关联数据作为背景知识支撑的智能决策研究
2018-05-17
(河北大学管理学院 河北 保定 071000)
一、引言
决策制定是一个复杂的过程。在决策过程中,数据扮演了重要的角色,需要根据不同的数据集,结合实际经验,制定整体的决策方案。但是在许多领域,虽然积累了许多本领域的数据集,但是,由于缺乏足够的背景知识的支持,在利用数据开展决策的时候,不能有效的发挥出数据的价值。关联数据中蕴含了语义信息,如果在决策过程中,将本领域的数据集与相关的关联数据集有效结合,对于指导实际决策具有重要的应用价值。
二、s相关研究
对于基于关联数据的知识发现的过程和层次,不同学者给出了不同的解读。赵卫军①提出由服务、组件和对象3功能实体组成的基于SOA的关联数据的高校图书馆知识服务架构模型,分成数据层、聚合层、组件服务层、应用层。李楠和张学福②认为基于关联数据的知识发现过程包括了关联数据发布、相关源选择、关联数据整合、关联数据挖掘4个基本阶段。他们将基于知识发现的应用特殊性与知识发现活动一般规律相结合,构建了包括资源层、知识发现处理层、应用层的3层基于关联数据的知识发现模型。李俊和黄春毅③通过修改了传统知识发现模型提出了在关联数据基础上实现知识发现的模型,将整个过程概括为:通过SPARQL获取信息、数据预处理、转换数据格式、关联数据挖掘算法运算、结果的可视化和模式评估6大步骤。上述研究是分别从理论和实践的角度加以阐述,由此产生了关联数据知识发现过程的描述差异。而事实上它们仍然符合传统知识发现的数据收集、数据预处理、数据转换、数据挖掘、模式解释和评价这一一般过程。
三、研究基础
知识发现(Knowledge Discovery)是从大量数据集中发现隐藏于数据其中的、创新的、潜在有用的模式的过程④。目前国内外在知识发现的研究主要是以知识发现的概念、知识发现的任务、知识发现的评价以及知识发现算法等为主线,并且已经取得了一定的研究成果⑤。针对知识发现的一般过程,研究人员从不同的角度有不同的理解。一般研究人员熟知的数据库中的知识发现(KDD)的一般过程即为普遍认可的,是Fayyad在1996年提出的知识发现处理过程模型⑥。其主要是从数据源出发,经过数据预处理、数据挖掘、结果的表达和解释三个核心步骤最终获取知识的过程。KDD给基于关联数据的知识发现提供了一定的参考和借鉴,KDD是数据网络中知识发现的基础,因此基于关联数据的知识发现应以KDD研究作为基础,本文也遵循知识发现的一般过程。
发现新颖、有效、可理解的游泳知识是知识发现的最终目标。因此,在关联数据网络的资源基础上,发挥关联数据的优势、利用关联的资源去发现“关联的知识”是实现与关联数据的知识发现目标的顶层功能和核心保证。在海量的关联数据网络环境中,结合相关数据资源查询、获取、处理和挖掘,还需要通过特定的关联知识发现,制定需要生成的知识模式,从而按照这一模式的结构去抽取与知识发现需求最为相关的信息,并且以用户需要和理解的方式重新组织和架构相关信息,生成新的知识⑦。
四、研究假设
利用关联数据作为背景知识,能否发现新的知识、模式,能否通过关联数据集减少挖掘过程中耗费的成本。目的是验证关联数据集和待挖掘数据能否产生新的知识,从而为决策提供现实依据。
五、实验与讨论
(一)实验数据的选择
本实验要验证将关联数据集作为领域背景知识,将关联数据背景知识应用到现有待挖掘数据中。关联数据背景知识选择欧洲统计局发布的关联数据集,欧洲统计局的关联数据集中包含了大量关于欧洲的各项统计数据,成员国机构负责收集本国统计数据并进行编辑,欧洲统计局的作用则是与各成员国统计机构紧密合作,协调、整合统计资源,按照欧盟的需要汇总分析成员国提供的统计数据。统计范围涵盖欧盟经济社会活动的主要方面,包括经济、就业、研发创新、环境、公共健康、国际账户收支、对外贸易、消费价格、农渔业、交通、能源、科技等。这些数据最终都发布为关联数据,用户可以在其网站通过Sparql查询的方式获数据⑧。
现有待挖掘数据选择OECD(经济合作与发展组织)网站给出的各个成员国成人的饮酒量数据⑨。OECD的数据门户提供了多样化的数据格式,如csv、excel格式等,本案中我们下载excel原始文件,然后导出为csv格式。
(二)数据获取
关联数据的获取通过Jena获取,Jena提供了更加灵活的方式通过Sqarql查询提取关联数据中信息,本案中,将Jena集成到Eclipse开发环境中,通过程序获取数据。获取欧洲统计局各国家经济数据的Sparql语句如下:
SELECT(sum(?value)as ?ss)?geo
FROM
FROM
WHERE{
?s qb:dataSet
?s dcterms:date ?time.
?s eus:geo ?g.
?g rdfs:label ?geo.
?s sdmx-measure:obsValue ?value.
FILTER(lang(?geo)='en')
}
GROUP BY?geo
基于Eclipse集成开发工具,在Jena环境中运行以上语句得到欧洲统计局关于各个国家经济运行情况的数据,格式如图下所示。
1378^^http://www.w3.org/2001/XMLSchema#decimal|Finland@en
1235^^http://www.w3.org/2001/XMLSchema#decimal|Italy@en
OECD的数据直接从网站下载,数据文件为excel格式,后续分析阶段直接另存为csv格式,包含了国家信息及其酒精消费情况,其格式如表1所示。

表1 CEDC各成员国年度酒精消费情况
(三)数据处理
通过Google refine数据清洗工具对Sparql查询的数据进行清洗,去除无用标签和符号,Google refine是一款免费开源数据清洗工具,能够帮助用户转换数据集的工具,优化数据的质量以便于在真实场景中使用。
(四)分析
数据的分析通过Rapidminer,其提供图形化界面,通过Rapidminer数据挖掘软件将关联数据和待挖掘数据导入,对相关变量做相关性分析,本案中主要分析经济因素GDP与酒精的二元关系,首先将关联数据集和待挖掘的数据集进行合并处理,通过Rapidminer的算子模块Join进行数据合并,数据的工作流程图如下图1所示:
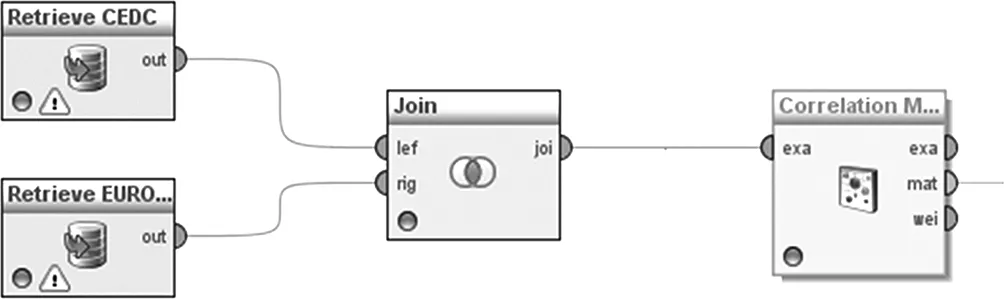
图1 数据处理流程图
执行以上流程得到变量相关性结果如下:

表2 GDP与酒精消费的相关系数
(五)验证、评价
通过以上分析,本实验建立在经典的知识发现和数据挖掘的基础之上,并结合关联数据的应用场景,设计了此挖掘步骤,通在工具的选择上,都是选用开源免费的软件和类库,这样为扩展带来了极大的灵活性,这样当面对多个关联数据集的时候,只需要调整数据整合的顺序,就能实现多数据集的关联挖掘。
通过计算的数据可以看出,应用关联数据作为领域背景知识能够为知识发现提供新的切入点,两个变量之间存在着相关性,这也拓宽了消费关联数据的范围,在大数据环境下,我们面对的是海量的异构数据,关联数据的出现能够为这些数据的挖掘提供背景知识,也能使数据挖掘的过程更加可操作化和简明化。
六、结语
在关联数据日益成熟、关联数据网络资源环境已经呈现的背景下,针对其特定知识发现规律的研究在理论和实践上都具有一定的意义。知识发现也能够作为基本方法论对关联数据的发展和完善起到促进的作用。本文在相关研究的基础上,分析和构建基于关联数据的知识发现应用体系,这一体系可以作为整合资源和成果的统一框架,也可以作为研究的基础和导向。关联数据研究得到了国内外广泛的关注,从关联数据的研究趋势和发展需求来看,基于关联数据的知识发现应用应当得到更多的重视。目前这方面的工作已经多方面展开,但主题相对分散,目标也不够明确。笔者希望本文所提出的应用体系可以作为关联数据研究的框架和基础,辅助相关工作的全面和深入的展开。下一步将研究将关联数据应用于人工智能领域,结合机器学习框架keras,探索关联数据更广阔的应用。
【注释】
①赵卫军.基于SOA的关联数据的高校图书馆知识服务架构[J].图书馆学刊,2013(6):103-105.
②李楠,张学福.基于关联数据的知识发现模型研究[J].图书馆学研究,2013(1):73-77,67.
③李俊,黄春毅.关联数据的知识发现研究[J].情报科学,2013.31(3):76-81.
④Soren A,Jens L.Creating knowledge out of interlinked data[J].Semantic Web,2010,(1):97-104.
⑤陈晓美,毕强,滕广青,等.语义网环境下数字图书馆知识发现的维度框架研究[J].情报学报,2014,33(2):148-157.
⑥Usama F,Paul S.Data mining and KDD:Promise and challenges[J].Future Generation Computer Systems,1997,(13):99-115.
⑦李楠.基于关联数据的知识发现研究:[D].北京中国农业科学院,2012.
⑧Eurostat-Linked Data.[EB/OL].http://eurostat.linked-statistics.org,2017-03-30.
⑨OECD.[EB/OL].http://www.oecd-ilibrary.org,2017-03-30.
【参考文献】
[1]赵卫军.基于SOA的关联数据的高校图书馆知识服务架构[J].图书馆学刊,2013(6):103-105.
[2]李楠,张学福.基于关联数据的知识发现模型研究[J].图书馆学研究,2013(1):73-77,67.
[3]李俊,黄春毅.关联数据的知识发现研究[J].情报科学,2013.31(3):76-81.
[4]Soren A,Jens L.Creating knowledge out of interlinked data[J].Semantic Web,2010,(1):97-104.
