面向智能电网大数据关联规则挖掘的频繁模式网络模型
2018-05-16孙丰杰王承民
孙丰杰,王承民,谢 宁
(上海交通大学 电子信息与电气工程学院,上海 200240)
0 引言
智能电网是利用现代网络信息技术等实现电网设备间的数据信息交换,从而实现电网实时自动化控制、智能调节、在线决策分析等功能的新型电网[1]。
智能电网的建设积累了海量数据资源,目前电力公司“用数据管理企业,用信息驱动业务”的需求日益迫切。而智能电网大数据具有4V特征,即数量大(Volume)、种类多(Variety)、速度快(Velocity)、价值密度低(Value)。传统的数据处理方法已经难以满足需求,因此学者们提出了一系列大数据挖掘算法。
关联规则挖掘算法由Agrawal等在文献[2]中首先提出,该方法从大量历史数据中寻找频繁项或属性之间的关联性。现有的关联规则挖掘方法主要是Apriori算法及频繁模式树FP-Tree(Frequent Pattern-Tree)算法[3-4]。Apriori算法的主要缺点是需要寻找大量的侯选项目集,当数据库较大时,存在组合爆炸问题,同时,Apriori算法需要多次扫描数据库,增加了计算的负担。
针对Apriori算法的缺点,J. Han提出了利用FP-Tree产生频繁项集的方法[5-6]。FP-Tree算法将提供频繁项集的数据库压缩到FP-Tree上,然后从初始后缀模式开始,构造条件模式基,再形成条件FP-Tree,并递归地在该树上进行挖掘,其主要优点体现在:不需要产生候选项,仅需要构造FP-Tree和条件FP-Tree,通过递归地访问FP-Tree产生频繁模式;对事务数据库仅需2次遍历,第1次遍历产生频繁1-项集,第2次遍历用于创建FP-Tree,从而极大地降低了访问数据库的次数。FP-Tree算法存在的主要问题为:挖掘过程中需要不断递归地生成“树”,增加了时空复杂度;FP-Tree和条件FP-Tree每次都需要双向遍历数据库,因此难以处理数据库更新、维护问题。
鉴于目前FP-Tree关联规则挖掘算法存在的问题,本文将提供频繁项集的数据压缩到FP-network上,通过形成关联矩阵,进行计算机存储和挖掘。本文方法继承了FP-Tree模型无需产生候选项以及不重复扫描数据库的优点,同时克服了FP-Tree模型生成复杂及更新、维护困难的缺点,特别适用于智能电网大型数据库,挖掘智能电网中的复杂规律。
1 FP-network模型
电力系统的数据库通常是事务和项目之间的关联,如表1所示的事务数据库,其中第1列为事务编号,第2列为项目集合,即事务包含哪些项目,项目集合为{I1,I2,I3,I4,I5}。

表1 事务数据库列表Table 1 Transaction database table
1.1 FP-network模型的网络图形式
根据表1,建立传统的FP-Tree模型如图1所示。由图1可见,树的生成过程十分复杂。此外,图1所示的FP-Tree模型将提供频繁项的数据库压缩到一个有向树状图上,所以存在维护、更新困难的缺点。为了避免这些缺点,本文提出了无向的FP-network模型。

图1 FP-Tree示意图Fig.1 Schematic diagram of FP-Tree
首先定义以下概念。
a. 弧容量:扫描事务数据库,第i条弧出现的次数,记作ai。
b. 节点频数:扫描事务数据库,节点j出现的次数,记为fj。
c. 节点负容量:扫描每条事务,节点j最后被扫描的次数,记为nj。
以表1为例,建立FP-network模型的过程为如下。
a. 将各个项目作为网络中的节点,将每个事物作为网络中的路径。

c. 按照上述原则依次扫描其他事务,所建立的FP-network如图2所示。

图2 FP-network示意图Fig.2 Schematic diagram of FP-network
图2所示的FP-network有以下特点。
a. 不同于FP-Tree,FP-network是无向图,且同一项目对应图中唯一节点(FP-Tree中同一项目可能对应多个节点)。
b. 弧容量之和等于所有节点频数与节点负容量的和,即:
(1)
其中,n为弧的数目;m为节点数目。
c. FP-network可能会将某些事务数量扩大。如对于项目I5而言,有2个事务与其相关联,分别为{I1,I2,I3,I5}和{I1,I2,I5}。但是图2中,节点I5可以找到4条路径,分别为{I1,I2,I3,I5}、{I1,I2,I5}、{I1,I3,I5}、{I2,I5},而后2条路径实际上并不存在。
1.2 FP-network模型的矩阵形式
为了避免上述网络图形式的缺点,FP-network的计算机存储采取事务(路径)-项目(节点)关联矩阵表示方式,即T=f(B,I)。仍以表1为例,有:
其中,T为事务集合;I为项目集合;矩阵B为事务-项目关联矩阵,其元素bij(i=1,2…,9;j=1,2,…,5)可以定义为:对于事务i,如果与项目j相关联,则bij=1 ,否则bij=0。对于大数据而言,通常事务数目远大于项目数目,因此生成关联矩阵的时间复杂度近似为O(事务数目),并且对数据库的存储可以转换为存储矩阵布尔矩阵B和I,极大地节省了内存。
1.3 FP-network算法步骤
利用FP-network算法可以方便地实现关联规则的挖掘,具体步骤如下。
a. 给定最小支持度阈值Smin。
b. 扫描数据库,如果fj c. 从nk为非零的第k个节点开始挖掘。 d. 只保留矩阵B中bik=1的节点k所有路径集合I(I={i丨bik=1}),仅保留节点k之前的节点信息,形成新的矩阵B、I。 e. 如果|nk|≥Smin,则节点k作为一个频繁项集的元素之一,否则不进行任何处理。删去此节点信息,形成新的矩阵B、I。转到步骤b,此过程持续至所有nk为非零的节点挖掘完为止。 如表1示例,取Smin为2,因I1—I5的节点频数均不小于2,故保留所有节点信息。首先从节点I3开始挖掘,矩阵B对应节点I3的列为第3列,其中元素为1的是第3、5、6、7、8、9行,保留这些信息得到新的矩阵。 将I3作为一个频繁项集的元素,并得到新的矩阵: 则I2也作为此频繁项集的元素;再重复一次,可得此频繁项集为{I1,I2,I3},且其所有子集(包括一项和两项)也是频繁项集。 同理从节点I4进行挖掘,其频繁项集为{I2,I4};从节点I5进行挖掘,其频繁项集为{I1,I2,I5}。至此,挖掘结束,所挖掘出来的频繁项集及其所有子集构成了频繁项集的集合。 FP-Tree模型的一个关键缺点是维护和更新困难,因为当新数据加入、原数据库更新或者改变支持度阈值时,FP-Tree算法需要重新扫描数据库来生成FP-Tree和条件FP-Tree。但是FP-network模型不存在这个问题,因为FP-network是以关联矩阵的形式保存的,而事务-项目关联矩阵中节点的顺序是任意的。例如,若调换节点I5和I1的顺序,可以将上述事务-项目关联矩阵做如下调整: 所产生的FP-network如图3所示。 图3 更新后的FP-network示意图Fig.3 Schematic diagram of updated FP-network 上述FP-network的关联规则挖掘首先从I3进行挖掘,得到频繁项目模式为{I2,I3,I1};然后,从节点I4开始挖掘,得到频繁项集为{I2,I4};最后从节点I1进行挖掘,得到频繁项目模式为{I5,I2,I1}。至此挖掘结束,FP-network不需要重新扫描数据库,只需要对矩阵进行操作,但仍然与上述结果相同。这说明FP-network模型与节点的排列顺序无关,克服了FP-Tree算法更新维护困难的缺点: a. 添加新的事务数据时,只需在矩阵B增加新的第j行和第i列,并改变相应的fj、nj; b. 改变支持度阈值Smin时,无需对矩阵进行任何处理,可直接在原矩阵上进行关联规则挖掘。 综上所述,FP-network算法与目前主要的关联规则挖掘算法Apriori、FP-Tree的比较如表2所示。 表2 关联规则挖掘算法的比较Table 2 Comparison among association mining algorithms 为了进一步验证所提FP-network算法的优越性以及展示FP-network算法如何应用于智能电网大数据分析,本文采用操作系统为Windows 10、内存为4 GB、CPU为Intel(R)Core(TM)i5-4430CPU@3.00GHz的实验环境,借助Anaconda平台,使用python语言开发,实现Apriori、FP-Tree、FP-network算法的实验测试。 以关联规则挖掘在输电线路故障分析领域的应用为例进行算例分析。采用某省电力公司大数据平台提供的输电线路故障信息,原始信息系统数据量庞大,达到TB级,但由于价值密度低,所以对2010 —2017年线路故障历史数据进行预处理(除噪、清洗、过滤等),得到1 276条有效信息,形成线路典型故障事务数据库,其中部分样本如表3所示。为满足算法测试需求,复制真实事务信息,可得到包含12 760条信息和127 600条信息的事务数据库。 对于数据库的“时间”属性,需要进行离散处理,鉴于实际分析需要,可忽略年份信息:T1表示春季(3—5月);T2表示夏季(6—8月);T3表示秋季(9—11月);T4表示冬季(12月至次年2月)。其他属性本身就是离散变量,定义了一系列字母变量来代替,预处理后的结果如表4所示。 在相同的实验环境下,取Smin=0.5%,分别测试Apriori、FP-Tree、FP-network算法在不同数据库规模下的运行速率,结果如图4所示。 由于图4可见,FP-network算法的运行速率要优于其他2种算法,且数据库规模越大,其他2种算法,尤其是Apriori的运行时间呈指数增长,使得FP-network优势更加明显。 表3 线路典型故障事务数据库Table 3 Transaction database of typical line faults 表4 预处理后的事务数据表Table 4 Transaction database after preprocessing 图4 不同数据库规模下的算法执行时间Fig.4 Executive time of algorithms with different database scales 图5 不同最小支持度下的算法执行时间Fig.5 Executive time of algorithm with different min_sups 改变支持度不会改变事务数据库的规模,但是会改变频繁项集的规模。采用包含127 600条信息的数据库测试不同支持度下的算法性能不同最小支持度下的算法执行时间,结果如图5所示。由图可见:在不同支持度下,FP-network算法的运行速率均优于另外2种算法;调低最小支持度(min_sup)后,3种算法的执行时间都有所增加,FP-network算法与其他2种算法的差距愈加明显。此外,FP-network算法可以较好地应对支持度的变化,运行速率变化幅度较小。 空间复杂度是对算法在运行过程中临时占用存储空间大小的量度,包括程序代码所占用的空间、输入数据所占用的空间和辅助变量所占用的空间。其中,输入数据所占用的空间不随算法的不同而改变;程序代码所占用的空间与算法书写的长短成正比。对于Apriori、FP-Tree、FP-network算法而言,存储算法本身的空间仅kB级,相较MB、GB级的数据库其差异可忽略不计;算法空间复杂度的对比重点在于辅助变量所占用的空间。利用memory_profiler模块,监控算法执行过程中所占用的最大内存,结果如图6所示。 图6 不同数据库规模下算法执行过程中占用的最大内存Fig.6 Maximum memory in execution of algorithms with different database scales 由图6可见,Apriori算法需要存储大量候选集,FP-Tree算法需要存储条件树,并需要进出栈操作,占用内存较大,FP-network算法占用内存空间远小于这2种算法,特别是在数据库规模较大时优势更加明显。综上所述,FP-network算法在处理大型数据库或强实时性问题时性能优势明显,适合电力系统大数据分析。因此,取Smin=0.5%,对故障信息数据库进行分析,得到所有频繁项集,进一步挖掘关联规则,结果如图7所示,图中连线的粗细表示关联程度的强弱。 图7 关联规则挖掘结果图Fig.7 Results of association rules mining 如图7所示,得到的关联规则有上百条,但是并非所有的关联规则都是有价值的。有些规则关联性十分弱,有些关联性并没有实际的意义。通过计算规则置信度(如式(2)所示),筛选出置信度不低于75%的规则,得到部分结果如表5所示。 (2) 其中,support(·)表示支持度。 表5 关联规则挖掘结果Table 5 Results of association rules mining 结合实际电力知识背景,利用上述挖掘结果可以分析该省的线路故障情况,找到电网中存在的薄弱环节,并针对这些薄弱环节提出改进措施和方案: a. 从规则1可知,该省中部地区220kV线路在3—5月份因为导线及地线舞动造成严重影响,因此应做好春季线路舞动预防措施; 图8 智能电网“数据系统业务”图Fig.8 Diagram of “Big data-System-Business” in smart grid b. 从规则2可知,该省南部地区在6 —8月因外力破坏(如违规施工)造成导线及地线故障较多,因此相关部门要采取措施杜绝违规施工; c. 从规则3可知,该省500kV的线路故障大多是绝缘子故障,主要集中在中部地区的12月至次年2月,因此检修部门可以在冬季有针对性地对中部地区多加巡查; d. 从规则4可知,该省东部地区的110kV线路故障大多数是导线及地线故障,因此相关部门要优化脆弱地区的线路布局等; e. 从规则5可知,该省线路覆冰故障主要集中在3—5月份,并以中部地区的500kV线路居多,因此中部地区应在该月份加强对500kV线路的监测,及时对覆冰进行融化处理。 如第3节所示,FP-network可以挖掘多维属性间的关联规则,除输电线路故障分析领域外,其在智能电网中的应用十分广泛。智能电网大数据的来源大致可分为电网外部和电网内部2类。电网外部的数据来源包括但不限于互联网信息系统、充电设施管理系统、气象监测系统、地理信息系统(GIS)等;电网内部的数据来源主要包括用电信息采集系统、设备运维管理系统(PMS)、企业资源计划(ERP)系统、SCADA系统、D5000系统、95589客服系统、营销系统等[7-8]。不同的系统存储着不同的数据信息,同时也对应着不同的业务部门和业务需求。 因此,本文将智能电网中常用的数据和信息系统进行了梳理,建立“数据-系统-业务”体系,如图8所示。通过图8所示体系,数据的来源和流向一目了然,既可以利用数据来驱动业务发展,也可以基于业务流程和需求进行数据挖掘分析。因此基于智能电网“数据-系统-业务”体系,FP-network算法在智能电网中的应用可以根据业务需求分为三大类[9]:面向用户服务、面向电力公司管理、面向政府决策。本文限于篇幅,着重介绍以下应用[10-14]。 a. 用户用电行为分析。 配用电环节要做到智能化,需要基于海量用户用电特征数据,如用电类别、时间、客户、行业、电压等级、气象、峰谷负荷等进行分析。通过FP-network算法挖掘不同用电行为特征间的关联规则,描述用电行为模式,实现面向用户服务的用电管理、有序用电,面向电力公司的台区负荷预测、用电调度,面向政府的工业发展趋势预测、电价制定等高级应用。 b. 电力系统故障分析。 电力系统的故障数据由用电信息采集系统、PMS、检修运维系统、ERP系统、GIS、气象信息系统(MIS)等组成,通常包括故障时间、地点、天气、故障类型、故障元件、损失、保护开关动作、恢复时间等一系列属性,通过FP-network充分挖掘历史数据多维属性间的关联关系,可以发现故障产生的规律,用于识别电网的薄弱环节、制订检修计划以及故障预警等,避免类似故障的再发生。 图9 FP-network在故障分析应用的流程图Fig.9 Flowchart of FP-network application in fault analysis c. 电力市场营销策略。 电力公司营销的数据库由售电量、交易电价、用户种类、气象信息、客户关系、客户满意度等所组成,应用FT-network,描述各种影响电量销售的外部因素与售电量、交易电价等之间的关联特征,可以进行需求预测、销售及收入预测,掌握营销业务重点工作,为电力市场营销提供辅助的决策信息。 d. 风光运行优化。 通过对风光发电系统历史运行数据的分析,可得特定工况下气象数据(风速、光照强度、温度等)与机组性能间的关联关系,从而对机组性能(可靠性、经济性、安全性等)进行客观、正确评估,辅助实现风电准确预测、风电场规划、制订出力调度计划等。 FP-network在智能电网的应用流程的步骤主要有数据采集、数据预处理、数据挖掘、关联规则分析及结果展示。其中,数据预处理包括噪声清洗、数据离散化处理、缺失值填补等。图9以电力系统故障分析为例说明应用的具体流程。 鉴于智能电网大数据发展的需要和目前关联规则挖掘算法存在的缺点,本文建立了适合智能电网应用的FP-network模型。所得到的主要结论如下: a. FP-network模型与FP-Tree模型相类似,将关联规则挖掘所需要的数据压缩到一个图上,但是FP-network图扩大了存储的事务规模,实际挖掘时需要以矩阵形式进行存储; b. 与FP-Tree模型相同,FP-network模型同样只能处理分类变量(即离散变量),因此需要预先对事务数据进行离散化; c. FP-network模型只需扫描1次原数据库,且以矩阵形式存储,尤其对于智能电网大型数据库而言,大幅降低了时间和空间的复杂度; d. FP-network模型方便被挖掘数据的更新和维护,因此提高了关联规则挖掘算法的效率; e. FP-network模型适合挖掘智能电网大数据,应用范围包括但不限于故障分析、营销策略制订、用电负荷研究、风电运行优化等。 参考文献: [1] 彭小圣,邓迪元,程时杰,等. 面向智能电网应用的电力大数据关键技术[J]. 中国电机工程学报,2015,35(3):503-511. PENG Xiaosheng,DENG Diyuan,CHENG Shijie,et al. Key technologies of electric power big data and its application prospects in smart grid[J]. Proceedings of the CSEE,2015,35(3):503-511. [2] 宋亚奇,周国亮,朱永利. 智能电网大数据处理技术现状与挑战[J]. 电网技术,2013,37(4):927-935. SONG Yaqi,ZHOU Guoliang,ZHU Yongli. Present status and challenges of big data processing in smart grid[J]. Power System Technology,2013,37(4):927-935. [3] AGRAWAL R,IMIELISKI T,SWAMI A. Mining association rules between sets of items in large databases[J]. Acm Sigmod Record,1993,22(2):207-216. [4] HAN T,KAMBER M. Data mining:concepts and techniques[M]. Beijing:Higher Education Press,2001:143-177. [5] SAVASMR A,OMICCINSKI E,NAVATHC S. An efficient algorithm for mining association rules[C]∥The 21th International Conference on VLDB. Zurich,Switzerland:Morgan Kaufmann Publishers Inc.,1995:432-444. [6] HAN J,PEI J,YIN Y. Mining frequent patterns without candidate generation[C]∥The 2000 ACM SIGMOD on Management of Data(SIGMOD 2000). Dallas,Texas,USA:ACM,2000:1-12. [7] TSENGV S,SHIE B E,WU C,et al. Efficient algorithms for mining high utility item sets from transactional databases[J]. IEEE Tran-sactions on Knowledge and Data Engineering(TKDE),2013,25(8):1772-1786. [8] 王守相,葛磊蛟,王凯. 智能配电系统的内涵及其关键技术[J]. 电力自动化设备,2016,36(6):1-6. WANG Shouxiang,GE Leijiao,WANG Kai. Main contents and key technologies of smart distribution system[J]. Electric Power Automation Equipment,2016,36(6):1-6. [9] 张东霞,苗新,刘丽平,等. 智能电网大数据技术发展研究[J]. 中国电机工程学报,2015,35(1):2-12. ZHANG Dongxia,MIAO Xin,LIU Liping,et al. Research on deve-lopment strategy for smart grid big data[J]. Proceedings of the CSEE,2015,35(1):2-12. [10] 薛振宇,胡航海,宋毅,等. 基于大数据分析的县公司综合评价策略[J]. 电力自动化设备,2017,37(9):199-204. XUE Zhenyu,HU Hanghai,SONG Yi,et al. Comprehensive evaluation based on big data analysis for county electric power company[J]. Electric Power Automation Equipment,2017,37(9):199-204. [11] 郝然,艾芊,肖斐. 基于多元大数据平台的用电行为分析构架研究[J]. 电力自动化设备,2017,37(8):20-27. HAO Ran,AI Qian,XIAO Fei. Architecture based on multivariate big data platform for analyzing electricity consumption behavior[J]. Electric Power Automation Equipment,2017,37(9):20-27. [12] 葛磊蛟,王守相,瞿海妮. 智能配用电大数据存储架构设计[J]. 电力自动化设备,2016,36(6):194-202. GE Leijiao,WANG Shouxiang,ZHAI Haini. Design of storage framework for big data of SPDU[J]. Electric Power Automation Equipment,2016,36(6):194-202. [13] 徐青山,王文帝,林章岁,等. 面向行业大数据特征挖掘的电力经理指数指标体系的建立与应用[J]. 电力自动化设备,2015,25(7):15-21. XU Qingshan,WANG Wendi,LIN Zhangsui,et al. Establishment and application of EMI indicator system orienting to massive industrial data mining[J]. Electric Power Automation Equipment,2015,25(7):15-21. [14] 王德文,孙志伟. 电力用户侧大数据分析与并行负荷预测[J]. 中国电机工程学报,2015,35(3):527-537. WANG Dewen,SUN Zhiwei. Big data analysis and parallel load forecasting of electric power user side[J]. Proceedings of the CSEE,2015,35(3):527-537.2 关联规则挖掘算法的比较


3 算例分析








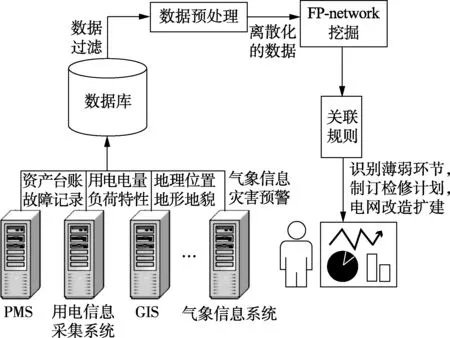
4 在智能电网中的其他应用
5 结论
