基于OpenCL的DRR算法优化研究
2018-04-13田林琳
田林琳,李 莹
(沈阳工学院 信息与控制学院,辽宁 抚顺 113122)
1 概 述
放射治疗计划系统(TPS)是利用计算机软件技术、剂量计算方法、控制手段等,解决治疗过程中的精确定位、剂量计算的快速精确、保证目标剂量的准确实施以及治疗计划的优化等问题[1]。数字重建放射影像(DRR)是TPS系统中的关键功能,是通过模拟X光线的衰减过程,从CT断层数据中生成类似X光片的成像效果,这对于放疗过程中的质量控制具有非常重要的意义[2]。DRR可在任意三维空间角度下实现对病患的“透视”模拟,能够随意观察放射靶区、特定组织或器官,或靶区与周围器官间的空间关系,因为没有治疗床的限制,可利用DRR得到模拟定位机难以拍摄的图像。同时省略了使用模拟放射摄影图像的成像步骤,既节省了临床费用,也减少了对病患的辐射[3]。
在TPS的临床应用中,DRR具有重要作用,为了达到临床应用的目标,要求DRR能够准确、快速地反映放射治疗中的真实情况,并能够满足动态性、交互性的需要[4]。这也是三维图像可视化领域中,人们一直试图解决的两个问题:一是实时地进行图像绘制,在DRR的实际使用中,要求可以快速、多角度地生成图像;二是真实地显示结果,这要求计算结果能够真实、客观地反映其解剖结构在三维空间上的细节与特征[5]。
典型的DRR算法是以光线跟踪算法为基础,利用虚拟摄影机视图追踪光线至投影图像中的每一个像素,每一条光线所经过的体元数据进行累加,累加值与像素亮度值成正比,使用这种方法实现重建出的DRR图像显示精度和图像质量都非常好,满足了显示结果真实性的要求[6-7]。但由于此算法需要跟踪每条从虚拟光源发出的光线,涉及到大量的光线与CT三维体数据进行求交测试的运算,运算量非常大。传统的基于CPU技术的实现方式通常不能满足交互式DRR算法的需求,随着GPU(graphic processing unit)在并行计算能力、存储容量和可编程能力等方面的发展,使DRR算法的性能提升成为可能[8]。
英伟达(NVIDIA)公司于2007年提出的CUDA架构(compute unified device architecture)使得开发者能够以GPU的强大并行计算能力为基础,建立一种更快更高效的数据计算解决方案。但CUDA架构的一个最主要问题是通用性,人们只能使用NVIDIA系列产品对GPU进行开发。而作为一个软件系统,TPS是运行在医院提供的计算机上,各医院的硬件环境千差万别,所以使用CUDA加速的局限性比较高。而基于异构平台的OpenCL通用计算规范,允许开发者以相同的代码在任何支持该规范的平台上运行,包括NVIDIA和AMD显卡,甚至包括支持OpenCL的CPU,这大大降低了程序对硬件平台的依赖性,具有较强的理论意义和实践价值。
使用OpenCL对TPS系统中的DRR算法进行并行加速,主要出于三个目的:
(1)通过对DRR算法的加速,满足算法交互性和实时性的需要,这不仅能减少患者的等待时间,也提高了TPS的使用效率。
(2)OpenCL作为通用计算标准,与CUDA架构相比,其性能缺乏评判,通过使用OpenCL技术在NVIDIA显卡上实现对DRR算法的加速,软件人员可以更好地审视其性能,以便于在今后的开发中进行平台选择。
(3)通过将数据存储在不同的硬件存储器上的性能对比,开发人员可以深入了解不同存储器在并行优化中的影响,便于在使用OpenCL技术时进行数据的合理布局。
2 OpenCL概述
OpenCL是一个可以在异构平台上进行并行编程的开放框架标准,包括一组底层程序接口和一个高效、快速、可移植的抽象层,为开发者提供了一个有效的并行开发环境、一组与平台无关的工具和丰富的中间层。
OpenCL框架运行时使用主机端程序对所有支持OpenCL的设备进行统一管理。对于每个支持OpenCL规范的计算设备,其在内部又进一步划分为多个计算单元(compute unit),每个计算单元又划分为多个处理单元(processing element),每个处理单元以SIMD或SPMD的方式运行[9]。
为了支持代码的可移植性,OpenCL定义了一个抽象的内存模型,开发者可以根据该模型编写代码,硬件厂商可以将该模型映射到他们自己实际的硬件上[10-11]。OpenCL定义的内存空间如图1所示,这些内存空间与OpenCL程序密切相关。
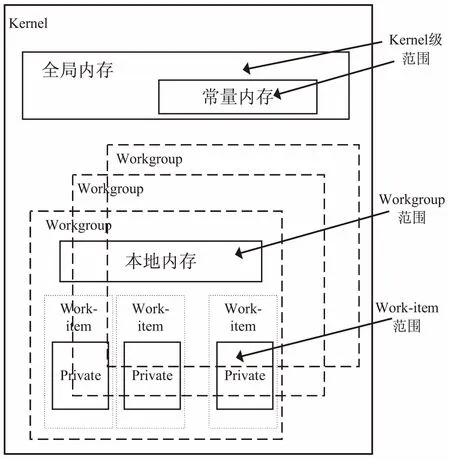
图1 OpenCL内存模型
OpenCL内存模型按照访问权限划分,依次分为全局内存和常量内存(Kernel范围)、本地内存(Workgroup范围)、私有内存(Work-item范围)。其中纹理内存和常量内存的数据位于全局内存,但其拥有高速缓存[12]。
3 DRR算法的优化过程
3.1 DRR算法原理
DRR图像是通过模拟X光线衰减过程生成的,X光线穿过的组织不同,被吸收的剂量也不同,所以采用X光线衰减模型进行模拟,有如下公式:
(1)
其中,I0为X射线的初始强度;μi为组织i的线性衰减系数;L为X射线的长度。
式1的离散形式如式2所示:
I=I0×e-∑μili
(2)
其中,I0和μi同式1;li表示X射线穿过组织i的距离。式2为生成DRR图像的关键公式[13]。
3.2 编写串行程序
编写一个能够正确运行、没有存储器资源泄露的CPU串行程序,作为并行优化的正确性和性能测试的基准。这样做的原因是:(1)由于在目前的OpenCL版本上,使用C++只能实现一些OpenCL编程中主机部分的函数,包括OpenCL设备初始化、CPU和GPU之间的数据通信、注销OpenCL计算环境等,而真正在GPU上执行的kernel函数和device函数都是以C语言函数的形式编写的,所以首先把TPS系统中DRR算法部分由C++程序转换为C程序。(2)OpenCL device上运行的代码不易调试,所以在串行程序中去除不易并行的因素,使得程序中的循环或者迭代之间没有或者较少的数据依赖,这会大大减少并行程序出错的概率,因此接下来在第1步串行程序的基础上改写以符合OpenCL的并行操作,例如函数中的静态变量和全局变量在程序运行过程中,会被多个线程同时访问,但其值一直保持不变,会使并行程序中线程之间存在依赖性,不利于程序的并行化,所以根据算法的实现过程改造为局部变量。还有将程序中代表CT体数据的数据指针由二级指针修改为一级指针,这样CT体数据成为一个连续的内存数据块,方便了数据从CPU端向设备端的复制和在绑定纹理时对体数据内存排列的要求。
3.3 确定并行化方案
支持OpenCL计算的GPU通常具有数个多处理器,每个多处理器都具有SIMD架构,支持在同一时钟周期内处理不同的数据,这使得OpenCL主要针对基于数据的并行计算方式[14]。光线追踪算法中每一条光线的计算过程都是相互独立的,不同光线之间没有依赖关系,因此可以方便地进行并行化,只需将每一条光线设计成一个独立的计算线程就能实现基于光线追踪的DRR算法并行化。这是利用OpenCL实现基于光线追踪的DRR算法的可能性。图2是DRR算法的并行化方案。
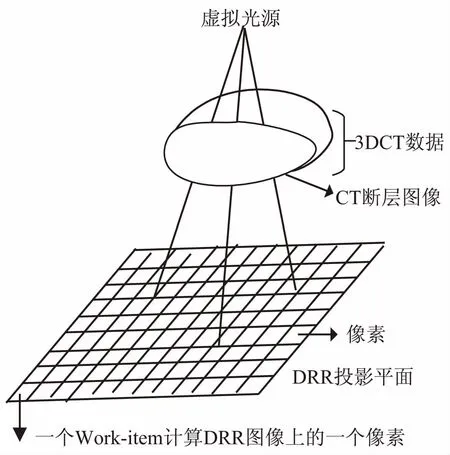
图2 DRR算法的并行化方案
使用OpenCL进行并行程序设计,其中一个主要特点是针对不同的存储器类型进行数据存储。GPU中有全局内存、常量内存、纹理内存和共享内存。DRR算法的输入数据CT体数据少则80~150张,多则200~400张甚至更多。以150张CT图像为例,其需要的内存为150*0.5 MB=75 MB,所以只有全局内存和纹理内存可供选择。纹理内存缓存在芯片上,因此它能够减少对内存的请求并提供更高效的内存带宽[15]。纹理缓存是专门为那些在内存访问模式中存在大量空间局部性(spatial locality)的图形应用程序而设计的[16]。文中对CT体数据存储在全局内存和纹理内存的性能进行了对比。
常量内存中的数据位于全局内存,但拥有局部缓存加速,常量内存的空间较小(只有64 K),因此将虚拟光源的点坐标、CT图像的层厚、图像大小、像素大小等在计算过程中恒定不变的少量参数放在常量内存中。
对于不同CT值数据的衰减表,大小是4 096,类型是单精度浮点,可以选择将数据存储到全局内存、纹理内存或者常量内存,文中也对三种情况下的程序性能进行了对比。
3.4 并行化实现步骤
OpenCL实现DRR算法的步骤主要有:
(1)调用clGetPlatformIDs获得可用的平台,设置使用OpenCL设备;
(2)调用clCreateContext在指定平台上创建上下文;
(3)调用clCreateCommandQueue函数,在已经创建好的上下文上创建命令队列;
(4)在GPU上分配三维image对象,并将CT体数据和CT衰减表从CPU读取至设备的全局内存或者纹理内存中;
(5)在GPU上为算法的其他参数分配设备内存或者常量设备内存,如虚拟光源的点坐标、CT图像的层厚、图像大小、像素大小等,并将CPU端的数据复制到对应的设备内存中;
(6)创建一个网格,并且设置好workgroup和workitem的大小;
(7)创建内核对象,使用clCreateKernel创建一个kernel对象,调用clEnqueueNDRangeKernel启动kernel函数;
(8)kernel函数执行,先判断当前的workitem要处理的像素是否在DRR图像范围内,如果不是,则不进行计算直接返回;否则执行DRR算法内核函数,在内核函数的执行过程中更新DRR图像关联的全局设备内存;
(9)kernel函数执行完毕,把更新后全局内存数据复制回CPU内存;
(10)在屏幕上描画CPU内存上的结果;
(11)释放OpenCL设备上的空间以及CPU上的内存。
3.5 并行参数设置
基于OpenCL的DRR算法中,用一个线程来计算DRR图像中一个像素的值,如DRR图像的分辨率为m*n,则在一个kernel中就包括使用m*n个线程,每个workgroup中的workitem设置为32*16,则一个kernel中的workgroup数目为(m/32)*(n/16)。
4 实 验
4.1 实验环境
针对相同的算法复杂度,将CT体数据分别存储在全局内存和纹理内存并分别与串行程序进行了对比,另外对CT衰减表分别存储于全局内存、纹理内存和常数内存并与串行程序进行了对比,以评估OpenCL将数据存储在不同存储器上的性能。
使用的平台如下:
GPU:NVIDIA GeForce GTX760 2 G显存;
CPU:Intel i5 4590 4核4线程 3.3 GHz;
内存:DDR3 1 600 MHz 8 G。
4.2 结果分析
文中分别对分辨率为2 048*2 048和1 024*1 024的DDR图像进行了CPU和GPU的计算结果和性能对比,使用GPU运算的结果和CPU相比,运行结果误差是1e-2,结果可以接受,如图3所示。

图3 CPU和GPU的运算结果对比
性能对比如表1~3所示。

表1 体数据在全局内存时的性能对比
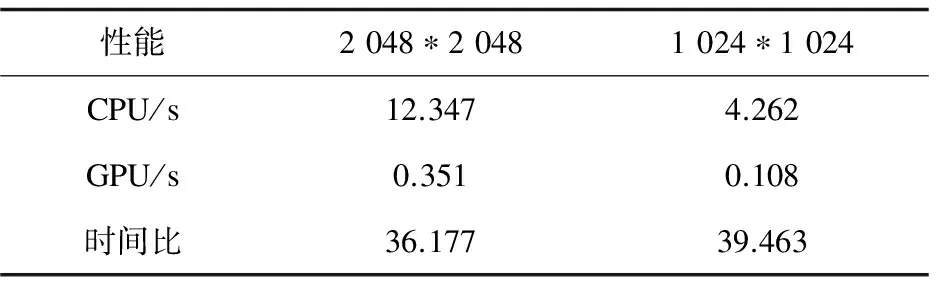
表2 体数据在纹理内存时的性能对比
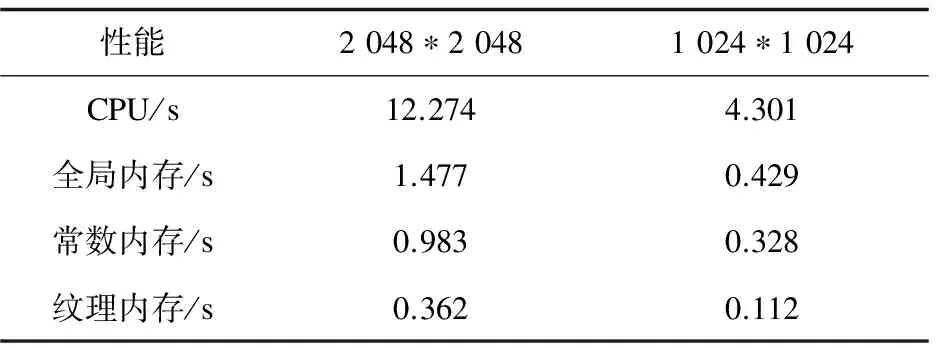
表3 CT衰减表在不同存储器上的性能对比
由表1~3中的对比数据可见:经过OpenCL优化的DRR算法速度比CPU串行版本明显快很多;在OpenCL编程中使用纹理内存可以大大提高程序的加速比;在相同条件下,纹理内存的速度略大于常数内存,并且远大于全局内存;OpenCL并行程序和串行程序的加速比与基于CUDA的DRR图像生成算法相近[13]。
5 结束语
通过利用DRR算法的可并行性,使用OpenCL技术对基于光线追踪的DRR算法进行优化,并在GPU上进行了并行算法调优;通过对OpenCL中的各种存储器的优化使用,显著提高了程序的运行效率。目前,OpenCL的使用仍然有很多局限,在诸如复杂的分支和逻辑判断等方面仍然不如CPU灵活,但随着GPU的快速发展,相信OpenCL的应用范围将更加广阔。
参考文献:
[1] 闫 锋.数字重建放射影像生成方法及其应用研究[D].合肥:合肥工业大学,2010.
[2] 戴建荣,胡逸民.图像引导放疗的实现方式[J].中华放射肿瘤学杂志,2006,15(2):132-135.
[3] 吴宜灿,李国丽,陶声祥,等.精确放射治疗系统ARTS的研究与发展[J].中国医学物理学杂志,2005,22(6):683-690.
[4] FERNANDO R,KILGARD M J.The Cg tutorial:the definitive guide to programmable real-time graphics[M].[s.l.]:Addison-Wesley,2003.
[5] 汪 俊,吴章文,张从华,等.基于射线追踪的数字重建影像增强技术[J].生物医学工程学杂志,2005,22(1):125-128.
[6] HUANG Jianbing,CARTER M B.Interactive transparency rendering for large CAD models[J].IEEE Transactions on Visualization and Computer Graphics,2005,11(5):584-595.
[7] LEVORY M.Volume rendering by adaptive refinement[J].Visual Computer,1990,6(1):2-7.
[8] RUSSAKOFF D B,ROHLFING T,MORI K,et al.Fast generation of digitally reconstructed radiographs using attenuation fields with application to 2D-3D image registration[J].IEEE Transactions on Medical Imaging,2005,24(11):1441-1454.
[9] 李 森,李新亮,王 龙,等.基于OpenCL的并行方腔流加速性能分析[J].计算机应用研究,2011,28(4):1401-1403.
[10] 贾海鹏,张云泉,龙国平,等.基于OpenCL的拉普拉斯图像增强算法优化研究[J].计算机科学,2012,39(5):271-277.
[11] NVIDIA Corporation. NVIDIA OpenCL JumpStart guide[M].America:NVIDIA,2009.
[12] MUNSHI A.The OpenCL specification[S].America:Khronos OpenCL Working Group,2009.
[13] 杜晓刚,党建武,王阳萍.基于CUDA的数字重建影像生成算法[J].计算机科学,2015,42(2):301-305.
[14] 刘 磊.基于GPU的医学图像三维重建及可视化技术研究[D].广州:南方医科大学,2008.
[15] 刘 鹏,高 军,雷勋祖,等.一种基于光场的数字重建影像快速生成算法[J]. 南方医科大学学报,2007,27(10):1537-1539.
[16] NAGY Z,KLEIN R.Depth-peeling for texture-based volume rendering[C]//Proceedings of the 11th Pacific conference on computer graphics and applications.Washington,DC,USA:IEEE Computer Society,2003:429-433.
