机器学习在运营商用户流失预警中的运用
2018-05-03刘颖慧崔羽飞
赵 慧 刘颖慧 崔羽飞 张 第
中国联通研究院北京10032
引言
我国通信行业经过近二十年的发展,现在基本呈现三足鼎立的局势。各企业竞争日趋激烈,各大运营商都面临着客户状态不稳定,客户生命周期缩短等问题。
移动通信行业的现有企业中,一般情况下客户月流失率在3%左右,如果静态计算,所有客户会在2~3年内全部流失。
2017年我国的移动电话普及率首次突破102.5部/百人,在一个如此成熟和饱和的市场中,开拓新用户的难度可想而知。从传统意义上来讲,移动通信行业保留旧客户利润率为开发一位新客户的16倍,尤其对于剩余客户市场日渐稀疏的移动通信市场来说,减少客户流失就意味着用更少的成本减少利润的流失,这点已经为运营商所广为接受。由此可见客户保持的重要性,也就是说保留旧客户比开发、吸收新客户更重要,如何提前识别高风险流失客户更是首先需要解决的问题,成为通信企业越来越关注的焦点。
之所以将机器学习应用于运营商用户离网分析,是因为机器学习是一种基于数据的自主学习方法,相较于传统的用户维挽,机器学习可以提高效率、提高准确性、降低成本。
按照不同的应用类型,机器学习分类算法对用户是否离网预测水平的量化评价指标包括准确率、召回率、精确率、F1得分等。为了实现优秀的分类预测效果,众多的分类算法被提出,并在业界使用。其中一类方法非常特殊,我们称为多模型融合算法。融合算法是将多个推荐算法通过特定的方式进行组合,融合在机器学习中扮演着极为重要的作用,本文结合联通青海用户离网预测的实践经验为大家系统性地介绍。
相较于传统成本高、准确率低的客户维挽方法,本文建立的客户流失预警模型是使用机器学习分类算法和模型融合手段,整合客户历史海量数据,通过对客户基本状态属性与历史行为属性等数据进行深入分析,提炼出已流失客户在流失前具有的特征,建立流失预警模型。具体来说是通过对用户的流量、通话、短信、资费等信息,使用用户三个月为周期的数据进行模型训练,运用机器学习技术,使用决策树、随机森林、逻辑回归等算法对多个模型结果进行模型融合,提高预测精度,对客户下下个月是否流失进行预测。
本模型不仅仅给出客户流失预测的名单,同时给出用户流失的可能性得分,以及影响用户是否流失的最重要的指标排名,帮助企业提前识别高风险流失客户,显著提高企业的市场竞争力。
1 机器学习理论
根据文献[1]可知机器学习有很多方法,大体上可以分为监督学习(Supervised Learning)、无监督学习(Unsupervised Learning)、半监督学习(Semi-Supervised Learning)、强化学习(Reinforcement Learning)等。下面对各类学习做一简单概述。
1.1 监督式学习
监督式学习算法训练的数据含有两大部分,一部分是含有很多特征的预测变量,一部分是有一个标签或是目标的目标变量。通过这些变量搭建一个模型,对于一个已知的预测变量值,我们可以得到对应的目标变量值。重复训练这个模型,直到它能在训练数据集上达到预定的准确度。属于监督式学习的算法有:回归模型、决策树、随机森林、K邻近算法、逻辑回归等。
用户流失预警本质上是监督式学习中的分类模型,包含目标变量即用户是否流失的标签,同时含有自变量也就是我们使用的流量、短信、语音等相关预测变量字段。通过这些变量搭建用户流失预警模型,对于已知的用户是否流失标签,得到对应的流失预测,重复训练用户流失模型,直到它在我们指定的模型评估指标上达到最优状态。因此我们需要使用分类算法,本文选用逻辑回归、决策树、随机森林这三个分类模型。下面介绍本文使用的三个机器学习分类算法理论以及各自的优缺点。
1)逻辑回归模型是由以下条件概率分布模型表示的分类模型,可以用于二分类或多类分类,概率分布如下。

这里,x为输入特征,w为相应特征对应的权重。
逻辑回归模型源于逻辑斯蒂分布,其分布函数F(x)是s型函数。逻辑回归模型是由输入的线性函数表示的输出的对数概率模型。
逻辑回归模型一般采用极大似然估计,或正则化的极大似然估计,可以形式化为无约束最优化问题。求解该最优化问题的算法有梯度下降法、拟牛顿法等。
逻辑回归的优点:①便利的观测样本概率分数;②对逻辑回归而言,多重共线性并不是问题,它可以结合L2正则化来解决;③逻辑回归广泛应用于工业问题上。
逻辑回归的缺点:①当特征空间很大时,逻辑回归的性能不是很好;②不能很好地处理大量多类特征或变量;③对于非线性特征,需要进行转换;④依赖于全部的数据。
如果想继续了解逻辑回归与其他算法,比如朴素贝叶斯、Adaboost等的关系,可以参见文献 [2]、[3]。
2)分类决策树模型是表示基于特征对实例进行分类的树形结构。决策树可以转换成一个if—then规则的集合,也可以看作是定义在特征空间划分上的类的条件概率分布。
决策树学习旨在构建一个与训练数据拟合很好,并且复杂度小的决策树。因为从可能的决策树中直接选取最优决策树是NP完全问题。现实中学习次优的决策树。
决策树学习算法包括3部分:特征选择、树的生成和树的剪枝。常用的算法有ID3、C4.5和CART。
特征选择的目的在于选取对训练数据能够分类的特征。特征选择的关键是准则。常用的准则如下。
①样本集合D对于特征A的信息增益(ID3)。
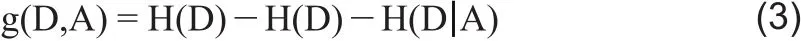
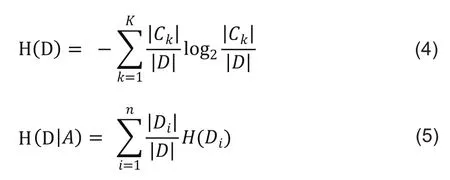
其中,H(D)是数据集D的熵,H(Di)是数据集Di的熵,是数据集D对特征A的条件熵,Di是D中特征A取第i个值的样本子集,Ck是D属于第k类的样本子集,n为特征A取值的个数,k是类的个数。关于ID3算法可见文献[4]。
②样本集合D对特征A的信息增益比(C4.5)。
其中,g(D,A)是信息增益,HA(D)是D关于特征A的值的熵。关于C4.5算法可见文献[5]。

③样本集合D的基尼指数(CART)。

特征A条件下集合D的基尼指数:
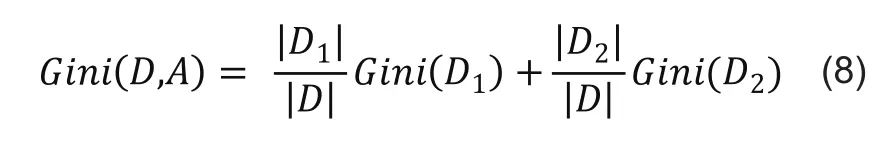
关于CART算法可见文献[6]、[7]。
④决策树的生成。通常使用信息增益最大、信息增益比最大或基尼指数最小作为特征选择的准则。决策树的生成往往通过计算信息增益或其他指标,从根节点开始,递归地产生决策树。这相当于用信息增益或其他准则不断地选取局部最优的特征,或将训练集分割为能够基本正确分类的子集。
⑤决策树的剪枝。由于生成的决策树存在过拟合问题,需要对它进行剪枝,以简化学到的决策树。往往从已生成的树上剪掉一些叶节点或叶节点以上的子树,并将其父结点或根结点作为新的叶结点。
决策树的优点:①直观的决策规则;②可以处理非线性特征;③考虑了变量之间的相互作用。
决策树的缺点:①直观的决策规则;②训练集上的效果易高度优于测试集,即过拟合。
3)随机森林。单模型分类方法模型往往精度不高,容易出现过拟合问题,因此很多学者往往通过组合多个单分类模型来提高预测精度,这些方法称为分类器组合方法。随机森林是为了解决单个决策树模型过拟合问题而提出的算法。随机森林是一种统计学习理论,它利用bootstrap重抽样方法从原始样本中抽取多个样本,然后对每个bootstrap样本进行决策树建模,然后组合成多棵决策树进行预测,并通过投票得到最终预测结果,分类公式如下。
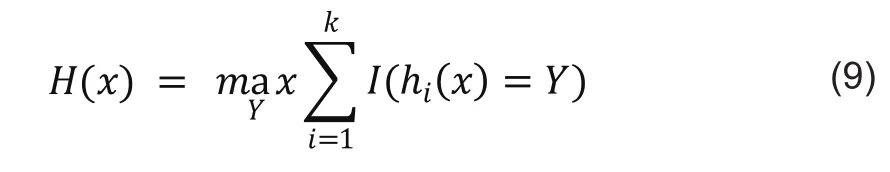
其中,H(x)表示随机森林分类结果,hi(x)是单个决策树分类结果,Y表示分类目标,I(.)为示性函数,通过投票策略max完成最终分类。
随机森林的优点:①对于很多类别,它可以产生高准确度的分类器;②它可以处理大规模的数据输入;③可以在决定类别时,顺便评估变量的重要性;④对于有缺失值的情况,它仍能维持较高的准确度;⑤对于不平衡的分类数据,它可以平衡误差。
随机森林的缺点:①随机森林被证明在某些噪声较大的分类或回归问题上会过拟合;②对于有不同级别的属性的数据,级别划分较多的属性会对随机森林产生更大的影响,所以随机森林在这种数据上产出的属性权值是不可信的。
关于随机森林算法可见文献[2]。
1.2 无监督式学习
与监督式学习不同的是,无监督式学习是学习数据集上有用的结构性质。通常学习数据集的概率分布、密度估计等。属于无监督式学习的算法有:关联规则、K-means聚类算法等。
1.3 强化学习
这个算法可以训练程序做出某一决定。程序在某一情况下尝试所有的可能行动,记录不同行动的结果并试着找出最好的一次尝试来做决定。属于这一类算法的有马尔可夫决策过程。
1.4 模型融合
用户流失预警模型面对的应用场景往往存在非常大的差异。例如新/老用户、高/低价值客户等等,这些不同的用户属性中,不同的机器学习分类算法往往都存在着不同的适用群体,不存在一个机器学习分类算法在所有情况下都胜过其他的算法。所以融合方法的思想就自然而然出现了,即充分运用不同机器学习分类算法的优势,取长补短,组合形成一个强大的用户流失预警框架,俗话说“三个臭皮匠顶个诸葛亮”;因此,模型融合可以增强预测的精度和泛化能力。劣势就是重计算造成了时间的损失,并且存在好坏不一的结合可能不如单个分类器效果好的风险,因此我们在模型融合之前,对模型使用Grid Search方法进行了单个模型最优参数的选择,保证模型融合之前的单个分类器预测结果是最优的。常用的模型融合方法有统一融合(Voting)、堆融合(Stacking)等。本文对3个基础模型采取投票制的方法,投票多者确定为最终的分类。
1.5 网格搜索
网格搜索(Grid Search)实际上就是暴力搜索, 它存在的意义就是自动调参,只要把参数输进去,就能给出最优化的结果和参数。首先为想要调参的参数设定一组候选值,然后网格搜索会穷举各种参数组合,通过调节每一个参数来跟踪评分结果,实际上,该过程代替了进行参数搜索时的for循环过程。根据设定的评分机制找到最好的那一组设置,即寻找最优超参数的算法。此外采用基于网格搜索的交叉验证法来选择模型参数,避免了参数选择的盲目性和随意性。
2 实例建模
主要介绍用户流失预警模型的生产系统布置反馈流程、模型输入字段属性及用户群确定、模型的具体实施流程,同时给出部分模型测试结果。
本模型以联通青海省4G用户数据为实例进行模型训练,得到最优模型参数,用于未来月份的用户是否流失的预测,给出流失清单、流失可能性得分、影响流失的重要因子。模型可用于用户维系、模型校验、模型优化等具体的场景
2.1 生产系统布署
模型从产生到生产系统落地应用主要分为8个步骤,分别为:确定目标用户群、模型预测、给出流失清单(得分、是否流失、重要指标)、用户维系、维系结果反馈、效果总结对比、模型的进一步优化、模型效果进一步校验,通过优化和校验再进一步指导模型的预测,提高模型预测精度。
2.2 建模主要阶段、步骤
数据准备的最终目的是形成宽表。关于宽表的细节表述请见文献[8]。宽表把流失预测可能使用到的各种属性都集成到了每月一张的表中,极大地方便了后面的流失预测工作。此外,在宽表中要添加一个重要属性,那就是是否流失。0为继续保持在网,1为预测为流失。这个属性的取值要根据之前在需求分析中约定的预测时间点来确定。
宽表中包括了用户流失预警模型所需的部分字段,主要包括用户的基本资料、用户的行为属性、根据原始属性产出的衍生指标以及我们的目标字段也就是用户当月是否流失的标识,如表1所示。
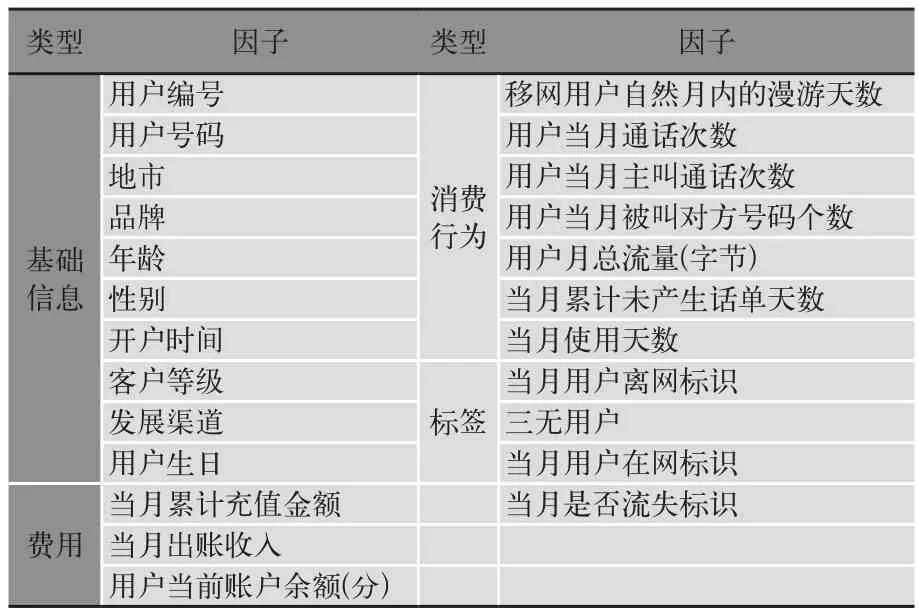
表1 宽表
以联通青海省4G用户的基本资料、用户产生的语音、流量、短信、资费等相关字段为依托的整个模型建设流程如图2所示,可以看出整个建模部分的流程主要分为6大部分,分别为:数据初步处理核查、数据清洗预处理、样本分割CV采样、模型库建立、网格搜索参数调优、最后的结果输出。
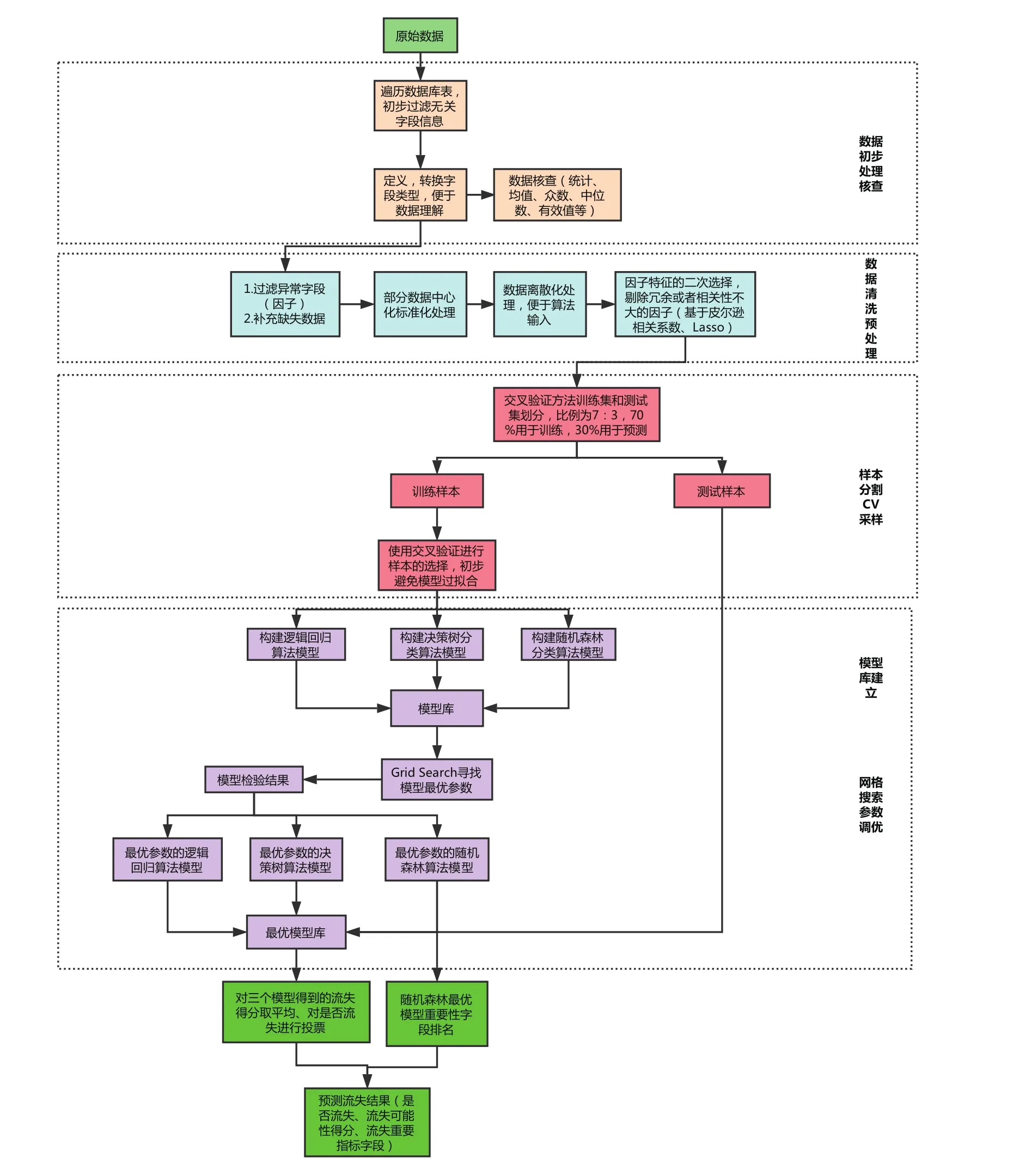
图2 模型建设流程图
其中第1部分我们首先遍历整个数据库表,初步整理及过滤掉无关重复的字段,定义并且转换模型所需要的数据类型及编码使得数据便于理解,同时会对数据进行描述性统计分析,查看其众数、中位数、均值、缺失值等基本信息;第2部分对数据做清洗预处理,基于第1部分得到的关于数据的初步描述过滤掉一些异常的字段因子,同时使用基于均值、中位数等方法对缺失值进行填充或者剔除,对部分连续性数据进行中心标准化或者离散化处理,这个时候会对字段基于相关系数、Lasso等方法进行二次选择,同时划分用户群;紧接着第3部分对筛选出来的数据基于交叉验证方法进行采样划分,划分的比例为7∶3,其中70%用于训练,30%用于测试;第4、5部分基于划分出来的训练集进行模型库的建立,本文建立逻辑回归、决策树、随机森林算法模型,基于全搜索方法建立充分参数的模型库,在模型库中基于Grid Search方法寻找到与训练数据和测试数据都表现良好的充分匹配的模型最优参数,进而得到各个算法的最优模型,这个时候对三个最优模型进行保存;第6部分对我们要预测的数据进行模型调用,这个时候可以得到三个最优模型关于要预测的数据的输出结果,主要包括流失的概率、是否流失标签、模型的重要性因子,基于模型的输出结果我们对三个模型进行结果的融合,主要包括对流失概率进行均值处理,对是否流失进行投票处理,同时基于随机森林得到的模型重要性因子进行从高到低排名,我们取最重要的5个因子作为输出,最后输出的结果包括用户的唯一标识、用户是否流失的标签、用户流失的可能性得分、用户在流失的最重要5个因子字段对应的数值,具体形式见表2。

表2 模型输出结果
本用户流失预警模型也可以尝试使用其他的分类算法,具体的细节可以学习文献[2]。
2.3 预测结果
在流失预警模型输入用户对应于宽表的相关字段数据,对用户是否在一定时间内流失进行预测判断,模型同时输出用户的流失可能性得分以及导致用户流失的重要性因子。
表3是逻辑回归、决策树、随机森林基于联通青海4G用户2017年5、6、7月份数据预测9月份数据得到的测试集上的结果。可以看出模型的预测指标效果从整体来说是令人满意的,其中逻辑回归效果差一点、决策树效果中等、随机森林预测效果最好。可见每个算法都有自己独有的特点,为了达到“三个臭皮匠顶个诸葛亮”的效果,也为了模型结果的稳定性,我们最后使用了模型融合方法,对三个算法的预测结果进行了融合,从融合结果来看,它比单个算法的效果要好。
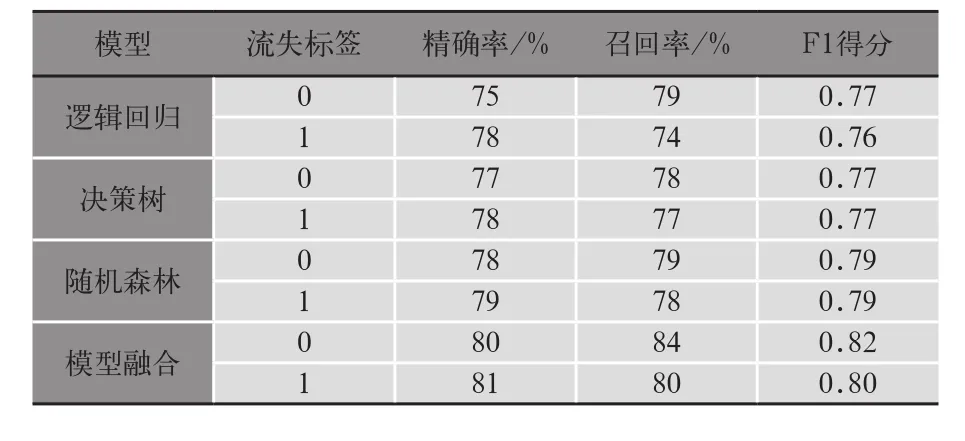
表3 默认模型预测效果评估关键指标
表4是基于2017年5、6、7月份数据使用网格搜索方法调优后预测9月份数据得到的测试集上的结果。可以看出三个算法的各个指标都有了比较明显的提升,最后模型融合的各个指标也相对提升了。说明网格搜索方法不仅节省了寻找模型最优参数的时间,同时与模型融合可以自动把模型预测效果提升,尽可能得到我们理想中的结果。

表4 网格搜索模型预测效果评估关键指标
3 建议
本文从运营商所面临的用户流失场景出发,结合实际情况分析了当前用户流失的现状,传统用户维挽的缺点,给出了使用机器学习算法建立用户流失预警模型对用户进行维挽的优势。介绍了文章使用的机器学习算法的相关理论、优缺点。给出了用户流失预警模型的实现框架,在实例建模部分给出了预测青海省相关用户流失的结果以及结果对比分析。
数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已,从模型结果来看,我们的预测效果还可以,但是如果想进一步提升预测的各个指标,可以参考从模型和算法方向给出的相关建议。
3.1 模型调优方向
1)依据前期模型理解与实操经验,改进前期模型存在问题。①进一步增加可能提高模型相应预测指标的字段,比如和用户各种费用相关的字段。②提高模型输入数据的品质,比如进一步增加特征提取,基于业务增加复合指标。③提高模型调优速度,比如基于业务经验进行相关参数的设定等。④进一步优化数据预处理方式:如不同的因子基于其特点,采用不同的方式进行数据清洗、中心化标准化、离散化;根据用户的特点采用聚类方式对用户进行进一步的划分;尝试更多的分类算法或者深度学习算法进行模型的不同方式的融合;不同的用户群,可采用不同的抽样比例进行分层抽样等等。
2)可以收集或者使用更多可用的原始数据,提取特征,优化模型,提高模型预测相关的指标。如用户累计欠费金额、累计充值次数、累计投诉次数等等。
3)紧密结合业务,结合实际的生产经验、更多期的数据反馈等,进一步提高模型的预测结果。
3.2 算法使用方向
现在深度学习在各个领域已经取得了比较优秀的结果,后续可以使用lstm等深度学习算法尝试预测用户是否流失。
[1]李航.统计学习方法[M].北京:清华大学出版社,2012
[2]周志华.机器学习[M].北京:清华大学出版社,2016
[3]Michael Collins,Robert E Schapire,Yoram Singer.Logistic regression,AdaBoost and Bregman distances[J].Machine Learning,2002,48(1-3):253-285
[4]Podgorelec V,Zorman M.Decision Tree Learning[J].2017,2:1751-1754
[5]金田重郎,Quinlan J R.C4.5 Programs for Machine Learning[J].Journal of Japanese Society for Artificial Intelligence,1995,5:475-476
[6]Breiman L,Friedman J H,Olshen R A,et al.Classification And Regression Trees[M].Wadsworth International Group,1984:17–23
[7]Ripley Brian D.Pattern Recognition and Neural Networks:Tree-structured Classifiers[M].Cambridge:Cambridge University Press,1996:233-234
[8]连建勇,李磊,陆勇.基于数据挖掘的电信客户流失预测模型研究[D].广州:中山大学,2008
