近阈值非预充静态随机存储器
2018-05-08蔡江铮陈黎明
蔡江铮, 黑 勇, 袁 甲, 陈黎明
(1. 中国科学院微电子研究所 智能感知中心,北京 100029;2. 中国科学院大学 微电子学院,北京100029)
近阈值非预充静态随机存储器
蔡江铮1,2, 黑 勇1,2, 袁 甲1,2, 陈黎明1,2
(1. 中国科学院微电子研究所 智能感知中心,北京 100029;2. 中国科学院大学 微电子学院,北京100029)
为了降低静态随机存储器在处理声音和视频数据时的功耗,提出一款新型的非预充单元.相比常规6管和8管单元,其读操作消除了预充机制,抑制了无效的翻转,因此功耗得到显著优化.本单元通过多阈值技术,在保证低电压区域读噪声容限的同时也加强了数据读出的能力.而且通过引入切断反馈环的机制,有效地提升了单元写能力.此外,在存储阵列中应用半斯密特反相器,大幅地提升了静态随机存储器读操作的性能.基于SMIC 130 nm 工艺,分别实现容量为 6 kbit 的非预充和常规8管静态随机存储器测试芯片.测试和仿真数据表明,这种新型存储器相比常规8管存储器在功耗的抑制上具有显著优势,可以作为低功耗应用的良好选择.
静态随机存储器;非预充;声音和视频;低功耗
随着医疗电子、可穿戴设备和物联网等低功耗应用的快速发展,功耗取代性能逐步成为芯片设计中最核心的指标[1].静态随机存储器(Static Random Access Memory,SRAM)占据了芯片相当大比例的功耗,因此静态随机存储器功耗的降低成为芯片功耗优化的关键所在.近亚阈值技术作为最有效的手段之一,被广泛应用于静态随机存储器的低功耗设计中[1-7].在近亚阈值区,经典6管静态随机存储器受制于稳定性和漏电等问题不能正常工作,因此8管静态随机存储器成为低功耗芯片的首选[3].为了进一步降低静态随机存储器的读写功耗,在某些特定应用场景中,研究者不断发掘存储在静态随机存储器中的诸如声音和视频等特定数据的特点进行电路设计从而获得功耗优化.文献[8]基于视频数据的特点,混合使用8管和6管单元,使得静态随机存储器工作在更低的电压下.文献[9]也从视频数据的特点出发,将数据进行编码,同时将写位线设定为最小翻转的情况,从而降低视频数据写入的功耗.但是这些方法都会引入额外的电路开销.而且,基于常规8管单元设计的静态随机存储器都采用如图1所示的预充机制实现读操作:在准备阶段,预充信号为低电平,读位线被预充到高电平;然后在判定阶段,字线信号打开,读位线的状态由单元内部数据决定.然而,预充机制的存在使静态随机存储器在处理声音和视频数据时产生无效功耗[10].声音和视频中存在大量相同数据,导致静态随机存储器中不同单元的存储内容相同,因此当读取存储内容时,会获得连续的“0”或“1”数据.连续“0”数据的读出在静态随机存储器中会引起不必要的翻转.文献[11]通过将大多数的“0”数据转变为“1”数据的方式达到节省功耗的目的.然而,这种方法并不能完全解决连续读“0”带来的功耗开销问题.基于以上问题,笔者提出非预充的单元结构,通过消除预充机制实现对声音和视频数据的低功耗处理.
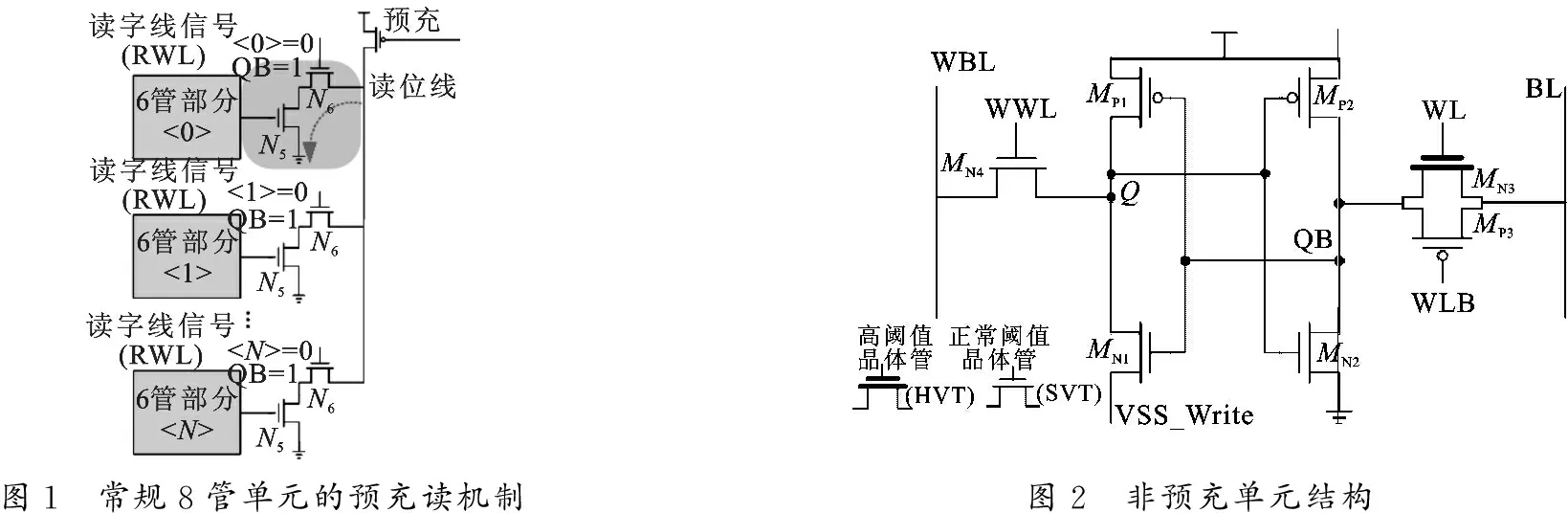
图1 常规8管单元的预充读机制图2 非预充单元结构
1 非预充单元结构
非预充单元的结构如图2所示.晶体管MP1,MP2,MN1和MN2组成背靠背反相器,实现数据保持功能;MP3和MN3组成传输门,实现数据读写传导功能;MN4为写操作晶体管,只在写操作时有效,实现写能力的提升.在读操作时,互补字线信号写线信号(WL)和写字线反相信号(WLB)被同时使能,而写字线信号(WWL)处于无效状态,此时单元右侧单向开启,内部反相数据(QB)通过传输门决定位线的最终状态.因此,位线(BL)不需要被提前预充至高电平,预充机制可以被消除.在写操作时,字线信号WWL,WL,WLB全部被使能,单元两侧全部开启,写位线信号(WBL)和位线(BL)接收写驱动电路的输入数据,实现数据的写入.但是为了确保单元读操作时在近阈值区的抗干扰能力,其传输门的传导能力不能设计过强,因此位线(BL)不能轻易改写内部数据,导致写能力被弱化.为了增强写能力,在单元中引入了切断反馈环的方式.在写操作时,其中一个反相器的地(VSSWrite)被悬空,所以位线(BL)能相对轻松地改写内部数据.与此同时,当反馈环被切断时,晶体管MN4能迅速改变右侧的反相器的状态,从而进一步加强写能力.
2 功耗的优化
基于前述分析,常规单元结构受制于预充机制,在处理连续“0”数据时存在无效的翻转,具体的过程如图3所示.在读取连续“0”的情境中,前一个周期完成后,位线会被重新预充到高电平,然后当前周期再开始新的一轮位线放电过程.实质上,由于相邻周期读取的数据是一致的,这个不断翻转的过程是无意义的.这种不必要的翻转一直持续到读“1”时刻的来临.为了解决这个问题,非预充单元消除了无效翻转,读操作的逻辑如图4所示.在第1次读取“0”数据时,位线进行一次翻转,此后每次“0”的读取都不再进行翻转,一直持续到“1”的读取才又一次进行翻转.因此,连续“0”数据的读取只需要一次充放电的开销.随着读“0”时间的增加,整体功耗的优化就会很显著.
定量对比不同单元间的功耗,将常规单元读操作时位线在每个周期(T)中一次充电和放电过程中产生的功耗设定为P0,则N个读“0”周期消耗的总能量是NTP0.对于非预充单元而言,N个周期中位线只有一次充电和放电的过程,等效为常规单元一个周期的进程,其余N-1 个周期位线不进行任何翻转.同时,在翻转周期中非预充单元产生的功耗与常规8管单元近似,都为P0.假定不翻转周期的功耗为P1,则非预充单元在N个周期中总能量的消耗为TP0+ (N-1)TP1.由于P1远远小于P0,所以非预充单元的能量消耗可以近似为常规单元的 1/N.随着读“0”周期数的增多,非预充单元相比常规单元在功耗开销方面优势越来越显著.

图3 常规8管单元的读过程图4 非预充单元的读过程
在0.5 V电压下,使常规8管单元的读位线在每次读操作时都进行翻转,仿真其翻转功耗P0;使非预充单元的位线不翻转,仿真其静态功耗P1.在不同工艺角下,非预充单元的功耗都显著降低,如图5所示.

图5 不同工艺角下P0和P1的比较图6 功耗优化比例随读“0”个数的变化趋势
图5是对单次读操作的仿真.如果按照图4所示的实际情况工作: 假设存在N个读“0”周期,分别对8管和非预充单元进行功耗分析,并以8管单元功耗和非预充单元功耗的比值来衡量优化比例,则这段时间内的功耗优化如图6所示.随着N的增大,每个工艺角下的功耗优化效果都呈增强趋势.当然,优化效果也不能无限增长,它受两个因素制约: 首先受应用中“0”数据多少决定; 其次还受静态随机存储器阵列中挂接的单元数目的影响.当阵列中单元数目确定后,即使应用中存在的“0”的个数大于单元数,功耗的优化比例也只能被限定在固定的范围内.此外,由于预充机制被消除,静态随机存储器可以省去预充电路,从而降低功耗.而且由于预充电路的节省,时钟电路的负载和尺寸也可以被优化,进而使功耗进一步降低.
3 读操作分析

图7 非预充单元读能力
然而,非预充单元无法隔离读写操作,读操作时外界噪声仍然可以通过传输门进入单元内部,从而影响已有数据的稳定性,因此相比8管结构,其读噪声容限存在劣势[12].为了缓解这种劣势,非预充单元通过两种方式加强读噪声容限:加大单元中背靠背反相器的尺寸,保证即使在外界噪声被引入的状况下,数据还能稳定保持.但是,这会牺牲部分写能力.减小噪声耦合路径的强度,采用高阈值技术弱化传输门的导通能力.当传输门由高阈值晶体管组成时,此时路径抑制噪声的效果最佳.但是这也减弱了内部数据改变位线状态的能力,影响读出效果.图6展示了单个非预充单元的读出能力,其中原始读“0”操作表示传输门晶体管都为高阈值晶体管时的读“0”的能力,优化读“0”操作表示传输门是混合阈值时的读能力情况.由图7可知,在原始读状态中,非预充单元读“1” (Q=1,QB为“0”)的能力远强于读“0” (Q=0,QB为“1”)的能力.若传输门全部采用高阈值晶体管,则虽然抑制噪声进入单元内部的效果变强,但同时也使得内部数据传输到位线的能力大大减弱,因此针对读“1”与读“0”的情况,进行混合阈值的使用.在优化过程中,将传输门中的N沟道金属氧化物半导体(N-channel Metal Oxide Semiconductor,NMOS)采用高阈值晶体管,P沟道金属氧化物半导体(P-channel Metal Oxide Semiconductor,PMOS)采用正常阈值晶体管.优化后的读“0”操作的变化时间相比原始操作更短,提升了读操作的性能.这既保证了单元对位线的改写能力,同时又弱化了噪声传输路径,有效地提升了读操作的稳定性.此外,由于非预充单元是单端结构,外部噪声耦合进入单元内部的路径只有一条,与常规6管单元相比,引入噪声的概率降低,噪声容限相对提高.但是与常规8管单元相比,非预充单元还是会引入噪声的,故读噪声容限仍然有一定的恶化.图8表示在 0.5 V 电压下,常规6管结构、非预充单元和常规8管结构在 10 000 次蒙特卡罗仿真中的读噪声容限.

图8 不同单元间读噪声容限比较图9 不同电压下3个单元3σ标准下的读噪声容限
非预充单元的读噪声容限是0.12 V,相比常规8管结构和6管结构分别降低了36%和提升了71%.此外,以上的噪声容限都是基于最恶劣的静态情况进行分析的,在实际应用中情况会有所缓和,读操作的稳定性还会进一步增强.由于声音和视频数据中存在大量连续的“0”和“1”,所以位线跳变频率较低,从而引入的噪声相对较少,这有利于读噪声容限的提升.而且,当位线状态与单元内部数据一致时,单元的读噪声容限可以达到与常规8管结构相似的能力,这种情况在此类应用中出现的概率很高.所以,非预充单元的读噪声容限在 0.5 V 的电压下是非常乐观的.为了进一步说明不同电压下3个单元噪声容限的情况,用3σ标准进行评判,如图9所示.随电压下降,常规8管和非预充单元读噪声容限充足,而常规6管单元恶化严重.

图10 非预充单元的阵列结构及反相器电压传输特性曲线
与此同时,非预充单元改变位线状态的能力不仅受到传输门和背靠背反相器强度的影响,也受到位线负载的制约.因此,在组成阵列时,每根位线上连接的单元数受到限制.而且,由于单元读“1”能力强于读“0”能力,可以将连接位线的反相器进行特殊设计用以平衡读出能力.反相器的电压传输特性曲线可以被设计得更偏向低电平,从而有利于“0”数据的读取.整个阵列结构如图10(a)所示,每根位线连接16个非预充单元.而反相器采用半斯密特反相器,与普通反相器相比,电压传输特性线向低电平的偏移更加显著,如图10(b)所示.因此“0”数据读出时,位线的充电过程会被快速感知,增强了读能力.
4 写操作分析
在单元尺寸设计中,读噪声容限的提升是首要目的,相应地,写噪声容限被弱化.为了加强写能力,采用切断背靠背反相器反馈环的机制,如图2所示.在写操作时,左侧反相器的地可以浮动,从而打断反馈环使内部数据更容易被改写.同时多个单元共用VSSWrite信号,可以有效地降低电路开销.为了保证写入数据的正确性,VSSWrite信号需要比字线信号提前.在 0.5 V 电压下,最坏的写情况出现在SNFP工艺角中.此时,如果VSSWrite不浮动,则写噪声容限只有 6 mV,意味着在最坏情况中,单元不能有效操作在 0.5 V 电压下.当采用优化的写机制后,有效地提升了写能力,使得单元在 0.5 V 电压下正常工作.
5 流片与测试
基于中芯国际集成电路制造(上海)公司(Semiconductor Manufacturing International Corporation,SMIC) 130 nm 工艺,设计了容量为 6 kbit 的非预充静态随机存储器,单元版图如图11所示,面积为 5.53 μm2,而工艺厂商提供的6管单元,面积为 3.014 μm2,因此本单元面积增加83%.这是因为非预充单元控制信号较多,而且还使用正常设计规则检查(DRC规则),而工艺厂商的单元使用特殊设计规则检查.因此,如果去除规则的差别,则面积的增长会有所缓和.

图11 单元版图图12 0.42V电压下非预充静态随机存储器的功耗
笔者还制造了相同容量的常规8管静态随机存储器作为比对.在室温下,非预充静态随机存储器的最低工作电压为 0.42 V,当它处理“0”和“1”不断变化的数据时,其位线在不断地翻转,此时的电流为 18.6 μA,如图12所示.从图12的波形中能看出,读“0”操作相比读“1”操作的能力弱.但是,非预充静态随机存储器读“0”和读“1”时消耗的电流相等,而与之对比的常规8管静态随机存储器读“0”的电流比读“1”高19%左右,所以非预充静态随机存储器对读“0”操作有19%左右的功耗优化.
随着读“0”的个数增多,非预充静态随机存储器的功耗逐渐降低,最终在标准测试算法(Memory Scan算法)的作用下,测试激励中具有256个连续的“0”数据,非预充静态随机存储器的功耗不断降低,如图13所示.

图13 非预充静态随机存储器功耗随读“0”个数的变化图14 非预充和常规8管单元的功耗比较
但是,随着连续“0”个数增多到一定程度的数量后,整体功耗不再优化.首先是因为位线长度为16个,所以优化效果不能无限增长; 其次是因为连续读“0”的操作导致读写电路的功耗在整体功耗中的占比下降,此时其余电路的功耗占据主要地位,所以更多的“0”也不再会明显地降低功耗了.但是,非预充静态随机存储器消除预充机制后,其全局和局部预充电路也可以被随之消除,与此同时,预充电路的消除也可以导致时钟负载的降低,因此时钟电路尺寸也可以得到进一步优化,进而使得在Memory Scan算法下,非预充静态随机存储器是常规8管静态随机存储器功耗的48%左右,如图14所示.
6 结 束 语
通过发掘特定数据的特点,笔者提出非预充静态随机存储器单元,消除预充机制来降低功耗.测试和仿真结果表明,非预充单元在功耗优化方面相比常规8管单元更具竞争力.同时,多阈值技术和半斯密特反相器的引入,不仅保证了单元在低电压区域的稳定性,同时也加强了单元的读出能力.此外,通过切断反馈环的方式有效地提升了单元的写能力.在SMIC 130 nm 工艺下, 非预充静态随机存储器能够稳定工作在 0.42~ 1.20 V 的电压范围内,功耗仅为常规8管静态随机存储器的48%左右.
参考文献:
[1] CAI J Z, ZHANGA S M, YUAN J, et al. 320 mV, 6 kb Subthreshold 10T SRAM Employing Voltage Lowering Techniques[J]. Journal of Semiconductors, 2015, 36 (6): 065007.
[2] DO A T, LEE Z C, WANG B, et al. 0.2 V 8T SRAM with PVT-aware Bitline Sensing and Column-based Data Randomization[J]. IEEE Journal of Solid-State Circuits, 2016, 51(6): 1487-1498.
[3] KIM T H, LIU J, KIM C H, et al. A Voltage Scalable 0.26 V, 64 kb 8T SRAM withVminLowering Techniques and Deep Sleep Mode[J]. IEEE Journal of Solide-State Circuit, 2009, 44(6):1785-1795.
[4] LU C Y, CHUANG C T, JOU S J, et al. A 0.325 V, 600-kHz, 40-nm 72-kb 9T Subthreshold SRAM with Aligned Boosted Write Wordline and Negative Write Bitline Write-assist[J]. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 2015, 23(5): 958-962.
[5] ATIAS L, TEMAN A, GITERMAN R, et al. A Low-voltage Radiation-hardened 13T SRAM Bitcell for Ultralow Power Space Applications[J]. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 2016, 24(8):2622-2633.
[6] WEN L, CHENG X, ZHOU K, et al. Bit-interleaving-enabled 8T SRAM with Shared Data-aware Write and Reference-based Sense Amplifier[J]. IEEE Transactions on Circuits and Systems Ⅱ: Express Briefs, 2016, 63(7): 643-647.
[7] WANG B, NGUYEN T Q, DO A T, et al. Design of an Ultra-low Voltage 9T SRAM with Equalized Bitline Leakage and CAM-assisted Energy Efficiency Improvement[J]. IEEE Transactions on Circuits and Systems Ⅰ: Regular Papers, 2015, 62 (2):441-448.
[8] CHANG I J, MOHAPATRA D, ROY K. A Priority-based 6T/8T Hybrid SRAM Architecture for Aggressive Voltage Scaling in Video Applications[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2011, 21(2): 101-112.
[9] DO A T, ZEINOLABEDIN S M A, KIM T T. A 0.3 pJ/Access 8T Data-aware SRAM Utilizing Column-based Data Encoding for Ultra-low Power Applications[C]//Proceedings of the 2016 IEEE Asian Solid-State Circuits Conference. Piscataway: IEEE, 2017:173-176.
[10] NOGUCHI H, IGUCHI Y, FUJIWARA H, et al. A 10T Non-precharge Two-port SRAM for 74% Power Reduction in Video Processing[C]//Proceedings of the IEEE Computer Society Annual Symposium on VLSI: Emerging VLSI Technologies and Architectures. Piscataway: IEEE, 2007:107-112.
[11] FUJIWARA H, NII K, NOGUCHI H, et al. Novel Video Memory Reduces 45% of Bitline Power Using Majority Logic and Data-bit Reordering[J]. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 2008, 16(6): 620-627.
[12] CHIEN Y C CHIANG I H, WANG J S. Sub-threshold SRAM Bit Cell pnn forVDDminand Power Reduction[J]. Electronics Letters, 2014, 50(20): 1427-1429.
Near-thresholdnon-prechargedSRAM
CAIJiangzheng1,2,HEIYong1,2,YUANJia1,2,CHENLiming1,2
(1. Smart Sensing R&D Centre, Institute of Microelectronics of Chinese Academy of Sciences, Beijing 100029, China; 2. School of Microelectronics, Univ. of Chinese Academy of Sciences, Beijing 100029, China)
In order to save the power consumed by the static random access memory when it deals with voice or video data, a novel memory cell is proposed which eliminates the precharge mechanism in the read operation, thus suppressing the invalid power compared with the conventional 6T and 8T cell. Furthermore, multiple threshold technology is employed in the cell, which not only guarantees the read static noise margin, but also enhances read ability. In addition, a Schmitt trigger based inverter is also applied in the cell array and hence it improves the read speed. Two memories including the proposed one and the conventional one are fabricated in 130 nm process, respectively. Test results indicate that the proposed memory is excellent in reducing power consumption compared with the conventional 8T memory, and hence it becomes a suitable choice for the low power chips.
static random access memory; non-precharged; voice and video; low power
2017-02-14
时间:2017-06-29
中国科学院先导专项资助项目(XDA06020401); 国家自然科学基金资助项目(61306039)
蔡江铮(1989-),男,中国科学院微电子研究所博士研究生, E-mail:caijiangzheng@ime.ac.cn.
http://kns.cnki.net/kcms/detail/61.1076.TN.20170629.1735.038.html
10.3969/j.issn.1001-2400.2018.01.019
TN43
A
1001-2400(2018)01-0106-06
(编辑: 郭 华)
