基于优化的并行AlexNet人脸特征点检测算法*
2018-05-23陈东敏姚剑敏
陈东敏,姚剑敏
(福州大学 物理与信息工程学院,福建 福州 350002)
0 引言
随着虚拟现实增强技术的兴起,许多的研究项目和商业产品以实现人机交互为目的[1]。人脸特征点定位在人脸对齐、面部表情识别等方面具有很重要的意义。如何通过普通摄像头实现对人脸特征点的准确定位是本文研究的方向。
传统上,人脸关键点检测涉及图像处理、特征提取、主成分分析等方法(包括主动形状模型[2]和主动外观模型[3])以及后续发展出来的一些方法,比如基于限制局部模型的方法[4]、基于主动外观模型的方法[4]和基于回归的方法[5-7]等。
近年来,运用深度学习训练的方法逐渐火热起来。2013年,汤晓鸥课题组提出了利用级联深度卷积神经网络进行面部特征点定位[5],在当年达到了最先进的水平。本文借鉴三级联结构的第一级部分,提出了一种基于优化的并行AlexNet卷积神经网络模型,在模型输入图像处理上,采用3个子图像3个通道颜色的方法,进一步加大模型的独立性,并引入批归一化层,降低误差的同时减少模型的迭代次数,增加模型泛化能力。
1 AlexNet模型
AlexNet由Alex Krizhevsky等人设计并在2012年ILSVRC中获得冠军,该模型将物体分类错误率从此前的25.8%降低到16.4%,在当时达到最优水平。
AlexNet可以训练更大数据集以及更深的网络,后续的一些ZF-net、SPP-net、VGG等网络,都是在其基础上修改得到的。该模型分为8层,5个卷积层以及3个全连接层,网络的前端是原始像素点,最后端是图片的分类结果;卷积层中包含ReLU激活函数和局部响应归一化(LRN)处理,以及最大降采样层(Pool)。图1是AlexNet网络结构图。
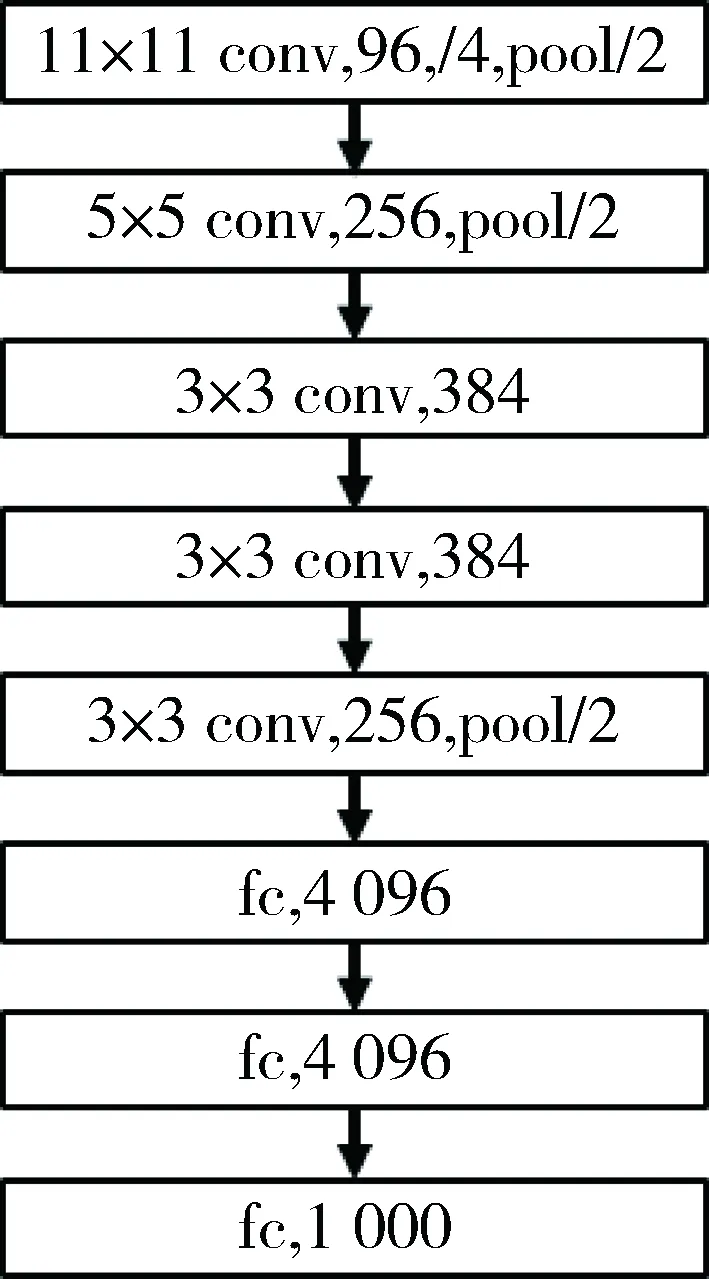
图1 AlexNet网络结构图
相比于传统的CNN,AlexNet模型结构有许多重要的改动,比如数据增强、Dropout、ReLU激活函数、LRN、重叠 Pooling、GPU并行。
1.1 数据增强
为了增强模型的鲁棒性,减少过拟合,增加模型的泛化能力,在对图像数据集的处理上,采用的方法是在保持数据标签不变的情况下增大数据集[7]。本文是关于图像的回归算法,采用了3种方法,只需很少的计算量就能达到数据扩充的目的。
(1)图像翻转
将图像进行水平翻转可以简单地扩充训练数据集至一倍。图2为图像水平翻转。

图2 图像水平翻转
(2)调整RGB像素值
在图像训练集中对图像的RGB像素集合采用主成分分析法处理。每个训练图像中,成倍增加已有的主成分,倍数为一个零均值、0.1标准差的高斯分布中提取的随机变量。得到图像中每一个像素值为:
(1)
增加以下项:
[p1,p2,p3][α1λ1,α2λ2,α3λ3]T
其中pi是像素值协方差矩阵第i个特征向量,λi是其对应特征向量的特征值,也是上文提到的随机变量。每个具体的训练图像的全部像素只提取一次。
(3)对图片进行随机平移
为了增强模型的鲁棒性,本文采用对原始图片进行随机平移。具体平移量如表1所示。其中平移量数值单位为像素点个数。

表1 图像偏移幅度
1.2 ReLU非线性
常见的神经网络激活函数有tanh(x)和sigmoid(x),当神经网络进行反向传播时会发生梯度消失。ReLU本质上是分段线性函数,其前向传播计算、反向传播都非常简单,无需太复杂的计算操作,因此ReLU函数可以训练更深的网络。ReLU函数右边恒等于零,使神经元一部分输出为零,起到稀疏网络的作用,类似Dropout层的作用,可以在一定程度上缓解过拟合[8]。图3是上述各激活函数模型。
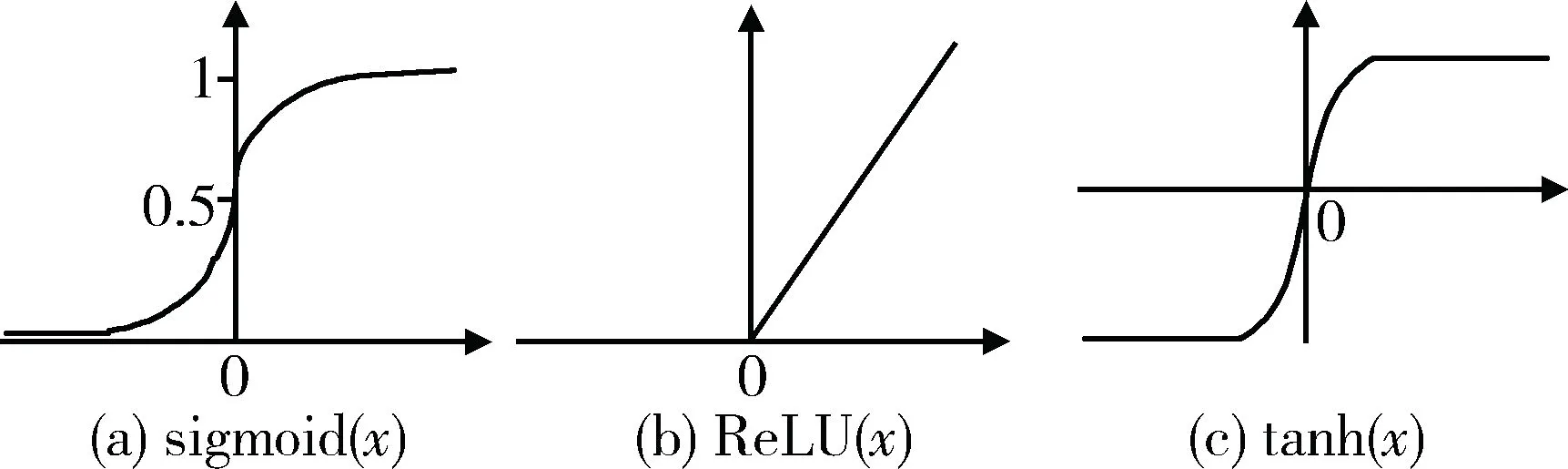
图3 激活函数
其中:
ReLU(x)=max(0,x)
tanh(x)=2sigmoid(x)-1
1.3 局部响应归一化(LRN)
ReLU所具有的线性及非线性性质使得不需要输入归一化来防止达到饱和,但是局部归一化方案可提高网络的泛化能力[9-11]。归一化公式为:
2 优化的AlexNet并行模型
2.1 并行结构
2013年汤晓鸥课题组将级联运用到了模型当中,利用级联深度卷积神经网络进行面部特征点定位。图4为级联系统结构图。
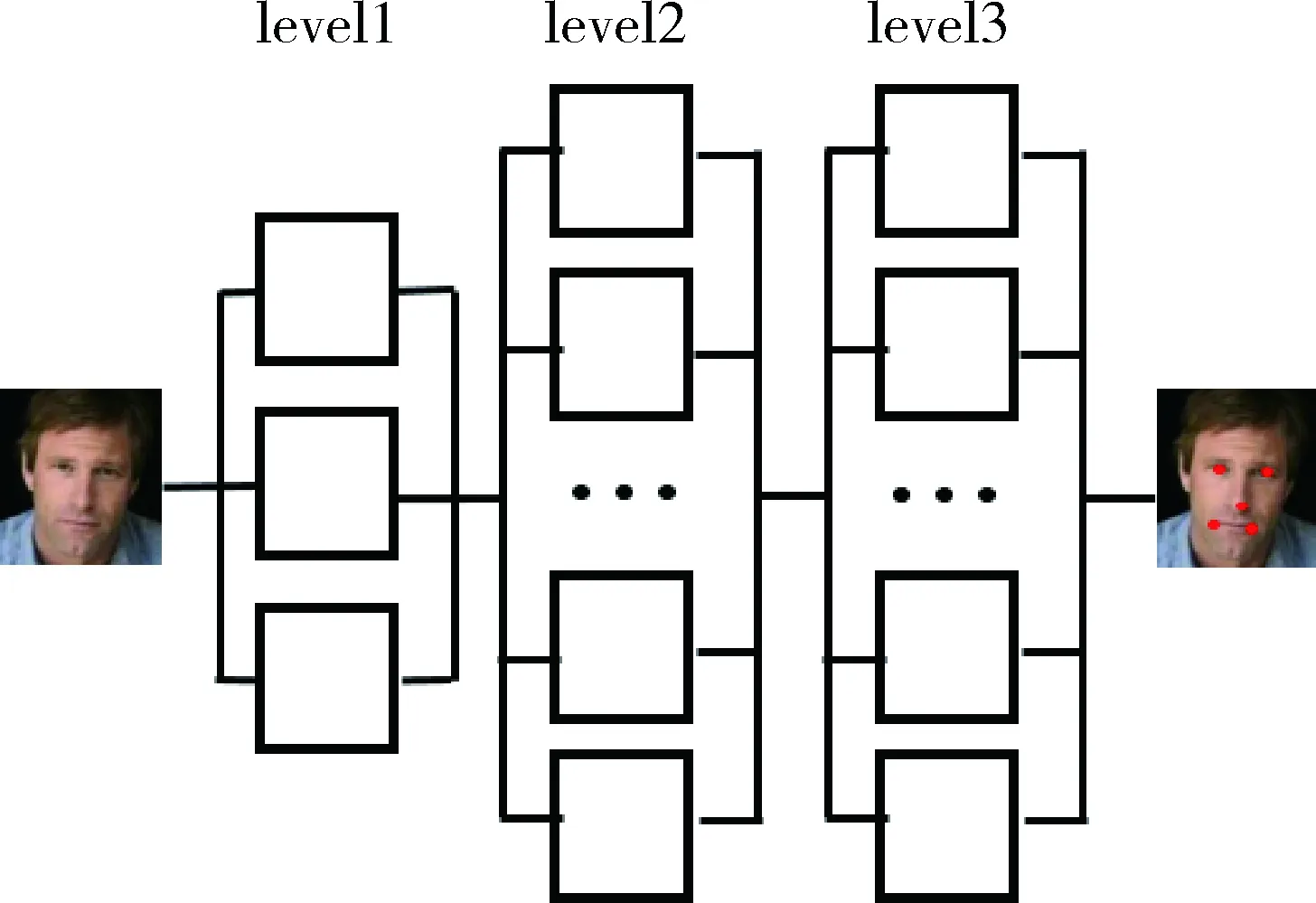
图4 级联系统结构图
该模型具有三级结构,第一级为粗定位,后面两级为精确定位。首先,采用灰度图像进行训练,经过第一级的结构,将训练的人脸图像分为互有重叠的3个子图像F1、EN1和NM1,3个子图像分别传送到3个互有差异的卷积神经网络模型进行训练,输出结果加权平均得到5个特征点的粗定位;接着经过第二级结构细定位,以上一级输出的5个特征点坐标为中心从人脸图像抠出5个适当大小的包含特征点的子图像传送到10个一样模型的卷积神经网络进行训练,将结果加权平均得到细定位;最后通过最后一级精确定位,做法同第二级,待模型收敛后,将结果加权平均得到最终的精确的人脸特征点坐标。
以上模型涉及卷积神经网络模型达23个,参数庞大,收敛慢,本文借鉴级联结构的第一级部分,提出了一种优化的AlexNet并行卷积神经网络算法。模型均采用AlexNet模型,在不增加网络层数的情况下通过并行结构能够增大模型预测的准确率,减少误差。图5为并行结构图,其中输入为原始图像,切分为互有重叠的3个子图像分别进入F1、F2、F3模型,输出3个互有重复的特征点坐标子集,加权平均得到最终的人脸特征点检测结果。
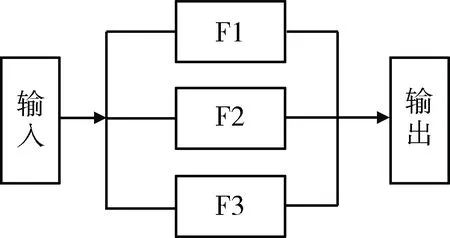
图5 并行结构图
2.2 优化的AlexNet
本文采用的卷积神经网络是基于AlexNet模型基础进行优化的,优化的AlexNet模型如图6所示,共有7层:4个卷积层,3个全连接层,模型的输出是5个坐标。其中conv表示卷积过程;Pool(z)是池化层,这里采用最大池化,4×4表示池化核大小;Batch Normalization (BN)是批归一化层。

图6 优化的AlexNet模型
与传统的AlexNet相比,优化的AlexNet去掉一层卷积层,加入了BN层,并且根据训练集调整网络模型参数。其中改动最大的是图像的输入处理,以及引入了批归一化层。
2.2.1图像的输入
本算法采用美国马萨诸塞大学公开的人脸数据集LFW(Labeled Faces in the Wild)。该数据集被广泛用于研究无约束的人脸识别问题。数据集包含13 466张包含人脸的图片和标签文档,标签文档储存着每一张图像的人脸位置坐标以及其5个特征点坐标,其中特征点为左、右眼中心,鼻尖,左、右嘴角的坐标。遵循交叉验证的方法,从LFW随机抽取9/10的人脸图片以及左右镜像共24 228张做训练集,余下1/10和左右镜像共2 704张做测试集。
原始图像进入F1、F2、F3之前会被切分成3个互有重叠部分的子图像,其中3个子图像分别具有以下特征:包含所有特征点的R通道图像,不包含嘴巴特征点的G通道图像,不包含眼睛特征点的B通道图像。3个模型训练目标特征点两两相交,将各自结果加权平均之后得出最终的人脸特征点坐标。图7为图像的输入切分。

图7 图像的输入
随着输入图片的切分,模型中的参数也随着调整。
2.2.2批归一化处理
在每次随机梯度下降时,通过mini-batch来对相应的激活值做规范化操作,使输出值各个维度的均值为0,方差为1。而最后的“scale and shift”操作是为了让因训练所需而“刻意”加入的BN能够最有可能还原最初的输入,即:
β(k)=E[x(k)]
从而保证整个网络的泛化能力。以下是批归一化的计算步骤:
输入:mini-batch 中xi的值:B={x1…xm},需要学习的参数:γ,β
输出:{yi=BNγ,β(xi)}
//mini-batch 均值
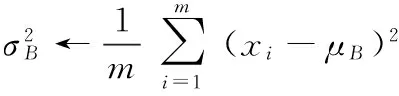
//mini-batch 方差
//归一化
//scale and shift
为了防止神经网络在训练中发生梯度消失,加入了批归一化层。批归一化层对网络层的输入值进行预处理,通过将隐藏层的输出数据进行归一化操作,使其服从标准的高斯分布,是一种更为有效的局部归一化处理。
3 实验结果及分析
实验环境为:Windows 10的64位操作系统,AMD显卡型号为HD7470M,4 GB内存,TensorFlow 1.2,Python 3.5以及Python-OpenCV库。
TensorBoard是TensorFlow的一个可视化工具。通过TensorBoard可以随时观看训练中正确率及误差收敛情况曲线图以及神经网络模型训练的流程图,可以查看任意隐藏层的特征图。本文实验结果主要依靠TensorBoard来得出结论。
3.1 并行结构与传统结构的对比实验
输入图像尺寸为30×30,模型有无并行结构性能比较如图8、图9所示。图8为训练误差,并行结构模型为2.842 9e-3,耗时17 h 2 min 15 s;无并行模型为6.047 1e-3,耗时为7 h 32 min 12 s。
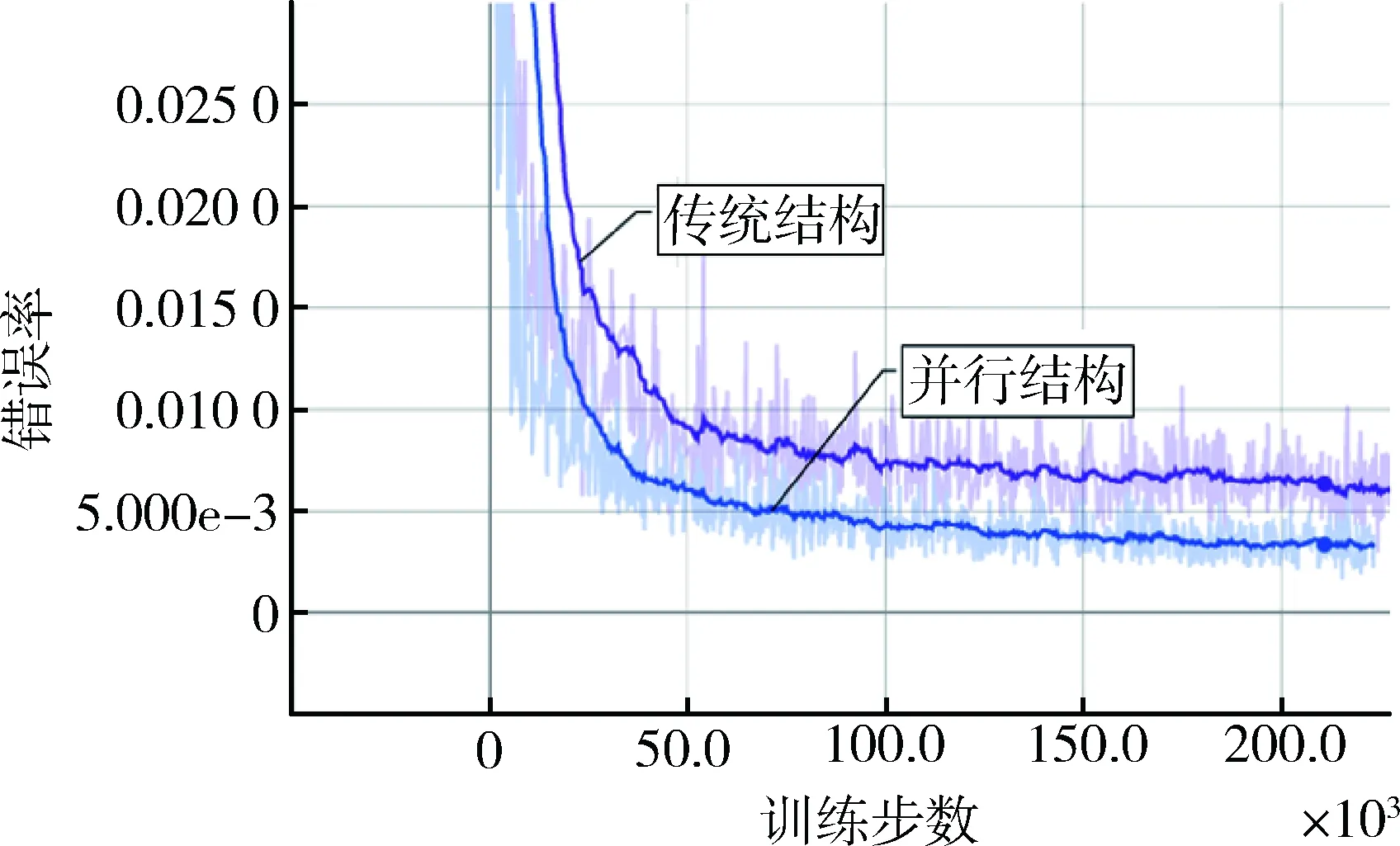
图8 训练误差
图9为正确率。并行结构模型先于传统结构达到收敛。
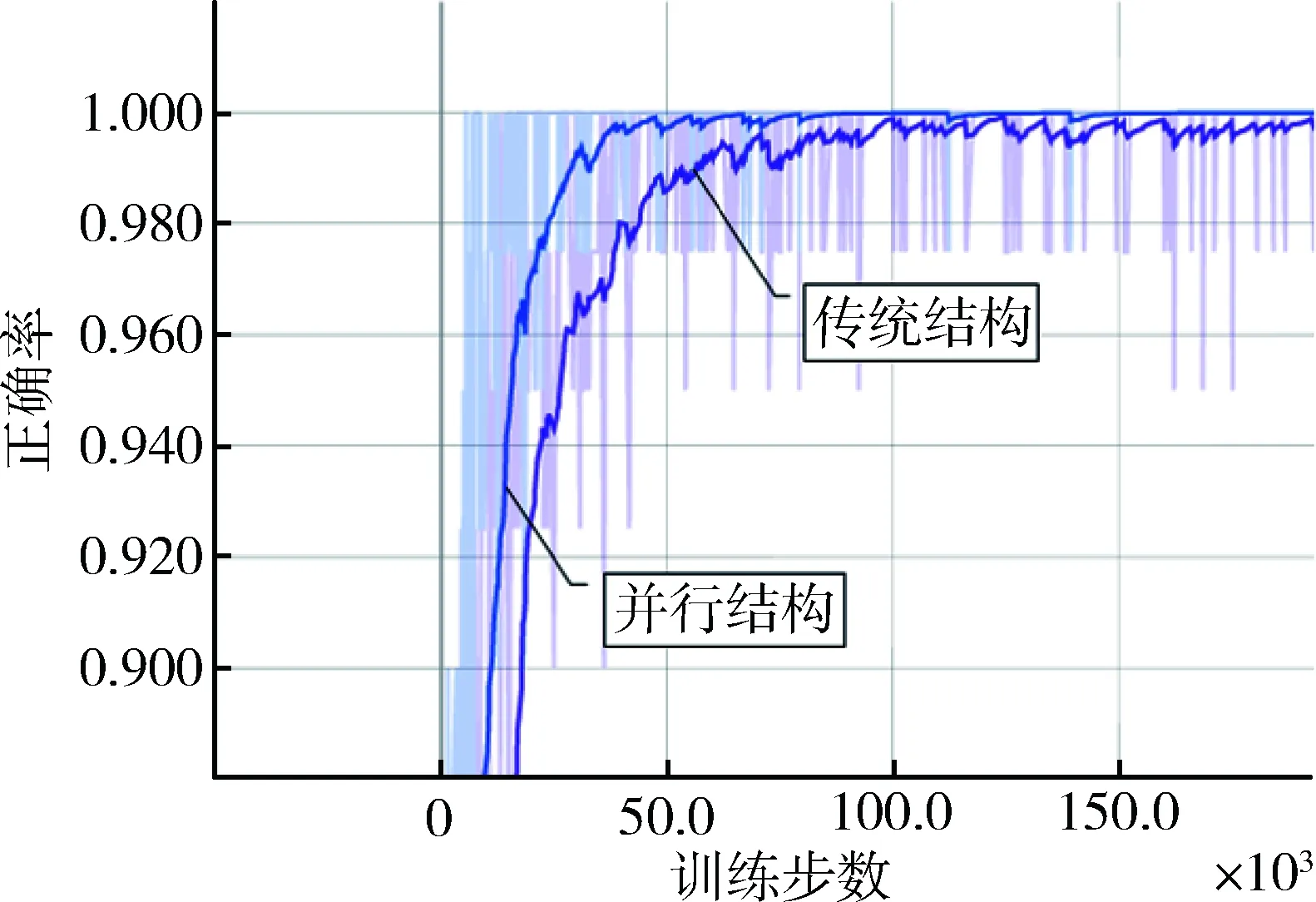
图9 正确率
综上,并行结构模型误差更低,达到收敛更快,鲁棒性更好,但在训练耗时上并不占优,由于同时对3个神经网络模型进行训练,训练时间也更长。
3.2 优化的AlexNet并行结构性能分析
3.2.1图像的优化对比
模型进行图像优化处理后对比汤晓鸥并行结构,图10所示为正确率对比,图11为误差对比。

图10 正确率对比

图11 误差对比
误差具体数值对比如表2所示。经过图像优化的算法模型比原始模型误差降低5.08%。

表2 误差数值对比
3.2.2引入批归一化处理层
引入批归一化层的对比如图12、图13所示。

图12 正确率对比

图13 误差率对比
误差具体数值如表3所示。加入BN层的算法模型比原始模型误差降低34.21%。
将图像优化和批归一化层同时作用于模型中,结果如图14、图15所示。

表3 误差对比

图14 正确率对比

图15 误差率对比
误差数值对比如表4所示。图像优化+BN层的算法模型比汤晓鸥模型第一级模型误差下降44.57%。

表4 误差对比
4 结论
本文构建了基于优化的AlexNet并行卷积神经网络模型对人脸图像进行特征点定位,将输入图像切分为3个互有重叠的人脸子图像,3个子图像分别连接3个不同的卷积神经网络进行训练,并且子图像分别取原图像的一个颜色通道,进一步增加各个模型的差异性,待模型收敛后,将3个网络输出的特征点坐标加权平均,得出最终的人脸特征点坐标。并在网络中加入批归一化层减少迭代次数,加快收敛,并且使得结果误差减小。
在LFW数据集上实验结果表明,并行神经网络模型比单层神经网络正确率高,误差小;基于优化的AlexNet并行神经网络比没有优化的并行神经网络的迭代速度更快,误差降低44.57%。在预测上,基于优化的并行模型预测结果均优于汤晓鸥级联模型第一级部分。故而,本文所使用的优化的并行模型算法用于人脸特征点定位具有比汤晓鸥级联第一级卷积神经网络更好的鲁棒性和准确性。下一步拟对基于神经网络的人脸检测算法进行研究。
参考文献
[1] ZHANG C, ZHANG Z. A survey of recent advances in face detection[R]. Technical Report of Microsoft Research, 2010.
[2] COOTES T F,COOPER D,TAYLOR C J, et al. Active shape models-their training and application[J].Computer Vision and Image Understanding,1995,61(1):38-59.
[3] COOTES T F,EDWARDS G J.TAYLOR C J. Active appearance models[C] // Proceedings of the European Confidence on Computer Vision.Berlin:Springer,1998:484-498.
[4] SARAGIH J M,LUCEY S,COHN J. Face alignment through subspace constrained mean-shifts[C] // Proceedings of the IEEE International Conference on Computer Vision. IEEE,2009:1034-1041.
[5] SUN Y, WANG X, TANG X. Deep convolutional network cascade for facial point detection[C]. 2013 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE,2013:3476-3483.
[6] Dong Yuan, Wu Yue. Adaptive cascade deep convolutional neural networks for face alignment[J]. Computer Standards & Interfaces,2015, 42:105-112.
[7] LIU X. Discriminative face alignment[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2009,31(11):1941-1954.
[8] Cao Xudong, Wei Yichen, Wen Fang, et al. Face alignment by explicit shape regression[J]. International Journal of Computer Vision,2014,107(2):177-190.
[9] LAUER F, SUEN C Y, BLOCH G. A trainable feature extractor for handwritten digit recognition[J]. Pattern Recognition,2007,40(6):1816-1824.
[10] SAINATH T N, MOHAMED A R, KINGSBURY B, et al. Deep convolutional neural networks for LVCSRA[C] // Proceedings of IEEE International Conference on Coustics, Speech and Signal Processing, 2013:8614-8618.
[11] 赵志宏,杨绍普,马增强. 基于卷积神经网络LeNet-5的车牌字符识别的研究[J]. 系统仿真学报, 2010,22(3):638-641.
[12] Fan Jialue, Xu Wei, Wu Ying, et al. Human tracking using convolutional neural networks[J]. IEEE Transactions on Neural Networks,2010,20(10):1610-1623.
