基于深度稀疏辨别的跨领域图像分类
2018-04-19,
,
(复旦大学 计算机科学技术学院,上海 200433)
0 概述
随着快速移动通信技术的发展,图像、视频等多媒体信息数量与日俱增,图像分类技术在目标检测、图像检索和视频监视等实际应用领域都起着至关重要的作用。然而,在实际应用中,源领域(训练数据集)和目标领域(测试数据集)的数据由于图像来源不同,领域之间特征空间和特征分布往往具有一定的差异,使得源领域训练出来的图像分类模型不能很好地作用于目标领域。例如,训练图像来自商家拍摄的背景干净、图像清晰、角度直接的高分辨率图像,而测试图像来自消费用户拍摄的图像,图像分辨率低、背景杂乱,常常带有噪音,训练图像和测试图像的特征分布具有较大差别。
对于跨领域分类问题,一种传统的解决方法就是重新收集测试图像领域的图像并进行标注,在此基础上训练一个新的分类模型。当测试集图像数量较大时,人工标注的工作需要耗费巨大的人力、财力和时间成本。当在测试集领域上收集到的图像数量较少、图像多样性不足,直接在测试集领域上训练出来的分类器易于过拟合,缺乏鲁棒性。为解决以上问题,无监督跨领域分类研究如何利用源领域已标注数据学习目标领域知识,对无标签测试集进行分类。
跨领域分类问题研究的难点在于源领域与目标领域具有不同的特征空间和特征分布,同时目标领域缺少标注信息。本文构建一种基于深度卷积网络(CNN)[1]的跨领域模型框架——稀疏辨别性迁移分类模型(Sparse Discriminating Transfer Model,SDTM)。SDTM模型通过在深度网络Softmax分类层的训练过程中自适应学习目标领域特征空间分布,通过调整分类边界的方向与垂直于目标领域的高辨别性高方差方向,构成深度稀疏辨别性迁移网络Deep-SDTM。Deep-SDTM同时具有深度神经网络和SDTM的迁移能力。最后在2个跨领域分类标准数据集Office-Caltech[2]和Office-31[3]上,对比SDTM深度迁移模型与其他一系列特征预处理方法。
1 相关工作
根据处理角度的不同,跨领域分类方法可以分为特征预处理方法和迁移学习方法。预处理方法分析样本选择偏差和相关性变量以最小化领域之间差异,或者保留如方差和几何结构等重要的数据属性,使得特征可以适用于不同领域之间。例如,GFK[2]保持领域间几何结构,以此作为跨域的不变性特征属性。联合分布适应(JDA)[4]使用最大化均值差异来估计跨领域分布的距离,并使用主成分分析(PCA)构建跨领域特征子空间学习跨领域知识。迁移分量分析(TCA)[5]扩展MMDE[6]学习传递组件,是一种有效的核非线性学习方法,应用单个预定义的核函数进行核映射。SDTM与这些预处理方法(如JDA)具有良好的结合能力,取得了非常好的互补作用并实现了分类精度的提升。
迁移学习方法对训练过程中的分类模型进行调整,或者使用核函数学习[7]和度量学习[8-9]的方法,学习适用于目标领域的分类模型。随着深度学习在图像识别领域的研究和发展,深度卷积神经网络(CNN)被证明是一种具有良好迁移能力的分类模型[10]。深度领域混合模型(DDC)[11]通过添加网络适应层和数据集移位损失来学习领域的不变特征表示。深度适应网络(DAN)[12]侧重于增加深前馈网络的可迁移性,通过学习核函数[13]来减少领域间差异。在实验中,本文将基于深度网络的Deep-SDTM迁移框架与现有的一些无监督的深度CNN转移学习模型[11-14]在标准测试集上进行比较。实验结果表明,该方法可以获得最佳的性能。
跨领域分类模型SDTM模型分类边界调整方式如图1所示。

图1 跨领域分类模型SDTM模型分类边界调整方式
2 深度跨领域图像辨别性多分类模型
2.1 问题定义

2.2 网络模型架构
深度神经网络具有很好的迁移能力,然而由于目标领域数据集较小而且缺乏目标领域标签,传统的在深度卷积网络之中进行微调(fine-tune)的方式不再适用于跨领域分类问题。所以,SDTM模型使用预训练的深度网络参数,并对分类层进行调整构成深度稀疏辨别性转换模型Deep-SDTM(如图2所示)。 Deep-SDTM网络中包含五层卷积层作为特征提取层、两层全连接层和一层分类器层的分类预测层。之后修改最后一层分类器损失求解函数,令分类器学习带标签的源领域数据信息及无标签的目标领域特征分布信息,从而优化网络权值适应跨领域分类问题。
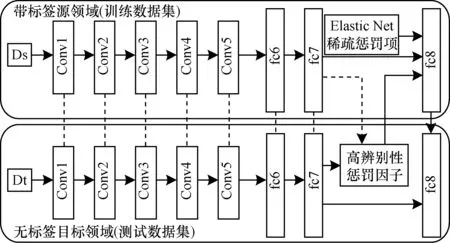
图2 基于CaffeNet fc7的Deep-SDTM跨领域分类模型架构
在SDTM模型中,首先借鉴了主成分分析(PCA)的思想。引入目标领域特征空间的多重主方向特征向量,使分类边界保持在目标领域的特征空间的辨别性。图1展示了当分类简化为二分类并且仅仅选取一个主方向进行约束时,原分类边界自适应调整的方式,在训练过程中原始分类边界向垂直于目标领域特征空间第一主方向的朝向进行调整。SDTM中对于目标领域多重主方向进行学习,使源领域训练的分类器更好地契合于整个目标空间。此外,在SDTM中引入了稀疏性约束,对于非结构化图像数据的稀疏高维特征进行特征选择,保持对于源领域和目标领域都更为重要的特征维度。
当分类为二分类问题时,类标签y只可以取2个值(正或者负),而多分类问题中y可以有大于2个的多值选择,y可以将函数指向不同的类。SoftMax回归模型广泛适用于单标签的多分类问题,Deep-SDTM最后一层分类层网络使用M类的逻辑斯蒂的SoftMax分类器表示。源领域的多分类函数表示为:
(1)
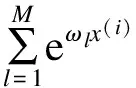
(2)
为了更好地理解目标空间的特征分布,模型提取多个保持高信息属性的主特征向量形成辨别性惩罚因子Linf(ω)。Linf(ω)被引入到损失函数的求解之中,帮助分类器在调整决策边界的过程中更好地使其对于目标领域特征空间有分辨作用(如图1所示)。在跨领域分类问题中,随着深度特征等高维度特征的广泛使用和训练数据的不足,在fsrc的训练过程中常常会过拟合。因此,可以认为训练集的特征空间是高维而稀疏的。为了更好地进行特征选择去除冗余特征,同时增加稀疏惩罚项Lspr(ω)到分类函数fsrc的训练之中。Lspr(ω)使用Elastic Net惩罚因子,它结合lasso回归和岭回归的共同优势,在训练模型中选取出对于跨领域分类最有效的子集。综上所述,目标领域分类器fsrc的损失函数Ltar(ω)可以重构为如下形式:
Ltar(ω)=Lsrc(ω)+μLinf(ω)+λLspr(ω)
(3)
其中,超参数μ和λ用于决定迁移学习因子和稀疏因子的权重。保持目标领域多维度辨别性因子Linf(ω)帮助理解目标数据集的特征分布,稀疏约束Lspr(ω)帮助对于高维特征进行更有效的特征选择。
2.3 基于目标领域的多维度辨别性因子
模型基于目标领域特征方差最大化的思想,使得分类器训练过程中可以对于目标空间的特征有着更大的辨别率,因此提高了测试集的分类效果。在SDTM模型中,使用多个主特征向量的组合因子来微调源领域上训练的分类器决策边界,使得分类模型在测试空间上更有辨别性,多维度辨别性因子表示为:
Linf(ω)=
(4)
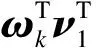
2.4 稀疏惩罚因子
在统计学习中,采用无偏估计训练参数极易产生过拟合的状况。为了减少过拟合情况,引入Elastic Net缩减和约束参数,在保持分类精度最大化和经验风险最小化的同时,降低预测模型的复杂度。在原有的损失函数Lsrc(ω)中增加稀疏约束:
(5)
其中,第一项用于减少分类函数的过拟合程度,第二项控制特征选取的稀疏性。函数中通过超参数λ1和λ2分别调控正则化程度和稀疏化程度的大小。
在SDTM模型中,正则化项和稀疏化项同时与辨别性因子相互作用,起到对于目标领域特征选择的结果。稀疏化项Lasso惩罚将更多维度的线性回归系数减小到零,生成稀疏模型。相应地,正则化项零回归惩罚因子减轻函数的稀疏性,增加特征非零权重的维度,同时保持调整函数过拟合的作用。当单独使用稀疏惩罚项的时候,通常稀疏惩罚过大,从而导致观察量过少;或者稀疏惩罚过小导致函数过拟合,分类函数常常表现不尽理想。Elastic Net规范项保持了Lasso稀疏化项和零回归正则化项的双重优势,因而在SDTM模型中使用Elastic Net规范项进行特征选择。
2.5 参数求解
求解稀疏辨别性转换模型,实验采用批梯度下降求解最小化目标函数,由于线性回归仅有一个最优点,因此梯度下降求解SDTM线性回归预测模型并不会陷入局部最优,其梯度损失函数表示为:
G(ω)=Lsrc(ω)+μLinf(ω)+λLspr(ω)
(6)
其中,G(ω)表示一个nsrc×M的响应矩阵(n表示训练数据的实例个数,M表示领域内类数目)。一般来说,选择主方向特征向量的个数是一种权衡的过程:过低的迁移学习能力,或者过大的噪声。
3 实验结果与分析
实验中首先探索基于SDTM模型的跨领域分类层对于传统SURF特征的分类性能,然后比较在SDTM模型下深度卷积网络各个网络层的迁移能力,最后比较基于深度网络的SDTM模型与近年来领先的深度跨领域分类方法的分类精度。
3.1 实验准备
Office数据集[3]是一个在跨领域图像分类问题广泛使用的标准数据集。它包括3个现实应用的场景:Amazon,Webcam和DSLR,每个领域包括相同的31个类。Caltech-256[15]是另一个用于目标识别问题领域的标准数据源,它与Office数据集拥有10个共享类。实验同时在31类Office-31数据集和包含10个共同类的Office-Caltech联合数据集测试和比较SDTM模型。
实验使用目标领域数据集的分类精度对实验进行评价,即目标领域分类正确的图像数量与目标领域总图像数量的百分比值。
在训练过程中,分类层之前包括conv1层~fc7层均采用CaffeNet[16]在ImageNet数据集上的预训练网络参数[1],分类层辨别性因子Linf(ω)选择目标领域前10个主方向特征向量进行自适应学习。
3.2 实验对比方法
实验SDTM模型与一系列的跨领域分类方法进行比较,其中包括基于特征和实例的预处理方法、基础迁移学习模型及深度迁移模型。
3.2.1 基准方法
NN使用基于1-最近邻的方法在带标签的源数据集上进行训练[2,6]。主成分分析方法(PCA)则是在NN的训练方式之前使用主成分分析对特征进行降维降噪处理。SVM和基于Lasso惩罚的逻辑斯蒂回归模型(L1-LR)则是基于线性分类模型对源领域各个类的特征分别训练并组合成多分类模型,以此预测目标领域中每个无标签实例的归属类。
3.2.2 预处理与基础迁移学习模型
TSL[17]采用Bregman 散度代替MMD中的距离量度方法用以进行分布比较。TCA[5]是一种传统的基于MMD惩罚和PCA模型的迁移学习方法。GFK[2]是通过插入中间子集到目标领域和源领域之间来探索跨领域间的共通点。JDA[4]在MMD的基础上同时调整特征的边缘分布和条件分布来实现跨领域分类。ILR[18]通过在逻辑斯蒂回归模型增加分布约束保持分类模型具有识别目标领域最大方差方向特征的能力。TJM[19]在降维的过程中,通过匹配跨领域间的特征并重新调整实例权重来保持源领域和目标领域间的一致性。
3.2.3 基于深度学习的迁移学习模型
LapCNN[1]是一种基于Laplacian图正则化的深度卷积神经网络的半监督变体方法。CNN[1]是2012年ImageNet竞赛上的主要模型,它生成的深度特征具有很好的迁移学习能力[10]。JDA[4]+CNN[1]在基于深度神经网络的模型对比中是一个很强的基准方法,它结合预处理方法JDA和深度卷积神经网络。DDC[11]在深度神经网络中的第二层全连接层(fc7)和第三层全连接层(fc8)之间增加一层运用单核MMD进行惩罚的自适应层,来学习领域间的不变性特征表示方式。DAN[12]通过将网络层与基于Hilbert空间的核函数相结合,生成一种全新的深度迁移网络模型,并用一种优化的多核选择方法减少领域之间的差异。
3.3 分类层SDTM评价与分析
实验首先探索分类层SDTM的迁移能力与传统非基于深度学习的跨领域方法的分类效果对比。然后使用SURF进行特征提取,通过聚类将SURF特征集成为800维的特征向量作为输入向量,基于Office-Caltech的10个公共子数据集进行实验。跨领域图像分类标准数据集Office-Caltech图像示例如图3所示。表1中将SDTM模型与其他跨领域分类模型的分类效果进行比较,包括JDA、TCA等特征预处理方法和ILR等迁移模型算法。
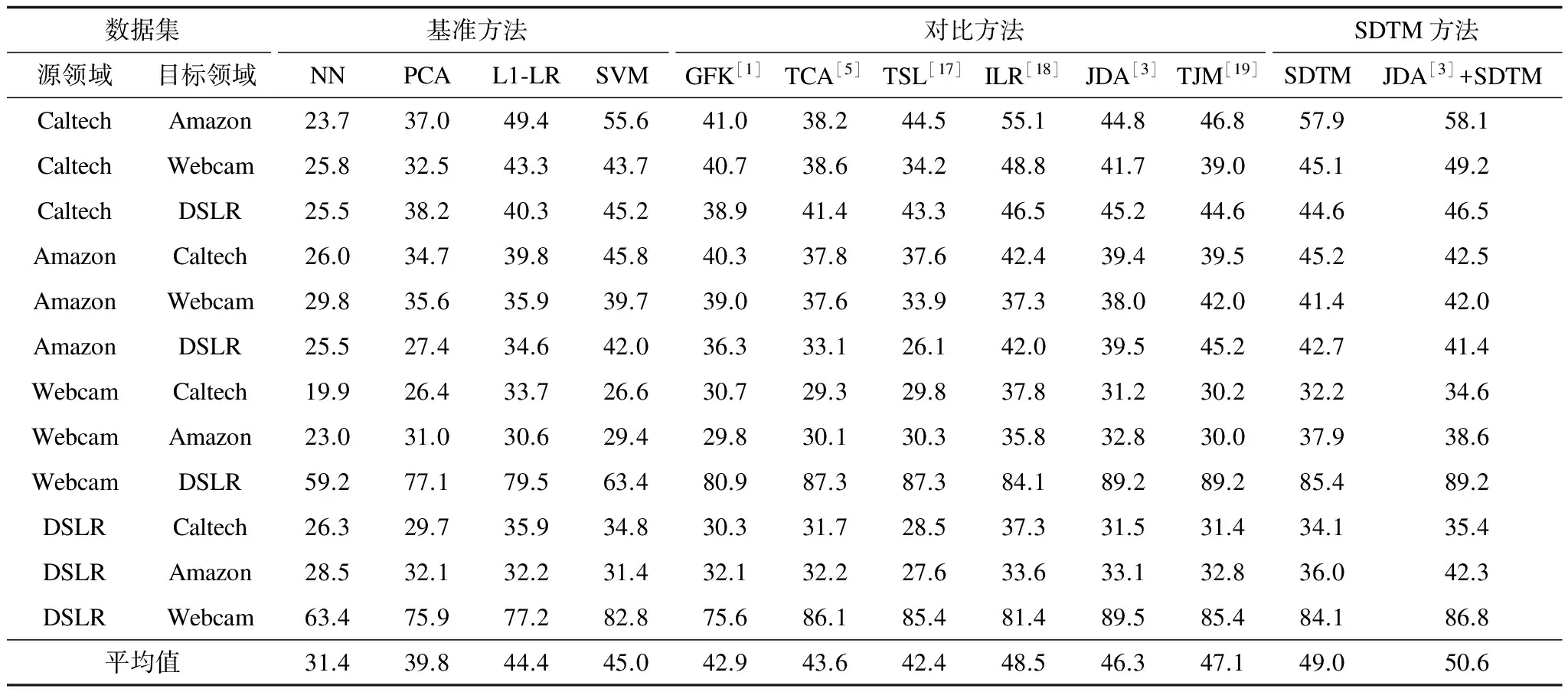
表1 Office-Caltech跨领域分类标准数据集上基于SURF特征的分类精度 %
实验中SDTM通过主方向的引入和多重因子的综合来微调分类器分类平面方向,大大提高了领域自适应能力。SDTM集成模型(JDA+SDTM)实现最佳性能,平均精度为50.55%,其次是单一SDTM和ILR,分别为48.96%、48.5%。
3.4 各深度卷积神经网络层迁移性分析
实验探索Deep-SDTM模型在深层卷积神经网络架构中各层输出上的迁移能力。一般来说,在学习卷积神经网络权重时,更深的层有更强的抽象能力,有助于表示图像的更深语义。因此,通过所选择的层来优化表示基于CNN特征的问题极为重要。为进一步探讨,实验使用最后一层卷积层以及各个全连接层的特征来评估实验模型的迁移能力。如图4所示分类精度变化,其中,A、W、D、C分别表示Amazon、Webcam、Dslr、Caltech 4个不同领域。基于第二全连接层(fc7)的Deep-SDTM在大多数领域之间表现出最强的迁移能力,唯一例外是由第1个全连接层(fc6)在Caltech->Amazon的领域分类上获得,但在平均性能上fc6小于fc7约4.7%。因此,实验采用基于fc7与分类输出层进行连接,Deep-SDTM中辨别性因子和稀疏性因子作用于整个深层神经网络的最终分类层fc8(如图2所示)。

图4 Office-Caltech跨领域分类标准数据集上深度卷积网络各层与Deep-SDTM结合分类效果
3.5 Deep-SDTM网络结构评价与分析
实验将基于SDTM的深度网络模型与DDC[11]和DAN[12]等领先的CNN迁移模型相比较,探索Deep-SDTM的跨领域分类效果。在实验中,调整稀释惩罚参数λ1、λ2和辨别性因子参数μ,会对跨领域分类效果产生影响。调整参数μ在控制目标领域高辨别性方向对于分类边界的作用,调整λ1和λ2控制模型的稀疏性和分类参数的复杂性。实验发现,对于如深度卷积特征等高维高信息抽取率的特征来说,通过稀疏控制进行特征选择起着更为重要的作用,而对于缺乏智能化学习能力的SURF等传统特征而言,使用较大的辨别性因子进行自适应学习则更为显著。实验中为了测试性能的稳定性,使用了恒定的参数值进行对比评价。
表2展示了不同的方法对10类Office-Caltech转移学习问题的卷积神经网络在表2中的结果。与近年提出的方法DAN相比平均提高2.5%。“SDTM+预处理”模型精度提高了3.7%,从86.1%提高到89.8%。相比之下,“CNN+预处理”将精度从84%提高到86.1%,只提高了2.1%。

表2 Office-Caltech跨领域分类标准数据集上基于深度神经网络的分类精度 %
表3展示了Office-31数据集的分类精度。与表2中的实验相似,实验将Deep-SDTM模型与深度模型(如CNN,LapCNN,DDC和DAN)进行比较,并于表3中测试31个类别中Deep-SDTM在Amazon、Webcam和dslr 3个数据集的迁移学习能力性。结果表明,基于预处理的SDTM模型获得最佳平均精度为74.6%。
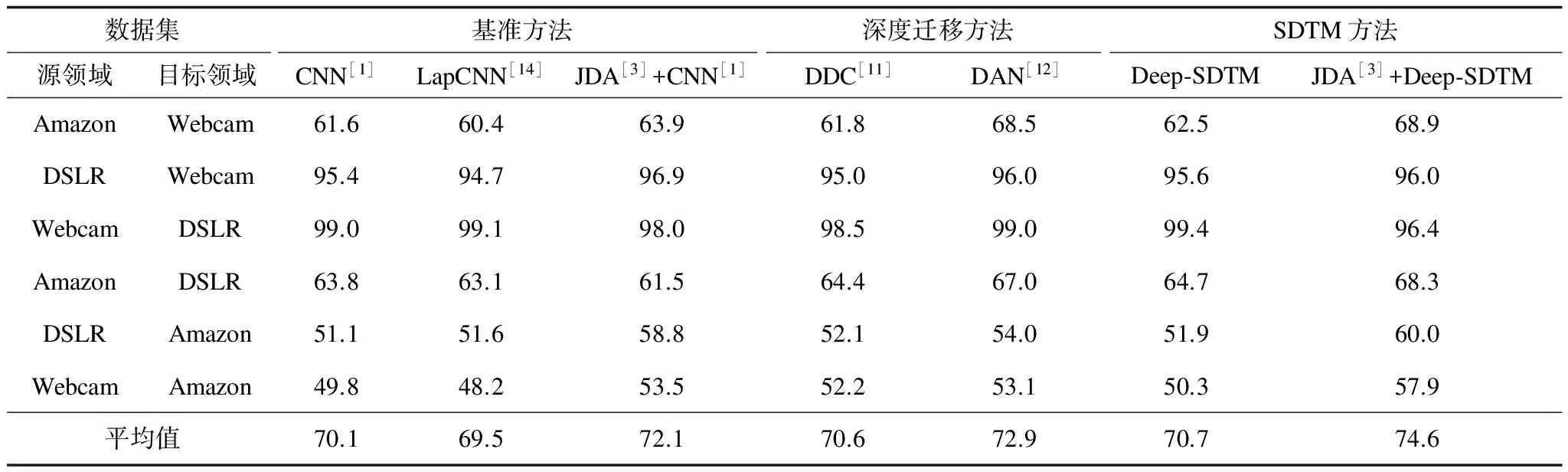
表3 Office-31跨领域分类标准数据集上基于深度神经网络的分类精度 %
在表3中,“SDTM+预处理”结合模型精确度提高了3.9%(从70.7%到74.6%),而CNN结合模型“CNN+预处理”仅仅增加了2.1%(从70.1%到72.1%),是SDTM模型提高性能的一半。实验结果表明,与预处理方法相结合的Deep-SDTM模型比其他组合方法更有效地提高领域间的迁移能力。
4 结束语
针对现实生活中常见的训练和测试领域间特征分布差异的问题,本文建立稀疏辨别性迁移模型SDTM及其对应的跨领域深度卷积神经网络Deep-SDTM网络结构,该网络结构具有不同网络层的迁移能力及其灵活的结合能力,与传统的基于特征的预处理方法有较强的互补作用。实验结果表明,SDTM模型提升了跨领域分类的分类精度,具有较好的跨领域学习能力。
[1] KRIZHEVSKY A,SUTSKEVER I,HINTON G E.Image classication with deep convolutional neural networks[C]//Proceedings of Advances in Neural Information Processing Systems.South Lake Tahoe,USA:MIT Press,2012:1097-1105.
[2] GONG Boqing,SHI Yuan,SHA Fei,et al.Geodesic flow kernel for unsupervised domain adaptation[C]//Proceedings of 2012 IEEE Conference on Computer Vision and Pattern Recognition.Washington D.C.,USA:IEEE Press,2012:2066-2073.
[3] SAENKO K,KULIS B,FRITZ M,et al.Adapting visual category models to new domains [C]//Proceedings of ECCV’10.Crete,Greece:Springer,2010:213-226.
[4] LONG Mingsheng,WANG Jianmin,DING Guiguang,et al.Transfer feature learning with joint distribution adapta-tion[C]//Proceedings of IEEE International Conference on Computer Vision.Portland,USA:IEEE Press,2013:2200-2207.
[5] PAN S J,TSANG I W,KWOK J T,et al.Domain adaptation via transfer component analysis[J].IEEE Transactions on Neural Networks,2011,22(2):199-210.
[6] PAN S J,KWOK J T,YANG Qiang.Transfer learning via dimensionality reduction[C]//Proceedings of AAAI’08.Chicago,USA:AAAI Press,2008:677-682.
[7] WANG Hao,WANG Wei,ZHANG Chen,et al.Cross-domain metric learning based on information theory [C]//Proceedings of AAAI’14.Quebec City,Canada:AAI Press,2014:2099-2105.
[8] DUAN Lixin,TSANG I W,XU Dong.Domain transfer multiple kernel learning[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2012,34(3),465-479.
[9] WANG Wei,WANG Hao,ZHANG Chen,et al.Transfer feature representation via multiple kernel learning[C]//Proceedings of AAAI’15.Austin,USA:AAAI Press,2015:3073-3079.
[10] YOSINSKI J,CLUNE J,BENGIO Y,et al.How transferable are features in deep neural networks? [C]//Proceedings of Advances in Neural Information Processing Systems.Montréal,Canada:MIT Press,2015:3320-3328.
[11] TZENG E,HOMAN J,ZHANG Ning,et al.Deep domain confusion:maximizing for domain invariance[EB/OL].[2014-10-21].http://pdfs.semanticscholar.org/.
[12] LONG Mingsheng,CAO Yue,WANG Jianmin,et al.Learning transferable features with deep adaptation networks [C]//Proceedings of ICML’15.Lille,France:[s.n.],2015:97-105.
[13] 彭 敏,傅 慧,黄济民,等.基于核主成分分析与小波变换的高质量微博提取[J].计算机工程,2016,42(1):180-186.
[14] WESTON J,RATLE F,MOBAHI H,et al.Deep learning via semi-supervised embedding[M].Germany,Berlin:Springer,2012.
[15] GRIN G,HOLUB A,PEROAN P.Caltech-256 object category dataset[D].Pasadena,USA:California Institute of Technology,2007.
[16] JIA Yangqing,SHELHAMER E,DONAHUE J,et al.Caffe:convolutional architecture for fast feature embedding[C]//Proceedings of the 22nd ACM Inter-national Conference on Multimedia.Orlando,USA:ACM Perss,2014:675-678.
[17] DACHENG S S,GENG T B.Divergence-based regulariza-tion for transfer subspace learning[J].IEEE Transactions on Knowledge and Data Engineering,2010,22(7):929-924.
[18] ZHU Guangtang,YANG Hanfang,LIN Lan,et al.An informative logistic regression for cross-domain image classification[C]//Proceedings of International Conference on Computer Vision Systems.Copenhagen,Denmark:Springer,2015:147-156.
[19] LONG Mingsheng,WANG Jianmin,DING Guiguang,et al.Transfer joint matching for unsupervised domain adaptation[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition.Columbus,USA:IEEE Press,2014:1410-1417.
