基于概率模型的冬小麦白粉病监测研究*
2018-05-22刘林毅黄文江董莹莹杜小平马慧琴
刘林毅,黄文江,董莹莹,杜小平,马慧琴,3
(1. 中国科学院遥感与数字地球研究所,数字地球重点实验室,北京100094;2. 中国科学院大学,北京100049;3. 南京信息工程大学,应用气象学院,气象灾害预报预警与评估协同创新中心,南京210044)
0 引言
近年来,随着气候变化的影响,我国小麦白粉病的发生与危害日趋严重[1]。据统计,白粉病发病后可使小麦减产10%~20%[2],严重时可达40%~60%[3]。1980年以前,全国小麦白粉病发病面积在100万hm2以下,1989年首次突破600万hm2。2000年以来,中国小麦白粉病的发生面积一直维持在600万hm2左右,广泛的发生区域使得白粉病严重影响我国的粮食安全。因此对于小麦白粉病的监测一直是众多学者研究的热点。
我国小麦病害的监测主要基于传统经验模型,这种方法多在“点”上开展工作,且依赖人工田间调查,不但费时费力、效率低下,而且无法对大范围小麦种植区进行有效的病害监测。具有快速、实时、大面积、无破坏等特点的对地观测技术的出现,无疑为区域小麦病害监测提供了新的思路和方法[4]。目前区域尺度的小麦白粉病监测主要基于统计分析和模式识别等数据挖掘算法解析卫星影像,构建病害识别、区分和严重度反演模型。如Yuan等[5]基于Worldview-2和Landsat-8卫星影像数据,以绿度归一化植被指数(green normalized difference vegetation index,GNDVI)、红边可见光大气阻抗指数(visible atmospheric resistant index,VARIred-edge)、Greenness和Wetness为 特 征 因子,通过Fisher线性判别分析(Fisher linear discriminant analysis,FLDA)构建了小麦白粉病和蚜虫的监测模型,监测精度达82%。Zhang等[6]基于北京市郊区白粉病实地调查数据,利用多时相HJ-CCD遥感影像,通过马氏距离(mahalanobis distance,MD)、最大似然法(maximum likelihood classifier,MLC)、偏最小二乘回归(partial least square regression,PLSR)、混合调制匹配滤波(mixture tuned matched filtering,MTMF)构建了四种白粉病监测模型,并将PLSR模型和MTMF模型进行了融合,监测精度达到了77.78%。Yuan等[7]基于SPOT-6影像和光谱角制图(spectral angle mapping,SAM)算法提出了结合地面高光谱和多光谱影像的小麦白粉病监测方法,经验证精度可达78%。上述研究所构建的白粉病监测模型大多注重利用影像单波段信息和植被指数对病害进行识别和分级监测,对研究区生境信息与白粉病发生的关系研究甚少。
近年来,卫星影像空间分辨率和时间分辨率的提高以及遥感数据分析处理技术的发展使得空间信息的精细化提取和应用成为可能。同时,精准农业的出现要求农业系统信息能够被详细精确的表达[8]。一些学者认为传统的分类监测方法使得归于同一类别的影像像元丢失了自身特有的属性信息,不利用精细空间信息的表达,并尝试通过展现影像各个像元的独特性来表达地理现象的空间渐变特征,进而精确表达研究目标的空间信息。如Zhu等[9]通过整理专家经验构建了滑坡预测模型,预测结果精确描述了开县和三峡地区滑坡易发性的空间分布,通过Z检验证明了该模型有较高的预测精度且在不同区域都能得到较好的预测结果。Qin等[10]通过构建相似性模型来表达嫩江地区的坡位分布信息,结果表明该方法有较高的分类精度且分类结果能够很好地保留坡位分布的空间连续性。杨琳等[11]利用模糊c均值聚类(fuzzy c-means clustering,FCM)获取土壤—环境间的关系并基于知识景观推理(soil land inference model,SoLIM)模型进行黑龙江鹤山农场的土壤类型制图,经验证土壤类型图的总体精度达72%且能很好地表达土壤类型分布的空间连续性。
常规的病害监测研究注重建立和改进病害识别和区分算法,且通常基于验证点集对监测结果进行验证,对监测结果误差空间分布的研究较少[5-7]。概率模型(probabilistic model)通常被用来描述随机因素对结果的不确定性影响[12],基于实测数据构建的概率模型通常更贴近实际,虽然概率模型算法种类较多,但是计算方便、灵活,能够很好地表达结果误差,有较强的通用性和推广性。目前概率模型主要被应用于目标分类与结果预测,Martinetti等[13]提出了2种空间概率模型对法国南部普罗旺斯地区的城镇用地进行土地变迁预测,并对两种概率模型的预测结果进行了对比分析。Ng[14]基于概率模型对美国的经济衰退时间节点、持续时长和经济周期拐点进行了预测分析并取得了较好的效果。农业方面,Areal等[15]基于概率模型衡量了不同种作物类型对环境的影响并发现转基因作物相比于传统作物对环境的影响更小。Damalas等[16]基于概率模型分析了巴基斯坦罗德兰和韦哈里地区作物农药施用的影响因子并对影响因子进行了重要性排序。该文以陕西省关中平原西部为研究区域,利用高分一号卫星(GF-1/WFV)遥感影像数据和研究区气象数据产品,反演提取表征小麦生长状态的归一化植被指数(normalized difference vegetation index,NDVI)、增强型植被指数(enhanced vegetation index,EVI)以及表征小麦生长环境的降雨量(precipitation)和地表温度(land surface temperature,LST)信息。基于概率模型对研究区地小麦白粉病进行了监测,并将监测结果与分类与回归树(classification and regression tree,CART)和随机森林(random forests,RFs)2种常用的分类方法的监测结果进行对比分析,同时得到了研究区小麦的白粉病患病概率、监测结果及其错分概率的空间分布信息。
1 数据与方法
1.1 研究区域概况
该文的研究区域(图1)为陕西省关中平原西部地区(34.14°N~34.6°N,107.65°E~109.1°E),海拔高度325~800m,总面积约5.55万km2。该地区土质疏松肥沃,水源充足,是中国重要的商品粮产区[17]。研究区地处暖温带半湿润季风气候区,是气候变化的敏感区,年平均温度6~13℃,年均降水量500~600 mm,雨热同期,冬春降水较少,春、伏旱频繁发生[18],是小麦白粉病的常发区域。
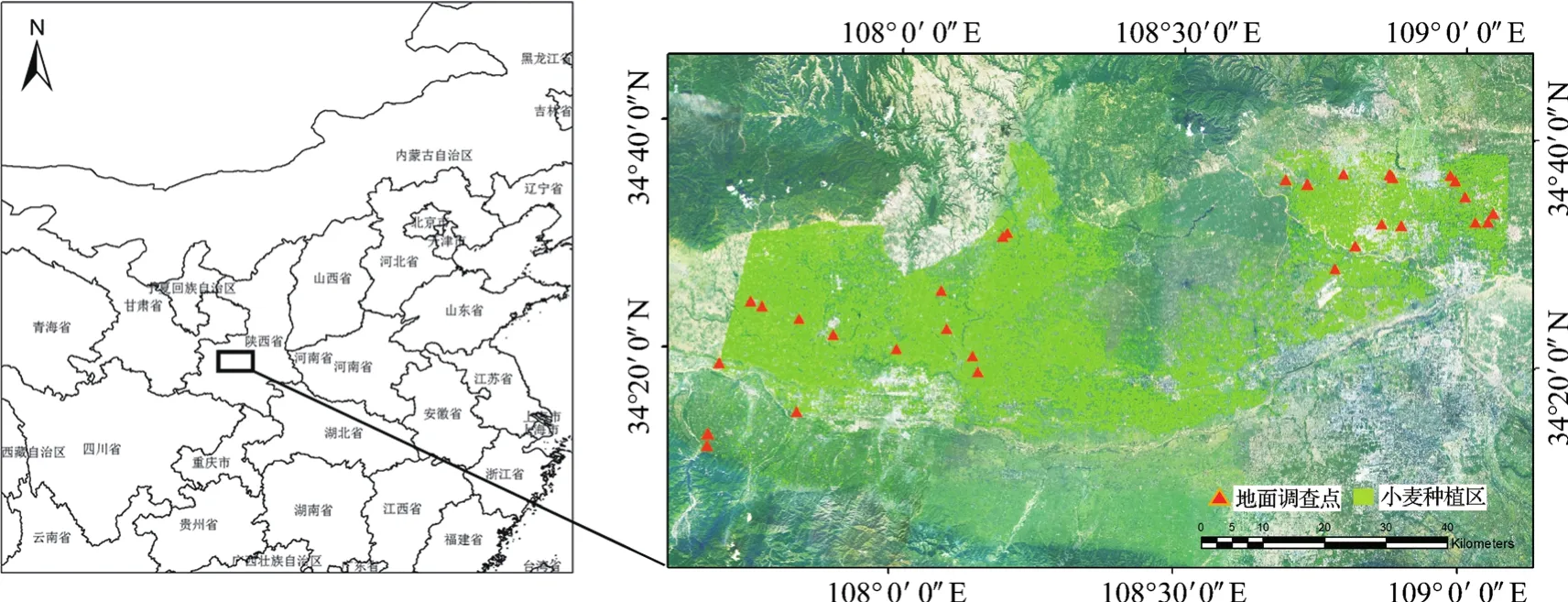
图1 研究区域概况Fig.1 General situations of study region
1.2 数据
地面调查数据获取时间为2014年5月中旬,调查点主要分布在研究区的东北部和西南部。调查时在每个调查地块选取1m×1m样方5个(图2),统计每个样方内的病情严重度指数,病情严重度(disease index,DI)采用农业行业标准(NY/T613-2002)中小麦白粉病“0 ~ 9 级法”进行记录,取所有样方病情严重度指数的均值作为调查点的病情严重度指数并用手持式GPS在调查地块的中心位置定位。地面调查数据共有调查点42个,结合实际白粉病监测需求,该文将调查点分为健康(DI:0~1)与患病(DI:2~9)两种。

表1 2014年研究所用遥感数据与气象数据Table 1 Remote sensing data and meteorological data used in this study

图2 调查点样方选取示意图Fig.2 A schematic diagram of sample selection
1.3 数据处理
1.3.1 数据预处理
对获取的GF-1/WFV数据进行辐射定标、大气校正和几何精校正等预处理[20]。
辐射定标采用的公式为式(1):

式中,Lz(λz)为传感器入瞳处的光谱辐射亮度(W/(m2·sr·μm)),Gain为定标斜率,DN为卫星载荷观测值,Bias为定标截距。辐射定标参数从中国资源卫星应用中心获取(http://www.cresda.com/CN/)。
大气校正采用FLAASH大气校正模型,所需参数为GF-1/WFV传感器光谱响应函数、卫星观测几何参数等。几何精校正采用Landsat-8/OLI全色影像作为控制影像,选取控制点100个,最终平面精度在1个像元以内。
1.3.2 特征因子的选择
当前时代是商品经济时代,商品与人们的生活息息相关,高中生也不例外。人们在挑选商品时,包装成为了影响大众消费行为的重要因素。合理的包装,不仅能保护商品免于挤压,而且还能让商品更显美观,能够拉近消费者与产品之间的距离。事实上,包装不仅是一种外在形式,而且还是商品价值构成中的因素。当前商品过度包装活动的综合表现为:
冬小麦白粉病病原菌在环境条件适宜的情况下以吸胞伸入寄主表皮细胞吸取寄主营养,病菌菌丝体在病部表面形成绒絮状霉斑,上有一层粉状霉[21]。研究区冬季温度较低,白粉病病原菌越冬后在小麦返青拔节期开始进行侵染,患病小麦症状多出现在孕穗期之后,在灌浆期最为明显[6],因此返青拔节期到灌浆期的小麦生长状态和环境条件与白粉病的发生关系密切。故选取能够表征小麦生长状态和和体现环境条件的特征因子用于小麦白粉病监测模型的构建。
受白粉病侵染的小麦在发病前后其生物量和冠层结构会发生显著变化,NDVI作为一种广泛应用于植物生长监测的植被指数,可以反映植物生物量的变化[22];而EVI对植物的冠层结构比较敏感[23],故研究选用NDVI和EVI来表征小麦生长状态。表2给出了两种指数的名称及计算公式。考虑到多时相数据可以更好的表达小麦生长状态的变化,研究最终将2014年3月14日(返青拔节期)和2014年5月18日(灌浆期)研究区小麦的NDVI和EVI均值(NDVIaverage、EVIaverage)作为模型的部分输入变量。

表2 研究所用植被指数Table 2 Vegetation index used in this study
白粉病病原菌的侵染过程主要受到温度和降雨的影响[26],故选用温度和降雨作为体现环境条件的指标。4月份雨量多、田间湿度大,或5月上旬阴雨连绵均易造成小麦白粉病的流行,若小麦生长后期雨量偏多分布均匀,温度又偏低,将延长白粉病的流行期,加重病情,因此研究将研究区2014年4月到2014年5月中旬的每8日平均地表温度和每5日平均降雨量(LSTper-8-days、Precipitationper-5-days)作为白粉病监测模型的另一部分输入变量。
研究采用独立样本T检验对选取的各个特征因子与小麦白粉病的相关性进行检验(表3)。结果显示NDVIaverage、EVIaverage、LSTper-8-days和Precipitationper-5-days的T检验P值均小于0.01,表明所选特征因子与白粉病发生的相关性十分显著,可用于小麦白粉病监测模型的构建。

表3 相关性分析结果Table 3 Correlation analysis results
1.3.3 小麦种植区提取
研究区冬小麦收割时间集中在5月底到6月初,小麦收割前后地表特征差异明显。研究选取了2014年5月18日与2014年6月17日的GF-1/WFV影像数据反演得到的NDVI信息来实现对研究区的小麦白粉病种植面积的提取。利用式(2)获取两个时相的NDVI差异数据(NDVIdifference),并基于地面调查点进行监督分类,最后对分类结果进行Majority/Minority分析,将虚假像元正确归类[27],得到研究区小麦种植区域分布数据。

1.4 概率模型的构建
1.4.1 健康小麦特征因子值分布情况的探索与表达
该研究首先对健康小麦特征因子值的分布进行分析,通过分析各个特征因子值的直方图后,对实地调查点健康小麦的特征因子值进行Shapiro-Wilk正态性检验并绘制Q-Q图(图3),结果表明各特征因子对应Q-Q图中点的分布均近似散落于一条直线附近且正态性检验结果(表4)的P值均大于0.05,证明健康小麦特征因子值的分布近似于正态分布。

图3 特征因子的标准Q-Q图Fig.3 Standard Q-Q diagram of characteristic factors

表4 特征因子正态性检验结果Table 4 The results of characteristic factor normality
研究采用非线性最小二乘法对各个特征因子分布函数的参数进行拟合,表5列举出了各参数对应的拟合结果值。

表5 拟合结果Table 5 Fitting results
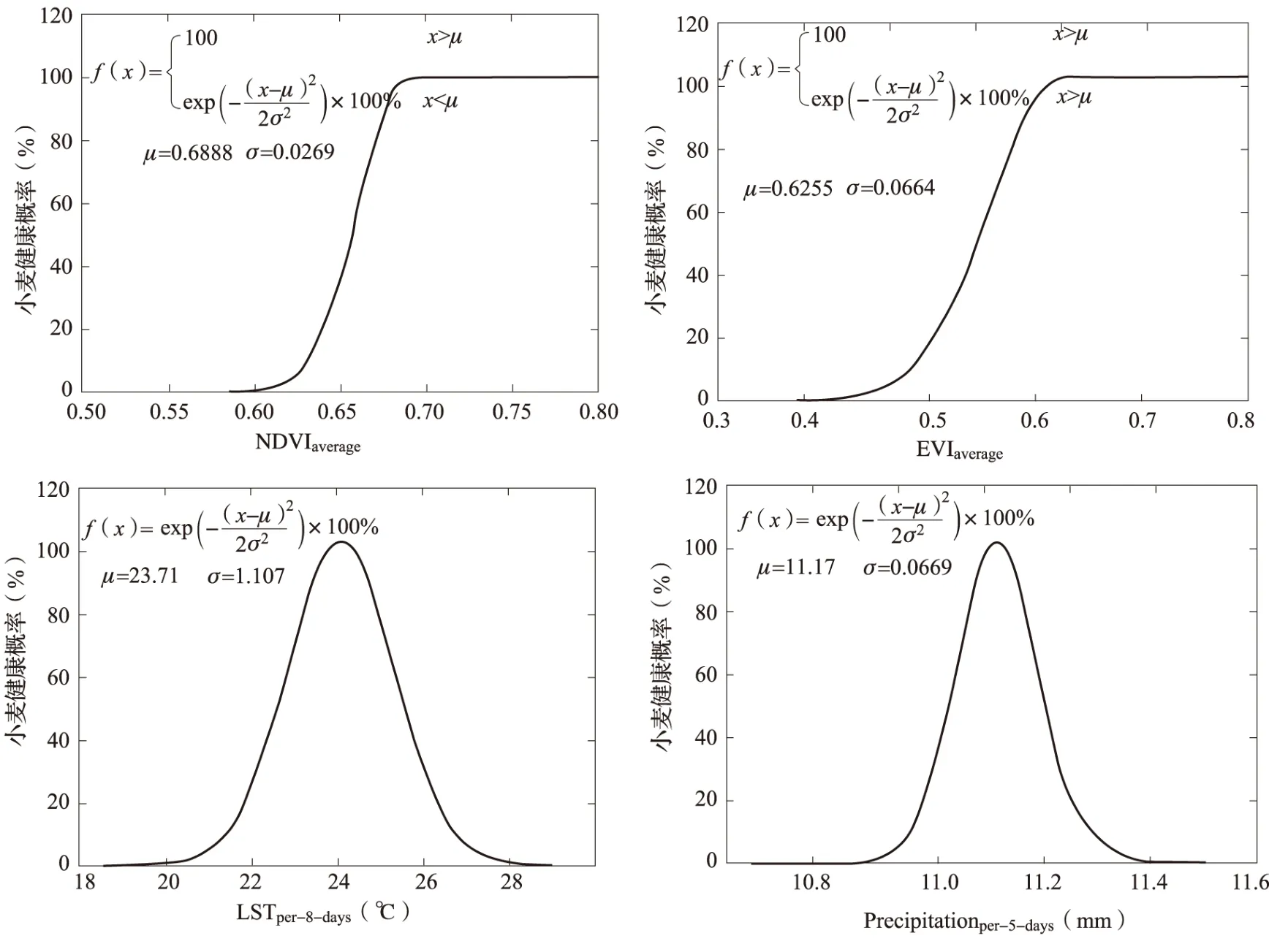
图4 特征因子与小麦健康状态的关系Fig.4 The relationship between characteristic factors and the wheet health status
分析表明健康小麦特征因子值的分布近似于正态分布,且正态分布函数的峰值出现在x=μ时,表明健康小麦对应的特征因子值多集中于μ值附近且特征因子值从μ值开始变化时对应健康小麦数量的变化服从正态分布。因此该研究选取各个特征因子对应分布函数的μ值作为健康小麦各个特征因子的最典型值,即当某地块小麦的某特征因子值x=μ时,则表示该地块小麦为健康小麦的概率最大。基于此,研究将x=μ时小麦为健康小麦的概率设为100%,由此得到各个特征因子与小麦健康状态间关系的定量表达如图4所示。
1.4.2 小麦综合健康概率的计算

小麦综合健康概率即为整合了所有特征因子后某地块小麦为健康小麦的概率。该研究中小麦综合健康概率的计算方法为式(3)。式中P(NDVIaverage)、P(EVIaverage)、P(LSTper-8-days)和P(Precipitationper-5-days)分别为相应特征因子单独所得小麦健康概率,w1、w2、w3和w4依次为特征因子NDVIaverage、EVIaverage、LSTper-8-days和Precipitationper-5-days对应的权重值。
研究将实地调查点的健康小麦和患病小麦分别赋予100%和0%的小麦综合健康概率值,在此条件下采用最小二乘法进行线性拟合,得到各特征因子值的系数,最后将系数进行归一化后作为各个特征因子的权重值。
具体的数据处理及实现流程如图5所示。

图5 数据处理流程Fig.5 Date processing flow
2 结果与分析
2.1 研究区小麦白粉病监测结果
研究基于小麦综合健康概率,利用式(4)得到研究区小麦患病概率空间分布情况(图 6a)。

从图6可以看出,研究区中部地区小麦患病概率较高,西部和东北部患病概率相对较低,且东北部不同麦区间患病概率差异较大。整体的变化趋势表现为由中部高患病概率区向西部和东北部低患病概率区过渡,且过渡区域明显,表明小麦患病概率空间分布与实际调查结果较为相符。为进一步展示细节,对研究区中咸阳市郊区部分麦区的白粉病患病概率的监测结果进行了放大展示(图6b),可以发现该地区麦区患病概率较高,且监测结果在小面积麦区也能清晰地反映区域间的差异性。在实际小麦白粉病监测中有时需要将健康与患病小麦进行明确区分,以指导农场的农药喷施管理,因此以50%的患病概率为界,将小麦直接划分为健康(P′≤50%)和患病(P′>50%)。此外研究还选取了目前较为流行的CART和RFs 2种分类方法与基于概率模型的白粉病监测方法进行对比分析,3种方法的白粉病最终监测结果如图7所示。从图7可以看出,3种方法的监测结果均表现为研究区中部有较大面积白粉病,但RFs模型监测结果中发病区面积较小,东北部和西部几乎没有发病区,与其他2种方法的监测结果差异较大。CART模型和概率模型的监测结果则较为相似,二者在研究区东北部的监测结果具有很高的一致性,但CART模型的监测结果在研究区西部发病面积较小。总体而言,3种模型的监测结果表现为CART模型和概率模型的发病面积较大,RFs模型的发病区较少且多集中于研究区中部。

图6 研究区小麦患病概率分布图Fig.6 Probability distribution map of wheat disease in the study area
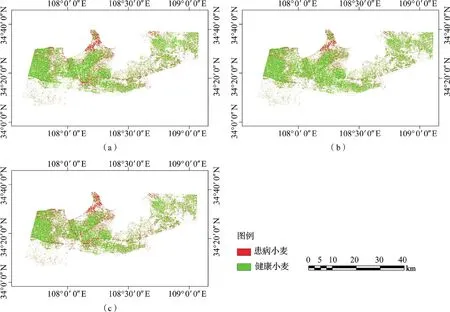
图7 3种方法的白粉病监测结果,包括分类回归树(a)、随机森林(b)和概率模型(c)Fig.7 Wheat Powdery mildew monitoring results using three methods,including classification and regression tree(a)、Random forest(b)and probabilistic model(c)
2.2 模型评估
因研究所用实地调查点数量较少,故采用留一法进行监测结果的精度验证。各监测方法所得监测结果的混淆矩阵、总体精度、漏分误差、错分误差及Kappa系数见表6。

表6 各方法监测结果的总体验证Table 6 The overall verification of the monitoring results using various methods
从精度评估结果中可以看出,基于CART模型的白粉病监测结果精度最高(83.33%),kappa系数为0.63,而概率模型的监测结果总体精度略低(81.25%),且kappa系数为0.61,RFs模型的监测结果精度最低,为77.08%。将健康小麦误分为患病小麦是3种监测方法的主要误差来源,这种错误分类也使得3种方法均有相对较低的制图精度(健康小麦)和用户精度(患病小麦),这种现象主要是由部分实地调查样点中患病样点的患病程度较轻以及采样点对应像元的异质性导致的[27]。虽然概率模型的监测结果精度略低于CART模型,但CART模型在样本量较小时不稳定,个别训练样本会导致决策标准的较大变化,而概率模型相对稳定,在采用留一法进行验证时各训练样本集产生的监测结果几乎无明显差异。
此外,基于研究区小麦患病概率数据和小麦种植区白粉病概率模型监测结果,利用式(5)可得到对应的错分概率分布图(图8),从中可以看出,研究区中部和西北部高错分概率麦区较多且分布较为集中,东部高错分概率麦区较少且分布较为分散。综合概率模型监测结果与错分概率分布结果可知患病区中高错分概率麦区明显多于健康麦区,这可能是由于地面调查数据中患病点相对较少且分布较为集中,导致在进行由点至面的监测中存在较大的不确定性。进一步将监测结果中错分的验证点和正确分类的验证点所对应的错分概率数据进行对比分析(表7),发现监测结果中错分验证点对应的错分概率均值为41.95%,明显大于正确分类验证点对应的错分概率均值(29.94%),且正确分类验证点对应的错分概率标准差较大,表明存在错分概率较大的验证点未被错误分类。考虑到错分概率表达的是一种可能性且该部分验证点数量极少,因此错分概率分布图整体上与实际情况有较好的一致性,可以指导监测结果的评估。


图8 研究区小麦白粉病监测结果错分概率分布图Fig.8 The mis-probability distribution of the wheat powdery mildew monitoring results in the study area

表7 验证点对应错分概率Table 7 Probabilities of verifying point error
3 结论与展望
3.1 结论
以陕西省关中平原地区为例,基于2014年5月18日及2014年6月17日的GF-1/WFV影像数据提取了该区域的小麦种植区;基于2014年3月14日和2014年5月18日GF-1/WFV影像数据获取了该区域小麦长势信息;基于CHIRPS数据和MOD11A2数据获取了该区域小麦生长环境信息。以多时相NDVI和EVI均值NDVIaverage和EVIaverage,以及返青拔节期至灌浆期每8日LST均值LSTper-8-days和每5日降雨量均值Precipitationper-5-days为特征因子,通过数据探索分析与关系拟合构建了与特征因子对应的患病概率模型,并得到了该区域小麦种植区患病概率分布图,并以50%的患病概率为界得到了该区域小麦白粉病监测结果,同时得到了监测结果对应的错分概率分布图,另外将概率模型的监测结果与常用分类方法CART和RFs的监测结果进行了对比分析。结果表明,以50%患病概率为界得到的小麦白粉病监测结果的总体精度与CART模型的监测精度相近且比RFs模型高出4.17%,此外基于概率模型的小麦患病概率分布图较CART和RFs方法保留了更多田间信息,能够更详细地展现研究区小麦患病概率的空间分布情况以及高患病概率麦区向低患病概率麦区的过渡情况,说明概率模型能够更好地监测小麦白粉病。此外,基于患病概率数据产生的错分概率分布图与实际情况有较高的一致性,对监测结果的整体评价具有指导作用。综上可知,基于概率模型的小麦白粉病监测方法可以应用于区域小麦白粉病的监测,且相比传统的监测方法具有更好的监测效果。
3.2 展望
样本的数量和质量在模型的建立过程中至关重要,该研究在开展过程中考虑到采样成本的问题,样本点数量有限且没有往年的采样数据,今后会考虑重新去研究区进行采样以检验模型的通用性。此外小麦白粉病的发生是多种因素共同作用的结果,该研究中仅仅考虑了部分植被参数信息和田间生境信息,所构建的模型必然存在一定误差,今后在研究过程中将逐步纳入农田管理信息、风向信息等数据,尽可能构建一个融合星地多源数据的小麦白粉病综合监测模型,从而更精确地对白粉病在空间上的分布、发生严重度等进行监测。
参考文献
[1]杨美娟,黄坤艳,韩庆典. 小麦白粉病及其抗性研究进展. 分子植物育种,2016(5):1244~1254.
[2]刘淑香,杨军玉. 3种杀菌剂防治小麦白粉病田间试验. 现代农业科技,2010,(2):178,180.
[3]王志顺,陈桥生,张道荣,等. 小麦白粉病的发生原因及综合防治. 现代农业科技,2009,(19):174.
[4]Zhang Jingcheng,Yuan Lin,W ang Jihua,et a1.Research progress of crop diseases an d pests monitoring based on remote sensing.Transactions of the Chinese Society of Agricultural Engineering(Transactions of the CSAE),2012,289(20):1~11.
[5]Yuan L,Bao Z,Zhang H,et al. Habitat monitoring to evaluate crop disease and pest distributions based on multi-source satellite remote sensing imagery.Optik-International Journal for Light and Electron Optics,2017,145:66~73.
[6]Zhang J,Pu R,Yuan L,et al. Monitoring powdery mildew of winter wheat by using moderate resolution multi-temporal satellite imagery.PloS one,2014,9(4):e93107.
[7]Yuan L,Pu R. ,Zhang J,et al. Using high spatial resolution satellite imagery for mapping powdery mildew at a regional scale.Precision Agriculture,2015,DOI:10. 1007/s11119-015-9421-x.
[8]Gebbers R,Adamchuk V. Precision Agriculture and Food Security.Science,2010,327(5967):828~831.
[9]Zhu A,Wang R,Qiao J,et al. An expert knowledge-based approach to landslide susceptibility mapping using GIS and fuzzy logic.Geomorphology,2014:128~138.
[10]Qin C,Zhu A,Shi X,et al. Quantification of spatial gradation of slope positions.Geomorphology,2009:152~161.
[11]杨琳,朱阿兴,秦承志,等. 运用模糊隶属度进行土壤属性制图的研究——以黑龙江鹤山农场研究区为例.土壤学报,2009,46(1):9~15.
[12]Liu X,Kuang Z,Yin L,et al. Structural reliability analysis based on probability and probability box hybrid model.Structural Safety,2017,68:73~84.
[13]Martinetti D,Geniaux G. Approximate likelihood estimation of spatial probit models.Regional Science and Urban Economics,2017,64:30~45.
[14]Ng E C Y. Forecasting US recessions with various risk factors and dynamic probit models.Journal of Macroeconomics,2012,34(1):112~125.
[15]Areal F J,Riesgo L. Probability functions to build composite indicators:A methodology to measure environmental impacts of genetically modified crops.Ecological Indicators,2015,52:498~516.
[16]Damalas C A,Khan M. Pesticide use in vegetable crops in Pakistan:Insights through an ordered probit model.Crop Protection,2017,99:59~64.
[17]窦睿音,延军平.关中平原太阳黑子活动周期与旱涝灾害的相关性分析.干旱区资源与环境,2013,27(8):76~82.[18]郭晓鸽,庞奖励,史兴民,等.关中平原近50 年来气候生产力的变化及对植物影响研究.农业系统科学与综合研究,2010,26(4):395~400.
[19]Funk C,Peterson P,Landsfeld M,et al. A Quasi-global precipitation time series for drought monitoring data series 832.Usgs Professional Paper,2014,Data Series(832).
[20]王利民,刘佳,杨福刚,等. 基于 GF-1 卫星遥感的冬小麦面积早期识别. 农业工程学报,2015,31(11):194~201.
[21]Wicker T,Oberhaensli S,Parlange F,et al. The wheat powdery mildew genome shows the unique evolution of an obligate biotroph.Nature Genetics,2013,45(9):1092~1096.
[22]Pang G,Wang X,Yang M. Using the NDVI to identify variations in,and responses of,vegetation to climate change on the Tibetan Plateau from 1982 to 2012.Quaternary International,2017,444:87~96.
[23]Gao X,Huete A R,Ni W,et al. Optical-biophysical relationships of vegetation spectra without background contamination.Remote Sensing of Environment,2000,74(3):609~620.
[24]Rouse Jr,Haas R,Schell J,et al. Monitoring vegetation systems in the Great Plains with Erts.Nasa Special Publication,1973,351:309.
[25]Huete A,Didan K,Miura T,et al. Overview of the radiometric and biophysical performance of the MODIS vegetation indices.Remote Sensing of Environment,2002,83(1):195~213.
[26]Huang X,Zeller F,Wenzel G,et al. Molecular mapping of the wheat powdery mildew resistance gene Pm24 and marker validation for molecular breeding.Theoretical & Applied Genetics,2000,101(3):407~414.
[27]Yuan L,Pu R,Zhang J,et al. Using high spatial resolution satellite imagery for mapping powdery mildew at a regional scale.Precision agriculture,2016,17(3):332~348.
