一种基于Spark的大数据匿名化系统实现
2018-05-04卞超轶朱少敏周涛
卞超轶,朱少敏,周涛
(1.北京启明星辰信息安全技术有限公司,北京 100193;2.北京邮电大学,北京 100876)
1 引言
电力行业大数据分析与应用促进了电力系统运行方式、管理体制、发展理念和技术路线等方面的重大变革,成为智能电网和全球能源互联网创新发展的重要技术支撑。电力大数据分析涉及电力企业核心数据以及用户隐私数据,具有实时性更高、数据敏感度更强等特点,其数据安全与隐私保护的需求更加迫切,安全技术要求更高。例如,为了分析用户用电行为,需要将用电数据提供给内外部分析人员,但是原始数据中包含涉及用户隐私部分,一旦大规模泄露并被不法分子利用,存在巨大安全隐患;在电力企业运行管理方面,目前广泛利用大数据技术实现电源电网规划、发输变电设备状态评估、配电网供电可靠性等研究与应用,这些海量异构大数据是电力企业内部关键的运行管理数据,关系到电力企业的安全稳定运行,大规模研究与利用对数据处理、使用和存储等方面的信息安全带来了新挑战;防范大数据环境下电力系统核心数据和用户敏感数据的采集、上传及传播过程中的敏感数据泄露风险,迫切需要研究适应电力业务大数据分析架构的大数据去隐私化处理理论、模型和算法,形成大数据多层次全方位敏感数据保护基础环节。
数据匿名化是指以隐私防护为目的而对数据敏感部分进行特殊处理的过程,典型处理手段包括加密、单向散列、消去、掩盖和模糊泛化等,以避免数据在公开或共享时发生隐私泄露。分组匿名化(group-based anonymization)是一类经典数据匿名化技术框架,它通过构造匿名数据分组使得组内的各条数据无法互相区分,从而隐藏数据对应的用户身份。本文设计并实现了一种基于Spark实现的大数据匿名化系统,利用分布式内存计算来提高计算处理效率,支持Hadoop平台多种常用数据格式,如HDFS文件、Hive表等,并对系统实现的效果进行了测试验证及性能评估。
2 相关工作
2.1 Hadoop平台
Hadoop[1]是由Apache负责开发及维护的开源软件框架,主要目标是提供对大数据分布式存储及计算处理的支持。Hadoop的核心是分布式文件系统HDFS与分布式计算引擎MapReduce。
Spark[2]是一种分布式内存计算引擎,相比于MapReduce,启用了内存分布数据集,将计算任务中间结果保存在内存中,避免了 MapReduce计算处理中利用HDFS中转而带来的大量磁盘I/O,大幅提高并行计算效率。在存储方面,Spark沿用HDFS,实现对 Hadoop平台上的多种数据管理访问直接支持。
2.2 分组匿名化
传统数据匿名化方法仅仅通过去除数据中的身份信息(例如身份证号、姓名等)达到信息隐匿效果,但是仍可利用一些其他信息来定位识别个体。例如,表1中虽然没有包含身份信息,但是仍可以根据其中的非敏感信息(年龄、国籍及邮编)推断识别出具体的个人,从而造成用户用电量这类隐私敏感信息的泄露。这些可以被用于识别个体身份的非敏感信息被称为准标识符(quasi-identifier)。数据匿名化技术正是通过对数据中的这些准标识符进行处理以达到隐私保护的效果。

表1 包含敏感信息的数据
分组匿名化是一类经典数据匿名化技术,其核心思想是通过构造匿名记录组,使得同一组内的多条数据难以相互区分。k-匿名化(k-anonymity)[3]要求处理后的数据中存在的任意准标识符取值的组合都与至少 k条记录匹配。匿名化处理的手段有泛化和隐藏:泛化是指将属性的取值进行模糊替换处理,比如将“28”替换成“<30”,将“中国”替换成“亚洲”等;隐藏是指将属性值隐去,例如使用“*”替换。表2给出了对表1数据经过4-匿名化处理后的一种结果。总共12条数据形成了3组,每组内的4条数据拥有完全相同的准标识符,无法互相区分。

表2 4-匿名化示例
k-匿名化有缺陷,如表2中最后一组敏感属性取值相同,这样仍然暴露了隐私信息,因此l-多元化(l-diversity)[4]要求每种准标识符组合对应数据至少有l种不同敏感属性值。表3展示了对表1数据进行 3-多元化处理后的结果,它保证了每组敏感属性至少有3种不同的取值。
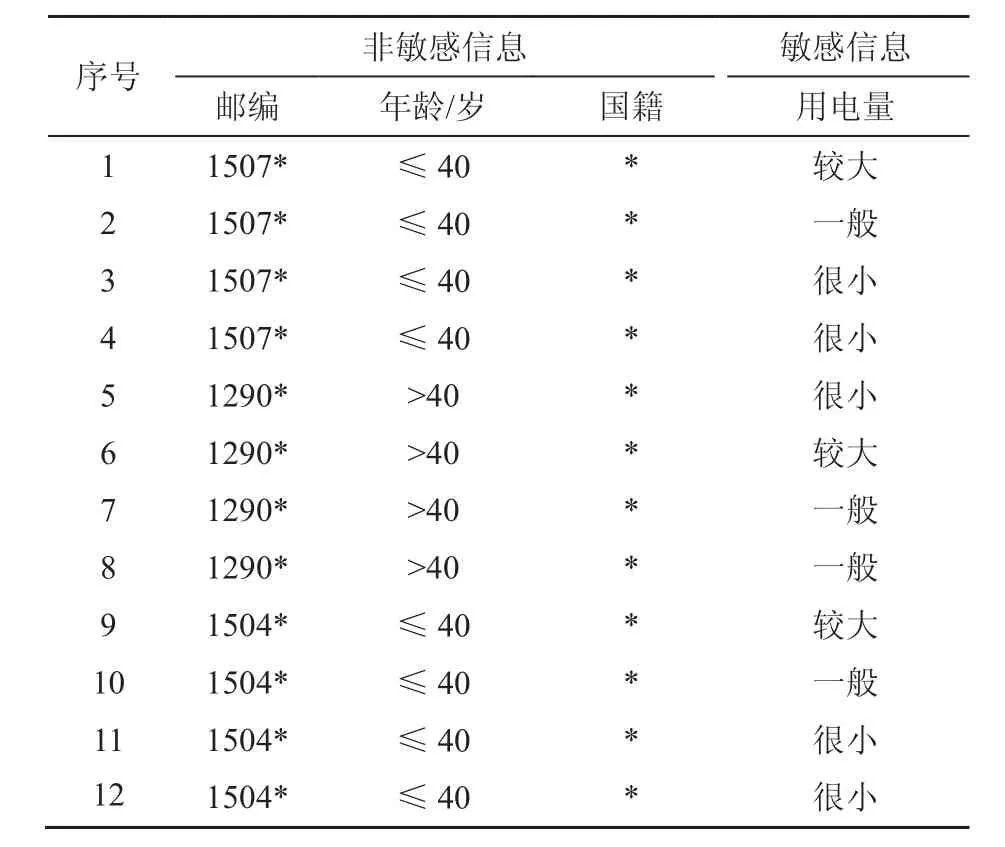
表3 3-多元化示例
k-匿名化和l-多元化是广泛应用的分组匿名化框架,已经有相应算法被提出以满足隐私要求[5],也有适用于小规模数据的开源工具发布[6],但是针对大数据场景仅有一些利用MapReduce来并行匿名化处理过程的工作[7]。为了满足电力大数据分析实际安全需求,本文设计了基于分布式内存计算引擎Spark开发,支持对以HDFS文件、Hive表等格式存储于 Hadoop平台的数据进行高效匿名化处理的系统,满足分组匿名化的隐私要求,实现数据公开及共享时的有效隐私防护。
3 系统实现
3.1 匿名化算法
本系统采用Mondrian算法[8]来实现数据匿名化。核心思想是先将所有准标识符对应的属性完全模糊化,这种情况下所有数据条目都是相同的,然后逐轮选取一个属于准标识符的属性增加公开信息,对数据进行不断划分,并确保划分出的任意子集包含的数据条目数均不小于k,也就是保证k-匿名化要求被满足。算法每轮迭代中都会选取构成准标识符的一个属性对数据进行划分,循环迭代直至不能再划分,即无论如何继续划分都会造成某个子集不再满足 k-匿名化要求。数据属性有两种类型:数值属性和类别属性。前者的划分是通过选取中间值(或中位数)对数据进行二分,而后者则是根据可取的具体类别数对数据进行划分(二分或多分,由类别属性的取值数决定)。
图1给出了一个对包含年龄、邮编这两个数值属性的数据集使用 Mondrian算法达到 2-匿名化要求的处理过程示例。图1(a)为数据分布情况,以“★”符号表示数据条目。初始数据中的年龄及邮编属性被完全模糊化,例如均以“*”表示。假设首先选择邮编这一属性进行数据划分,则结果如图1(b)所示。这时位于图1(b)左侧的数据子集的邮编属性可由初始的“*”表示变化为“≤27K”,而右侧的数据子集的邮编属性变化为“>27K”。然后对位于图1(b)左侧的数据子集选择年龄这一属性再次进行划分,结果如图1(c)所示。相应地,图1(c)左下方数据的年龄属性由初始的“*”变化为“≤60”,而左上方数据的年龄属性变化为“>60”。同样对位于图1(c)右侧的数据子集也选择年龄这一属性进行再划分,结果如图1(d)所示。这样图1(d)右下方数据的年龄属性变化为“≤62”,图 1(d)右上方数据的年龄属性变化为“>62”。此时不能再进行任何划分,否则会破坏2-匿名化要求。最后数据被划分为4个分组,每个分组内的数据无法互相区分。例如图1(d)中左上方的两条数据的年龄属性均为“>60”,邮编属性均为“≤27K”。
上述的Mondrian算法在简单修改后即可支持l-多元化。具体来说,在每次数据划分时不检查划分出的子集所包含的数据条目数,而改为检查划分出的数据子集是否满足 l-多元化要求。如果满足就继续递归划分,否则就回滚该次划分。
3.2 算法复杂度
Mondrian匿名化算法应用于仅包含数值属性的数据集时的工作过程与kd树的构造过程相同,所以具有相同的计算复杂度,即O(nlogn),其中n为总数据集大小。而按类别属性进行划分时,只需要遍历一遍相应数据即可,与数值属性时按中位数二分的计算复杂度是相同的(均为 O(k),这里k为要划分的数据集大小);划分后形成的子集数虽然有差别,但是对于总体计算复杂度的影响只体现在常数系数上。因此,Mondrian算法应用于一般数据集的计算复杂度仍为 O(nlogn),具有良好的可扩展性,适用于大数据场景。
3.3 实现细节
(1)数值类型的划分实现方式
Mondrian算法对数值属性划分时采取的方法是按中位数进行二分。由于在大数据规模下使用快速排序再定位中位数计算,时间复杂度较高,且线性时间复杂度的求中位数算法在 Spark上实现较为复杂,所以系统实现时通过统计每种取值出现的次数再快速定位出中位数,从而发挥Spark的数据并行处理优势。
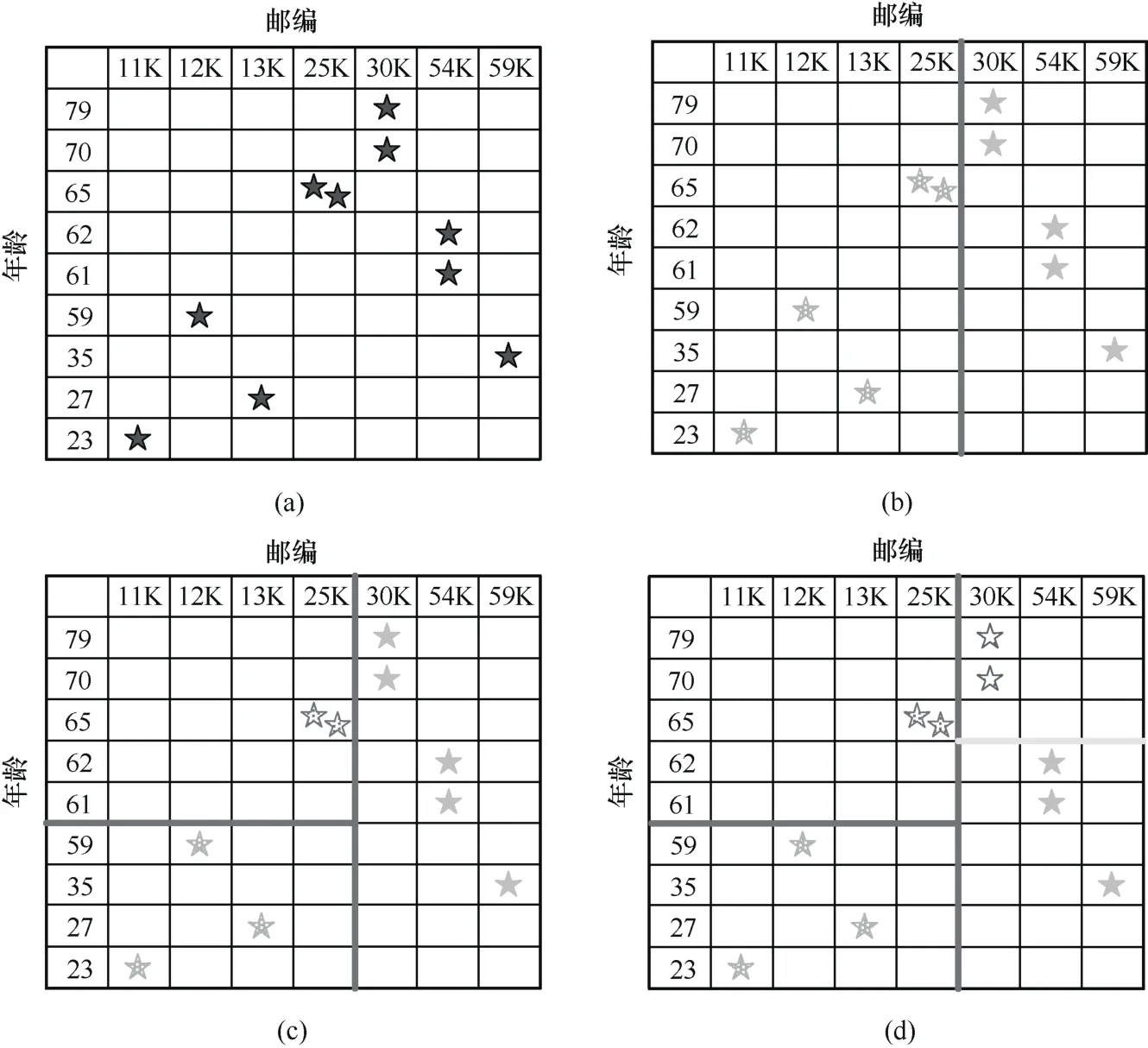
图1 Mondrian算法划分数值属性数据示例
(2)递归算法的实现方法
Mondrian匿名化算法是一个具有递归思想的算法,自顶而下地对数据进行划分,不断对划分出的子数据集使用相同过程进行再次划分,直至满足停止条件。然而递归实现在 Spark分布式计算平台上无法使用。本文改进为采用非递归实现,使用一个队列记录之后要继续进行划分的子数据集,然后按顺序从队列中取出依次进行。
(3)输入配置文件
数据匿名化处理需要类别属性的泛化树作为输入。所谓泛化树,就是类别属性进行泛化处理时的层次关系结构,如“中国”→“东亚”→“亚洲”→“*”。本系统中采用文本格式配置文件提供这一输入,文件中的每一行描述一个从叶节点(具体属性取值)到根节点(通常为“*”)的泛化关系,例如上述的泛化关系可表达为:“中国;东亚;亚洲;*”。
4 系统验证
本文系统测试采用机器学习及数据分析挖掘中常用的数据集Adult进行。Adult数据集是从美国1994年人口普查数据库抽取而来,其中包含一个敏感属性——收入状况,其他属性包括年龄、婚姻状态、职业、性别等。在测试中选取了其中8个非敏感属性(构成准标识符),其中两个是数值属性,其余6个均为类别属性。测试时将数据集以文本文件形式存放在HDFS中,同时将匿名化算法所需要的泛化树等配置信息也置于HDFS中供系统初始化时读取。
4.1 效果测试
图2显示了测试数据集中准标识符属性的取值样例,其中第一列与第三列是数值属性,其余均为类别属性。而图3则给出了准标识符属性经过本系统进行k-匿名化(k取值为10)处理后的样例。注意这两个图中的数据条目并非一一对应,只是随机选取的展示样例。可以看出,数值属性被泛化成一个区间,如第一列的“[38,45]”和第三列的“[11,14]”;而类别属性则被泛化成“*”或其他更高层次的泛化表达。经检查确认,本系统的匿名化处理结果与Mondrian算法的开源单机实现版本[9]相同,证明了本系统的匿名化算法实现的正确性。类似地,对于 l-多元化也进行了相应测试,同样能够得到预期正确结果,本文不再单独列出。

图2 原始数据集准标识符属性样例
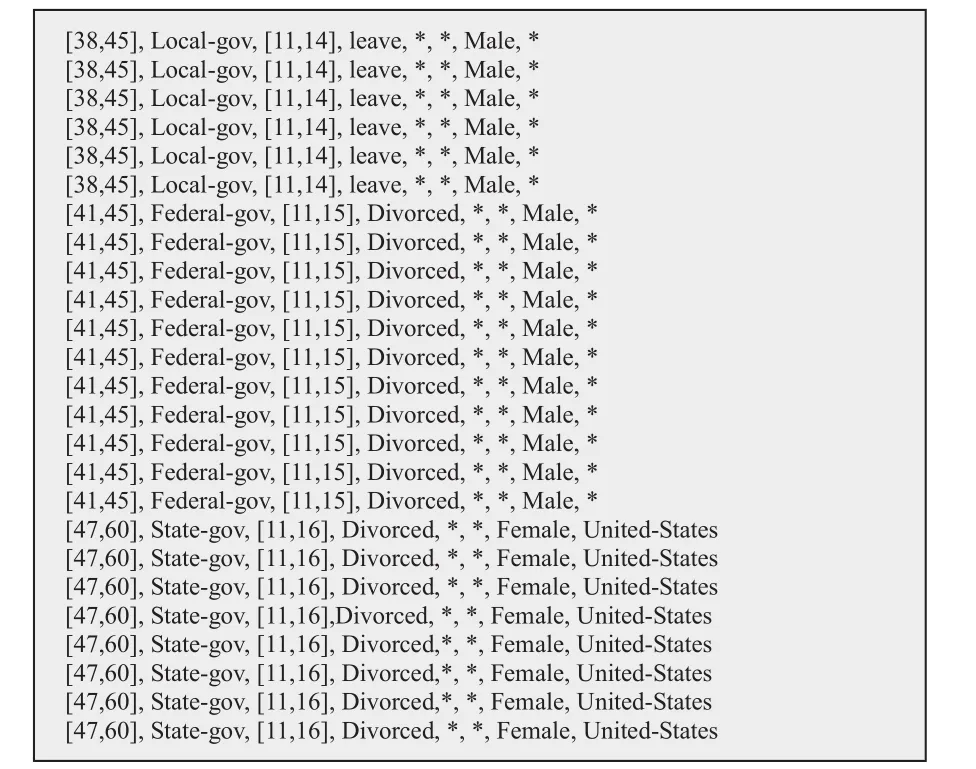
图3 经数据匿名化处理后的准标识符属性样例
4.2 性能评估
为了验证基于 Spark实现的系统在对数据进行匿名化处理时能否有效提高效率,对 Adult数据集进行扩充之后开展了一些简单实验。原始Adult数据集包含约 30 000条数据,无法体现Spark在大数据处理方面的优势,因此将其复制100倍、1 000倍,并对复制数据条目的数值属性进行随机修改,从而获得供性能评估测试用的数据。具体来说,复制100倍、1 000倍后的数据条数分别达到约3 ×106和30×106,相应的数据文件大小分别约为380 MB及3.8 GB。使用单机版的匿名化程序和基于 Spark实现的本系统分别进行相同的处理并记录各自消耗的时间,对于两种大小的数据集均重复进行了10次实验。其中实验用的Spark集群由3台Dell R720服务器(CPU:Intel®Xeon® E5-2603 v2@ 1.80 GHz,8核;内存:64 GB DDR3@ 1 600 MHz)组成,而单机版则在其中一台服务器上运行。图 4给出了实验结果,直方块表示10次实验的平均值,误差条表示标准差。结果显示基于Spark实现的匿名化系统比单机版程序对380 MB和3.8 GB数据集进行匿名化处理所用的时间分别少约 21%和 47%,表明基于 Spark实现的系统能够有效提高数据匿名化处理的效率,而且在数据规模增大时优势更为明显。

图4 数据匿名化处理时间对比
5 结束语
本文设计了一个基于分布式内存计算引擎Spark开发实现的大数据匿名化系统,支持对Hadoop平台的多种存储格式的数据进行高效匿名化处理,使用Mondrian算法达到k-匿名化、l-多元化等分组匿名化框架,能够在数据公开时对其中包含的隐私信息进行防护隐藏使其不会被恶意攻击者获取。系统性能相比于单机处理有明显提升。在未来的研究工作中,将参考Spark MLlib中决策树算法的实现来进一步提高系统的处理效率,并对数据经本系统匿名化处理后的价值损失进行理论分析与评估。
参考文献:
[1] Apache Software Foundation.Apache Hadoop[EB].2011.
[2] Apache Software Foundation.Apache Spark[EB].2014.
[3] SWEENEY L.K-anonymity: a model for protecting privacy[J].International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, 2002, 10(5): 557-570.
[4] MACHANAVAJJHALA A, KIFER D, GEHRKE J, et al.L-diversity: privacy beyond k-anonymity[J].ACM Transactions on Knowledge Discovery from Data (TKDD), 2007, 1(1): 3.
[5] FUNG B, WANG K, CHEN R, et al.Privacy-preserving data publishing: a survey of recent developments[J].ACM Computing Surveys (Csur), 2010, 42(4): 14.
[6] PRASSER F, KOHLMAYER F.Putting statistical disclosure control into practice: the ARX data anonymization tool[M].Berlin: Springer International Publishing, 2015.
[7] JADHAV R H, INGLE R B.A survey on data anonymization approaches using MapReduce framework on cloud[J].Digital Image Processing, 2015, 7(2): 48-49.
[8] LEFEVRE K, DEWITT D J, RAMAKRISHNAN R.Mondrian multidimensional k-anonymity[C]//International Conference on Data Engineering, April 3-7, 2006, Atlanta, GA, USA.Piscataway: IEEE Press, 2006: 25.
[9] QIYUAN G.GitHub-qiyuangong/basic_mondrian[EB].2015.
