OpenAI发布训练 实体机器人的最新模拟环境
2018-05-14


最近,OpenAI发布了8个模拟机器人环境,以及一个事后经验回放(Hindsight Experience Replay)的基线实现,所有这些都是基于过去一年的研究而开发,并已经使用这些环境对在物理机器人上运行的模型进行训练。同时,OpenAI还发布了一系列用于机器人研究的请求。
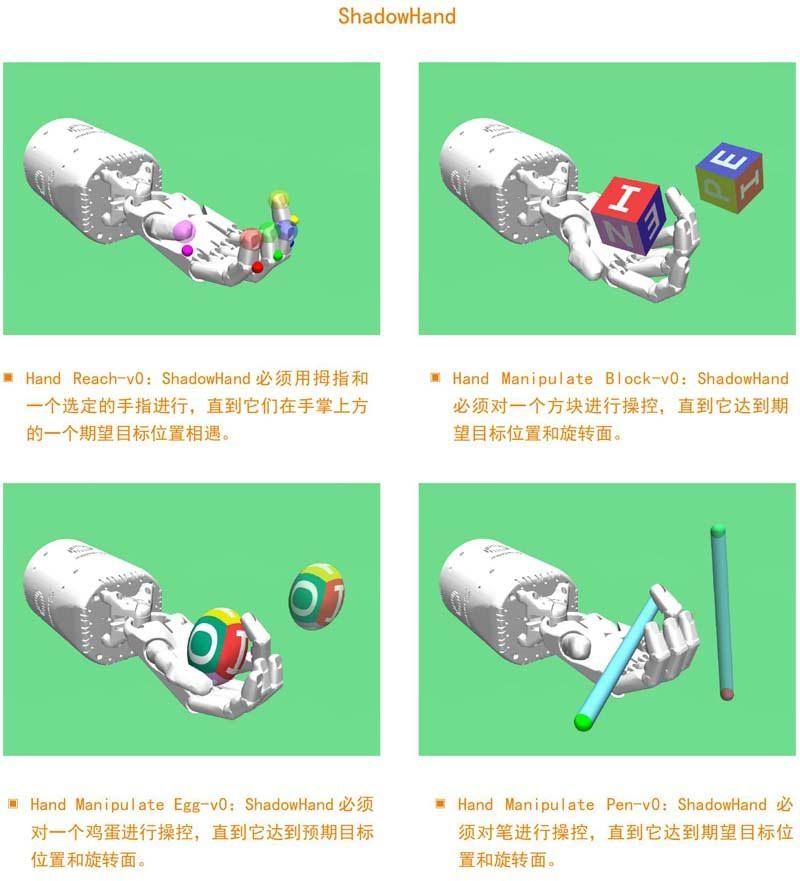
该版本包括四个使用了Fetch研究平台的环境和四个使用了ShadowHand机器人的环境。可以说,这些环境中所包含的操作任务要比目前在Gym中可用的MuJoCo连续控制环境要困难得多,因为所有这些现在都可以使用最近发布的算法(如PPO)得以轻松解决。此外,新发布的环境使用真实机器人模型,并要求智能体解决实际任务。
环境
该版本配备了8个使用MuJoCo物理模拟器的Gym机器人环境。这些环境是:Fetch(4个)和ShadowHand(4个)。
目标
所有新任务都有一个“目标”的概念,例如在滑动任务中冰球的期望位置,或用手在方块操控任务中操控方块的期望方向。默认情况下,如果没有达到预期目标,所有环境都会使用-1的稀疏奖励,如果达到预期目标(在一定的范围内),则为0。这与旧的Gym连续控制问题中所使用的形状奖励形成鲜明对比,例如带有形状奖励的Walker2d-v2。
OpenAI还为每个环境引入了一个密集奖励的变体。同时,还认为稀疏奖励在机器人应用中更具实际性,并鼓励每个人使用稀疏奖励变体。
事后经验回放
除了这些新的机器人环境外,OpenAI还发布了事后经验回放(Hindsight Experience Replay)(简称为HER)的代码,这是一种可从失败中汲取经验教训的强化学习算法。研究结果表明,仅需要稀疏奖励,HER便可以从大多数新机器人问题中学习成功的策略。下面,OpenAI还展示了未来研究的一些潜在方向,从而可以进一步提高HER算法在这些任务上的性能表现。
理解HER
要想理解HER的作用是什么,我们先来看看FetchSlide的上下文,这是一个需要学习如何在桌子上滑动冰球并击中目标的任务。第一次尝试很可能不会成功,除非我们很幸运,否则接下来的几次尝试也未必会成功。典型的强化学习算法不会从这样的经验中学到任何东西,因为它们只获得一个不包含任何学习信号的恒定奖励(在这种情况下为-1)。
HER形式的关键洞察力在于直觉上人类是怎么做的:尽管我们在某个特定目标上还没有取得成功,但我们至少实现了一个不同的成果。那么我们为什么不假设想要实现的目标就是开始时的目标,而不是我们最初设定的目标?通过这种替代,强化学习算法可以获得学习信号,因为它已经实现了一些目标,即使它不是我们原本想达到的目标。如果我们重复这一过程,我们最终将学会该如何实现任意目标,包括我们真正想要实现的目标。
这种方法使得我们去学习如何在桌子上滑动一个冰球,尽管奖励是完全稀疏的,尽管实际上我们可能从未在早期达到过预期目标。我们将这种技术称为事后经验回放,因为它会在事件结束后,对事件中选择的目标进行经验回放(在诸如DQN和DDPG之类的off-policy强化学习算法中经常使用的技术)。因此,HER可以与任何off-policy强化学习算法结合使用(例如,HER可以与DDPG结合,我们将其写为“DDPG + HER”)。
结果
我们发现HER在基于目标的、具有稀疏奖励的环境中运行得非常好。我们在新任务中对DDPG + HER和vanilla DDPG进行了对比。这种对比涵盖了每个环境的稀疏和密集奖励版本。
带有稀疏奖励的DDPG + HER明显优于其他所有配置,并且仅需要很少的奖励,便可以从这项具有挑战性的任务上学习成功的策略。有趣的是,带有密集奖励的DDPG + HER也能够学习,但表现性能较差。在这两种情况下,vanilla DDPG大多不能进行学习。我们发现这种趋势在大多数环境中都是正确的。
Requests for Research:
HER版本
尽管HER是一种很有发展前景的方式,可以用像文中所提出的机器人环境那样的稀疏奖励来学习复杂的、基于目标的任务,但仍有很大的提升空间。与最近发布的Requests for Research 2.0要求类似,我们对于如何具体改进HER和通用强化学习有一些想法。
自动事后目标创建(Automatic hindsight goal creation):我们现在有一个硬编码策略以选择我们想要替换的事后目标。如果这个策略可以被学习,那将是很有趣的。
无偏差HER:目标替换以无原则的方式改变了经验分配。这种偏差在理论上会导致不稳定性,尽管我们在实践中并没有发现这种情况。不过,例如通过利用重要性抽样,可以推导出HER的无偏差版本。
HER + HRL:将HER与层级强化学习(HRL)中的最新想法进一步结合起来会很有趣。它不仅可以将HER用于目标,还可以应用于由更高级别策略生成的操作中。例如,如果较高级别要求较低级别实现目标A,但却实现了目标B,则我们可以假设较高级别最初就是要求我们实现目标B。
更丰富的值函数:将最近的研究进行扩展将会非常有趣,并在附加的输入上(如折扣因子或成功阈值)调整值函数。
更快的信息传播:大多数off-policy深度强化学习算法使用目标网络来稳定训练。然而,由于变化需要时间来进行传播,这将会对训练的速度产生影响,并且我们在实验中注意到,它往往是决定DDPG + HER学习速度的最重要因素。研究其他不引起这种减速的稳定训练的方法是很有趣的。
HER +多步返回:由于我们替换了目标,因此在HER中所使用的经验极其off-policy。这使得它很难与多步返回一起使用。但是,多步返回是可取的,因为它们允许更快地传递关于返回的信息。
on-policy HER:目前,由于我们取代了目标,所以HER只能与off-policy算法一起使用,这使得经验极其off-policy。然而,像PPO这样的最新技术算法表现出非常吸引人的稳定性特征。研究HER是否可以与这种on-policy算法相结合是非常有趣的,例如通过重要性采样,在这方面已经有一些初步结果。
具有高频行动的强化学习:目前的强化算法对采取动作的频率非常敏感,这就是为什么在Atari上通常使用跳帧技术。在连续控制领域,随着所采取行动的频率趋于无穷大,性能趋于零,这是由两个因素造成的:不一致的探索,以及引導更多时间来向后传播有关返回信息的必要性。
将HER与强化学习的最新进展的结合:最近有大量研究改进了强化学习的不同方面。首先,HER可以与优先经验回放、分布式强化学习、熵正则化强化学习或反向课程生成相结合。
使用基于目标的环境
引入“目标”的概念需要对现有的Gym API进行一些反向兼容的更改:
所有基于目标的环境都使用gym.spaces.Dict观察空间。预期环境包含一个智能体试图实现的期望目标(desired_goal)、其目前达到的目标(achieved_goal),以及实际观察(observation),例如机器人的状态。
我们展示了环境的奖励函数,从而允许通过改变的目标以对奖励进行重新计算。这使得对目标进行替换的HER风格的算法成为可能。