基于PCIE总线的DMA控制器设计与实现
2018-05-23何广亮
何广亮
(中国空空导弹研究院,河南 洛阳 471000)
0 引言
在信号与信息处理领域,数据采集技术发挥着至关重要的作用,而高速数据传输技术是数据采集系统中的关键部分。随着信息处理技术的发展,传统的数据采集设备已经很难满足高带宽、大容量和高实时性的数据处理需求,数据的高速传输技术也成为制约数据采集系统性能的重要因素。
PCIE在高速数据采集和传输系统中具有显著的优势,本文设计实现了一种基于PCIE总线的DMA控制器,实现了FPGA板卡与PC之间的通信,满足了高速实时采集、传输数据的要求。
1 PCIE概述
1.1 PCIE简介
PCIE是PCI Express的简称,是计算机PCI总线的扩展接口。它沿用了现有的PCI通信标准及编程概念,是更快的串行通信总线。PCIE作为第三代I/O总线,比第一代总线(ISA/VISA/EISA 等)和第二代总线(PCI/AGP/PCI-X)具有更高的速率和更好的兼容性[1]。目前共有3个版本的PCIE规范,分别为1.0、2.0和3.0。1.0和2.0规范在物理层中使用8 B/10 B编码,而3.0规范使用128/130 B编码。1.0、2.0和3.0的单Lane峰值带宽分别为2.5 GT/s、5 GT/s和8 GT/s,实际的传输速率分别为2 GT/s、4 GT/s和8 GT/s。
1.2 PCIE总线的层次结构
PCIE总线采用分层结构,如图1所示。PCIE总线由物理层、数据链路层和事务层组成,各层又都分为发送模块和接收模块[2]。
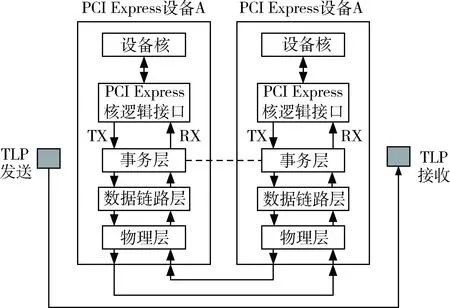
图1 PCIE总线的层次结构
在发送部分,首先在事务层形成事务层包(TLP),并把TLP储存在发送缓冲器中,等待向下层发送。这些TLP是根据来自设备核和应用程序的信息生成的;在数据链路层中,在TLP上添加一些附加信息,这些信息用来使对方在接收TLP时进行错误检查;在物理层,对TLP进行编码,然后从差分发送器发送出去[3]。
在设备的接收部分,物理层对接收的TLP进行译码,并将译码结果发往数据链路层;数据链路层对物理层发送来的TLP进行错误检查,若没有错误,则将该包发往事务层;事务层将TLP内信息转换为能由设备核和应用程序处理的表达形式,然后放入接收缓冲器[4]。
1.3 PCIE事务层数据包
TLP的基本格式如图2所示[5]。

图2 TLP的基本格式
完整的TLP由一个或多个TLP Prefix、TLP头部、Data Payload(数据有效载荷)和Digest组成。TLP头部是TLP最重要的标志,头部包含了TLP的总线事务类型、路由信息等一系列信息,其通用TLP头格式如图3所示。数据有效载荷是TLP携带的数据,最小为0,最大为1 024 DW。Digest值是基于头标、数据载荷字段计算出来的CRC。Digest是可选项,由TLP头决定是否需要Digest。

图3 通用TLP包头格式
Fmt和Type字段决定当前TLP使用的总线事务、TLP头部的长度、TLP是否包含数据[6]。TC字段表示流量类别;TD字段表示是否存在Digest;EP字段表示中毒数据。Attr字段表示属性位,位5为1表示灵活的顺序,为0表示紧凑的顺序;位4为1表示不侦测,为0表示侦测。Length字段表示数据有效负载的大小,以双字DW为单位,最小为0,最大为1 024 DW;First和Last DW BE字段分别表示数据有效负载的第一个和最后一个双字对应的字节是否有效。
2 DMA控制器实现方案
PCIE总线高速数据传输接口主要包括PCIE IP核和DMA控制模块。PCIE IP核直接在ISE中调用,用来实现PCIE的物理层和数据链路层。DMA模块主要实现了PCIE的事务层、中断机制和与上位机的通信。这两个模块之间的连接主要通过事务层之间的接口来完成。
2.1 Virtex-6 PCIE IP核
Xilinx公司提供了PCIE IP核(Virtex-6 FPGA Integrated Block for PCI Express)来解决PFGA与PC的通信问题,Virtex-6 FPGA 的PCIE嵌入式块是嵌入在ISE 中,通过调用ISE 中的CORE Generator 来使用的[7]。PCIE集成块的结构如图4所示,通过配置模块、使用和连接接口,可以通过该IP 核在系统中实现PCIE 通信接口。
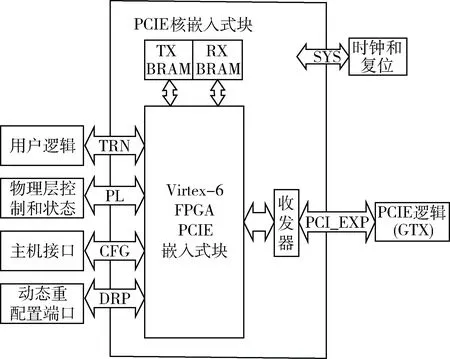
图4 PCIE集成块结构图
2.2 DMA控制器结构
DMA控制器结构框图如图5所示。
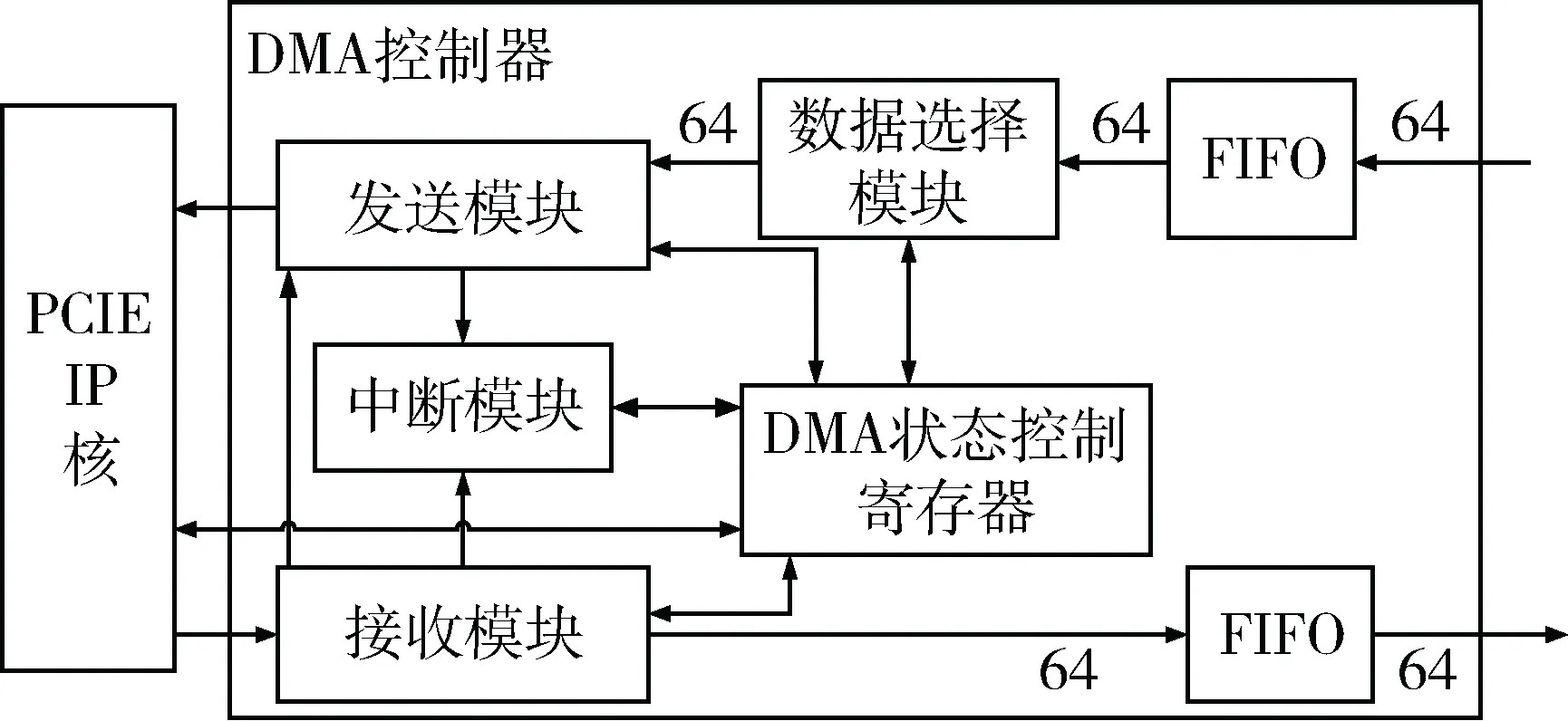
图5 DMA结构图
发送模块用于生成和发送事务层数据包,包括存储器读请求包(MRd)、存储器写请求包(MWr)和完成包(CplD)。该模块通过接收由其他模块传来的信号发送对应的TLP包。PCIE模块的事务接口发送相关信号到该模块上。
接收模块从IP核接收TLP数据包,可以接收完成(CplD)、存储器写(MWr)和存储器读(MRd)这3种类型的TLP包。接收模块接收到相应类型的TLP后,提取其中信息,发送给不同的模块。
DMA控制/状态寄存器(DMA Control/Status Register)用于主机系统通过控制FPGA内部的寄存器文件的设置来启动和停止端点到根复合体的DMA读写操作。包括一个控制寄存器以及若干个配置寄存器,配置寄存器有主机的目的地址、源地址信息,本地的目的地址、源地址信息,以及每次DMA的数据包长度等信息。
中断主要是通过一个32位的DMA中断寄存器来实现。在此32位中,共包含3个有效位:位1表示DDR3[8]缓存4 MB数据已满,位2表示DMA写完成,位3表示DMA读完成。
3 功能单元设计
3.1 发送模块
此模块主要完成TLP包的打包发送工作。PC端上位机首先发起DMA读写请求,PCIE 板卡在DMA状态寄存器读到这些信号后,主动发起DMA读写请求,这个过程需要与接收模块、中断模块和DMA控制状态寄存器的配合才能完成。发送状态机模块设计如图6所示。

图6 发送模块时序图
发送模块主要由14个状态机实现,如图7所示。下面对每个状态的含义和跳转条件进行说明。
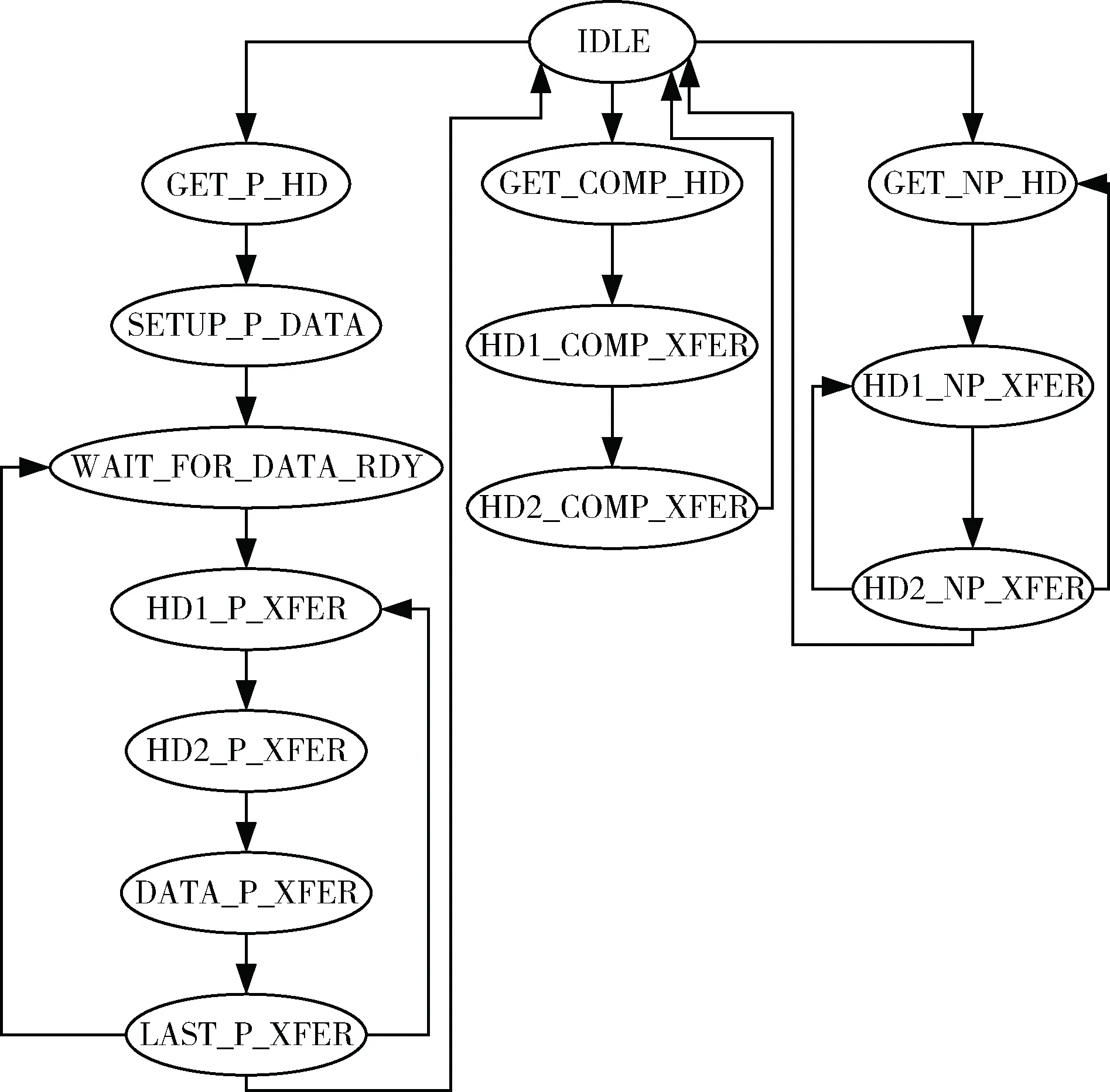
图7 发送模块状态机
IDLE:系统复位状态。
GET_P_HD:当存储器写请求头部生成并进入相应的FIFO时,进入此状态。无条件进入SETUP_P_DATA状态。
SETUP_P_DATA:向数据转换模块发出请求信号,若此时有数据则进入WAIT_FOR_DATA_RDY状态;无数据则停留在原状态。
WAIT_FOR_DATA_RDT:若数据准备好,进入HD1_P_XFER状态,否则停留在原状态。
HD1_P_XFER:从相应FIFO中读取DMA写请求TLP包头部前两个DW进行发送,进入HD2_P_XFER。
HD2_P_XFER:从相应FIFO中读取DMA写请求TLP包头部第三个DW,加上第一个DW数据进行发送,进入DATA_P_XFER状态。
DATA_P_XFER:将数据填入存储器写TLP进行发送。当还剩余一个周期的数据需要发送时,进入LAST_P_XFER状态。
LAST_P_XFER:若DMA写请求终止,则进入IDLE状态;若TLP中填充的字节数等于配置的TLP大小,则进入HD1_P_XFER状态;若TLP中填入的字节数小于配置的TLP大小,则进入WAIT_FOR_DATA_RDY状态。
GET_NP_HD:当存储器读请求头部生成并进入相应的FIFO时,进入此状态。无条件进入HD1_NP_XFER状态。
HD1_NP_XFER:从相应FIFO中读取存储器读请求TLP包头部前两个DW进行发送,进入HD2_NP_XFER状态。
HD2_NP_XFER:从相应FIFO中读取存储器读请求TLP包头部第三个DW,并加上32 bit数据进行发送。若发送存储器读请求的TLP个数等于DMA分块后的TLP个数,则进入IDLE状态;若发送存储器读请求的TLP个数小于DMA分块后的TLP个数,则进入HD1_NP_XFER状态。
GET_COMP_HD:当完成包头部生成并进入相应的FIFO时,进入此状态,无条件进入HD1_COMP_XFER。
HD1_COMP_XFER:从相应FIFO中读取完成TLP包头部前两个DW,进行发送,进入HD2_COMP_XFER状态。
HD2_COMP_XFER:从相应FIFO中读取完成TLP包头部第三个DW,并加上32 bit数据进行发送。然后进入IDLE状态。
3.2 接收模块
接收模块对接收到的TLP包进行解析,提取TLP包中的有效数据。接收时序如图8所示。

图8 接收模块时序图
接收模块主要由7个状态机实现,如图9所示。下面对各个状态含义与跳转条件进行简要说明。
IDLE:初始状态。当接收到数据第一个周期时,提取信息,判断此TLP包是何种类型的包,如果是存储器写请求则跳转到MWr状态;如果是存储器读请求则跳转到MRd状态;如果是带有数据的完成包,则跳转到CplD状态。
MWr:分析存储器写请求包的第二个周期数据,将其中的32 bit地址和32 bit数据提取出来,之后进入初始状态。
MRd:分析存储器读请求第一个周期数据,将其中的Attr、Request ID和Tag等字段信息发往发送模块,由发送模块组装完成包以回应此请求。之后进入GET_MRd_MSG状态。
GET_MRd_MSG:分析存储器读请求第二个周期数据,将其中32 bit地址提取出来进行缓存,然后进入初始状态。
CplD:将完成包第二个周期中32 bit数据提取出来,然后进入CplD_DATA状态。
CplD_DATA:提取完成包中的剩余数据,提取完毕后进入WAIT状态。
WAIT:由FPGA发起的存储器读请求PC端回应完毕,将相关信号置0,进入初始状态。
3.3 DMA 控制状态寄存器设计
在PCIE的BAR0空间映射着DMA寄存器,负责与 PC 进行数据传输。PCI 总线域的地址存放在BAR0 空间,内存地址到 PCI 总线地址的转换由根联合体 RC处理,PC操作BAR空间实际上是通过操作内存中BAR0对应的地址来完成的。在数据传输过程中,PC若想控制DMA传输的状态,只能通过读写BAR0空间来完成。在PC启动DMA之前,需要配置DMA 状态控制寄存器,包括使能DMA中断、使能DMA读写开始信号,填写DMA源地址、目的地址和DMA传输长度。DMA 启动后,通过读取dmacst寄存器查看 DMA 传输状态。然后等待中断,清除中断,转移数据,之后本次 DMA 请求结束。
3.4 中断设计
在FPGA逻辑端,中断主要是通过一个32位的DMA中断寄存器来实现的。中断设计流程图如图10所示。
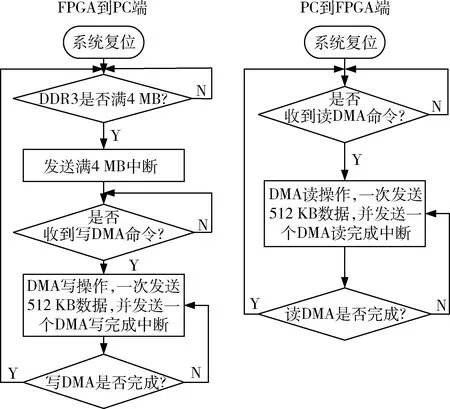
图10 中断模块流程图
中断描述:在发送数据时,一次写DMA完成4 MB数据的传送,当DDR3缓存4 MB数据时,就向PC端上位机发一个中断,PC端发起写DMA操作,FPGA端接收到此命令后,发起DMA写操作,每次DMA写操作完成512 KB数据的传送,并向PC端发送一个DMA写完成中断,相当于一次写DMA操作完成8次DMA写操作。接收数据时,PC端首先发起读DMA操作,FPGA端接收到此命令后,发起DMA读操作请求,PC端发送带数据的完成包来回应此请求,每次DMA读操作完成512 KB数据的接收,接收完后向PC端发送一个DMA读完成中断。
4 系统验证与测试
PCIE读写速率测试环境主要由存储服务器主机(PC)、阵列控制器和固态硬盘组成,如图11所示。
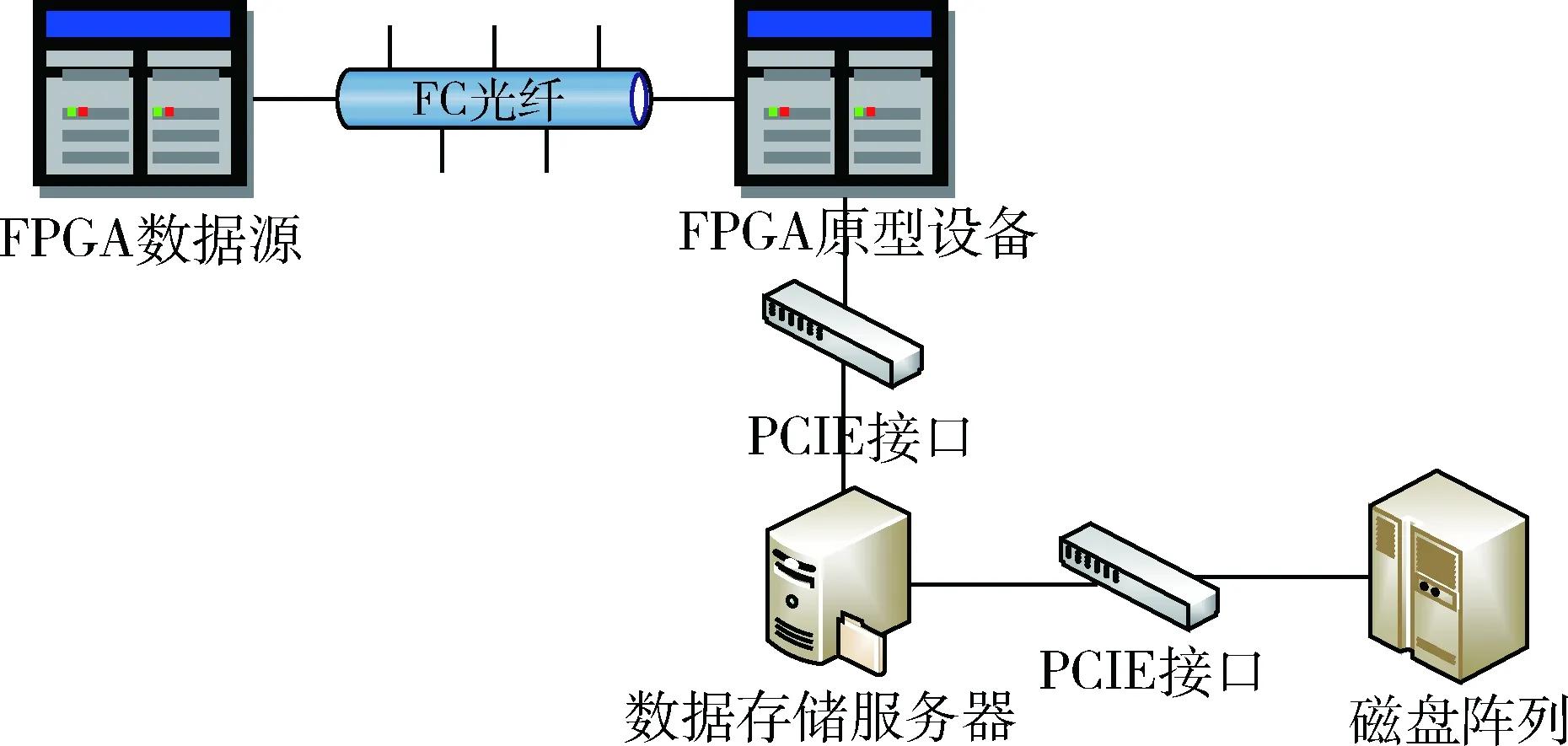
图11 测试环境组成
4.1 PCIE写速率测试
写操作DMA连续循环缓冲区大小为16 MB,每次DMA写操作传输大小为4 MB。测试在DMA写操作的基础上加上写磁盘阵列存储操作,单次操作数据量为4 MB,经PCIE的DMA写入存储服务器内存,再由内存写入磁盘阵列。操作计时由收到FPGA发起的通道数据FIFO满中断开始,直到4 MB数据全部写入磁盘后结束。操作时间采用计算CPU计数间隔精确计算,精度为微秒级。图12为测试部分结果,测试结果为由累计200次操作总时间换算得出的平均操作速率。
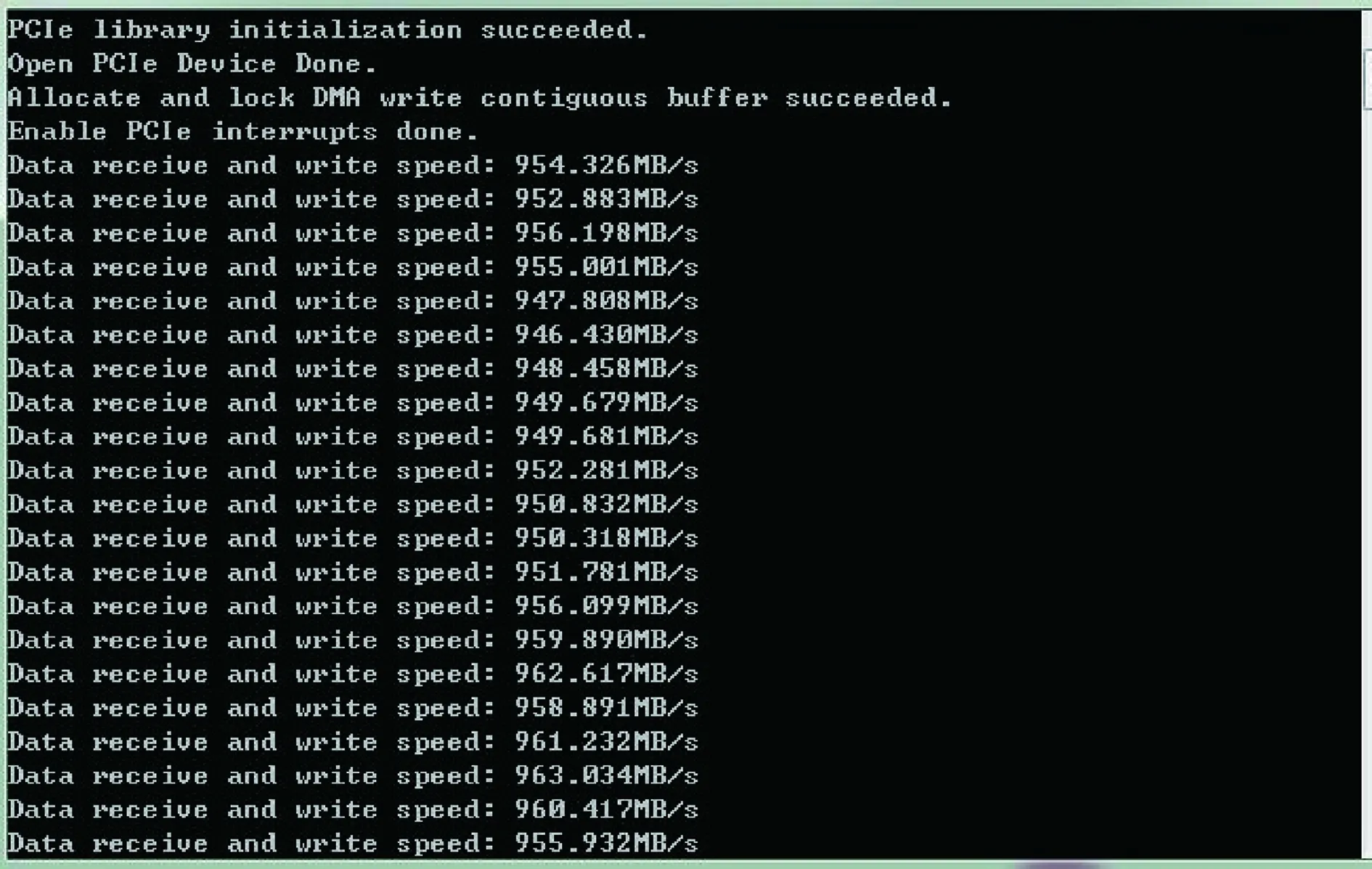
图12 DMA写速率测试
从图12可以看出,存储服务器存储操作的带宽在950 MB/s左右,约7.42 Gb/s。
4.2 PCIE读速率测试
此测试在读磁盘阵列的基础上加上DMA读操作,单次操作数据量为0.5 MB,经过磁盘阵列读入存储服务器内存,再由内存读入PCIE的DMA中,即FPGA中。操作计时由上位机发起读操作开始,直到0.5 MB数据全部进入FPGA内部后结束。部分测试结果如图13所示。
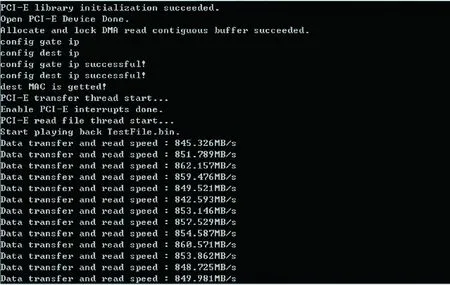
图13 DMA读速率测试
从图13可以看出,PCIE读操作的的带宽在850 MB/s左右,约6.8 Gb/s。
5 结论
本文设计的PCIE总线DMA控制器,与PC通信时收发速率均可达到6 Gb/s以上,满足了数据采集设备高带宽、大容量和高实时性的数据处理需求,具有一定的工程实践意义。
参考文献
[1] 张彪, 宋红军, 刘霖, 等. 基于PCIE接口的高速数据传输系统设计 [J]. 电子测量技术, 2015, 38(10): 113-117.
[2] 李木国, 黄影, 刘于之. 基于FPGA的PCIe总线接口的DMA传输设计 [J]. 计算机测量与控制, 2013, 21(1): 233-235,249.
[3] CRONE G, VOLPE D D, GORINI B, et al. The ATLAS readout system—performance with first data and perspective for the future[J]. Nuclear Instruments and Methods in Physics Research, 2010,623(1):534-536.
[4] DHAWAN S K. Introduction to PCI express-a new high speed serial data bus[C]. Nuclear Science Symposium Conference Record, IEEE,2005: 687-691.
[5] 张鹏泉,褚孝鹏,曹晓冬,等. 基于FPGA的PCIE总线DMA传输的实现[J]. 电子测试, 2016(21):4-6.
[6] 周立国, 梁淮宁, 谢冬冬, 等. 基于PCI Express总线的数据传输卡的设计与实现 [J]. 电子测量技术, 2007, 30(11): 28-31,39.
[7] 王薇. 基于FPGA的数据采集与处理系统研究[J].电子设计工程,2015(16):36-38.
[8] 潘一飞,余海. 基于FPGA的DDR3用户接口设计[J].电子制作,2013(15):9-11.
