基于改进人工蜂群算法的支持向量机时序预测*
2018-04-27曹志冬
刘 栋, 李 素, 曹志冬
(1.北京工商大学 计算机与信息工程学院 食品安全大数据技术北京市重点实验室,北京 100048; 2.中国科学院 自动化研究所 复杂系统管理与控制国家重点实验室,北京 100190)
0 引 言
支持向量机(support vector machine,SVM)[1],有效克服了非线性、过学习和局部极小值等问题;在众多领域的理论分析和实际应用中取得巨大成功,一度被公认为是机器学习领域的最佳算法。核参数寻优对于SVM具有决定性影响,现有优化方法[3~5]仍存在难以规避的问题。相比其他智能算法,人工蜂群[6](artificial bee colony ,ABC) 算法独有角色分工转换机制能平衡算法的全局和局部搜索,较大程度地摆脱局部最优,增大全局最优解的获取机率,且算法易实现、搜索精度高、控制参数少、鲁棒性强,但受限于自身进化方式和选择策略,实际应用中有待进一步加强[6,7]。粒计算是海量信息处理的一种新的计算范式,使大数据背景下复杂性、模糊性问题及满意近似解的研究逐渐成型,如模糊信息粒化理论[8](theory of fuzzy information granulation,TFIG)。
本文通过改进各分工蜂群的搜索机制进行SVM参数寻优,并引入信息粒化技术进行上证指数变化趋势和变化空间的建模预测来证明所提出方法的优越性。
1 支持向量回归
(1)
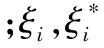
(2)
式中K(xi,x)为核函数,在线性不可分的情况下引入。
2 经典ABC算法
设原问题解空间维数是D,j∈{1,2,…,D}。搜索开始,引领蜂根据式(3)进行领域搜索并更新食物源位置
vij=xij+φ(xij-xkj)
(3)
式中j为随机整数,k∈{1,…,NP}且k≠i,代表从NP个食物源中随机选取一个不等于i的食物源,φ~U(-1,1)决定xij邻域的取值范围。当新食物源Vi=[vi1,…,vij]优于Xi,贪婪选择将Vi代替Xi;否则,保持Xi不变。待所有引领蜂已完成搜索和更新,立即进入信息交换区以摇摆舞的方式分享食物源信息。跟随蜂根据既得食物源信息,参照一定概率Pi并按轮盘赌来选择跟随引领蜂,首先在区间[0,1]上生成一个服从均匀分布的随机数r,若Pi>r,按式(3)进行邻域搜索,并以与引领蜂相同的贪婪选择策略确定要保留的食物源(或解)
(4)
式中fiti为解的适应度值评价,通常为最小化优化问题
(5)
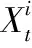
3 基于改进ABC算法的TFIG-SVR框架
3.1 经典ABC算法的改进
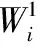
(6)
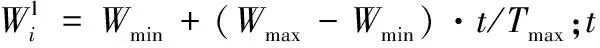

(7)
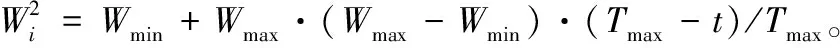
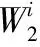
3.2 TFIG-SVR技术优越性的理论推导
对SVM引入TFIG构建TFIG-SVR,并进行几何论证:1)基于原始样本空间进行粒划分并在每个粒上进行支持向量训练,实现将非线性问题转化为若干线性可分问题,来获得一系列决策函数;2)这种学习策略增强了模型的泛化能力和拟合精度,有利于回归预测[9,10];如图1,传统SVR将整个样本特征空间用一个连续回归超平面F拟合,而GSVR则把特征空间划分为一系列子空间,然后基于子空间构建SVR来获得回归超平面F*,根据统计学及不敏感损失函数理论,F*相比F具有间隔更宽的超平面。因此,GSVR机制增强了模型的拟合精度,降低了算法时间复杂度,抑制过学习而获得了更强的泛化能力,另外,拟合过程的可并行实现又进一步提高了学习效率。其中,三角型模糊粒子可用于多决策性问题,因此,本文采用Pedrycz W所提出的三角形模糊集信息粒化方法[11]来构建TFIG-SVM模型。
图1 TFIG-SVR拟合示意
3.3 TFIG-SVR设计
文献[2,3,9,10,12]表明:高斯核即径向基核函数(radial basis function,RBF),具有优良的非线性拟合性能,其参数包括:σ表征核的宽度(核函数径向作用范围);C控制分类或回归超平面复杂程度和异常点数间的平衡,影响模型泛化性能;ε描述决策函数对预测误差不敏感区域的宽度,即真实值与预测值的差落在预定区间内,则认为无损失;反之,则有损失。本文采用改进ABC算法对SVR进行参数优化,并将SVR预测值的均方误差作为目标函数:minf(C,σ,ε),得TFIG-SVR及其算法流程如图2。
1)参数初始化。ABC算法基本参数设置、最大、最小惯性权重Wmax和Wmin以及适应度函数如式(5),fi为预测值与真实值的均方根误差; SVR相关参数元组(C,σ,ε)。
2)引入Pedrycz W模糊粒化方法处理原始数据,使Low,Mean,Up为三角型模糊粒子的参数,代表样本数据变化趋势的支撑下限、核和支撑上限。
3)利用改进ABC算法进行参数寻优。将参数三元组(C,σ,ε)抽象为食物源,通过C,σ和ε取值重新初始化蜂群,使引领蜂和跟随蜂按式(6)和式(7)搜索,并按经典ABC算法步骤执行和跳转,直到满足算法结束条件,来获得最佳参数元组(C,σ,ε)best,嵌入SVR对粒化数据进行回归预测。
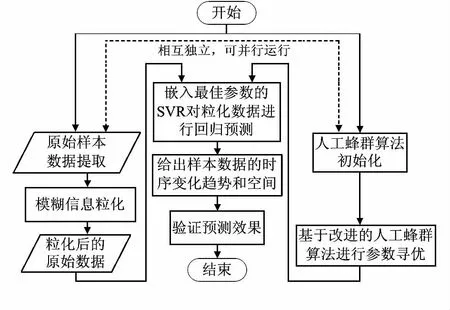
图2 基于改进人工蜂群算法的TFIG-SVR
3.4 模型时间复杂度计算
本文将构建网格搜索(gridsearch)[2]、粒子群优化(PSO)算法[3]、遗传算法(GA)[4]、蚁群优化(ACO)算法[5]和人工蜂群算法的SVR模型(设为x-SVR表1作为对照实验,将SVR时间复杂度统一设为定值O(f(n)),那么x-SVR时间复杂度仅须比较其核心智能算法。其中采用文献[2]中网格搜索算法,其时间复杂度可粗略估计为O(n3)。设NCircle为进化代数,n为种群规模,D为决策变量的维数,当n→D得表 1。其中,改进ABC算法时间复杂度与D无关仅取决于n;如果n足够大,低次幂项可忽略,那么改进ABC算法与其经典算法相比,几乎不需要额外付出时间耗费,另外,蚁群算法时间复杂度最高。

表1 x-SVR模型时间复杂度比较
4 实例应用与分析
收集上证指数1990年12月19日~2016年1月14日所有交易数据,包括收盘指数、指数最高值、指数最低值、当日交易量、当日交易额,预测后续5个交易日收盘指数的变化趋势和变化空间如表2。

表2 2016年1月15日至2016年1月21日上证实际收盘指
4.1 实验参数设定
1)gridsearch-SVR的惩罚参数C和核参数γ的设定,学术界并未明确限定,但C过高会陷入过学习,所以,本实验设定为[-8,8]和[-8,8](取以2为底的幂指数值),步距为1,相当于进化两代;2)考虑到样本数据规模较大,将PSO-SVR、ABC-SVR、改进ABC-SVR、GA-SVR和ACO-SVR相同参数设置为:种群进化代数为200,种群规模为20,损失函数ε的取值范围为(0,1],核函数相关参数γ的取值范围为(0,1],罚参数C的取值范围(0,100],其余参数均按算法最优性能设定;3)权重参数设定,最大惯性权重Wmax和最小惯性权重Wmin参照文献[13]设定。
4.2 实验结果分析
将引入TFIG的PSO-SVR、ABC-SVR、改进ABC-SVR、GA-SVR和ACO-SVR用于上证收盘指数预测,得到x-SVR模型2016年1月15日~21日收盘指变化空间结果如表 3。改进ABC-SVR预测所得收盘指数变化空间与表2中实际收盘指数最为接近,其次是PSO-SVR,ABC-SVR,GA-SVR,gridsearch-SVR,ACO-SVR表现最差,甚至产生了支撑预测空间支撑下限大于支撑上限的预测错误。
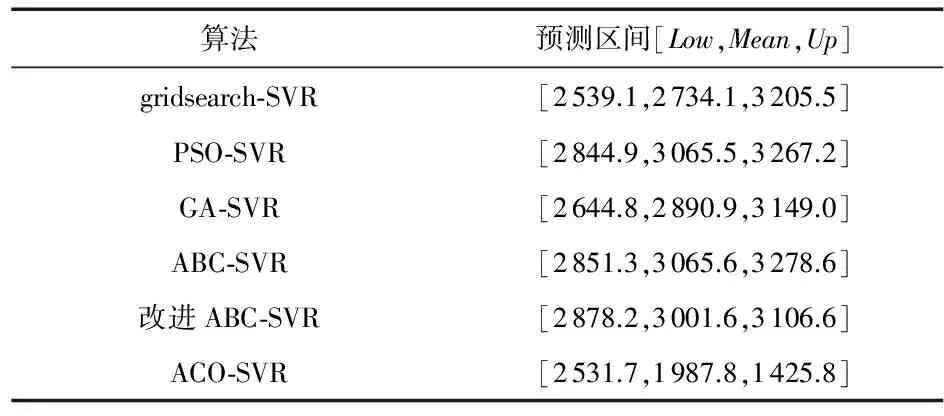
表3 x-SVR模型最终预测结果比较
上限参数Up是证券收盘指数预测最为核心的评价指标,由图3上限参数Up预测值的均方根误差随进化代数的变化可看出,ACO-SVR产生的误差值最大,预测精度不高,相比其他预测模型存在较大差距,说明蚁群算法不适合连续型时间序列预测与分析。改进ABC-SVR均方根误差最小,预测精度最高,其次依次为PSO-SVR,ABC-SVR,GA-SVR。在收敛速率上,PSO-SVR在算法早期率先达到稳定状态,但后期收敛速率变慢;GA-SVR相对于其他算法明显早熟,进化40代后进入成熟状态,对新空间的探测能力极为有限,且模型不稳定,易陷入局部最优;而改进的ABC-SVR和ABC-SVR初期算法进化过程相似,但改进ABC-SVR比ABC-SVR收敛速度更快,预测精度更高,且更早成熟。

图3 上证收盘指数预测迭代
为进一步对比x-SVR性能,基于主频2.7 GHz实验平台的MATLAB R2012b上运行程序,得到x-SVR的实际运行时间(s)和参数Up的预测平均绝对百分比误差(MAPE)如表 4,x-SVR运行时间与表1中对于x-SVR时间复杂度的公式推导结果完全吻合。如表4,智能算法中改进ABC-SVR和PSO-SVR模型训练速率明显快于ABC-SVR和GA-SVR;预测精度方面,改进ABC-SVR进化40代时就已经明显超过其他所有模型进化200代所能够达到的预测精度,且运行时间和网格搜索接近;另外,网格搜索回归精度与ABC-SVR接近,但运行时间不到ABC-SVR的1/4,网格搜索算法拥有进一步改进的潜力,表明:大数据条件下,简单模型往往具有更强的泛化能力和回归效能,如网格搜索法。
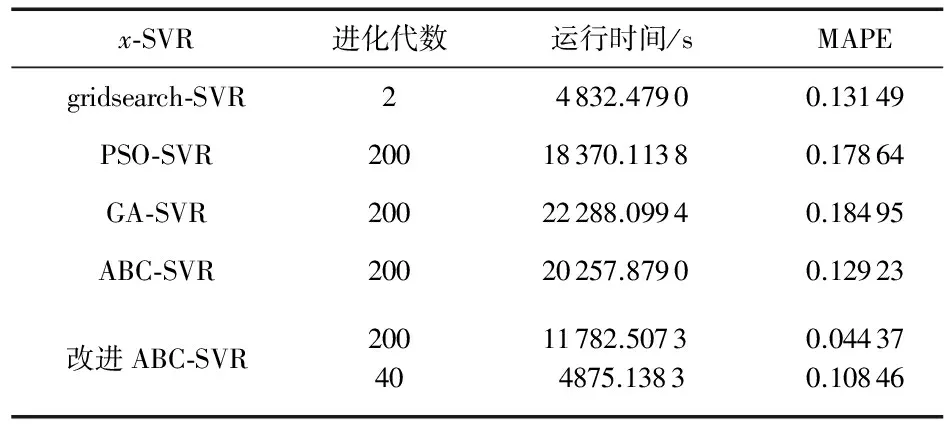
表4 x-SVR模型效能对比
5 结 论
1)继承经典ABC算法技术优势,同时提高了其收敛速率和预测精度;2)所提出算法在进化40代在回归精度和预测性能上可以明显超过其他智能算法,该方法对诸如关注效率和性能的数据样本也具有良好的通用性和可借鉴性;3)能在一定程度上摆脱局部最优和早熟限制,具有良好的泛化性能;4)与基线实验网格搜索模型相比,即使在算法时间耗费方面,算法进化40代达到可接受精度的前提下运行时间与大规模样本数据下的简单模型接近,5)以模糊信息粒化技术进行变化空间和趋势预测,规避了复杂结构数据难以追求问题最优解及定量化精确描述的困局。
参考文献:
[1] Chapelle O,Vapnik V,Bousquet O,et al.Choosing multiple parameters for support vector machines[J].Machine Learning,2002,46:131-159.
[2] Ma X Y,Zhang Y B,Wang Y X.Performance evaluation of kernel functions based on grid search for support vector regression[C]∥The 7th International Conference on Cybernetics and Intelligent Systems & IEEE on Robotics,Automation and Mechatronics,2015:283-288.
[3] Xiao T J,Ren D,Lei S H,et al.Based on grid-search and PSO parameter optimization for support vector machine[C]∥The 11th World Congress on Intelligent Control and Automation,2014:1529-1533.
[4] 崔小勇,林 宁.基于遗传模拟退火算法的无线传感器网路由协议[J].传感器与微系统,2016,35(7):32-34.
[5] 倪 壮,肖 刚,敬忠良,等.改进蚁群算法的飞机冲突解脱路径规划方法[J].传感器与微系统,2016,35(4):130-133.
[6] Basturk B,Karaboga D.An artificial bee colony(ABC)algorithm for numeric function optimization[C]∥Proceedings of IEEE Swarm Intelligence Symposium,Indianapolis,USA,2006:651-656.
[7] Karaboga D,Basturk B.A comparative study of artifieal bee colony algorithm[J].Applied Mathematics & Computation,2009,2(14):108-132.
[8] Zadeh L.Toward a theory of fuzzy information granulation and its centrality in human reasoning and fuzzy logic[J].Fuzzy Sets Syst,1997,90:111-127.
[9] 徐 计,王国胤,于 洪.基于粒计算的大数据处理[J].计算机学报,2015,38(8):1497-1517.
[10] Wang W J,Guo H S.Granular support vector machine based on mixed measure[J].Neurocomputing,2013,101(3):116-128.
[11] Pedrycz W.Knowledge-based clustering-fromdata to information granules[M].New Jersey:John Wiley & Sons,Inc,2005.
[12] Cheng X,Guo P.Short-term wind speed prediction based on support vector machine of fuzzy information granulation[C]∥25th Chinese Control and Decision Conference,CCDC 2013,2013:1918-1923.
[13] Nickabadi A,Ebadzadeh M M,Safabakhsh R.A novel particle swarm optimization algorithm with adaptive inertia weight[J].Applied Soft Computing,2011,11(4):3658-3670.
