一种带标签的协同过滤广告推荐算法
2018-04-19金紫嫣1b华薇
金紫嫣, ,,1b,,华薇
(1.南昌大学 a.计算机科学与技术系; b.软件学院,南昌330031; 2.共青科技职业学院,江西 共青 332020)
0 概述
目前,我国互联网广告已经有千亿级规模,搜索广告已成为在线广告的重要形式[1]。广告产业已从逐渐形成有针对性投放,广告投放价值可精准度量,发展成为用户友好型、广告客户有益型的广告市场[2]。搜索引擎收益(Revenue Per Search,RPS)是搜索广告推荐系统成功与否的重要评价指标之一,它可以通过搜索广告的计价方式(如CPC、Cost Per Click)与广告吸引用户点击的能力点击率(Click-Through Rate,CTR)来反映,即RPS=CTR×CPC[3]。因此,如何准确预测CTR并合理利用其进行广告推荐具有重要意义。
文献[4]将基于用户的协同过滤算法应用到广告推荐领域,将用户与广告推荐系统中的Query页面相对应、商品与广告推荐系统中的广告相对应、用户对商品的评分矩阵用CTR相对应,即待推荐Query页展示与其相似的Query页上的广告,可获得较高的CTR。文献[5]提出一种无位置偏见的协同过滤广告推荐算法,该方法考虑了广告位置对CTR的影响,利用页面和广告的相关性代替用户对商品的评分。文献[6]将对CTR的预测问题转换成排序问题,把CTR作为已知有用信息加入至推荐模型中,使用每个广告的预测权重值对广告进行排序。影响CTR的因素有点击量和展现量两个方面:其中影响点击量的因素有广告的创意、展现形式、相关性、展现位置等,影响展现量的因素有广告关键词的数量、质量、出价、推广地域及时段等。而且,在相关性计算中,广告关键词同样担当重要角色,其可以有效反映广告与Query的匹配程度。因此,充分考虑广告关键词对CTR的影响并改进传统相似性度量方法,是提高广告推荐质量的关键之一。
社会化标签(Social Tag)是Web2.0时代集体智慧的表征,是建立用户与资源之间的桥梁。标签系统不仅在音乐、电影、图书等领域得到了广泛的应用[7],也在广告推荐中得以应用。目前,标签广告推荐方法主要通过分析标签(广告关键词)、用户和资源(广告)三者之间的关系获得其推荐规则。比如,文献[8]提出一种改进的FolkRank广告推荐方法,在用户、资源、标签三元组中进行迭代计算,求出推荐标签。其中资源对应于广告推荐系统中的广告,标签对应于广告关键字。文献[9]分析用户在不同时间间隙中行为轨迹的相似性,将时隙间相似度作为权重值,将用户在不同时隙浏览的广告进行协同推荐处理。因此,如何合理找到标签推荐技术与协同过滤技术结合点,充分挖掘广告关键词、Query页、广告之间的关系,是提高广告推荐质量的关键之一。
本文在标签技术和系统过滤方法的基础上,将广告关键词作为标签引入Query页相似性计算中,采用Query页加权综合相似度度量方法,降低相似矩阵稀疏性,提出一种基于广告关键词的广告搜索兴趣模型Q-K-A(Query-Keywords-AD)。
1 相关定义
本节主要介绍与ADR-CF_T算法相关的Q-K-A兴趣偏好模型、加权相似度计算以及广告预测点击率等相关概念。
1.1 Q-K-A兴趣偏好模型
基于用户的协同过滤推荐主要是研究用户之间的关系[10],采用最近邻域技术,通过分析目标用户的兴趣偏好信息向其推荐符合其兴趣偏好的项目。然而,对于搜索广告实际应用背景,建立Query页之间的兴趣偏好模型仍需要考虑诸多因素。点击率(CTR)可以反映用户所输入的请求(即输出的Query页)对搜索引擎所选择展现广告的偏好程度。由于广告关键词因素不仅影响广告的展现量,又在影响点击量的相关性计算中充当重要角色。因此,考虑在Query页-广告的二维兴趣偏好模型中加入广告关键词因素,建立充分描述Query页偏好程度的三维兴趣偏好模型。基于广告关键词的Q-K-A兴趣模型需要考虑三方面因素:与Query页相匹配的广告关键词信息,被Query页展现过的广告信息以及Query页相匹配的广告关键词和其选择展现的广告之间的关系。为此,引入如下定义。
假设IS=(Q,K,A,C)为信息系统,其中,Q={q1,q2,…,qm}为Query页集合,m为Query页总数,K={k1,k2,…,kn}为广告关键词集合,n为广告关键词总数,A={a1,a2,…,ar}为广告集合,r为广告的总数,C={cq,a|q∈Q,a∈A},cq,a表示在Q中的元素q上展现A中的元素a所产生的点击率。
定义1(广告标签) 令T={t1,t2,…,ts}为广告标签集合,其中s为广告标签的总数。对任意ti∈T,kj∈K(1≤i≤s,1≤j≤r),有ti=kj,当且仅当i=k。
定义2(广告) 给定信息系统IS=(Q,K,A,C),非空有限集表示所有广告点击数据集,对∀x∈D,有x=
(1)
定义3(点击行为矩阵) 设矩阵是一个m×n的矩阵,其中,m行代表集合Q,n列代表集合A,表示m个Query页对n个广告的点击情况。矩阵Rm×n的第i行第j列的元素rij为qi的兴趣因子,用qi展现aj产生的点击率cqi,aj表示,若qi展现aj,则rij等于cqi,aj;否则rij为0。即:
(2)
定义4(组合) 给定信息系统IS=(Q,K,A,C),设qi∈Q,al∈A(1≤i≤m,1≤l≤r)分别为任意Query页、广告,令qi相匹配的广告标签组合为Kqi,I(qi,kj,al)为qi的兴趣因子,且:
(3)
Kqi可定义如下:
Kqi={kj|kj∈K,I(qi,kj,al)=1},Kqi⊆K
(4)
定义5(相关关系组合) 给定信息系统IS=(Q,K,A,C),设qi∈Q,kj∈K,al∈A(1≤i≤m,1≤j≤n,1≤l≤r)分别为任意Query页、广告标签(关键词)、广告,令KAqi表示Query页qi对应的广告标签(关键词)和广告之间的相关关系的组合,I(qi,kj,al)为qi的兴趣因子,定义同式(3)。于是,可定义如下:
KAqi={
(5)
根据定义1~定义5,所提Q-K-A模型可做如下描述:
定义6(Q-K-A兴趣模型) 给定信息系统IS=(Q,K,A,C),令IM={IMi|i=1,2,…,m}为兴趣模型,设qi∈Q(1≤i≤m)为任意Query页,则qi的兴趣模型为IMi=(Rqi,Kqi,KAqi)。其中,Rqi表示qi的点击行为集合,Kqi表示qi相匹配的广告标签(关键词)集合,KAqi表示qi的广告标签(关键词)和广告间的相关关系。
1.2 相似度计算
基于用户的协同过滤算法的关键环节是如何寻找与目标用户偏好程度相似的用户,本文采用修正的余弦相似度度量,不仅可使相关度在数值上保持相近,也使得所有的评分曲线趋于平稳。令Ixy是用户和共同评分的项目向量组合,Ix和Iy分别表示用户和用户的评分项目向量,则用户和用户之间的相似度可以表示如下:
(6)
在基于广告标签的搜索广告推荐系统中,Query页面相似性主要取决于3个方面因素:Query页间的共击相似性,共配标签相似性以及共含关系相似性。本文为充分表示用户评分差异性Query,上述三方面因素分别采用修正余弦相似度度量方法[11]、两Query页之间共同匹配的广告关键词的比例以及页之间共同匹配的广告关键词与广告相关关系的比例来计算。同时本文通过综合加权的方法计算推荐算法中Query页间相似度以降低相似矩阵计算的稀疏性,并使用Top-N策略减少Query页的K-最近邻域候选集的大小。设待计算相似性的2个Query页分别为qi和qj,则相关定义如下:
定义7(Query页间共击相似性) 给定信息系统IS=(Q,K,A,C),设qi∈Q和qj∈Q(i,j=1,2,…,m)为2个Query页,则qi与qj之间具有共同点击行为时的相似性simQA(qi,qj)可定义为:
(7)

定义8(Query页间共配标签相似性) 给定信息系统IS=(Q,K,A,C),设qi∈Q和qj∈Q(i,j=1,2,…,m)为2个Query页,则qi与qj之间具有共同匹配的广告标签(关键词)的相似性simQK(qi,qj)可定义如下:
(8)
其中,Kqi、Kqj、Kqc分别是qi、qj、qc相匹配的广告标签(关键词)集合。
定义9(Query页间共含关系相似性) 给定信息系统IS=(Q,K,A,C),设qi∈Q和qj∈Q(i,j=1,2,…,m)为2个Query页,则qi与qj之间具有共同包含的广告标签(关键词)与广告相关关系的相似性simQKA(qi,qj),可定义如下:
(9)
其中,KAqi、KAqj、KAqc分别是qi、qj、qc对应的广告标签(关键词)和广告之间的相关关系的集合。
为降低相似矩阵计算的稀疏性,减少计算误差,基于定义7~定义9,通过综合加权的方法得到推荐算法中Query页间的综合加权相似度。
定义10(Query页间综合加权相似性) 给定信息系统IS=(Q,K,A,C),设qi∈Q和qj∈Q(i,j=1,2,…,m)为2个Query页,α≥0,β≥0,γ≥0为3个权重调和因子,且α+β+γ=1,则qi与qj之间的综合加权相似性Sim(qi,qj)可定义如下:
Sim(qi,qj)=αSimQA(qi,qj)+βSimQK(qi,qj)+
γSimQKA(qi,qj)
(10)
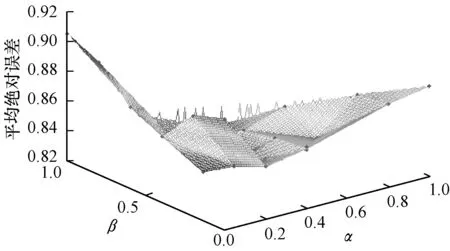
在本文中,式(10)的权重调和因子α、β、γ的具体值是根据实验参数调节的方法确定。
1.3 广告预测点击率
为获得高质量的广告推荐结果,带标签的协同过滤广告推荐算法思路如下:
1)对目标Query页qi与其他Query页qx(x=1,2,…,m,但x≠i)之间的综合加权相似度计算结果进行逆序排序(从大到小排序),采用Top-N策略取其中前K个相似度最高的Query页得到目标Query页qi的K-最近邻域NK(qi),并获得NK(qi)中Query页上所有展现过的广告集合作为候选推荐广告集A′。
2)以广告预测点击率为广告推荐衡量指标,对A′中每个候选展示的广告al(l=1,2,…,s,s≤r),计算其在目标Query页qi上展示时的预测点击率CTRpre(qi,al),结合CTRpre(qi,al)和Top-N策略从候选推荐广告集A′中筛选出最佳推荐广告集A*。
目标Query页K-最近邻域、候选推荐广告集和广告预测点击率分别定义如下:
定义11(目标Query页K-最近邻域) 给定信息系统IS=(Q,K,A,C),设qi∈Q为目标Query页,qx∈Q(x=1,2,…,m,但x≠i)为其他Query页,Sim(qi,qx)为qi与qx之间的综合加权相似度,δ>0为给定阈值,则qi的δ-邻域Nδ(qi)为:
(11)
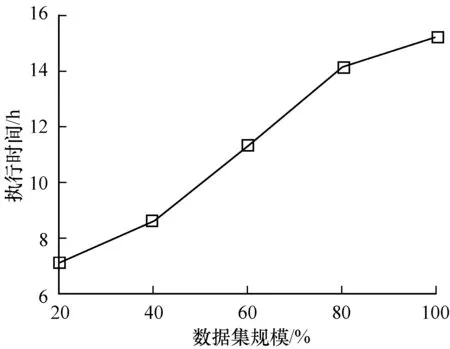
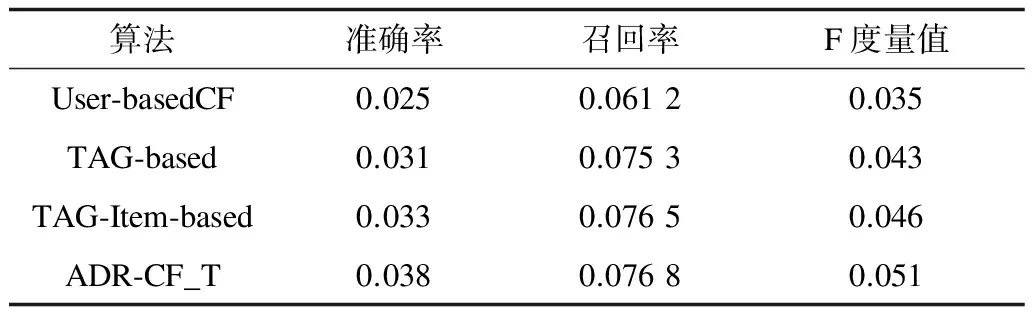
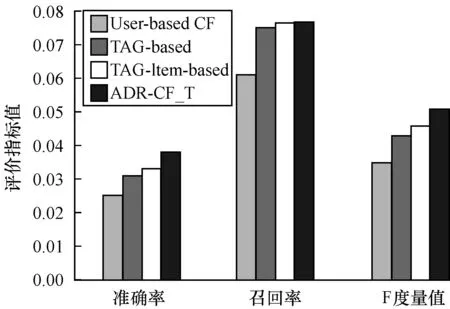
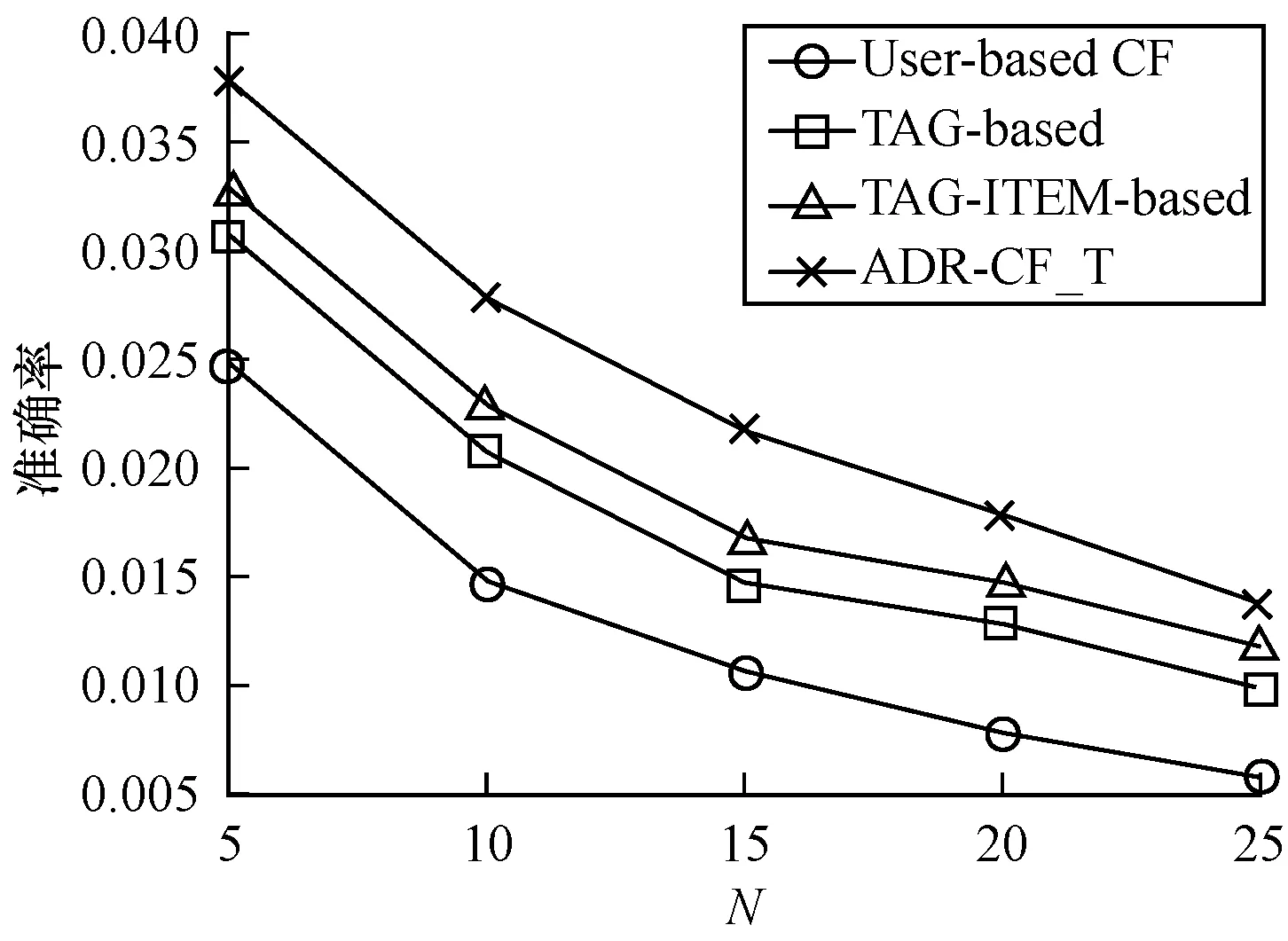
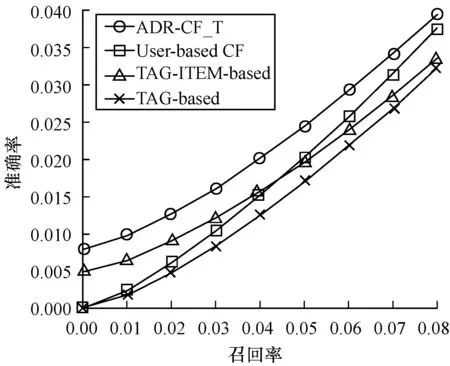
若将所有其他Query页与目标Query页的综合加权相似度序列按从大到小的顺序排序,记为S1≥S2≥…≥SK≥…≥Sm-1,其中K 定义12(候选推荐广告集) 目标Query页的K-最近邻域NK(qi)中Query页上所有展现过且目标Query页qi没有展现的广告构成集合称为候选推荐广告集,记为A′。显然,A′⊂A。 (12) 依据第1节给出的相关定义和算法设计思路,带标签的协同过滤广告推荐算法可描述如下: 算法带标签的协同过滤广告推荐算法ADR-CF_T 输入目标Query页qi(i=1,2,…,m),Query页集合Q(|Q|=r),广告关键词集合K(|K|=n),广告集合A,CTR集合C,邻居数N 输出目标Query页qi的最佳推荐广告集A* 步骤1对集合中的每个Query页qj,1≤j≤|Q|,j≠1,循环执行如下操作: 步骤1.1计算Query页间共击相似性SimQA(qi,qj)。 步骤1.2计算Query页间共配标签相似性SimQK(qi,qj)。 步骤1.3计算Query页间共含关系相似性SimQKA(qi,qj)。 步骤1.4计算Query页间综合相似性Sim(qi,qj)。 步骤2根据Sim(qi,qj),对集合中除了目标Query页qi的剩余对象从大到小排序。 步骤3选取集合中排序靠前的N个Query页为目标Query页qi的最近邻域N(qi)。 步骤4广告集合中的每个广告aj,1≤j≤|Q|,循环执行如下操作: 步骤4.1若目标Query页qi展现了广告aj,重新返回步骤4.1;否则,跳到步骤4.2。 步骤4.2将广告aj加入目标Query页qi的待展示广告集合A′中。 步骤5对于待展示广告集合A′中的每个广告aj,1≤j≤|A′|,循环执行如下操作:计算目标Query页qi对未展示的广告aj的预测点击率CTRpre(qi,aj)。 步骤6根据CTRpre(qk,aj),对待展示广告集合A′中的广告从大到小排序。 步骤7选取集合A′中预测点击率最高的前N个广告作为TOP-N最佳推荐广告集A*。 ADR-CF_T算法时间开销关键在于Query页之间的相似度计算,计算Query页间共击相似性SimQA上的时间开销与传统CF算法一致,都为O(m·r),计算Query页间共配标签相似性SimQK上的时间开销是O(m·n),计算Query页间共含关系相似性SimQKA上的时间开销为O(m·n·r),因此,ADR-CF_T算法的时间复杂度为O(m·n·r)。 本文选择KDDCUP2012[12]中track2的训练数据集作为实验数据。该数据提供了腾讯搜搜的搜索广告点击数据,共10.6 GB大小,149 639 105条数据。本文选取数据属性中的点击次数、出现次数、广告标示符、Query页面标示符、广告关键词标示符这5个属性作为搜索广告推荐系统的实验,即Click、Impression、AdID、QueryID、KeywordID。 本文首先对原数据进行随机抽样,选取其中的1 000 000条数据;根据本文实验的数据需求,删除其他7个属性列,并删除重复项后得到641 566条数据。其中Query页面290 479个,广告101 422个,广告关键词113 470个;其次,为了进一步避免严重的数据稀疏性问题,选择点击记录不少于30的Query页和广告,剩下19 436条数据,包含Query页10 936个,广告8 789个,广告关键词10 439个,在每个Query页面展现的广告中,随机选取80%的数据作为训练集,剩余数据作为测试集。 由于采取Top-N的推荐方式,本文实验采用对不同邻居数计算的准确率(Precision)、召回率(Recall)以及F度量(F-measure)来评价搜索广告推荐系统的质量。分别对它们进行如下定义[11,13-14]: 1)准确率是指为测试集中目标Query页推荐的广告集合Top(q)中,有多少广告是q展示过并且点击率较高的广告。令Result(q)是Query页在训练集中实际展现的广告集合,每个Query页推荐结果的准确率计算公式为: (13) 2)召回率又称作查全率,是指测试集中的推荐结果中,正确推荐所占的比例,则每个Query页推荐结果的召回率计算公式为: (14) 3)F度量是兼顾准确率和召回率的总体表现的综合指标。F度量的计算公式为: (15) 采用平均绝对误差(Mean Absolute Error,MAE)对各权重调和因子预测的准确度。对测试集中的一个Query页和广告,令CTRreal(q,a)为Query页对广告的实际点击率,CTRpre(q,a)为Query页对广告的预测点击率。则平均绝对误差(MAE)[14]的计算表达式为: (16) 3.3.1 参数调节 在带标签的协同过滤广告推荐算法中,其关键的相似度计算方法是对Query页间的共击相似性、共配标签相似性、共含关系相似性进行加权,使得相似性的计算更加准确。本文分别选取10%、20%、30%的数据集进行实验,通过对α、β遍历取值,观察MAE(α,β)的变化,权衡各相似性度量方法的权重。考虑到α+β+γ=1,因此,只取α、β作为因变量,实验结果如图1~图3所示。 图1 10%数据集权重调节因子对MAE的影响 图2 20%数据集权重调节因子对MAE的影响 图3 30%数据集权重调节因子对MAE的影响 从图1~图3可知,α、β的变化可以影响广告推荐算法的预测准确度,当0.2<α<0.4,0.4<β<0.6时,所提出的带标签的协同过滤广告推荐算法的性能最优。本文选取α、β、γ最优值分别为0.2、0.4、0.4。 3.3.2 可扩展性验证 为测试ADR-CF_T算法的可扩展性能,本文通过随机选取数据集规模的20%、40%、60%、80%的数据与整体数据集的执行时间进行对比,实验结果如图4所示。 图4 数据集规模与执行时间之间的关系 由图4可知,随着数据规模的增加,算法的执行时间从缓慢递增变化为急剧增加,又逐渐平稳递增。 可见,带标签的协同过滤广告推荐算法在数据规模增加的情况下,其执行时间的增长在可接受的范围内,故该算法具有较好的可扩展性。 3.3.3 推荐质量对比实验 在本文实验过程中将数据集分为训练集和测试集两部分,其中,训练集占80%,测试集占20%。通过Top-N输出推荐列表,并采用准确率、召回率、F度量值对实验的推荐质量进行评测。为了更明显地展现本文提出的带标签的协同过滤广告推荐算法的有效性,将权重调和因子α、β、γ分别调为1,即得到基于用户的协同广告推荐算法[3]、基于标签的广告推荐算法[15]、基于标签和项目关系的广告推荐算法[16]。为了比较以上3种算法和所提出的带标签的协同过滤广告推荐算法的推荐质量,本文设计了3组实验:即TOP5推荐各算法的推荐质量对比、不同N值下各算法的推荐质量对比、推荐质量优化程度对比。 1)TOP5推荐各算法的推荐质量对比 本文实验从准确率、召回率、F度量值3个方面,对所提出的带标签的协同过滤广告推荐算法与基于用户的协同广告推荐算法、基于标签的广告推荐算法以及基于标签和项目关系的广告推荐算法进行比较分析,根据广告推荐的实际应用情况,本文实验对每个页面推荐5个广告,即进行Top5推荐,实验结果如表1、图5所示。 表1 4种算法TOP5推荐实验评价指标结果 图5 不同推荐算法Top5推荐质量比较 通过对比发现,本文提出的带标签的协同过滤广告推荐算法在准确率上比传统协同过滤算法提高52%,在召回率上提高25%,在F度量值上提高46%,整体效果提高近41%。由于本文在计算Query页面之间相似性时,考虑了CTR、广告关键词以及广告关键词和广告之间的关系三方面因素的影响,综合的相似度计算方法可以有效地反映Query页对广告的偏好信息,广告关键词对于Query页和广告之间的相关性以及广告本身的特征进行较完整的描述。同时,本文提出的相似性度量的权重调和因子α、β、γ,通过分析发现其取值对推荐算法的预测准确度有较大的影响。 2)不同N值下各算法的推荐质量对比 最近邻居数的选择对推荐算法的推荐质量同样产生影响,因此,本文对比了最近邻居数选择为5、10、15、20、25、30的情况下,分别对基于用户的协同广告推荐算法、基于标签的广告推荐算法、基于标签和项目关系的广告推荐算法以及本文提出的带标签的协同过滤广告推荐算法的准确率、召回率及F度量值进行比较,其对比结果如图6~图8所示。 图6 不同N值下的准确率对比 图7 不同N值下的召回率对比 图8 不同N值下的F度量值 通过对比发现,当为每个页面推荐25个广告时,本文提出的带标签的协同过滤广告推荐算法与其他3种算法相比,在准确率上提高至少17%,在召回率上提高至少0.9%,在F度量值上提高至少21%。随着最近邻居数的增加,出现推荐效果不增反减的现象。这是因为在广告推荐系统中,真正相似的Query页面的数量有限。当选择更多的不相似邻居后,这些Query页面展现了来自不相似Query页面中的点击率较高的广告,导致推荐质量下降。因此,只有在广告推荐系统中正确地选择相似的Query页作为最近邻居,才能得到理想的协同推荐效果。 3)推荐质量优化程度对比 表2 不同算法的系数选择以及拟合优度指数 图9 推荐结果的准确率和召回率高斯拟合曲线 通过高斯拟合后的曲线看出,基于用户的协同广告推荐算法和基于标签和项目关系的广告推荐算法相比,随着召回率升高,两条曲线产生交点,根据表2中提供的系数可以求得交点坐标约为(0.047 2,0.016 8),则在召回率区间(0,0.047 2),基于用户的协同广告推荐算法的准确率低于基于标签和项目关系的广告推荐算法,其相差程度逐渐减小;在区间[0.047 2,0.08],基于用户的协同广告推荐算法的准确率高于基于标签和项目关系的广告推荐算法,并且相差程度逐渐增大。随着召回率增加,本文提出的带标签的协同过滤广告推荐算法的准确率明显高于其他3种算法,相比之下基于标签的广告推荐算法的准确率最低,与上一实验结果一致。 综上所述,通过分析广告关键词、广告及其之间的关系来构建Query页的兴趣度模型,计算综合的整体相似性,相对于利用CTR作为偏好信息以及广告关键词作为隐式偏好信息的方法,本文提出的广告推荐算法构建的Q-K-A兴趣度模型更加准确,具有较好的可扩展性,推荐的质量也得到了提高。 本文基于用户的协同推荐以及基于标签的推荐技术,探索标签与项目之间的关联关系,提出一种综合整体相似性的度量算法。该算法可正确地表达搜索广告推荐系统中Query页面的兴趣模型,使计算邻域的准确性得到保证,进而提高了推荐的准确性。实验结果表明,相比传统协同过滤算法、基于标签的推荐算法以及基于标签和项目关系的推荐算法,带标签的协同过滤广告推荐算法具有更好的可扩展性和更优的推荐质量。但该算法未考虑影响广告点击率的其他因素,如位置、出价等因素,因此,下一步将考虑与机器学习算法相结合,挖掘广告本身属性,提取特征信息,在实际应用中分析影响广告点击率的因素,提高推荐精确度。 [1] 王勇睿.互联网广告算法和系统实践[EB/OL].[2014-10-20].https://yuedu.com. [2] WANG Jinqiao,WANG Bo,DUAN Lingyu,et al.Interactive ads recommendation with contextual search on product topic space[J].Multimedia Tools and Applications,2014,70(2):799-820. [3] ANASTASAKOS T,HILLARD D,KSHETRAMADE S,et al.A collaborative filtering approach to ad recom-mendation using the query-ad click graph[C]//Proceedings of the 18th ACM Conference on Information and Knowledge Management.New York,USA:ACM Press,2009:1927-1930. [4] 霍晓骏,贺 樑,杨 燕.一种无位置偏见的广告协同推荐算法[J].计算机工程,2014,40(12):39-44. [5] MA H,LYU M R,ZHOU D,et al.Recommender systems with social regularization[C]//Proceedings of the 4th ACM International Conference on Web Search and Data Mining.New York,USA:ACM Press,2011:287-296. [6] 范双燕.基于广告点击率以及标签推荐图模型的广告推荐方法研究[D].北京:北京交通大学,2015. [7] 张国燕.基于标签的个性化广告精准营销系统设计与实现[D].武汉:华中师范大学,2013. [8] 范双燕,王志海,刘海洋.基于改进的FolkRank广告推荐及预测算法[J].软件,2014,35(9):43-48. [9] 田雪松.基于协同过滤的移动互联网广告推荐方法的研究[D].成都:西华大学,2016. [10] BREESE J S,HECKERMAN D,KADIE C.Empirical analysis of predictive algorithms for collaborative filtering[J].Uncertainty in Artificial Intelligence,1998,98(7):43-52. [11] JASCHKE R,MARINHO L,HOTHO A,et al.Tag recommendations in social bookmarking systems[J].AI Communications,2008,21(4):231-247. [12] KDDCup[EB/OL].[2012-12-21].http://acm.sjtu.edu.cn/courses/kddcup/2012. [13] NANOPOULOS A.Item recommendation in collaborative tagging systems[J].EEE Transactions on Systems Man & Cybernetics,Part A:Systems & Humans I,2011,41(4):760-771. [14] AMANDI A,GODOY D.Hybrid content and tag-based profiles for recommendation in collaborative tagging systems[C]//Proceedings of Latin American Web Con-ference.Washington D,C.,USA:IEEE Press,2008:58-65. [15] SCHLEE C.Targeted advertising technologies in the ICT space[M].Berlin,Germany:Springer,2013. [16] CANTADOR I,BELLOGIN A,IGNACIO F T,et al.Semantic contextualisation of social tag-based profiles and item recommendations[J].E-Commerce and Web Tech-nologies,2011,85:101-113.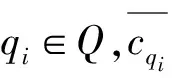
2 带标签的协同过滤广告推荐算法
3 实验结果与分析
3.1 数据预处理
3.2 评测指标
3.3 结果分析






4 结束语
