韩国语定语从句句法特征分析及其自动识别
2018-04-16安帅飞毕玉德
安帅飞,毕玉德,张 婷
(解放军外国语学院,河南 洛阳 471003)
0 引言
当前,语篇层面上的复句处理仍是机器翻译等应用系统面临的难点之一,如何将复句自动离析为单句成为许多人研究的重点。吴锋文[1]回顾了汉语复句二十年前的研究,概述了邢福义团队的汉语复句信息工程、张仕仁[2]在复句“功能结构树”及胡金柱等[3]在复句关系词提取等的研究工作。韩国语复句处理方面,刘洋等[4-5]利用连接词尾对并列类复句进行“解构化”处理,提出了对韩汉复句机器翻译的改进建议,并有效地实现了接续复句的自动提取实验。定语从句属于嵌套类复句,本文从定语从句入手,重点分析如何从嵌套类复句自动离析出单句的问题。
1 韩国语定语从句
韩国语中,仅有一对主谓关系的句子称为单句,有两组或两组以上主谓关系的句子称为复句[7]。根据语言的递归性,复句又划分为嵌套的包孕句与组合的接续句。韩国语句子分类体系如图1所示[8]。

图1 韩国语句子分类体系图
其中,韩国语包孕句下属的定语从句包孕句即为本文的研究对象*本文仅讨论单句作定语从句的情况,暂不讨论复句作定语(“”)和多重定语(“……”)问题。。
2 韩国语定语从句句法特征及其形式化表示
韩国语定语从句的基本构成为:定语修饰成分、冠形词形词尾、被修饰的中心词。可将其形式化为:AC→AM+ETM+Head*AC是定语从句(attributive clause)的简写;A是定语(attributive)的简写,M是modifiers修饰语的简写;ETM是冠形词形词尾在“韩国语21世纪世宗计划”语料标注体系的标注形式。。
根据定语修饰成分AM与中心词Head的关系,可将定语从句分为关系定语从句和同位定语从句[9]。
关系定语从句中,中心词Head充当定语修饰成分AM中的主语、宾语等句子成分。

同位定语从句中,中心词Head不作为AM的句子成分,与AM为同指关系。

另外,分析定语修饰成分AM的内部构成,可将定语从句分为长定语从句和短定语从句。长定语从句中,定语修饰成分AM是整个句子。短定语从句中,定语修饰成分AM是主语、谓语、宾语、状语等单句中的句子成分。所有的长定语从句均属于同位定语从句[10]。

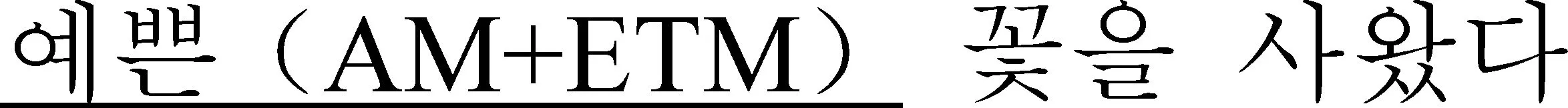
综上,定语从句的分类如图2所示。

图2 定语从句分类图
按照动词中心论观点[11],根据定语修饰成分AM中谓词的不同,本文将定语从句分为动词类AM、形容词类AM、系词类AM定语从句分别进行说明。
2.1 动词类AM定语从句
在语料观察实验中,利用WordSmith软件的Concord功能,将关键词设为ETM,共现词设为VV,从处理结果中选取500句定语从句进行人工观察分析,归纳总结动词类AM定语从句的类型*形容词类、系词类AM定语从句的观察实验与此相同,下文不再赘述。。
(1) 关系定语从句


除动词之外,动词类AM中往往还含有主语、宾语、状语等。根据语言学规律,结合在语料库中归纳分析,关系定语从句的构成可扩展为以下15种类型。
① 【主】+VV(+EP)+ETM+NP

主语在语料中的标记形式为:NP+主格助词JKS。因此,该类定语从句的形式化表示为“【NP+JKS】+VV(+EP)+ETM+NP”。
② 【宾】+VV(+EP)+ETM+NP;

宾语在语料中的标记形式为:NP+宾格助词JKO。因此,该类定语从句的形式化表示为“【NP+JKO】+VV(+EP)+ETM+NP”。
③ 【状】+VV(+EP)+ETM+NP


在定语修饰成分AM中,主语、宾语、状语等会交叉出现,且韩国语语序自由,各成分位置并不固定。各成分相互交叉,组合为以下形式。
④ 【主宾】+VV(+EP)+ETM+NP*受篇幅所限,组合类从句不再举例说明。下同。
在语料中体现为【NP+JKS】+【NP+JKO】+VV(+EP)+ETM+NP。
⑤ 【主状】+VV(+EP)+ETM+NP
在语料中体现为【NP+JKS】+【[AVM1—AVM6]】+VV(+EP)+ETM+NP。
⑥ 【状主】+VV(+EP)+ETM+NP
在语料中体现为【[AVM1—AVM6]】+【NP+JKS】+VV(+EP)+ETM+NP。
⑦ 【宾主】+VV(+EP)+ETM+NP
在语料中体现为【NP+JKO】+【NP+JKS】+VV(+EP)+ETM+NP。
⑧ 【宾状】+VV(+EP)+ETM+NP
在语料中体现为【NP+JKO】+【[AVM1—AVM6]】+VV(+EP)+ETM+NP。
⑨ 【状宾】+VV(+EP)+ETM+NP
在语料中体现为【[AVM1—AVM6]】+【NP+JKO】+VV(+EP)+ETM+NP。
⑩ 【主宾状】+VV(+EP)+ETM+NP
在语料中体现为【NP+JKS】+【NP+JKO】+【[AVM1—AVM6]】+VV(+EP)+ETM+NP。
在语料中体现为【NP+JKS】+【[AVM1—AVM6]】+【NP+JKO】+VV(+EP)+ETM+NP。
在语料中体现为【NP+JKO】+【NP+JKS】+【[AVM1—AVM6]】+VV(+EP)+ETM+NP。
在语料中体现为【NP+JKO】+【[AVM1—AVM6]】+【NP+JKS】+VV(+EP)+ETM+NP。
在语料中体现为【[AVM1—AVM6]】+【NP+JKS】+【NP+JKO】+VV(+EP)+ETM+NP。
在语料中体现为【[AVM1—AVM6]】+【NP+JKO】+【NP+JKS】+VV(+EP)+ETM+NP。
(2) 同位定语从句
同位定语从句分为长定语从句和短定语从句。
② 短定语从句中,定语修饰成分AM中不含终结词尾,中心词Head与长定语从句相同,基本构成为“VV(+EP)+ETM+NP”。短定语从句的AM、ETM构成与关系定语相同,同样可扩展出15种组合类型,不再详述。
2.2 形容词类AM定语从句
(1) 关系定语从句

定语修饰成分AM中,除了基本的形容词之外,往往还含有主语、状语等。因此,关系定语从句的构成可扩展为以下四种类型:
① 【主】+VA(+EP)+ETM+NP
主语在语料中的标记形式为“NP+主格助词JKS”。因此,该类定语从句的形式化表示为“【NP+JKS】+VA(+EP)+ETM+NP”。
② 【状】+VA(+EP)+ETM+NP

③ 【主状】+VA(+EP)+ETM+NP
该类结构在语料中体现为【NP+JKS】+【[AVM1—AVM6]】+VA(+EP)+ETM+NP。
④ 【状主】+VA(+EP)+ETM+NP
该类结构在语料中体现为【[AVM1—AVM6]】+【NP+JKS】+VA(+EP)+ETM+NP。
(2) 同位定语从句
同位定语从句分为长定语从句和短定语从句。
② 短定语从句中,定语修饰成分AM中不含终结词尾,中心词Head与长定语从句相同,基本构成为“VA(+EP)+ETM+NP”。短定语从句的AM、ETM构成与关系定语相同,同样可扩展出四种组合类型,不再详述。
2.3 系词类AM定语从句
(1) 关系定语从句

(2) 同位定语从句
同位定语从句分为长定语从句和短定语从句。

3 韩国语定语从句自动识别实验
实验时,按照前述定语从句句法结构特征,归纳分析其在语料中的左右边界规则和内部构成间的共现关系规则,构建定语从句识别规则集。根据识别规则集,对标注语料进行匹配运算,自动识别出定语从句。在此过程中,分析错误的识别结果,迭代完善规则集,最终自动识别出定语从句。具体流程如图3所示。

图3 韩国语定语从句自动识别实验流程图
3.1 实验语料及预处理
本文所用语料共80万句,来源于两处:①韩国政府为推动韩文信息化发展,自1998年开始实施、2007年建成的“21世纪世宗计划”标注语料库。该语料库涵盖新闻、小说、杂志等。本文从中选取了50万句。②网站抓取、后期整理后,获得政治、军事、外交、安全、经济、科技等新闻语句,利用UTagger分词器(标注体系与“21世纪世宗计划”标注语料相同)进行分词处理,得到30万句标注语料。
本文自动识别的对象是定语从句,其基本结构为“谓词+ETM+NP”。谓词分为单一谓词和复合谓词,在所用的标注语料中,单一动词、形容词被标记为VV、VA,派生动词、派生形容词的标记为“NNG -XSV、NNG -XSA”,合成动词、合成形容词的标记为VV-EC-VV|VX、VA-EC-VA|VX。为方便后期处理,在实验之初,使用正则表达式将复合动词、复合形容词的标记形式统一替换为VV和VA。


表1 惯用型词表

续表
3.2 韩国语定语从句的识别规则
定语从句的识别规则包含左右边界规则和从句内部结构的共现关系规则。
3.2.1韩国语定语从句的左右边界规则
根据第二节分析的定语从句句法结构特征,观察其在语料中的左右边界特征表现,并借此来界定定语从句。
(1) 左边界界定
通过观察语料及实验迭代分析,发现定语从句的左边界存在以下情况:
① 句子以定语从句开头,左边紧邻词不存在。

② 左边界紧邻词为连接词尾EC

EC作为连接复句的标志词,可作为其后定语从句的左边界。
③ 左边界紧邻词为冠形词形词尾ETM

该类定语从句含有双(多)重定语,本文从基本单元入手,分层级解决嵌套问题。
④ 左边界紧邻词为补助词JX

句中出现两个主语,主句的主语出现在从句的主语前,充当从句的左边界。
⑤ 左边界紧邻词为主格助词JKS

⑥ 左边界紧邻词为副词格助词JKB

⑦ 左边界紧邻词为宾格助词JKO

⑧ 左边界紧邻词为逗号SP、括号SS、特殊符号SW等

(2) 右边界界定
① 关系定语从句的右边界界定


② 同位定语从句的右边界界定

3.2.2韩国语定语从句内部构成的共现关系规则
根据3.2.1中的左右边界规则,得到了基本的定语从句,但对于含主语、状语、宾语等修饰成分的句子,无法判断主语等成分归属于主句还是从句。本文辅以定语从句内部构成间的共现关系规则解决这一问题。
(1) 根据语言学特征,结合在语料中的观察分析,得到确定的共现关系规则有四条:
② 根据左右边界规则抽取出的成分中,如含有两个主语(出现两个JKS),前一个JKS标识的主语归属于主句,后一个JKS标识的主语归属于从句;
③ 根据左右边界规则抽取出的成分,如是同位定语从句,主语、状语、宾语等修饰成分归属于从句;
(2) 对于无法确定归属的定语从句,计算内部构成成分间的共现频率,根据频率值来近似地估计各成分间的紧密关系,以判断其归属。下面以判断【NP+JKS】是否归属于形容词类AM定语从句为例进行说明。
在形容词类AM定语从句中,首先找到主语成分【NP+JKS】,其出现在ETM前,将该NP赋值为a1,然后找到定语从句的中心词,将该中心词赋值为a2,将AM中的形容词赋值为a3。计算并比较共现概率Count(a1,a3)/Count(a1)*Count(a3)与Count(a2,a3)/Count(a2)*Count(a3)。如果Count(a1,a3)/Count(a1)*Count(a3)的值大于Count(a2,a3)/Count(a2)*Count(a3),则认定主语成分【NP+JKS】与形容词的结合紧密度高于被修饰的中心词,【NP+JKS】归属于定语从句。反之,【NP+JKS】归属于主句。实验时,为解决数据稀疏问题,本文采用了加一平滑,对每个统计项都进行了加一处理[15]。
3.3 实验结果及评测
根据定语从句的识别规则集,对80万实验语料进行匹配运算,实现了定语从句的自动识别。将其中部分结果翻译展示如表2所示。

表2 定语从句自动识别实验结果表
为验证规则的可行性,本文借助了广泛应用于信息检索和统计学分类领域的正确率(P值)、召回率(R值),以及二者的加权平均F值,用来评价实验结果[16]。评测时,另外从新闻、小说、杂志三类语料中分别选取了500句进行实验,然后将人工分析得到的结果与程序自动识别的结果相比较,结果如表3所示。

表3 实验结果比对表
分别计算P、R、F的值结果如表4所示。
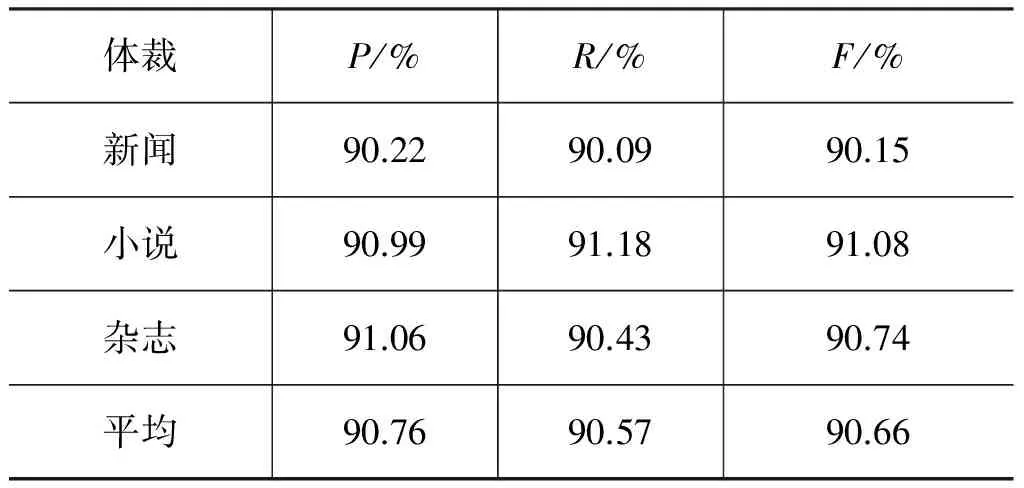
表4 实验评测结果表
经过比较分析,得到了实验中错误识别的定语从句有以下三个类型。
(1) 特殊符号(SW)导致的错误

(3) 语料标注错误

4 总结与展望
本文通过分析定语从句的句法结构特征,对其左右边界和内部构成成分的共现关系进行归纳总结,构建了定语从句识别规则集,实现了定语从句的自动识别。从嵌套类复句中自动离析出定语从句,为提高韩汉机器翻译、信息检索等应用系统的效能打下了坚实的基础。
本文主要讨论了单句作定语从句的情况,针对复句作定语及多重定语问题,以后将做进一步的分析研究。
[1]吴锋文.汉语复句信息处理研究二十年[J].中文信息学报,2015,29(1):13-18.
[2]张仕仁.汉语复句的结构分析[J].中文信息学报,1994,8(4):43-54.
[3]胡金柱,舒江波,姚双云,等.面向中文信息处理的复句关系词提取算法研究[J].计算机工程与科学,2009,37(10):90-93.
[4]刘洋,毕玉德,李健.基于句法知识的复句解构对韩汉复句机器翻译改进刍议[J].洛阳师范学院学报,2017,36(2):49-53.
[5]刘洋,毕玉德,李健.基于语言知识的韩国语复句自动识别策略及实现[J].东北亚外语研究,2017,17(2):42-49.
[6]安帅飞,毕玉德.韩国语名词短语结构特征分析及自动提取[J].中文信息学报,2013,27(5):205-210.
[7](韩)李翊燮.韩国语语法[M].郭一诚,译.北京:世界图书出版公司,2012:331.
[9]张光军,江波,李翊燮.韩国的语言[M].北京:北京大学出版社,2009:311-312.
[11]毕玉德.现代韩国语动词语义组合关系研究[M].北京:民族出版社,2005:27-28.
[13]韦旭升,许东振.新编韩国语实用语法[M].北京:外语教学与研究出版社,2006:613-617.
[14]李姬子,李钟禧.韩国语助词和词尾词典[M].张光军,译.北京:外语教学与研究出版社,2010.
[15]宗成庆.统计自然语言处理[M].北京:清华大学出版社,2008:78-79.
[16]冯志伟,胡凤国.数理语言学[M].北京:商务印书馆,2012:367.

安帅飞(1991—),博士研究生,主要研究领域为自然语言处理、模块识别。E-mail:anshuaifei2013@sina.cn

毕玉德(1967—),教授,博士生导师,主要研究领域为自然语言处理、韩国语句法语义学。E-mail:biyude@gmail.com

张婷(1984—),博士研究生,主要研究领域为自然语言处理、领域本体构建。E-mail:tinaam@sina.com
