基于RQA和V-VPMCD的滚动轴承故障识别方法*
2018-05-04徐冠基
柏 林, 曾 柯, 徐冠基, 陆 超
(重庆大学机械传动国家重点实验室 重庆,400044)
引 言
在实际的机械故障诊断过程中,提取的蕴含机械故障信息的特征值相互之间往往存在着某种数学关系,而且这种内在数学关系会因系统或工作状态类别的不同而存在明显的差异[1]。Raghuraj等[2]提出了一种VPMCD的模式识别方法,该方法主要利用样本特征值内在的相关性来建立特征学习模型,由于模型可以是非线性的、高阶的,因而VPMCD方法可以和支持向量机、神经网络一样处理非线性多变量预测问题。但是VPMCD方法对小样本问题的处理能力不佳,在训练样本比例为15%~30%之间时,VPMCD方法的预测精度[3]只有76.67%~87.63%,当训练样本比例为35%时,VPMCD方法预测精度[4]最高只有82%。VPMCD方法是基于最小二乘原理,当训练样本较少时会导致VPM模型预测不准确。另外单次VPMCD模型预测精度不高,在模式识别中可能会将某一预测样本投向错误的标签,即模型稳定性不好。杨宇等[1]将量子遗传算法应用到了VPMCD中克服了VPMCD选择模型的单一性和泛化能力较弱的缺点。程军圣等[5]为了解决VPMCD模型拟合过程中最小二乘法存在病态的问题将BP神经网络非线性回归方法代替了最小二乘法解决了该问题。但是他们都没有解决VPMCD方法对小样本处理能力不佳的问题,即当训练样本较少时会导致VPM模型预测不准确。因此笔者将投票法应用到了VPMCD多变量预测模型中。投票法就是将多个分类器的输出值进行组合,形成一个输出值,从而产生一个组合分类器的过程[6],常对分类存在不稳定或弱分类器集成时使用,是一种具有较强普适性的改进算法,对一次预测不准确的前提下,可以经过重复预测找出最有置信度的预测结果。另外由于滚动轴承的振动信号常常是复杂的非线性和非平稳性信号,因此利用非线性参数估计方法来提取隐藏在滚动轴承振动信号中的故障特征被越来越多的引入到轴承的故障诊断当中[7]。借助于RQA法对非线性、非平稳信号分析的鲁棒性和样本质量不高时处理的优势[8],在此基础之上提出了基于RQA和V-VPMCD的轴承故障识别方法(RQA+V-VPMCD)。最后通过对滚动轴承不同故障类型的故障模式识别实验,并对比传统VPMCD算法,SVM算法和BP神经网络算法的识别准确率,验证了该方法的有效性和准确性。
1 振动信号递归定量分析方法
滚动轴承在各种工况下,由于其载荷分布不均,刚度具有时变性,内外圈与滚动体的间隙以及摩擦等非线性因素影响导致滚动轴承的振动具有强烈的非线性性,因此传统的时域或频域分析方法对于非线性信号的分析具有一定的局限性[7]。考虑到RQA方法是一种有效的时间序列分析工具,适于分析非线性动力学系统,该方法对于非线性非平稳信号的分析有较强的鲁棒性,使用RQA分析信号可以获得其他方法难以得到的可靠结论[8-9]。因此本研究选择RQA方法对振动信号的非线性特征进行提取。
递归图[10]可以表示为
(1)

(2)
其中:X(i)m,X(j)m为空间嵌入矢量。

(3)
其中:m为重构维数;τ为延迟时间;xT表示x矩阵的转置;i满足1≤i≤N0-(m-1)τ。
由于X(i)m与自身的距离为0,故递归图总有一条主对角线存在,递归图中不规则的散列点反应了该系统中的随机成分,与主对角线平行的线段代表系统中的某些周期成分。几个常见的递归定量分析特征[8]如表1所示。
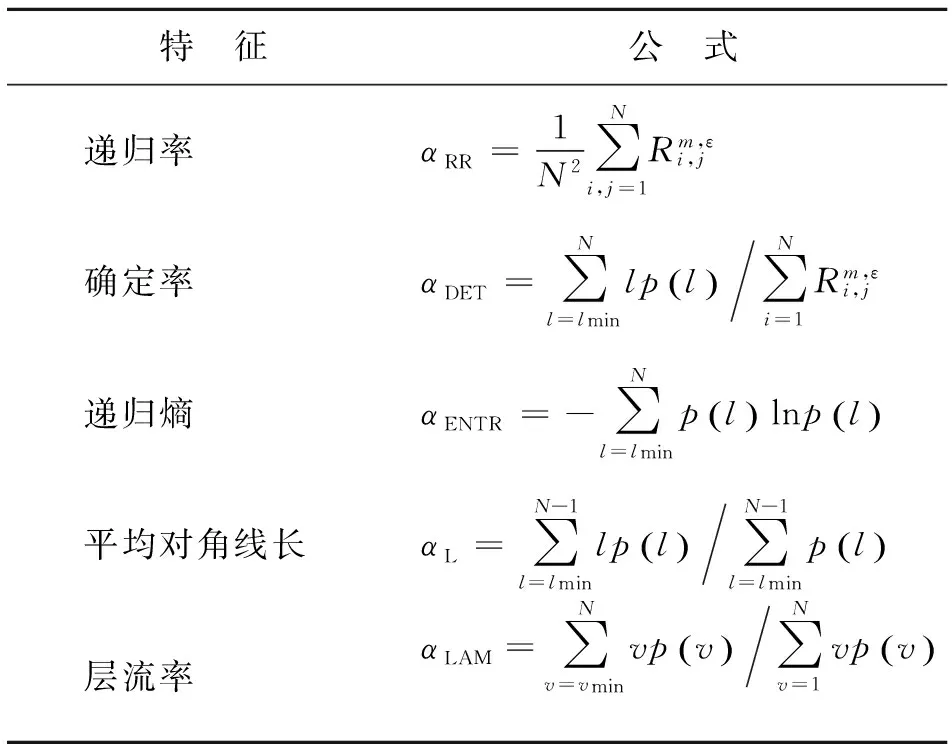
表1 递归定量分析特征
2 VPMCD算法及其存在的问题
在传统的VPMCD方法中[2],常用的特征Xi变量预测模型VPMi(theith variable predictive model,简称VPMi)主要有以下几种形式:线型模型L、线型交互模型LI、二次模型Q和二次交互模型QI。以任一模型为例,对特征量Xi建立预测模型VPMi,采用特征向量中其余特征值Xj(j≠i)来预测特征量Xi,有
Xi=f(Xj,b0,bj,bjj,bjk)+ζi
(4)
其中:ζi为预测模型误差;b0,bj,bjj,bjk为模型参数,通过训练样本拟合获得,算法流程见参考文献[2]。
VPMCD算法基于最小二乘原则,在真实情况中,常常会遇到训练样本数量较少的小样本问题,小样本情况下会产生两类问题:a.样本数量P少于参数个数Q时,拟合会舍去后面的Q-P个参数,导致拟合的不准确,最终影响预测结果;b.由于VPMCD算法基于拟合特性,当样本数较少时,训练样本的质量对最终预测结果影响非常大。图1给出了训练样本为较优子集和较劣子集两种情况下的VPMi训练模型质量对比,图中黑色和灰色圆点表示类别1样本聚类,白色圆点表示类别2样本聚类,每个样本由(X1,X2)两个特征组成。当训练样本集合能够反映出真实的样本群特性时,预测效果较优,当训练样本中离群点相对较多,聚类特性不明显时,拟合偏差较大,造成与真实的样本群特性差异较大,影响识别精度。
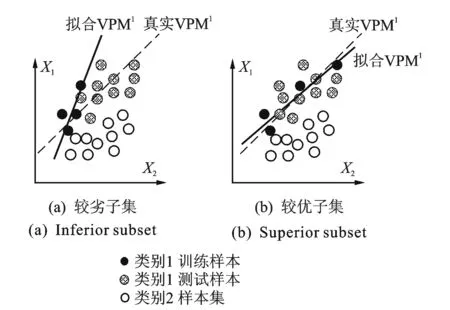
图1 训练子集质量对拟合结果的影响Fig.1 The influence of the quality of training subsets on the fitting results
3 基于递归定量分析和V-VPMCD的轴承故障识别方法
在无法增加训练样本数量的情况下,改进VPMCD算法抑制其不稳定性就显得尤为重要,现将投票法引入到VPMCD算法中,提出V-VPMCD(Voted-VPMCD)算法来改进针对小样本下VPMCD模型预测精度不高的问题。投票法常用于对分类存在不稳定性或弱分类器集成时使用,是一种具有较强普适性的改进算法。投票法的分类很多,其中Breiman[11]提出的装袋算法是用多数投票法将多个预测结果合并成最终结果输出。算法基本原理首先是选定迭代次数,也即投票次数i(i=1,2,3,…,k),在样本集D={X1,X2,X3,…,XN}中有效地组合n个样本得到训练样本集Di,用训练样本集训练分类器可以得到分类模型Mi,再将测试样本输入分类模型Mi返回预测标签,并对该标签计一票,最后由复合模型M*统计得票数,所得票数最多的标签即为测试样本最终标签。已经证明,只要单个分类器相互独立,分类器的个数趋向无穷时,组合分类器的分类错误会趋向于0[6]。将投票法引入到VPMCD算法中,可以解决小样本学习时训练子集选取的不确定性对分类精度造成影响,因为V-VPMCD变量预测模型下的一次分类预测相当于在原VPMCD模型下多次分类预测的寻优,因此V-VPMCD算法可以保持小样本数下较高的分类精度。算法流程如下。
1) 获取需要分析的时间序列{x(i)|i=1,2,…,N0}。
2) 利用互信息法求取延迟时间τ,利用CAO法求取重构维数。
3) 重构至高维空间X={x(i),x(i+τ),…,x(i+(m-1)τ)}T。
4) 设置递归阈值ε进行递归分析。
5) 计算RQA中共计r个递归量化参数:αRR,αDET,αENTR等。
6) 重复步骤1~5,计算得到N个信号样本的r个递归量化值,组成N×r的递归量化参数矩阵。对每一行样本所属的标签打上标记,对一个p分类问题总计有p类标签。

9) 多次投票结果组成预测矩阵Pi×k,1≤i≤Ntest,对某个预测样本统计多次投票中出现次数最多的标签作为该预测样本的最终标签。
4 实验验证
文中选取由Case Western Reserve University提供的滚动轴承故障实验数据,单位样本信号截取L=1 024个点,针对滚动轴承的10种故障状态,即10种标签类型,分别为正常、内圈故障(0.177 8 mm)、内圈故障(0.355 6 mm)、内圈故障(0.533 4 mm)、滚动体故障(0.177 8 mm)、滚动体故障(0.355 6 mm)、滚动体故障(0.533 4 mm)、外圈故障(0.177 8 mm)、外圈故障(0.355 6 mm)和外圈故障(0.533 4 mm),括号中的数字代表故障尺寸,采用电火花加工,为单点损伤。每种故障状态选取50组样本,10类故障总计500组样本。
然后利用RQA对上述样本集提取特征。在进行递归分析的时候,以下3个参数的选取对于特征提取至关重要,即重构维数m,延时时间τ和参考阀值ε。CAO法[12]可选择合适的重构维数m,而延迟时间τ的选择多采用自相关函数法或互信息法[13]。参考阀值ε一般取使得递归率αRR约为10%时的值[14]。然后计算得到由递归率αRR、确定率αDET、平均对角线长αL、递归熵αENTR和层流率αLAM这5个特征组成特征向量,得到一个维数为500×5的特征矩阵,即为特征样本集。
为了说明以RQA作为特征提取方法对VPMCD预测精度的提升,将EMD能量熵特征提取方法与其进行对比,得到如图2所示的RQA-VPMCD和EMD能量熵-VPMCD准确率对比。从图2中可以看出RQA对于VPMCD的预测精度,特别是小样本情况下的预测精度提升作用明显。
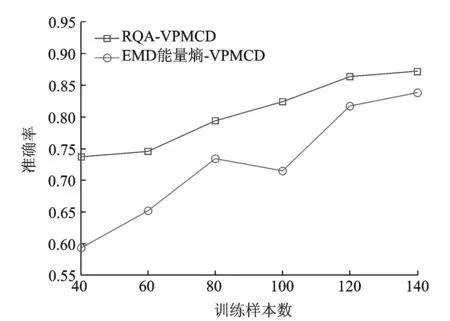
图2 RQA-VPMCD和EMD能量熵-VPMCD准确率对比Fig.2 The accuracy rate of RQA-VPMCD and EMD -VPMCD
分别随机选取100和300组样本作为训练样本集,输入VPMCD方法进行模型拟合。表2给出了不同训练样本数下VPMCD的最佳拟合模型,其中Xi表示第i个特征的预测模型VPMi。在较少样本的情况下,各类特征的预测模型会倾向于选择低阶模型,如线性模型L和线性交互模型LI,而当样本数目较多,预测模型会更倾向于选择高阶模型,尤其是最复杂的二次交互模型QI,其拟合残差最小。
表2 训练所得各特征最佳拟合模型类型
Tab.2 Best fitting model type of features after training

模型状态训练样本少(100个为例)训练样本多(300个为例)X1X2X3X4X5X1X2X3X4X5正常状态LILILIQQQIQIQIQIQI内圈(0.1778mm)QIQLILIQIQIQIQIQIQI滚动体(0.1778mm)QIQILILIQIQIQIQIQIQI外圈(0.1778mm)QIQIQIQIQIQIQIQIQIQI内圈(0.3556mm)QQILIQQQIQIQIQIQI滚动体(0.3556mm)QIQIQIQIQIQIQIQIQIQI外圈(0.3556mm)QILIQIQIQIQIQIQIQIQI内圈(0.5334mm)QIQIQIQIQIQIQIQIQIQI滚动体(0.5334mm)QIQILILILIQIQIQIQIQI外圈(0.5334mm)QIQILLLIQIQIQIQIQI
表3给出了VPMCD算法对不同训练样本数和测试样本数情况下其预测模型的识别准确性。由表3可知,VPMCD算法分类精度总体上随着训练样本的增加而增加,当训练样本数与预测样本数接近或相同时其分类性能达到较优状态。随着训练样本的增多,测试样本的减少,VPMCD算法的计算耗时呈现下降趋势。这主要是由于训练的计算开销主要为构建各个预测类型的VPMin,其中包括最小二乘的拟合过程,只需对矩阵QR分解后求解即可;另外,对每个标签每类特征寻找其最小残差的拟合模型也具有一定的计算量。而预测的开销主要是将预测样本代入多类VPMin中并计算比对误差最小的平方和标签,这是一个多次迭代和比较的过程,因此,原则上单位样本的预测耗时要大于训练耗时,文献[15]中的结论也证实了这点。
表3VPMCD不同训练、测试样本数情况下识别性能
Tab.3RecognitionperformanceofVPMCDbasedondifferentnumbersoftrainingandtestingsamples

总训练样本数总测试样本数正确分类样本(10次)平均准确率/%平均耗时/s100400329782.430.281120380328386.400.250140360314087.220.218160340299788.150.174180320285489.190.124200300273891.270.086220280258592.320.081240260242293.150.072260240226194.210.068280220207094.100.064300200187293.600.060320180169794.280.051340160150093.750.050360140131694.000.047380120113894.830.04440010094594.500.042
表4给出了训练样本数为100时10种滚动轴承状态的投票的样例,表4中黑色加粗的数字即为该次投票投向的错误标签号,这也是单次VPMCD算法的准确率不是很高的原因。有许多测试样本在某一些训练样本拟合的模型情况下被预测正确,而在另外一些训练样本拟合的模型情况下被预测错误,即模型稳定性不高,因此多次投票就显示出了其优越性。在多次投票情况下,将出现次数最多的标签作为测试样本的最终标签,可以看到样例中的样本都获得了正确的预测标签。若出现像第9个样本在10次投票过程中标签“7”和标签“9”得票相同这种情况,根据装袋投票法[11],若投票次数越多那么最后投票结果就越接近于真实结果,因此规定重新做10次投票,综合20次投票得出投票结果。若还是不能分出结果,就根据这两类得票数相同的标签中哪个标签在20次投票中第一次出现作为最后投票结果,经过20次投票后最终投票结果为“9”号标签,其与真实标签是相符的。
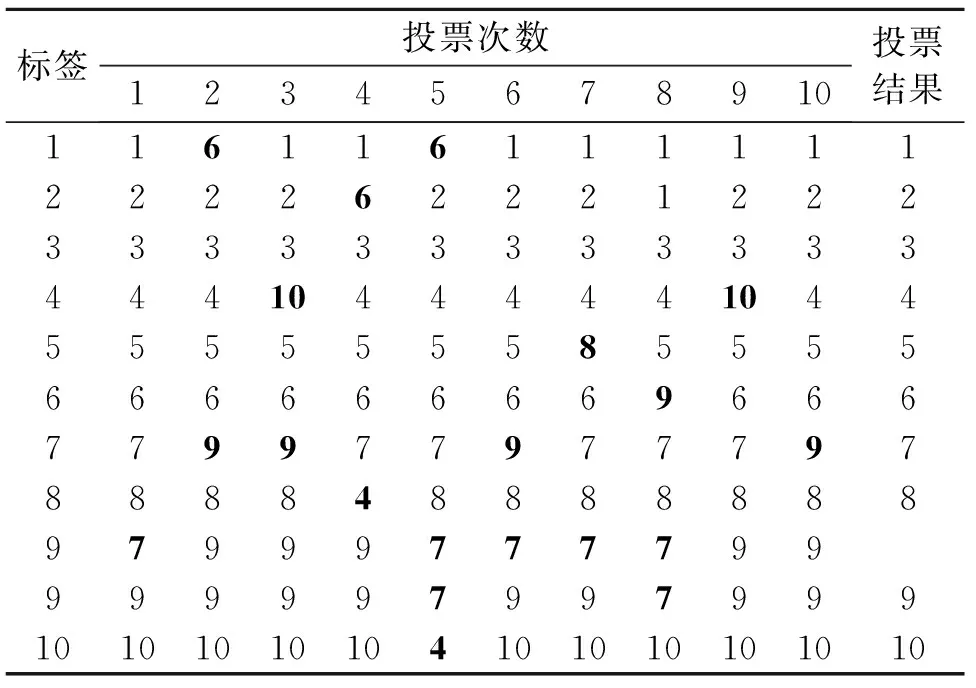
表4 V-VPMCD算法的投票样例
表5给出了V-VPMCD算法在不同训练样本数目下其预测模型识别性能概况。对比表3和表5可以看出,在训练样本数较少时,经过投票后的VPMCD算法其预测模型的准确度可以获得大约12%的提升,那是因为投票法增加了算法的稳定性,异常样本对整体识别精度的影响被弱化了。总体而言,相较于VPMCD预测模型,V-VPMCD预测模型在预测准确率方面提高3%~12%,因为一次预测相当于在多次VPMCD投票的综合结果中寻优,但是也正因为这个原因V-VPMCD算法的平均耗时要大于VPMCD算法。
表5V-VPMCD不同训练、测试样本数情况下识别性能
Tab.5RecognitionperformanceofV-VPMCDbasedondifferentnumbersoftrainingandtestingsamples

总训练样本数总测试样本数正确分类样本(10次)平均准确率/%平均耗时/s100400381195.287.367120380367696.735.782140360349196.974.674160340328396.555.016180320311897.452.393200300293697.851.913220280273397.611.707240260253997.681.623260240233397.201.682280220212696.641.648300200193296.601.665320180174697.001.003340160154696.630.938360140135496.710.890380120115696.330.83940010095695.600.789
图3给出了在同一RQA特征样本集下V-VPMCD,VPMCD,SVM和BP神经网络这4种分类模型的预测准确率比较。

图3 BP,VPMCD,SVM和V-VPMCD识别率对比Fig.3 General recognition rate of BP, VPMCD, SVM and V-VPMCD
从图中可以看出在各种训练样本数情况下,经过投票法改进的VPMCD分类模型较其余分类模型有明显的优势,并且在当训练样本极少(即40个样本,占总特征样本集的8%)的情况下其准确率也能达到90%以上。并且V-VPMCD分类模型当训练样本数与预测样本数接近或相同时其分类性能达到最优状态,但是当训练样本较充足时随着训练样本的增加V-VPMCD预测模型预测精度有微小下降,这是因为当训练样本较充足时影响预测精度的不再是训练样本的数量,并且文中在样本总和保持不变的情况下训练样本增加而测试样本减少,这时测试样本中的极少数离群样本对预测准确率的负面影响较测试样本量多时要大,文献[16-17]中也证实了这一点。VPMCD分类模型的识别准确率与训练样本数呈现很强的正相关性,在小样本情况下其预测精度很低。
对比其他文献,例如文献[3]中可以看到在训练样本比例为15%~30%之间时,VPMCD方法的预测精度只有76.67%~87.63%,文献[4]中当训练样本比例为35%时,VPMCD方法预测精度最高只有82%,这足以说明VPMCD方法在小样本情况下的识别性能不佳,而通过RQA+V-VPMCD方法能极大地提高其识别性能。
5 结束语
VPMCD算法识别准确率随着训练样本的递增呈现很强的正相关性,因而会面临很严重的小样本问题。因此笔者将投票法应用到了VPMCD多变量预测模型中,该方法核心思想就是对一次预测不准确的前提下,可以经过重复预测找出最有置信度的预测结果。同时利用RAQ对非线性、非平稳信号分析的鲁棒性和样本质量不高时处理的优势,来提取滚动轴承振动信号的非线性特征。在此基础上提出的基于RQA和V-VPMCD的滚动轴承故障识别方法,根据其在滚动轴承故障模式识别实验中的应用分析可知:a.RQA有对过程平稳性要求低,分析鲁棒性好的优势,它能准确提取出滚动轴承振动信号中的非线性特征,对分类准确率的提升有很大贡献;b.经过投票法优化后的VPMCD算法结合了VPMCD算法利用特征关联性作为分类依据的优越性,以投票的机制克服了单次拟合结果不稳定的情况,从多次投票中选取出现次数最多的标签来标记预测样本。预测标签准确性得到较大提升,提高了模式识别的精度和稳定性。
[1] 杨宇,李紫珠,何知义,等.QGA-VPMCD智能诊断模型研究[J].振动与冲击,2015,34(13):31-35.
Yang Yu, Li Zizhu, He Zhiyi, et al. QGA-VPMCD intelligent diagnosis model[J]. Journal of Vibration and Shock, 2015,34(13):31-35. (in Chinese)
[2] Raghuraj R, Lakshminarayanan S. Variable predictive models—a new multivariate classification approach for pattern recognition applications[J]. Pattern Recognition, 2009,42(1):7-16.
[3] 罗颂荣,程军圣,郑近德,等.GA-VPMCD方法及其在机械故障智能诊断中的应用[J].振动工程学报,2014,27(2):289-295.
Luo Songrong, Cheng Junsheng, Zheng Jinde, et al. GA-VPMCD method and its application in machinery fault intelligent diagnosis[J]. Journal of Vibration Engineering, 2014,27(2):289-295. (in Chinese)
[4] 刘吉彪,程军圣,马利.基于 PSODACCIW-VPMCD 的滚动轴承智能检测方法[J].振动与冲击,2015,34(23):42-47.
Liu Jibiao, Cheng Junsheng, Ma Li. An intelligent detection method for rolling bearings based on PSODACCIW-VPMCD[J]. Journal of Vibration and Shock, 2015,34(23):42-47. (in Chinese)
[5] 程军圣,马利,潘海洋,等.基于EEMD和改进VPMCD的滚动轴承故障诊断方法[J].湖南大学学报:自然科学版,2014,41(10):22-26.
Cheng Junsheng, Ma Li, Pan Haiyang, et al. A fault diagnosis method for rolling bearing based on EEMD and improved VPMCD[J]. Journal of Hunan University: Natural Sciences, 2014,41(10):22-26. (in Chinese)
[6] 王素格,杨军玲,张武.基于最大熵模型与投票法的汉语动词与动词搭配识别[J].小型微型计算机系统,2007,28(7):1306-1310.
Wang Suge, Yang Junling, Zhang Wu. Chinese Verb-verb collocation recognition based on maximum entropy model and voting[J]. Journal of Chinese Computer systems, 2007,28(7):1306-1310. (in Chinese)
[7] 朱可恒.滚动轴承振动信号特征提取及诊断方法研究[D].大连:大连理工大学,2013.
[8] Trulla L L, Giuliani A, Zbilut J P, et al. Recurrence quantification analysis of the logistic equation with transients[J]. Physics Letters A, 1996,223(4):255-260.
[9] 尹少华,杨基海,梁政,等.基于递归量化分析的表面肌电特征提取和分类[J].中国科学技术大学学报,2006,36(5):550-555.
Yin Shaohua, Yang Jihai, Liang Zheng, et al. Recurrence quantification analysis based on surface EMG signal feature extration and classification[J]. Journal of University of Science and Technology of China, 2006,36(5):550-555. (in Chinese)
[10] Eckmann J P, Kamphorst S O, Ruelle D. Recurrence plots of dynamical systems[J]. Europhysics Letters, 1987,4(9):973-977.
[11] Breiman L. Bagging predictors[J]. Machine Learning, 1996,24(2):123-140.
[12] Cao Liangyue. Practical method for determining the minimum embedding dimension of a scalar time series[J]. Physica D: Nonlinear Phenomena, 1997,110(1):43-50.
[13] 许岩.含噪混沌时间序列相空间重构参数估计[D].重庆:重庆大学,2013.
[14] Marwan N, Romano M C, Thiel M, et al. Recurrence plots for the analysis of complex systems[J]. Physics Reports, 2007,438(5):237-329.
[15] 程军圣,马兴伟,杨宇.基于排列熵和VPMCD的滚动轴承故障诊断方法[J].振动与冲击,2014,33(11):119-123.
Cheng Junsheng, Ma Xingwei, Yang Yu. Rolling bearing fault diagnosis method based on permutation entropy and VPMCD[J]. Journal of Vibration and Shock, 2014,33(11):119-123. (in Chinese)
[16] 程军圣,马兴伟,杨宇.基于VPMCD和EMD的齿轮故障诊断方法[J].振动与冲击,2013,32(20):9-13.
Cheng Junsheng, Ma Xingwei, Yang Yu. Gear fault diagnosis method based on VPMCD and EMD[J]. Journal of Vibration and Shock, 2013,32(20):9-13. (in Chinese)
[17] 刘刚,张洪刚,郭军.不同训练样本对识别系统的影响[J].计算机学报,2005,28(11):1923-1928.
Liu Gang, Zhang Honggang, Guo Jun. The influence of different training samples to recognition system[J]. Chinese Journal of Computers, 2005,28(11):1923-1928. (in Chinese)
