基于微博短文本的大数据分析方法探索与研究
2018-05-21宋啸天姚家伟
宋啸天 姚家伟
镇江市人民检察院
0 引言
中国互联网络信息中心(China Internet Network Information Center,CNNIC)在2017年1月发布了第39次《中国互联网络发展状况统计报告》,其中指出截至2016年12月,我国网民规模达7.31亿,手机网民规模达6.95亿,占比达95.1%,增长率连续3年超过10%。2017年5月,新浪微博发布2017年第一季度财报,截至3月31日,微博月活跃用户达3.4亿,位居世界第一。
国内在大数据分析领域的研究起步较晚,但是发展较快。中国社科院、人民日报社和国内多所大学于2006年就开始了相关研究,此外国内还有诸如中科点击(北京)科技有限公司的军犬网络舆情监控系统、红麦聚信(北京)软件技术有限公司的unotice舆情系统、南京绿色科技研究院的CCLA网络舆情分析系统等多个舆情分析软件,取得了较大的进展。
微博是一种兼具流行和新兴的社交方式,由于微博短文本中的语言表达较口语化,同时由于“未登录词”(没有被收录在分词词表中但必须切分出来的词,如缩写词汇、专有名词、新增词等)的存在,导致大数据分析的难度较大。本文针对以上问题,首先对需要进行预处理的微博文本内容进行了阐述,随后提出了一种基于“未登录词”的识别算法,并设计了面向微博短文本的聚类整合算法。
1 微博短文本预处理
短文本通常具有错误性大、时效性强、信息量少、词语更新频率快等特点。微博短文本除了具备以上共性特点外,还具备有语言符号化(以符号代替文字)、互动性强、词语省略等特点。所以,为了进行微博短文本大数据的有效分析,需要首先对文本内容进行处理,处理流程如图1所示。

图1 微博短文本预处理流程示意图
(1)标点符号
在传统的中文分词方法中,会自动删除标点符号后利用词库分词。但是微博短文本与传统文本不同,标点符号往往掺杂着作者的情感要素,需要单独进行处理。例如:“?”一般表示疑惑或者疑问,“。”一般表示无感情的称述,“!”一般表示语气加重或者惊讶。
(2)无用词
在一篇微博短文本中,会出现一些没有任何明确意义和具体含义的词语,本文将此类词语称为无用词。由于无用词的存在会极大的影响文本分析的效率和准确率,因此应当在预处理过程中对无用词进行提取并删除。无用词主要包含乱码、错误词汇等。
(3)表情符号
微博官方为了丰富交互的多样性,加入了大量的表情符号,这些表情符号有时甚至可以表达作者一整句话的内涵。在微博的文本数据中,表情符号位于<img>标签的“title”属性之中,且这些表情符号也有对应的文字表示,例如:用“[doge]”表示,用“[摊手]”表示。为了更加精确的进行微博短文本的处理,也需要将相关的表情符号单独抽取出来进行隐藏价值的分析。
(4)特殊符号
在微博的短文本制作过程中,可以用到“@”和“##”这两个基本功能。其中,“@”表示作者希望位于“@”字符后的用户关注此条微博内容,“##”中间的词语表示一个话题。由于“@”和“##”关联的词语无需进行词义分离,所以在分词前应将对应内容提取出来,并在后期整理时参与文本分析。
但是,微博的词语更新频率较快,目前大多数分词系统的词库无法做到100%的未登录词识别,这就导致分词结果正确率会随着未登录词占比的上升而下降。所以,本文针对微博短文的未登录词提出了一种智能的识别算法。
2 微博未登录词的识别算法研究
目前常见的UW(Unknown Word,未登录词)算法主要是基于统计的CRF(Conditional Random Field,条件随机场)、SVM(Support Vector Machine,支持向量机)等方法。基于有监督方法的基本原理如下:
(1)对比模型和样本参数提取新词,如HMM(Hidden Markov Model,隐马尔可夫模型)和VA(Viterbi Algorithm,维特比算法);
(2)统计涉及新词的词句出现次数,并根据阈值判断新词的使用程度,如独立字概率方法。
而无监督方法是当循环统计中发现新词的重复次数大于实验计算得出的标准值时,则将新词确认为UW。
两种方法的挖掘过程如图2所示。

图2 UW挖掘方法图
在分析微博短文本的特点时,可以直接提取“##”和“【】”中间的文本(话题文本)。微博正文则采用文本分词法进行划分处理,UW的确认步骤可简单的分为以下三步:
(1)确认候选词;
(2)通过计算MI(Mutual Information,互信息)方法筛选候选词;
(3)确认UW。
具体流程如图3所示。

图3 UW识别算法流程示意图
其中,N-Gram是指一种N元的切词方法,即将字符串分割为长度为 N ( 2 ≤ N ≤ 5 ) 的子串,并得到分割词汇,随后通过筛选确认较为重要的词汇,最后在筛选词中确认候选词。差异项的删除过程可分为以下十步:
(1)匹配词库和切词的结果;
(2)删除已存在词汇;
(3)删除 H _ S T R 中 不存在于 B D _ S T R 中的词汇;
(4)词典遍历;
(5)删除旧词;
(6)计算候选词出现频率;
(7)删除出现频率低于标准值的词汇;
(8)利用MI技术和AS(Adjacent String,相邻串)过滤候选词;
(9)当词汇间包含PS(Public String,公共字串),例如“检察机关公诉”和“察机关公诉处”,将以上两个词汇分别记做 A和 B,当频率计算时发现 和 均存在且频率相同,则将A和B进行组合为联合词汇 AB,即“检察机关公诉处”,反之则删除频率词汇;
(10)利用MI技术计算AB能否构成UW。
当算法的过滤层次越高时,UW的识别准确率也越高。当词库本身不健全或是判断范围没有覆盖短文本全部内容时,将导致识别准确率有一定幅度的下降,但是本文提出的算法在计算速度和准确率上仍有较好的保证。
3 面向微博短文本的聚类整合算法
在微博短文本大数据分析的框架体系内,文本聚类是其中的一项基础工作。微博短文本信息主题分散、长度不一、没有较为显著的共性规律。为了在这些大量错综复杂的文本信息中挖掘出具备价值的内容,是聚类算法需要参与其中的主要因素之一。
传统的基于文档主题生成模型(Latent Dirichlet Allocation,LDA)的K-MEANS算法可用于对文本模型进行聚类计算,算法框架如图4所示。

图4 LDA-K-MEANS算法框架示意图
由于该算法的初始中心是通过随机或主观经验的方法进行设定,所以容易过早收敛,导致局部最优;并且该算法在分析词汇间语义时会进行降维处理,这就使得文本的完整性受到影响。对此,本文设计了一种新型的面向微博短文本的聚类整合算法。主要从以下两点进行调整:
(1)调整初始中心
为了改进传统K-MEANS聚类算法初始中心选取客观性较弱的问题,本文采取概率论理念对其加以改进。在调整后的初始中心选取算法中,本文将数据文本的相关主题内容表示为对应的关系矩阵,不同的主题对应的重要度也各不相同,重要度越高的主题越能反映文本的核心内涵。该算法主要可分为以下三步:
1)选取重要程度和关联程度较高的主题;2)根据主题词进行文本内容预处理;
3)获取收敛中心并作为聚类文本的初始中心。
由于单一的主题词没有整体的评估价值,所以需要对主题词的分布概率进行总结,并得出其在文本集合中的重要性。随后对文本集合重要性由高至低排序并选取排名靠前的主题词,运用K-MEANS算法对文本集合进行初始聚类,再计算被选取主题词的相似度,得到对应的中心点,最后将这些中心点作为K-MEANS的初始中心点。
(2)调整相似度算法
传统的K-MEANS算法中相似度的计算是基于“文本—主题”的语义关联模型,但维度的降低将导致相似度的计算结果精确度较差。通过融合VSM(Vector Space Model,向量空间模型)的算法(L_VSM),可以在不损坏文本信息完整性的同时能够在分析上挖掘出更深层次的关系,提升相似度算法准确性。由于采取了线性融合的方式,使得其准确率高于LDA算法和VSM算法,并且在计算过程中也保留了语义的关联关系,使得面向微博短文本的聚类整合算法准确率较高、运算速度较快。面向微博短文本的聚类整合算法流程如图5所示。
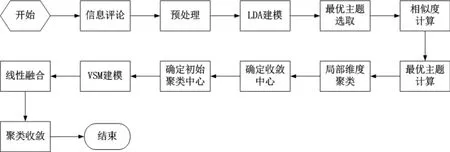
图5 面向微博短文本的聚类整合算法流程示意图
通过后续的模拟仿真测试,本文提出的面向微博短文本的聚类整合算法与LDA算法、VSM算法相比,其聚类F-Measure值(一种评价分类模型好坏的统计量)较高。初始中心杜绝了随机选取过早收敛的问题,符合微博短文本的实际分布情况。面向微博短文本的聚类整合算法通过线性融合,在一定程度上缓解了LDA算法降维和VSM算法语义联系弱带来的影响,使得相似度计算的准确率较高,有助于提升微博短文本的聚类分析质量及成效。
4 结语
互联网大数据的分析系统在国内外已经得到了较为广泛的应用,但是如何针对微博短文本进行纵深的大数据分析,以及如何将分析得出的内容更加有效的在社会发展中发挥出应有的作用,仍是我们需要继续深入研究的工作。由于微博在社交元素中拥有典型性,其用户群体之间的关系也是潜移默化、盘根错节的,本文将以此为切入点,在后续的研究中继续开展深入分析。
