基于用户兴趣模型的个性推荐算法
2018-05-23郁钢陆海良单宇翔高扬华
郁钢 陆海良 单宇翔 高扬华

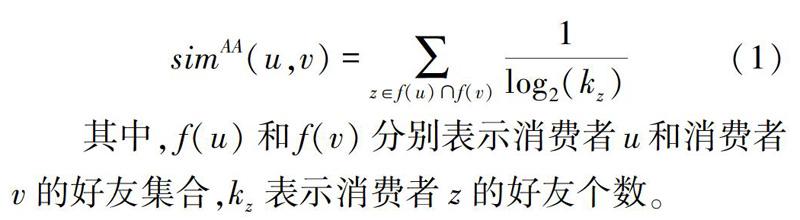
摘 要: 协同过滤推荐技术和基于商品属性的推荐技术是比较流行的个性化推荐方法,但是前者存在数据稀少和新对象问题,后者也存在无法挖掘用户潜在兴趣的问题。本文采用基于区域用户的相邻用户进行数据评分的矩阵填充,并采用商品之间的关联规则应用和解释来向用户推荐产品。测试表明,本方法解决了新商品的问题,并且在推荐的准确度、新颖性和覆盖度上有了较好的效果。
关键词: 用户兴趣模型;个性推荐;数据稀疏问题
Abstract:Collaborative filtering recommendation and recommendation based on product attributes are popular personalized recommendation methods. But the former can't handle the issues about sparse data and new objects the latter is not capable of mining the potential interests of users. This paper uses the matrix of data grading based on the adjacent users of the regional users and recommends the products to the users by applying and explaining the association rules between the commodities. Testing shows that this method solves the problem of new products and has good results in terms of accuracy novelty and coverage.
Key words: user interest model;personalized recommendation; sparse data
1 协同过滤算法
协同过滤(collaborative filtering CF)推荐算法是当前使用最为频繁也最有效果的个性化定制销售策略,可以利用消费者之间的共性向目标用户推荐已知用户的兴趣偏好[1]。CF算法一般利用用户对商品的评价信息和用户信息来构造用户-商品矩阵,根据用户之间的相似性产生邻居用户集,进而产生推荐数据集[2]。针对目标用户的推荐过程就是使用矩阵数据进行预测,评估用户对未接触过产品的评分情况、即感兴趣度,由此在大量数据集中计算出推荐列表。
CF的推薦算法的主要实现过程则如图1所示。对其内容可描述为:
(1)生成用户-商品矩阵;
(2)采集相近用户数据集;
(3)推荐结果集合。
用户对商品的评价可分为显式评价和隐式评价。其中,显式评价是指用户对自己感兴趣的商品进行有意识的评分。隐式评价[3]是用户在网页中的驻留时间,对某一商品的消费记录等方式。现阶段针对企业的营销,多是采用显式和隐式相结合的方式来获取信息。
2 数据稀疏问题
CF算法中的评分分布存在分散性问题,即数据稀疏问题,因数据量太少会引起寻找邻居用户时的困难,进而将无从保证个性化的推荐效果。在用户-商品矩阵中,空缺的评分可设置为一个固定值,该值可采用评分均值或者总分的中间值,当下已有研究能够证明这种方式可以改善个性化推荐的结果。但是这种方式并不能很好地解释用户为什么被赋予评分均值或者中间值。
在上述的CF推荐算法中,若消费者A和消费者B之间不存在对同一商品进行评分的行为,即使2位消费者之间对商品属性的偏爱存在很多的相同点,推荐系统也无法判定2位客户之间的关联关系。基于商品属性相似度的个性化推荐可以解决这个问题,但若针对2个商品,同一用户还未对其给予评价,这2个商品之间的相同点也将难于计算出来。
针对评分矩阵的稀疏性问题,许多研究从用户关联、技术创新等不同角度提出解决方案。从用户角度,如张忠平[4]等提出将用户对商品的评分作为一个集合,来计算消费者之间的共同点,筛选增加用户对商品评价共同的评分项,从而可以提升预测的准确度。秦凯[5]等人从社会网络信任特征出发来寻找相似用户。HUANG[6]等人考虑商品属性信息和用户注册信息的关联匹配。从技术角度,张光卫[7]等人通过聚类技术对大量数据的评分结果内容实现降维处理,进而减小被推荐者近邻的整体范围空间,提高评测的准确度。王兆国[8]等人利用用户或物品的评分频次信息,建立了线性回归模型,以此预测用户对未置评物品的评分。王明佳[9]提出基于项目情景的推荐方法综合项目分类对用户提供个性化推荐模式。
上述研究在一定程度上提高了个性化推荐的准确度,部分解决了数据稀疏性问题。但是,在测定两者之间的相同点时,前提条件是用户与用户之间并不存在关联关系,也就是说用户被相邻消费影响程度是相同的。在实际应用中,不同的消费者受其兴趣度相邻用户的影响程度并非完全相同,这种情况会直接影响商品最终评分的精准性,进而影响到用户的实际需求[10]。虽然引入、也研究了一些情景因素,但却仅仅考虑了用户自身的属性和商品的分类,而并未关注重视用户周围因素对个性化所造成的作用效果。
综上,在评分数据极端稀疏的情况下,前述研究没有同时考虑到用户评分行为和用户环境两种重要因素,依然无法准确地度量用户间相似性,造成评分预测准确度较低,导致推荐质量也随即呈现下降态势。在企业的个性化推荐营销的过程中,多数推荐策略都是依据用户对商品评分的高低来预测消费者对商品的偏爱程度,不同消费者之间利用评价相同产品的个数来测定用户之间的相似性。这种情况是在数据混合的条件下展开的,而没有对用户划定分类。如果能够提前进行用户分类,分类的原则主要基于用户所在区域、所处时间段等情景,如此可将相似用户相对准确地合并归类,而在此基础上实施推荐算法,才能有效改进评分预测准确度,从而提高协同过滤的推荐质量。
3 混合协同过滤算法
提出新客户受周围因素的影响来解决数据稀少问题,即对于新客户而言,其所在的地域和周围生活环境会在很大程度上影响到用户的决定。因而,可以将新客户的空白评分依据好友用户的评分进行填充,不仅可以增加用户的个人数据集,还可以丰富商品属性的特征数据集,有利于发现客户隐含的兴趣偏好。在以下研究中,设计提出了根据好友关系和商品属性的特性功能来缓解推荐算法带来的数据稀少的缺陷。该算法主要是通过老用户与新用户是好友的关系来计算用户对商品属性的偏爱程度,间接获取新的消费者对商品的选择方向和预计评分,从而增加销售量,扩大企业的知名度。
本文采用的是Adamic-Adar指数和资源分配指数计算客户与客户间的相同点。原理来自计算机网络结构图,即任意的2个未连接的节点之间在未来有可能会发生链接的概率大小。此后,则拓展到了电子商务中用于推演得到用户与商品之间的偏爱程度和社交关系网中计算好友之间的信任程度。在企业中,可根据相同地域条件来划分新用户,将新用户划分到具有类似爱好的老用户群体中。
Adamic-Adar指数是指通过增加好友数量较小的相似权重来提升共同好友的权重计算(排除好友为零的情况),数学定义如下:
资源分配指数表征着在复杂网络上进行动态资源分配的应用指数。假设有2个节点u、v没有直接相连。节点u可以把资源发送给v,两者之间的共同邻近节点起着传送的作用。
假设每个传送者有一个单位资源,并且传送给每个邻近节点的概率是一样的。资源分配指数的定义如下:
即sim(u,v)=sim(v,u),虽然彼此间的目的不同,但是两者有着相似的结构,也就是说降低了共同邻近节点。
通过新用户与好友之间的关系分析得到两者之间的相关性。对于商品i和用户u来说,基于朋友关系的预测值具体可如式(3)所示:
其中,Ni是对商品i的评分预测客户数据集合;ICv是客户V评价商品的个数;sim(u,v)是用户U和用户V之间的相关性。
基于商品的已有属性信息挖掘出用户对项目的偏爱程度,因此基于商品属性信息的预测评分值的计算公式可表述如下:
其中,NTi是项目i的所有标签;ITCt表示标签t的商品个数;rel(u,t)表示用户u对标签t的偏爱程度。
依据新用户与老用户之间关联关系,得到预估评分值与根据商品属性信息的预评分后,研究通过设定权重α对2种预测评分构成的优化组合而运算推出预测评分值公式如下:
4 实验分析
在研究中,对α进行了实验设定,分别将α取值为0,0.2,0.4,…,1。在此基础上,为了消除推荐商品数量过多对α值的影响,研究又同步设置了推荐商品数量,也就是从5、10、15、20、25共设计展开了5组仿真实验。实验运行结果如图2所示。
由图2可以看出,随着α值的变化,其波动趋势基本一致:随着α值增加,开始处于上升状态,达到最大值以后,缓慢下降。在本实验中,当α=0.2时,准确率为最高,这也进一步证明了好友关系的模式和商品属性的混合协同过滤算法要优胜于单独的基于商品属性信息的算法性能。本文算法的设计流程内容表述可见如下:
步骤一 选定要推荐的地区和商品规格,依据传统的推荐算法计算目标用户的兴趣相似的用户和非相邻用户数据集。对于非邻居的用户的数据集取值概率性较大的作为用户评分的参考值,结合邻居用户的评分数据集进行汇总,给出评分数据。
步骤二 筛选用户信息,根据用户自身属性进行劃分聚类,基于用户年龄、收入、生活区域等因素研究划分用户的类别。
本文选择某类商品在湖南省的销售数据作为推荐数据来源,针对客户背景、客户情景下和非相邻数据集进行推荐评估。湖南数据库中包含了对产品的真实评分数据。系统新用户在使用前需要先填写个人信息,并且对已购买产品做出评价,总分数为10分,评分越高,意指对该商品就越满意。此外,还需要填写个人的年龄、性别、职业等信息。在这个数据库中包含了大量的用户数据,本次研究集中选择长沙地区用户的数据实现地域性的个性分析。数据库中存在很多表结构,基础性的就包含了用户评价表、用户个人信息表、产品规格表等在内。
表中的商品分类有很多,比如依据纯度、包装、香型、年份、产地等特点生成得到的商品分类。整个实验数据集可分为训练集和测试集,其中训练集占总数据集的80%,而测试集则占据了20%。整个数据集提取了来自湖南地区的5 000条数据,涵盖了400位用户对100个不同规格商品的评价。这里,将用户的编号设置为1~400,商品编号设为1~100。研究中,存在一个用户Uk未对数据库中的商品进行评价,因而需要预测用户Uk对商品i的评分。现取n=28,基于传统的预测方式计算出商品n的最近邻近值,采用皮尔森相关系数算法计算得出商品n的10个最近邻居。同商品n最近似的其它商品编号可见表1。
由表1可以看出,与商品n相似的产品有10个。为了获得用户对商品的预测评分,在实验中选取上述产品的均值。也就是说,基于好友关系的用户对商品的评分预测值可设定为其邻居用户针对多个相似商品的均值。这种方式在很大程度上解决了矩阵存在评分数据稀疏的问题。
5 结束语
协同过滤推荐技术和基于商品属性的推荐技术是在个性化推荐研究中颇为流行的项目领域重点课题。只是分析可知,前者存在数据稀少和新对象问题,后者也存在无法挖掘用户潜在兴趣等问题。本文针对这一数据稀疏性问题,采用了基于区域用户的相邻用户进行数据评分的矩阵填充。对于无法挖掘用户潜在兴趣的问题,采用商品之间的关联规则应用和解释来向用户推荐产品。通过充分利用地域性、用户好友信息、商品特性等在相当程度上解决了推荐技术中的现实问题,对于企业中个性化销售创造了有利条件,从而增加了整个企业的销售量。
参考文献
[1] 冷亚军,陆青,梁昌勇. 协同过滤推荐技术综述[J]. 模式识别与人工智能 2014 27(8):720-734.
[2] 刘青文. 基于协同过滤的推荐算法研究[D]. 合肥:中国科学技术大学,2013.
[3] STROBBE M VAN LAERE O DHOEDT B et al. Hybrid reasoning technique for improving contextaware applications[J]. Knowledge and Information Systems 2012,31(3):581-616.
[4] 张忠平,郭献丽. 一种优化的基于项目评分预测的协同过滤推荐算法[J]. 计算机应用研究 2008 25(9):2658-2660,2683.
[5] 秦凯,吴家丽,宋益多,等. 基于社会信任的协同过滤算法研究综述[J]. 智能计算机与应用 2015 5(4) 55-59.
[6] HUANG Z CHUNG W CHEN H. A graph model for ecommerce recommender systems[J]. Journal of the American Society for Information Science and Technology 2004 55(3):259-274.
[7] 张光卫,李德毅,李鹏,等. 基于云模型的协同过滤推荐算法[J]. 软件学报 2007 18(10):2403-2411.
[8] 王兆国,谢峰,关毅. 一种基于线性回归的新型推荐方法[J]. 智能计算机与应用,2017 7(4):1-5.
[9] 王明佳,韩景倜,韩松乔. 基于模糊聚类的协同过滤算法[J]. 计算机工程 2012 38(24):50-52.
[10]许鹏远. 多因素综合框架的协同过滤推荐算法[D]. 大连:大连理工大学 2017.
