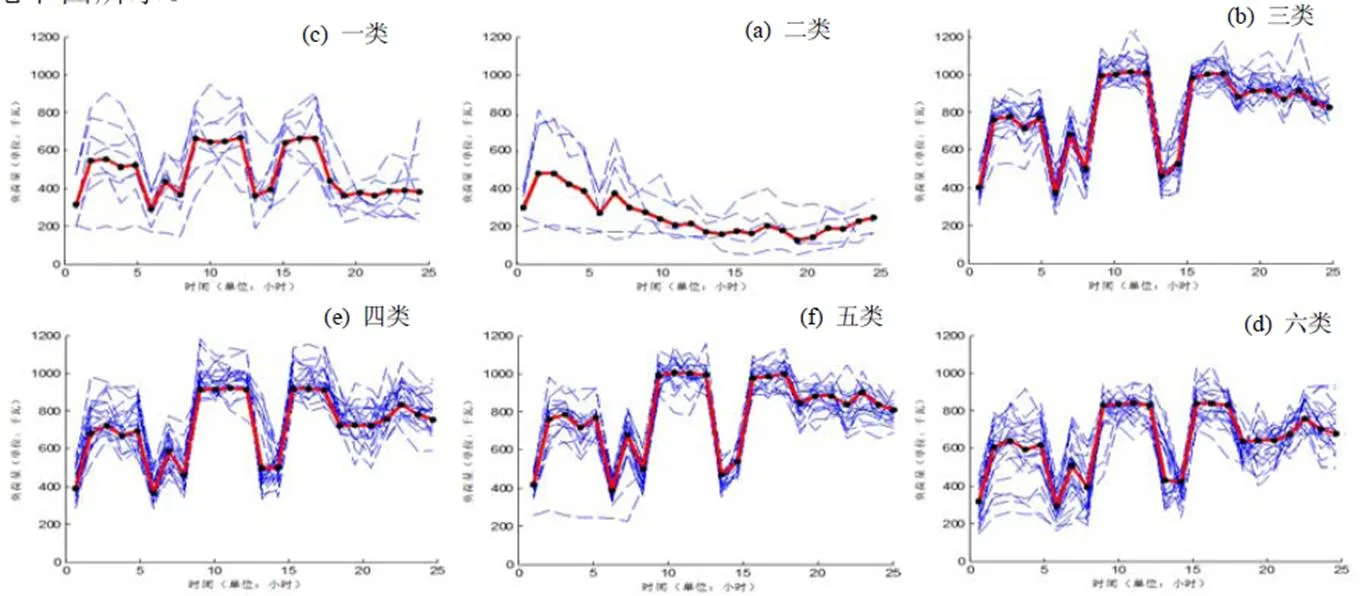
图 3 某电子元件制造企业负荷聚类
从图中可以看出,负荷曲线出现三个高峰值,分别在2点,8~11点和14~16点,有一部分为迎峰负荷。分别分析各类别情况可以看出,第一类和第二类比较特殊,属于减产和停产的情况,其他几类负荷曲线的形态类似。分析高峰负荷可以看出,负荷最高达到1200 kW,最低在800 kW,大致稳定在1000 kW,且和季节没有太大的关联,初步分析得知,高峰时可以通过减产等措施降下200~300 kW的负荷量。
算例结果表明该方法能够实现通过掌握和分析电力系统中的负荷构成,达到引导电力用户选择合理的用电时间,或采用合理的蓄能方式,达到移峰填谷、高效利用电能的作用。可见该组合聚类法对于进行负荷特性聚类研究,具有非常重要的理论和实践意义。
[1] 杨浩,张磊,何潜,等.基于自适应模糊C均值算法的电为负荷分类研究[J].电力系统保护与控制,2010,38(16):111-115
[2] 刘莉,王刚,霍登辉.K-means聚类算法在负荷曲线分类中的应用[J].电力系统保护与控制,2011,39(23):65-68,73
[3] 刘自发,庞错镜,王泽黎,等.基于云理论和元胞自动机理论的城市配电网空间负荷预测[J].中国电机工程学报,2013,33(10):98-105.
[4] 彭显刚,赖家文,陈奕.基于聚类分析的客户用电模式智能识别方法[J].电为系统保护与控制,2014,42(19):68-73
[5] 肖白,憂鹏,穆钢,等.基于多级聚类分析和支持向量机的空间负荷预测方法[J].电力系统自动化,2015,39(12):56-61
[6] 蒲天骄,陈乃仕,王晓辉,等.主动配电网多源协同优化调度架构分析及应用设计[J].电力系统自动化,2016,40(1):17-23
[7] 冯明灿,谢宁,王承民,等.考虑瞬时性峰值负荷特性的配电网可靠性规划[J].电网技术,2015,39(3):757-762
[8] 邓海,覃华,孙欣.一种优化初始中成、K-means聚类算法[J].计算机技术与发展,2013(11):42-45
[9] 刘思,傅旭华,叶承晋,等.考虑地域差异的配电网空间负荷聚类及一体化研究方法机[J].电力系统白动化,2017,41(3):70-75
[10] 刘思,傅旭华,叶承晋,等.基于聚类分析和非参数核密度估计的空间负荷分布规律研究[J].电网技术,2017,41(2):604-609
[11] 李知艺,丁剑鹰,吴迪,等.电力负荷区间预测的集成极限学习机方法[J].华北电力大学学报,2014,41(2):79-87
[12] 符杨,朱兰,曹家麟.基于模糊贴近度理论的负荷密度指标求取新方法[J].电力系统自动化,2007,31(19):46-49
[13] 黄宇腾,侯芳,周勤,等.一种面向需求侧管理的用户负荷形态组合分析方法[J].电力系统保护与控制,2013,41(13):20-25
[14] 韩家炜.数据挖掘:概念与技术[M].范明,译.北京:机械工业出版社,2012:299-301
A Machine Learning Combination Clustering Algorithm and Its Application
WANG Lin-lin1, XIE Zhong-ju2, CHEN Yong-quan3*, WANG Qi4
1.2.100031,3.102206,4.100020,
The characteristics of power load first analyzed and the load characteristics indexes were made a classification in this paper. Then based on a detailed analysis of system clustering method and K-means clustering algorithm, combined with the characteristics of the load characteristics of power system was proposed. This method can be applied to the classification of power load characteristics, as well as the classification of cash flow historical data and data analysis of load forecasting. Finally, the daily load data of a certain electronic enterprise as example to validate the algorithm, the results show that the method can make more accurate judgments in load characteristics of users.
System clustering; K-means clustering; power enterprise; load classification
TP181
A
1000-2324(2018)03-0463-04
2017-02-13
2017-03-20
国家电网公司总部科技项目:改革背景下国家电网公司现金流管理关键技术研究(sdw20170101)
王琳璘(1983-),女,硕士,副所长,主要研究方向为金融方向. E-mail:wanglinlin16@126.com
Author for correspondence. E-mail:yqc@vip.163.com
