基于选择性集成ARMA组合模型的零售业销量预测
2018-05-23,,,
,,,
(1.湖南大学 信息科学与工程学院,长沙 410082; 2.快乐购股份有限公司,长沙 410003)
0 引言
全球化经济时代企业竞争日益强烈,需要利用有价值的商业数据在竞争中取得优势地位。预测商品的销量有利于提高零售企业自身的库存周转率和运行效率[1]。为此,国内外学者们提出了多种销量预测模型并结合具体实例进行了研究[2]。商品的销量随着时间不断变化,将销量看成是时序数据,可以通过时序挖掘相关方法对其进行预测研究。常用的时序分析模型有灰度模型[3]、马尔可夫模型[4]、自回归条件异方差模型[5]、贝叶斯向量自回归模型等[6],其中ARMA模型应用最广泛[7]。ARMA模型通过抽取时序数据内部的规律用于时序的周期预测和趋势分析,现已广泛应用于市场销售额预测、消费模式变迁等长期追踪资料的研究[8]。传统的ARMA模型是线性回归模型,只能捕捉平稳时序中的线性模式,但是商品销量的变化是受多种因素影响的,在其变化过程中同时存在非平稳非线性变化模式,因此,单一建立ARMA模型无法准确描述商品销量的变化趋势。为了克服传统时序线性模型预测精度低的问题,多种非线性回归预测方法被提出,其中表现较好的有SVR方法[9]以及ELM方法[10]。从理论上说,构建非线性模型能以无限精度拟合原始序列,但是需要大量的训练样本,并且容易陷入过拟合。因此,将传统的线性模型与智能非线性方法整合预测商品销量是有必要的,已有许多研究表明,通过整合不同的模型能显著提升预测性能。Yan和 Ma认为,ARIMA(Auto-Regressive Integrated Moving Average)与径向基函数网络(RBFN)的异构组合模型性能要优于ARIMA和RBFN自身,并在月降雨量预测中得到验证[11]。Babu和Reddy[12]使用ARIMA滤波器探索了自然种类的波动情况,并将人工神经网络(ANN)模型进行了适当的应用。Bangzhuzhu[13]提出了一种新颖的异构ARIMA和最小二乘支持向量机(LLSVM)方法,用于预测碳价格的波动情况;Wang等人[14]提出一种异构人工神经网络和支持向量机的模型用于地表PM10和SO2日浓度预测。
针对传统的时序模型无法捕捉商品销量中的非平稳和非线性特征,论文提出一种将时序线性回归模型与智能非线性回归方法组合的预测模型。首先利用ARMA模型识别出商品销量数据中的线性成分,再对其残差中的非线性成分分别采用SVR和ELM方法进行预测,两部分组合后得到最终预测结果。由于ARMA模型存在平稳性假定且定阶过程复杂、随机性强,论文提出一种选择性集成多个差异ARMA模型的定阶方法。经过某电商平台真实销售数据验证,论文提出的选择性集成ARMA定阶方法定阶更准确,改善了ARMA模型在平稳及非平稳时序下的预测效果。组合方法得到的销量预测结果相比仅采用线性平稳时序模型更符合实际,稳定性更好,因而验证了提出的组合模型具有一定的参考价值。
1 销量影响因素及组合预测过程
通过分析消费者的购买行为,发现诸多商品之间的销量变化是相互影响的,不同商品之间存在着竞争和合作关系[15]。某一商品的销量受其同类型商品销量的影响、关联商品销量的影响以及商家营销推广活动的影响。从内在影响因素映到外在表现,销量变化呈现出一定的发展模式和潜在规律。通过挖掘历史销量数据中潜在的规则和模式,建立数学模型对其进行描述,可以达到预测销量未来走势的目的。
根据销量数据的时序特征,论文采用ARMA模型对其中的线性因素、季节性周期性规律、随机因素进行预测。对除此之外的可能存在的突发因素及非线性变化部分,仅基于统计时序模型来拟合和预测会产生较大的非线性误差,故将影响商品销量变化过程看成是平稳随机过程以及非平稳非线性噪音的叠加。先通过ARMA模型识别出销量数据中的线性成分,然后采用不同的非线性回归预测方法对残差数据作出预测并将预测结果补偿给ARMA模型。其误差补偿示意图见图1。

图1 商品时序预测误差补偿示意图
如图1所示,本文先根据历史销量数据建立ARMA模型。假设观测数据为一维,当前时间为t,总采样时间为N,则建模后依次得到Ut+1,Ut+2,……UN个初步预测值。将初步预测值与真实值相减得到ARMA模型的非线性残差。通过滑动窗口法获得前d维销量数据作为SVR和ELM方法的输入,得到t+1,t+2,……,N时刻的误差预测值Et+1,Et+2,……,EN,最后将初步预测值和误差预测值叠加得到商品销量的最终预测值。具体流程见图2。
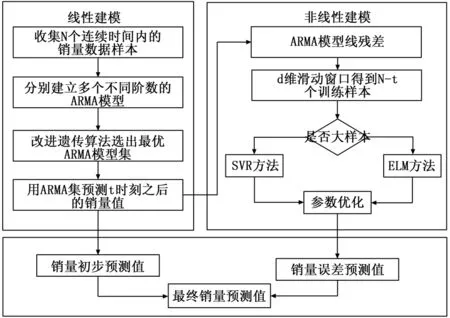
图2 组合方法建模流程
2 非线性误差补偿模型
2.1 ARMA模型
ARMA模型是迄今最常用的拟合平稳时间序列的线性回归模型,它由自回归模型AR(p)和移动平均模型MA(q)组合而成,分别反映系统对历史数据和随机噪音的依赖关系。ARMA(p,q)的数学模型一般表示为:
(1)
其中:▽dxt=(1-B)d是差分运算,用于把数据处理成平稳时序,序列{εt}是白噪声序列,B为滞后算子,Bnxt=xt-n。ARMA模型经过多个参数的试算,以及反复模型评定,最终得到最优阶数p,q。
2.2 选择性集成ARMA模型
ARMA模型应用的关键是确定模型的自回归阶数p和移动平均阶数q,而往往在实际应用时无法准确定阶,造成模型的准确率下降。本文提出了一个基于模型编码的选择性集成ARMA模型定阶的新方法,该方法不直接对ARMA模型的阶数求解,而是通过集成多个ARMA模型作为基学习器,对所有基学习器二进制编码,然后利用遗优化算法[16]选择出最优学习器组合。选择性集成方法通过选择部分精度较高、多样性大的个体学习器,能获得比采用全部学习器更好的性能,周志华等人[17]最先从理论上证明了选择性集成的有效性。
选择性集成ARMA模型过程如下:
1)设定p,q初始解空间:阶数p、q的解空间表示最优阶数可能存在的范围,假设p的解空间为(0,n),q的解空间是(0,m),则一共有(n+1)*(m+1)个ARMA(p,q)模型参与集成。
2)集成编码方法:采用二进制模型权重编码方法,即对每个模型的权重进行二进制编码,权重为1表示选中该ARMA模型参与集成,权重为0表示未选择该ARMA模型。
3)模型预剪枝:如果n与m的值过大,遗传编码长度过长,变异的多样性会受到抑制不利于产生最优解。因此,在用遗传算法寻优之前,需要预先剔除模型无法收敛的p、q组合,以提高算法获取最优解的能力。
4)遗传算法寻优过程:遗传算法解的构成为:
W(t)={ω1(t),ω2(t),...,ωD(t)}
(2)
表示初始种群中某个染色体在t次迭代后的基因序列,D表示参与集成的ARMA个数,ωj表示每个ARMA模型权重,初始种群权重的设置如下:
(3)
其中:rand( )是随机函数。为了选出泛化能力强的ARMA模型组合,适应度函数选择均方根误差函数的倒数。均方根误差越小,适应度越大,被遗传的概率也就越大,这与遗传算法的规律相符。故对于一个特定的ARMA集合i,适应度函数可描述为:
(4)
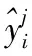
为了产生验证集Lval用于集成选择,采用滑动窗口法对时序数据进行标准预处理,每次滑动一个窗口以产生一个验证样本。ARMA模型的输入输出映射函数为:
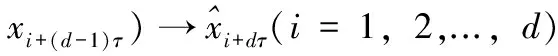
(5)
其中:τ为延迟时间,论文设为1;d是滑动窗口的维数。
2.3 组合模型预测过程
组合模型ARMA-SVR、ARMA-ELM预测过程如下。
步骤一:数据准备与ARMA建模。将商品的销量数据以周为周期分布构建时间序列,设定阶数p,q解空间大小,根据解空间构建多个不同阶数的ARMA模型进行集成,然后利用遗传优化算法选出最优ARMA模型集。用该ARMA模型集对商品未来销量进行预测,真实值和预测值在t时刻的残差为:
(9)

(10)
3 实例预测分析
收集某电商平台2011年1月1日到2012年12月28日期间某品牌手机销量数据、饼干销量数据作为实例研究对象。通过分析商品的货道设计等实际情况,商品的备货通常不宜过于频繁,因此本文旨在预测未来一周内的商品总销量。将数据以周为单位进行预处理后,得到商品销量曲线图,如图3所示。
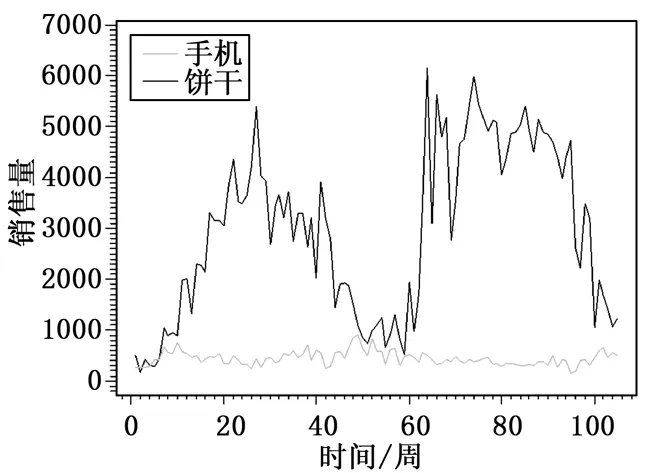
图3 商品销量曲线图
3.1 选择性集成模型预测结果
利用Eviews工具对两个序列进行单位根检验以确定序列是否平稳,检验结果见表1。通过检验结果可知,手机销量序列数据具有很好的平稳性,饼干销量序列数据非平稳。
将非平稳序列进行差分运算直至平稳后,再根据AIC定阶准则对序列反复试算,最后得出手机序列最优模型为ARMA(1,1),饼干序列最优模型为ARMA(0,1)(此处统称为ARMA-1)。分别采用ARMA-1、选择性集成ARMA模型(简称为ARMA-2)对两组序列的后45周数据进行预测,得到残差序列,如图4所示。
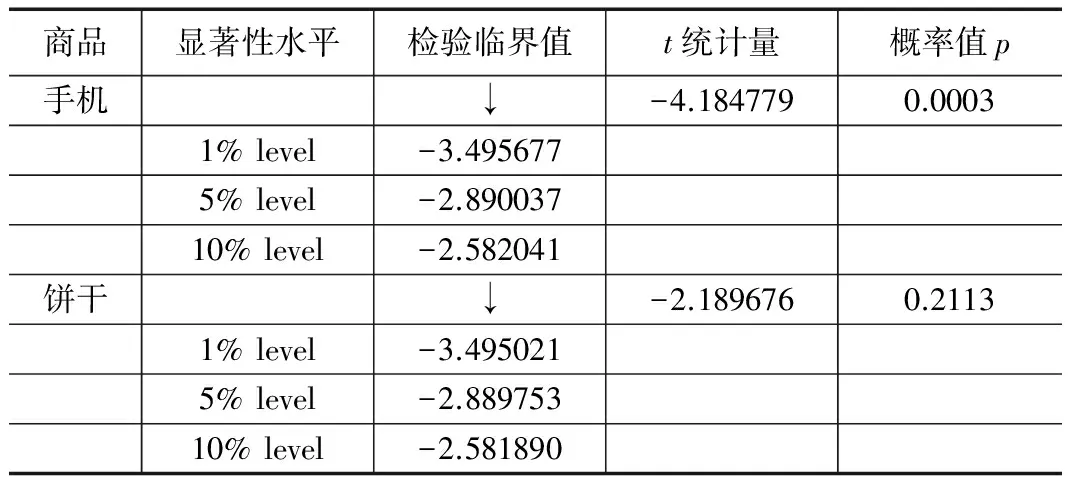
表1 序列单位根检验

图4 两类商品的残差序列
根据图4可知,ARMA-2降低了ARMA模型的平稳性假定条件,简化了模型的定阶过程。选择性集成方法通过集成了部分差异性大的ARMA模型作为组合学习器,在平稳和非平稳序列上的预测结果都更接近真实值。
3.2 组合模型预测结果


图5 三类模型的销量预测值
论文分别采用MAE(Mean Absolute Error,平均绝对误差)、RMSE(Root Mean Squares Error,均方根误差)和MAPE(Mean Absolute Percentage Error,平均绝对百分误差)三个性能指标来度量每个模型的预测误差。由预测结果可以看出,ARMA-2的MAPE在平稳时序上比ARMA-1模型提高了23.58%。在非平稳时序上提高了41.28%。组合模型中ARMA-SVR的预测精度分别在ARMA-2的基础上提高了68.86%(平稳)和45.18%(非平稳);ARMA-ELM的预测精度分别提高了64.47%(平稳)和14.90%(非平稳),这也应证了ARMA模型不能识别销量数据中非线性影响因素的假设。对比两种组合方法,ARMA-SVR在小样本、非平稳时序下预测准确度达到92.62%,对比ARMA-ELM精度更高、稳定性更好。
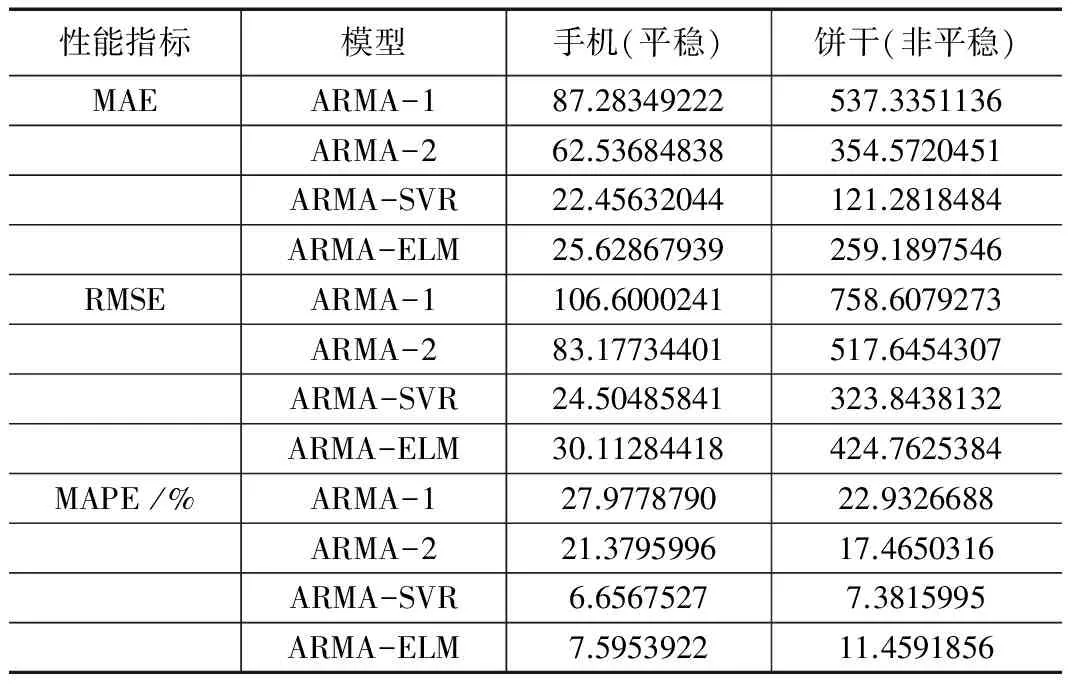
表2 模型预测效果比较
4 结束语
短期销量预测对现代零售企业采购和库存具有很大战略指导价值。通过分析零售商品销售趋势,企业能更好地把握消费者的未来消费走向,有利于企业制定有效的市场营销策略。论文根据当前ARMA模型定阶准则和方法的不足,提出了选择性集成的定阶方法,将定阶过程自动化,为线性平稳时序数据的分析提供了一种新思路。针对ARMA模型只能捕捉商品销量中的线性及平稳因素的特点,论文提出了将ARMA模型与智能非线性回归模型组合的预测方法,引入非线性预测方法中表现较好的SVR方法和ELM方法对残差当中的非线性、非平稳因素进行预测并补偿。实验证明,选择性集成ARMA方法定阶更准确,有效改善ARMA模型在非平稳时序上的预测效果,组合模型得到的销量预测结果相比仅采用线性平稳时序模型更符合实际,稳定性更好。商品销量受外界因素的影响较大,收集完整影响因素数据存在一定困难,论文仅对销量历史数据进行了分析,继续研究中需进一步整理较完整的销售数据,不断完善预测模型,以期达到预期的效果。
参考文献:
[1] 何 伟,徐福缘. 需求依赖库存且短缺量部分拖后的促销商品库存模型[J]. 计算机应用,2013,33(10):2950-2953.
[2] Kanko Y, Yada K. A Deep Learning Approach for the Prediction of Retail Store Sales[A]. IEEE 16th International Conference on Data Mining Workshops (ICDMW)[C]. Barcelona, 2016, 531-537.
[3] 何 斌,蒙 清. 灰色预测模型扩广方法研究[J]. 系统工程理论与实,2002(9):137-140.
[4] Schoof JT,Pryor SC. On the proper order of Markov chain model for daily precipitation occurence in the contiguous United States [J]. Journal of applied meteorology and climatology,2008, 47(9): 2477-2786.
[5] Engle R F. Autoregressive conditional heteroskedasticity with estimate of the variance of United Kingdom infation[J]. Econometrica, 1982(50):987-1007.
[6] 樊重俊. 贝叶斯向量自回归分析方法及其应用[J]. 数理统计与管理,2010,29(6):1060-1066.
[7] Box G E P, Jenkins G N, Reinsel G C著.时间序列分析预测与控制[M].顾岚主译.中国统计出版社,1997:51-58.
[8] Esling P,Agon C. Time-series Data Mining [J]. ACM Computional Survey,2012, 45(1):1-34.
[9] Chang C C, Lin C J. Training v-Support Vector Regression: Theory and Algorithms[J].Journal of Neural Computation,2002, 14(8):1959-1977.
[10] Huang GB,Zhu QY,Siew CK. Extreme learning machine: theory and applications[J]. Neurocomputing,2006,70(1-3):489-501.
[11] Qiao Yan. Application of integrated ARIMA and RBF network for groundwater level forecasting[J]. Forecasting Environmental Earth Sciences[J].2016,75(5):1-13.
[12] Babu CN, Reddy BE. A moving-average filter based hybrid ARIMA-ANN model for forecasting time series data[J]. Appl. Soft Comput ,2014,23:27-38.
[13] Bang Zhuzhu,Wei Yiming. Carbon price forecasting with a novel hybrid ARIMA and least squares support vector machines methodology[J].Omega,2013,41(3):517-524.
[14] Wang P,Liu Y,Qinz ET.A novel hybrid forecasting model for PM10and SO2daily concentrations[J].Total Environ Sci, 2015, 505, 1202-1212.
[15] 何周舟. 基于时序数据的结构学习与模式预测联合优化算法研究[D].杭州:浙江大学,2016.
[16] Piotr Faliszewski,Jakub Sawicki,Robert Schaefer, et al. Multiwinner Voting in Genetic Algorithms[J].IEEE Intelligent Systems,2017,32(1):40-48.
[17] Zhou ZH, Wu jx,Tang W. Emsembling neural networks:Many could be better than all[J]. Artificial Intelligence, 2002, 137 (1-2): 239-263.
