基于交易数据的信用评估方法
2018-05-22周继恩杜金泉
陈 煜 周继恩 杜金泉
(中国银联股份有限公司 上海 200135)
0 引 言
随着大数据时代的到来,各种各样的用户数据都可以用于转化,评估,体现个人数据。日常消费数据还有很大的挖掘价值。学术研究方面,国内学者从定性和定量的角度对个人信用评估进行了一系列的研究[5],但是目前为止尚未形成一种针对银行卡交易数据的个人信用评估模型及体系。因此本文以个人信用评估方法为研究中心,结合银行卡交易数据,构建一个新的个人信用评估模型。
1941年,Divid Durand采用评分形式来评估个人信用,建立了经典的消费信贷评分标准。随着计算机技术的不断发展,越来越多的计量方法应用到了信用评估领域,比如统计学中的线性回归方法和Logisitic回归[6],机器学习中的神经网络[3]、集成学习[8]、支持向量机[2]等,这些方法不断完善着信用评估系统。
1 信用模型构建
首先,本文着眼于个人信用模型的建立,采用的数据来源于线下刷卡、网上消费等产生的交易数据。然后,针对问题,提取有效的特征集,筛选特征并用于信用模型的训练。最后,对训练完成的信用评估模型验证,解释结果,并做出相应的决策建议。
1.1 信用特征计算方法
特征是指区分不同类型的本质特点,在信用评估的问题下,更偏向寻找,计算那些能够用于区分信用好的用户及信用差的用户的特征,用户的信用画像由这些信用相关的特征组成。因此特征提取在提高分类的准确性中起着非常关键的作用。
交易数据中包含的要素有:交易金额、交易时间、交易渠道、商户代码、交易地区、交易类型、商户类型、卡类型、卡介质、发卡机构、收单机构等。在研究中,本文根据交易数据,提取了众多的特征,大体的方法主要分为三类:
(1) 基于统计方法的特征提取 每个人所持有的卡数和产生交易的次数都不同。本文基于统计的方法提取了大部分特征。提取特征的常见方法有均值、方差、最大值、最小值、时率、占比等。基本上交易中绝大部分要素都可以通过统计的方法衍生出众多的特征。
(2) 利用聚类方法,计算行为特征模型 有些人偏爱消费,有些人偏爱存取。依据每个人不同的行为偏好,采用聚类的方法将目标用户分为几类,利用聚类方法针对不同群体计算行为特征。聚类的场景可以是交易时间、交易渠道、交易金额、交易次数、交易频率等。例如,消费行为聚类特征,将交易渠道分为四类{ POS ,ATM,电脑互联网消费,其他},计算每个持卡人各个渠道的交易占比,以此4个特征作为聚类特征,利用Kmeans算法,将样本用户划分为几类。
(3) 依据经验知识,刻画信用特征 构造用户画像主要是依靠内部和外部的信用经验,抽象出影响个人信用风险的关键性因素,依据交易数据实现关键因素的计算。在信用领域、还款能力、还款意愿,资金管理能力等都是影响信用评估的关键。
1.2 特征筛选
通过以上三种方法,计算了大约2 000多特征。这里有许多特征对于信用评估是无用的,甚至有负面作用。特征选择减少特征的数量,使模型泛化能力更强。本文采用特征选择的方法有:
(1) IV值 IV值,即information value,中文表述为信息量或信息值,其主要作用就是当我们在用决策树或逻辑回归构建分类模型时对变量进行筛选。IV值就是衡量自变量对于标签特征的区分能力,IV值越大,区分能力越强。本文设置IV值的阈值为0.04,筛选掉IV值小于0.04的特征变量。
(2) 相关性过滤 相关系数用于考察两个变量或特征之间的相关程度。如果相关性过高,会导致模型重复计算。因此,需要过滤掉相关性过高的特征,本文设定线性相关性阈值为0.5.当两个变量相关性大于0.5时,保留IV值较大的特征变量。
2 信用评分模型
一般的分类算法,输出的并不是一个评分,而是一个类别。信用评分的优势在于可以在实际评估审核用户的贷款资格时,依据其他信息,状况做出更切实的调整;并且信用状况本身通过二分类问题简单描述,并不完全适合。因此本文通过集成学习方法,训练多个成员分类器,通过设计融合函数,达到评分的效果。
决策树是一种实用,高效的学习算法。它有着许多良好的特性,比如训练时间负责度低,预测时间短等,但同时,单独一棵决策树也有许多缺点,比如容易过度拟合。通过集成学习方法,可以大大减少单决策树带来的负面影响。随机森林是集成学习的一种方法,本文采用随机森林的方法,利用上一步计算筛选所得的特征,引入随机代价矩阵,学习和训练模型。
2.1 引入随机性
一般而言,在信贷领域将客户分为两部分,一部分是信贷行为较好的用户,我们将客户在借贷后,按期还款,视为“好客户”;有一些客户在借款后,未能按期还款,拖延达一定日期后,我们认定这类客户为“坏”客户。为方便起见,定义“坏”客户为正样本,“好”客户为负样本。样本中正样本和负样本比例不均衡。同样一个正例带来的损失远远大于好客户带来的收益。因此在训练成员分类器时,设置代价敏感矩阵。
(1)
式中:vbad是一个坏客户被误判为好客户所造成的的损失,vgood是对于好客户误判造成的损失,正确分类的代价为0。
随机森林是由多个决策树组成的分类器,为了确保成员分类器之间的差异性,随机选择F个输入特征来对决策树的结点进行分裂。随机森林的相关性取决与F的大小。F越小,成员树之间的相关性越弱。
集成学习对于弱分类器有提升效果,保证了成员分类器之间具有一定的差异性。本文设计随机代价敏感矩阵向量,以提升成员分类器的差异性。设λ为均匀分布,记为λ~U(1/a,a)(a>1),随机代价矩阵表示为:
(2)
针对每一个成员分类器产生一个随机代价矩阵,从而形成随机代价向量。随机代价向量表示为:
CV={cv1,cv2,…,cvm}
(3)
本文所提算法RCV-RF算法流程如下
算法1,RCV-RF
输入:训练样本集X=[x1,x2,…,xn]
步骤1从训练集X中,采用booststrap方法有放回地随机抽取m个样本集,构成新的样本集X={X1,X2,…,Xm}。
步骤2引入随机代价敏感向量CV,设置每个子树训练的代价敏感矩阵。
步骤3设n个特征,则在每一棵树的每个节点处随机抽取F个特征,进行节点分裂。
步骤4将生成的多棵树组成随机森林。
2.2 融合函数
通过训练产生m个成员分类器,在模型决策时,需要将每个成员分类器预测的结果进行融合,输出一个评分。信用评分可以表示为多个成员分类器中认为是好客户的占比。信用评分可以表示为:
(4)
式中:Cj(x)为第j个成员分类器预测的结果,δ(·)为指示函数,如果Cj(x)输出等于good为1,否则为0。
信用评分是由多个分类器投票产生,可能造成低分段和高分段的人数聚集过多,中间分段的人数过少。遇到这种情况,可以通过调大均匀分布的范围来达到分值覆盖人数相对均匀的目的。
3 实验对比
本文采用的数据包含两部分,一部分是使用过信用产品的客户信息及还款情况,另一部分是相关客户在银联渠道的交易数据。本文只采集借款之前的交易数据,借款之后的交易数据不参与建模。模型用于客户申请贷款的资格核准。客户借贷的场景为互联网消费金融,用户通过手机认证,无抵押贷款,贷款数额在3 000~15 000之间。
由于逾期的时间不同,所以“坏”可以是不同程度的,从拖延少于15天,15天到30天,一直到30天以上。“坏”客户为逾期超过30天的客户,“好”客户为逾期小于3天的客户。数据集中有2 643个坏客户,34 028个好客户,客户使用信用产品的时间在3~8月份之间。
本文依据时间将数据集分为训练集与测试集,3~6月为训练集,训练集用于训练信用模型,7~8月份客户测试集用于评估模型的效果。

表1 训练集与测试集大小
为评估特征计算方法有效性,采用IV值作为评价指标,对一些典型的特征做分析。为了比较提出的算法RCV-RF优劣性,本文选择对比的算法有RF,GBDT,Adaboost。采用ROC、AUC、K-S作为评价指标,对比算法结果。
3.1 特征分析
前文中提到,课题通过不同的方法,计算信用相关的特征变量,从而构造用户画像。本节首先分析一些典型的用户画像特征。
从表2可以看出,交易行为,消费金额的特征对于逾期风险有着较强的相关性。往往消费金额越大,在消费金融信贷产品上逾期的风险就会越低。经常出现刷卡余额不足的情况,说明了客户缺乏对资金管理的意识,潜在地提升了逾期的风险。这些特征对于好坏客户有着较为明显的区分度,并且绝大部分特征对于坏客户占比都呈现单调性。为本文后续建模提供了有力的支持。依据IV值和相关性等方法,特征选择出115维特征。
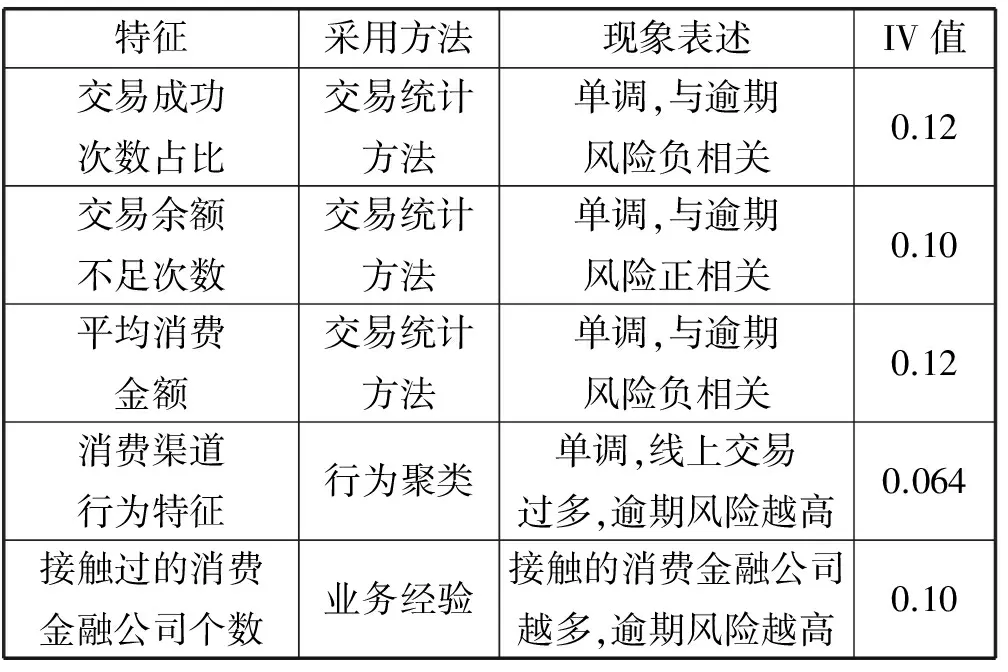
表2 部分特征的IV值
3.2 实验结果对比
本文选择了GBDT、RF、Adaboost三种经典的集成学习算法作为比较算法,所有算法均采用上文计算筛选所得特征集,使用3~6月份的数据做训练,7~8月份数据做测试,且使用相同的数据集训练与评估。如表3所示。
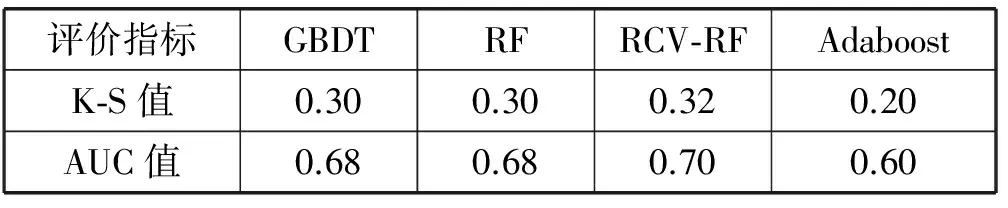
表3 模型的KS值对比
如图1所示,是本文算法和常用集成学习算法的ROC对比图。从图中可以看出,本文所提算法RCV-RF的AUC值为0.70略高于RF,GBDT算法,Adaboost算法效果与其他三种算法效果差距明显。通过KS值比较,RCV-RF算法亦优于其他算法。

图1 模型效果ROC图
4 结 语
本文基于银行卡的交易数据,针对互联网消费信贷场景进行分析,提取有效的特征集,建立一个用于信用评估的模型,并通过与其他常用算法对比,验证本文所提算法的有效性。本文主要分为两部分。首先,本文通过三种计算方式,提取在信用评估上具价值的特征变量,构建了基于交易数据的用户信用画像,这些特征对于模型训练起到了关键的作用。其次,本文算法通过引入随机代价敏感向量的方式,增强了成员分类器之间的差异性,并且通过评分融合函数使信用评分更为合理、有效。
参 考 文 献
[1] 石勇,孟凡.信用评分基本理论及其应用[J].大数据,2017(1):19-26.
[2] 陈云,石松,潘彦,等.基于SVM混合集成的信用风险评估模型[J].计算机工程与应用,2016,52(4):115-120.
[3] 胡来丰.基于粗糙集BP神经网络个人信用评估模型[D].电子科技大学,2015.
[4] 叶菁菁,吴斌,董敏.P2P网贷个人信用评估国内外研究综述[J].商业时代,2015(31):109-111.
[5] 李孟来.我国个人信用评分模型的应用探讨[J].金融管理与研究:杭州金融研修学院学报,2009(2):52-54.
[6] 马海英.基于神经网络及Logistic回归的混合信用卡评分模型[J].华东理工大学学报(社会科学版),2008,23(2):49-52.
[7] 沈翠华,邓乃扬,肖瑞彦.基于支持向量机的个人信用评估[J].计算机工程与应用,2004,40(23):198-199.
[8] 姜明辉,谢行恒,王树林,等.个人信用评估的Logistic-RBF组合模型[J].哈尔滨工业大学学报,2007,39(7):1128-1130.
[9] King G,Zeng L.Logistic Regression in Rare Events Data[J].Political Analysis,2001,9(2):137-163.
[10] Shuang C,Wei X.Design and Selection of Construction,Parameters and Training Method of BP Network[J].Computer Engineering,2001,92:336-337.
[11] Osuna E,Freund R,Girosi F.Training svm:An Application to Face Detection[C]//Proceedings of CVPR’97,June 17-19,1997.
[12] Orgler Y E.A Credit Scoring Model for Commercial Loans[J].Journal of Money Credit & Banking,1970,2(4):435-445.
[13] Huang C L,Chen M C,Wang C J.Credit Scoring with A Data mining Approach Based on Support Vector Machines[M].Pergamon Press,Inc.2007.
[14] Chen C,Breiman L.Using Random Forest to Learn Imbalanced Data[J].2004.
