基于数据挖掘软件SPSS modeler的影响职业院校招生因素的研究
2018-05-03王红旗
王红旗
(宿州职业技术学院 安徽·宿州 234000)
引言
在信息科技引领21世纪时代潮流的背景下,人们每天会面临数以万计的各种数据,这些海量数据难以用人工统计的方式来发现或寻找隐藏在其中的某一些规律,惟有运用先进的数据库处理技术才能对一些庞大的数据集群进行深入的挖掘,进而精准又快速地找到隐藏在数据中的规律,最终为某方面的工作需求提供决策参考,根据数据挖掘出来的规律来制定较为合理的政策或措施,可使某行业或领域发展始终处于健康、稳定及可持续状态[1]。总之,挖掘数据库中的数据、找到隐藏在数据中的规律是最终目标。如何挖掘数据库是人们面临的共同难题。本文针对职业院校招生数据,利用SPSS modeler软件对职业院校历年来的招生数据进行挖掘,并从中发现职业院校招生的某些规律,据此规律而改进招生策略,可使当前面临困境的职业院校招生问题得以缓解,为以后进入良性的可持续阶段打下基础。
1.数据挖掘及SPSS modeler软件概述
1.1 挖掘数据的定义
数据挖掘(Data Mining)就是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的、人们事先不知道的但又是潜在有用的信息和知识的过程[2]。数据挖掘的三个重要步骤为:数据准备、数据挖掘、结果表达和分析,具体分为以下几个步骤:商业定义、数据集成、数据清理、数据变换、数据挖掘、模式评估、知识表示。数据挖掘是一门交叉学科,它把人们对数据的应用从低层次的简单查询,提升到从数据中挖掘知识,提供决策支持。
1.2 SPSS modeler软件
SPSS modeler软件是一款专门用于数据挖掘的软件,操作界面通俗易懂,设置的挖掘参数方便快捷,建立的模型分析结果可靠[3]。SPSS modeler软件操作的主要步骤:数据预处理—运行SPSS modeler出结果—统计规律。数据预处理就是将不适用于SPSS modeler软件运行分析的数据做筛选删除处理;运行SPSSmodeler出结果就是将已处理的数据导入软件,利用SPSS modeler软件建立可视化的模型,实现对数据全方位的挖掘,同时将软件运行的结果显示在操作界面上;统计规律即通过显示的结果找到某一特定的规律,以便于分析人员根据规律来制定相对应的策略[3]。在运行SPSS modeler软件时主要设置三个参数,即:数据的提升度、置信度及支持度,如若能合理设置这三个参数,就能对在数据挖掘中出现的规律提供更好的判断依据。
2.职业院校招生数据挖掘分析与设计
职业院校招生在高校招生中处于最后一批次,生源的数量质量较本科院校招生处于劣势,因此职业院校的招生除了受到本身教学质量和生源就业率的影响外,生源的数量与质量也是影响职业院校招生的关键因素。
2.1 影响职业院校招生因素分析
(1)生源的成绩数据分析
根据历年招生的生源成绩来科学划定生源的层次,层次划分的准则是符合职业院校招生生源成绩实际情况,成绩段划分过高或过低都会影响招生。
(2)需求专业的设置分析
职业院校应该以服务地方经济为导向来合理地设置本职业院校的专业,从而提高职业院校的社会认可度。
(3)生源毕业时的就业情况分析
生源在选择职业院校的基本意向就是毕业后能够就业,若就业率较高,则生源的选择本职业院校的机率就大,否则下一年的本职业院校招生生源率就会下降。
2.2 职业院校招生数据挖掘设计
(1)对体现数据是否具备关联性的三项指标:数据的提升度、置信度及支持度设定合理阈值。
(2)对招生生源的成绩数据、需求专业的设置及生源毕业时的就业数据做筛选处理,即对这些数据按照离散数学上的离散原理做离散处理。
(3)编制数据关联性处理程序对职业院校的生源成绩数据、需求专业的设置及生源毕业时的就业数据进行处理,并将处理的结果保存在系统中。
(4)分析数据关联性处理后的数据结果,找到能够准确反映职业院校招生的规律。
(5)对有关联性的数据深入挖掘,通过体现数据关联性强弱的三项指标:数据的提升度、置信度及支持度来验证关联数据存在的关系,即数据支持度在预先设置的阈值范围内的判定为有关联性的数据,越靠近支持度的设定阈值,其关联性越强;数据的提升度也在预先设定的阈值范围内并与阈值差的绝对值越小,则该组关联性相关数据是影响职业院校招生的重要数据。SPSS modeler软件分析出的置信度分别与系统设置的阈值进行比较,进而分析出隐藏在关联性的数据中客观存在的规律[4]。关联性的数据挖掘的设计流程,如图2-1所示。

图2-1 关联性的数据挖掘的设计流程
3.SPSS modeler软件研究职业院校招生数据挖掘的实现
按照职业院校招生数据挖掘分析和设计原则,利用SPSS modeler软件对职业院校招生数据做处理,并建立招生生源的成绩、需求专业的设置以及生源毕业时的就业情况模型,如图3-1所示。
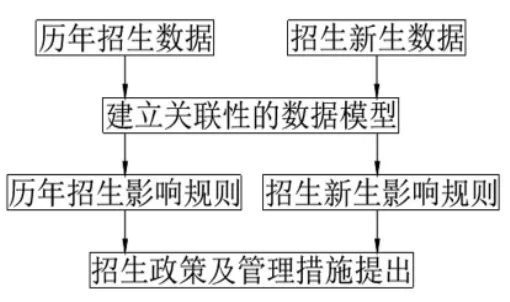
图3-1 职业院校招生数据挖掘模型图
从图3-1可知,对招生生源的成绩、需求专业的设置以及生源毕业时的就业情况按照图中要求来建立模型,从而找出三者间有关联性的数据以及隐藏在数据中的规律,最终为职业院校招生提供决策支持。
3.1 数据处理
针对招生生源的成绩、需求专业的设置以及生源毕业时的就业情况数据,需要对这些数据进行筛选预处理,为进一步的关联性的数据挖掘提供便利。如表3-1、表3-2及表3-3所示。
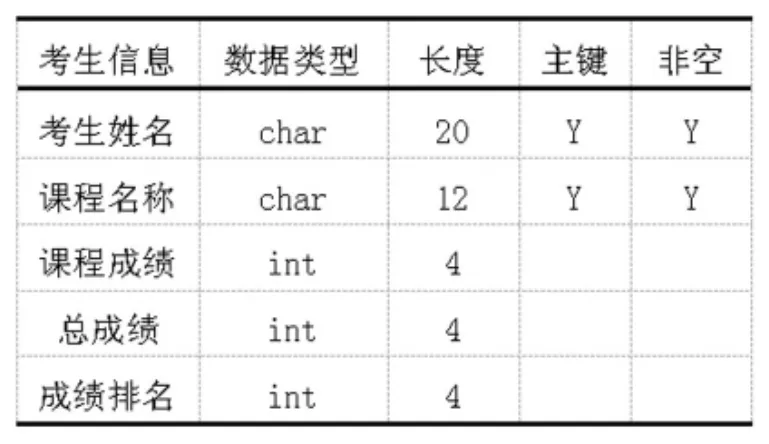
表3-1 招生生源的成绩基本信息

表3-2 需求专业设置情况

表3-3 生源毕业时的就业情况
3.2 spss modeler建模及数据挖掘
利用spss modeler软件对职业院校招生数据进行挖掘,先将招生生源的成绩、需求专业的设置以及生源毕业时的就业情况数据做离散和差集筛选处理。先将数据做平均分段处理,选中软件界面上的筛选键,点击确认,则经过筛选后显示的数据为离散差集处理后的全部数据段,同时需要多次重复筛选,直至界面显示数据处理完成。再设置三项指标即:数据的提升度、置信度及支持度值,最后运行软件,操作界面显示系统运行后跳出的一组数据,即在设置的支持度范围内的多次重复项集。最后界面跳出在预设的提升度和置信度范围内的一组数据。本文利用spss modeler数据挖掘软件对职业院校招生数据进行挖掘,流程图如图3-2所示。
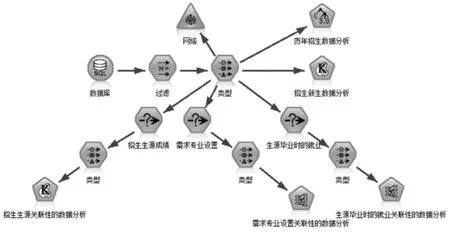
图3-2 职业院校招生数据进行挖掘流程图
由图3-2所示,招生生源的成绩、需求专业的设置以及生源毕业时的就业情况数据以excel表格形式输入spss modeler软件中,再设定三项指标的参数,即设定数据的提升度、置信度最小为60及最低条件支持度为15,如图3-3、3-4和3-5所示。

图3-3 招生的生源成绩关联性的数据建模

图3-4 需求专业的设置关联性的数据建模
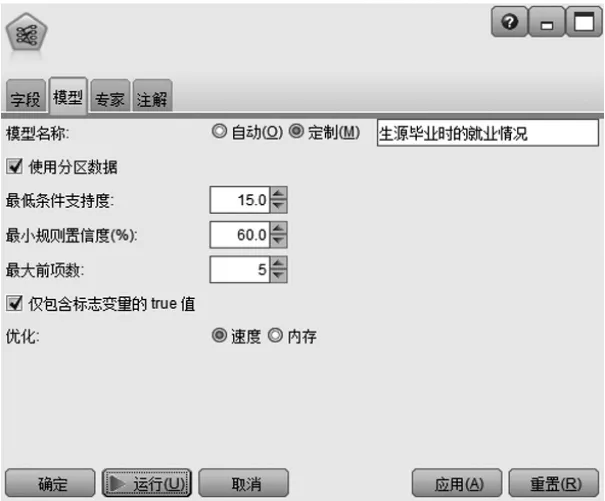
图3-5 生源毕业时的就业情况关联性的数据建模
通过SPSS modeler软件对职业院校招生数据进行挖掘分析,在分析中需要将招生生源的成绩、需求专业的设置以及生源毕业时的就业情况的三个因素中,分别通过招生生源的成绩作为自变量,而需求专业的设置和生源毕业时的就业情况作为因变量;将需求专业的设置作为自变量,招生生源的成绩和生源毕业时的就业情况作为因变量;将生源毕业时的就业情况作为自变量,招生生源的成绩和需求专业的设置作为因变量,并且以系统设置的数据的提升度、置信度最小为60及最低条件支持度为15为前提条件,最后职业院校招生数据的挖掘结果及数据的提升度、置信度和支持度的参数,如表3-4所示。
由职业院校招生数据的挖掘的结果及置信度和支持度值来看,找出职业院校招生数据中隐藏的一些规律如下:
(1)根据支持度结果分析,生源毕业时的就业情况分段数据的平均支持度值与设定的最低条件支持度差值绝对值是最大的,招生生源的成绩分段数据中的支持度平均值与设定的最低条件支持度差值绝对值为最小的,需求专业的设置分段数据的平均支持度值与设定的最低条件支持度差值绝对值介于生源毕业时的就业情况的与招生生源的成绩之间,按照最低条件支持度与平均支持度的差值绝对值的大小影响因素原则来判断,绝对值的偏差越小,影响越大[5],则可得出结论:在影响职业院校招生的三个因素中,招生生源的成绩数据对于职业院校的招生的影响〉需求专业的设置的影响〉生源毕业时的就业情况。

表3-4 招生的数据挖掘情况及参数
(2)根据置信度结果分析,招生生源的成绩分段数据中的置信度平均值与设定的最低条件置信度差值绝对值为最小的,而生源毕业时的就业情况分段数据的平均置信度与设定的最低条件置信度差值绝对值是最大的,按照最低条件置信度与平均置信度的差值绝对值的大小影响因素原则来判断,绝对值的偏差越小,影响越大[5],则也可得出结论:在影响职业院校招生的三个因素中,招生生源的成绩数据对于职业院校的招生的影响〉需求专业的设置的影响〉生源毕业时的就业情况。
(3)总结置信度和支持度与各自设定的绝对值差值可知,影响职业院校招生的因素大小顺序是招生生源的成绩〉需求专业的设置〉生源毕业时的就业情况。
4.结论
综上所述,运用SPSS modeler软件对职业院校招生数据进行深入挖掘分析,针对挖掘数据中的三项指标,数据的提升度、置信度和支持度值,来设定较为合理的条件值,再运用SPSS modeler软件对招生生源的成绩、需求专业的设置以及生源毕业时的就业情况等数据进行分析,最后得出结论。职业院校的招生工作,可以根据以上结论制定本校良性发展策略:短期来说,可根据生源的实际情况正确选择考生的成绩段以确保顺利完成招生任务;长远来看,要重视专业设置,要以服务地方特色经济和社会需求为设置方向。另外,还要充分考虑各专业毕业生的就业情况。
[1]王宏志.大数据算法[M].北京:机械工业出版社,2015.
[2]刘功申,邱卫东,孟魁,李建华.基于真实数据挖掘的口令脆弱性评估及恢复[J].计算机学报,2016,39(03):454-467.
[3]张启徽.关联规则挖掘中查找频繁项集的改进算法[J].统计与决策,2015,(04):32-35.
[4]陈荣鑫.R软件的数据挖掘应用[J].重庆工商大学学报(自然科学版),2011,28(06):602-607.
[5]薛毅,陈立萍.统计建模与R软件[M].北京:清华大学出版社,2007.
