基于视觉显著性与肤色分割的人脸检测
2018-04-13鲍小如曹雪虹焦良葆
鲍小如,陈 瑞,曹雪虹,焦良葆
(1.南京邮电大学 通信与信息工程学院,江苏 南京 210003;2.南京工程学院 通信工程学院,江苏 南京 211167;3.南京工程学院 康尼机电研究院,江苏 南京 211167)
0 引 言
人脸检测一直是图像处理与模式识别中的研究热点,现已广泛应用于智能监控、手机拍照、个人身份识别等领域。人脸检测算法层出不穷,大致可分为以下3大类[1]:肤色分割法、提取几何特征法和统计理论的方法。基于肤色分割[2-5]的人脸检测算法利用的是彩色图像中人脸肤色与非人脸之间的差别。该类算法虽然因其原理简单而较容易实现,且可以满足实时检测的要求,但是检测效果易受光照和类肤色的影响。基于几何特征的方法中最常用的是基于模板匹配的人脸检测方法[6-8]。它从大量的人脸图像中训练出统一的人脸模板,然后在检测区域中寻找与该模板最相似的区域,即确定为人脸区域。但精确的人脸模板较难实现,因为人脸间的差异颇大,另一方面人脸姿态的不统一也使得检测效果不理想。基于统计理论的人脸检测算法中应用最广的是Viola-Jones提出的AdaBoost方法[9]。该方法的特征选择是在积分图像上完成的,首先选择特征构建弱分类器,采用“级联”的方式一步步地构建强分类器。该算法推出了一种人脸检测框架,极大地提高了人脸检测的速度和准确率,但对不端正人脸检测时,检测率不高。
近年来视觉显著性发展相当迅速,自Koch和Ullman[10]提出所谓的生物启发模型后,学者们开启了视觉显著性的研究与探索。其中,Itti等[11-12]提出了一种基于视觉注意的显著性检测模型,接着Harel等使用文献[11]中特征选择的方法,并结合马尔可夫链的原理,用以计算特征之间的差异,最后将其正则化处理后,生成基于图的视觉显著模型(graph-based visual saliency,GBVS)[13]。之后还有Goferman等提出的基于上下文的显著性分析方法等等[14]。在国内,清华大学的程明明等[15]提出了基于直方图对比度(histogram contrast,HC)的显著性分析算法与结合区域对比(region contrast,RC)的显著性分析方法等等。
文中提出一种基于视觉显著性与肤色分割的人脸检测算法。由于利用GBVS算法生成的显著性图中显著性区域比较集中,可以更好地提取人脸目标,而其他视觉显著性算法提取的显著性区域比较分散或者显著性区域细节文理太清晰,这两种情况都会影响显著图的阈值分割并得到模板的进程,所以文中使用基于图论的显著性检测算法获取人脸区域的显著图。可以先利用视觉注意机制[16],从一幅复杂背景图中快速定位出包含人脸的大致区域,再利用人脸肤色在L*a*b*空间[17]的a,b分量确定人脸中心位置。
1 基于图论的视觉显著性(graph-based visual saliency,GBVS)
国内外学者一般认为对于一幅图像,人们视觉第一时间注意到的区域,或者局部视觉特征突出的区域为图像显著性区域。鉴于GBVS生成的显著图主要集中在一块区域且有利于阈值分割,文中采用GBVS算法进行前期处理,GBVS在特征提取上沿用了Itti等提出的方法,并在计算特征之间的差异时引入马尔可夫链得到显著性值,最终归一化显著值生成视觉显著图。
视觉显著图获取步骤如下[18]:
(1)输入一幅大小为250×250的灰度图片,利用高斯核函数平滑图像,每次将分辨率降低为原来的1/2,下采样4次,实验中只用第2,3,4次采样得到的图像。分别提取这3幅图像的亮度特征和方向特征,其中方向特征是提取的0°,45°,90°,135°方向的信息,最后可得到15幅底层特征图(图像尺寸32×32)。
(2)把这15幅特征图依次作为输入,计算每幅图的激活图。对每一幅特征图,以图中的每一个像素点为节点,根据像素点间的灰度值相似度和像素点位置间的距离(欧氏距离)作为连接权值,建立一个全连通的有向图GA,从节点(i,j)到节点(p,q)的有向边会赋予一个权值,定义为:
W((i,j),(p,q))=d((i,j)‖(p,q))·
F(i-p,j-q)
(1)
其中,d((i,j)‖(p,q))表示节点(i,j)和节点(p,q)之间像素值M(i,j)和M(p,q)的相异程度,计算公式为:
(2)
F(a,b)表示节点(i,j)与节点(p,q)位置间的欧氏距离,计算公式为:
(3)
(3)连接权值矩阵(1 024×1 024),并归一化权值矩阵,使矩阵每列之和为1,形成马尔可夫状态转移矩阵。
(4)对马尔可夫转移矩阵进行多次迭代,直到马尔可夫链达到平稳分布。马尔可夫链的平稳分布反映了随机游走者在每个节点/状态消耗时间的积累。节点视觉特征越不相似,权值越大,转移概率就大,在这个节点积累的时间就长;反之就短。视觉特征越不相似的点越显著。
(5)找到马尔可夫矩阵的主特征向量(1 024×1),主特征向量是主特征值对应的向量,矩阵的多个特征值中模最大的特征值叫主特征值,对应图像的显著节点。把主特征向量重新排列成两维(32×32)的形式,就得到了激活图,并对其进行归一化。
(6)按以上方法得到每个特征通道的特征图的激活图,再把各个特征通道内激活图相加,最后把亮度和方向特征通道激活图都叠加起来,得到视觉显著图。
2 L*a*b*色彩空间
CIEL*a*b*色彩空间(简称L*a*b*色彩空间)是用L*,a*,b*三个不同的坐标轴指示颜色在空间中分布的一个三维体系。当用CIEL*a*b*表示某一颜色时,L*轴表示颜色的明暗程度,黑在底端,白在顶端;+a*表示红色,-a*表示绿色;+b*表示黄色,-b*表示蓝色;如图1所示。颜色的色彩变化可以用a*,b*的数值来表示,颜色的亮度变化可以用L*的数值来表示。

图1 CIEL*a*b*色彩空间
将RGB色彩空间中的图像信息转换到L*a*b*色彩空间中,需要先对输入图像的RGB信息分量进行Gamma校正:R=g(r),G=g(g),B=g(b)。其中r,g,b(r,g,b∈[0,1))是输入图像的原始颜色分量信息,而R,G,B(R,G,B∈[0,1))分量则是经过Gamma校正后得到的颜色分量信息。
Gamma校正函数g(x)为:
(4)
然后将经过Gamma校正后的R,G,B分量转换到XYZ空间:
[XYZ]=M*[RGB]
(5)
其中,转换系数矩阵M为:

(6)
转换后的X∈[0,0.950 6),Y∈[0,1),Z∈[0,1.089 0)。X,Y,Z经线性归一化后得到X1,Y1,Z1∈[0,1),之后再进一步转换到L*a*b*色彩空间:
L=116*f(Y1)-16
(7)
a=500*[f(X1)-f(Y1)]
(8)
b=200*[f(Y1)-f(Z1)]
(9)
其中,转换函数f(x)为:
(10)
计算后可得到L,a,b分量值,L∈[0,100),a∈[-169,169),b∈[-160,160)。为了方便计算,可将3个分量都归一化到[0,255]之间。
3 基于视觉显著性与肤色分割的人脸检测
文中算法的基本实现流程如图2所示。

图2 算法基本流程
开始输入一幅含有人脸的复杂背景图片,接着利用GBVS方法获取图片的视觉显著性图,然后对显著图进行阈值分割从而得到二值模板图。但是该模板并不精确,内部可能存在少量干扰像素点或空洞,对其进行形态学操作之后就可以得到精确的模板了,模板中白色区域就是初步的人脸位置区域R1;接着计算原始图像的R1区域在L*a*b*色彩空间中每个像素的a,b分量值与人脸肤色的a,b分量值的欧氏距离,并人为设定一个经验阈值,排除一些相差很大的像素点;之后计算在阈值内的所有像素点的质心,将该质心作为人脸中心点,并按中心点到R1区域边缘的最小距离的80%为半径,截取准确人脸区域,即得到精确的人脸区域R2;最后在原始图像上截取出人脸。
经过原理介绍,下面将给出算法的详细实现步骤。该算法大致可分为三个部分:第一部分是从LFW数据库中计算出人脸肤色在L*a*b*色彩空间的3个分量平均值;第二部分是使用视觉显著性算法获取图像显著图并阈值化后得到初步目标人脸区域;第三部分是在得到的初步人脸区域中利用人脸肤色在L*a*b*色彩空间的a,b分量平均值进一步得到精确的人脸区域。算法具体的实现步骤如下:
(1)选取LFW数据库中的部分标准图像,截取图像中的人脸肤色部分,并由RGB色彩空间转换到L*a*b*色彩空间,计算L,a,b的分量值,最后取它们的平均值ave_L,ave_a,ave_b。
(2)输入一幅彩色图像I(x,y),通过GBVS算法生成该图像的显著性图,记为S(x,y)。
(3)显著性图S(x,y)中每个像素的值即为该像素的显著性值,将显著性值归一化到0~1之间,文中取0.6作为阈值对显著图S(x,y)进行分割,得到一个粗略的二值模板M(x,y)。
(4)对模板M(x,y)进行细化得到精确的模板M1(x,y)。具体操作如下:如果模板M(x,y)中存在一些由于阈值分割而残留的像素点,则对其进行膨胀操作删除干扰像素点;如果M(x,y)丢失信息过多,就对M(x,y)进行孔洞填充。最终得到模板M1(x,y)。
(5)通过模板M1(x,y)就可以得到人脸的初步区域,M1(x,y)中的白色区域就是目标人脸的大致区域R1了,接着将图像I(x,y)从RGB色彩空间转换至L*a*b*色彩空间,转换后的图像用IL(x,y)表示。对于IL(x,y)中R1区域的每个像素点计算出它们的a,b分量与第一步得到的ave_a和ave_b之间的欧氏距离dis_ave,考虑到光照因素的影响,除去了亮度分量ave_L。
(11)
(6)确定中心点。对于前面计算出的dis_ave,根据频数直方图统计的情况人为设定一个分割阈值s,除去R1区域内一些阈值之外的点。计算出中心点坐标cet_x,cet_y:
(12)
(13)
其中,p表示一个像素点;dis_ave_p表示像素点p的a,b分量与ave_a,ave_b之间的欧氏距离;count表示R1区域内在阈值s内的像素点的总数;p_x和p_y分别表示像素点p的横坐标值和纵坐标值。
(7)确定目标人脸区域。对M1(x,y)进行边缘处理,得到其区域边缘的所有像素点集合,求出区域边缘像素点到中心点最小距离r。最后以0.8r为半径围绕中心点作正方形,即该正方形区域就是最终要确定的目标人脸区域。
(8)在原始输入图像I(x,y)上截取之前得到的目标人脸区域,就完成了整个人脸检测。
4 实验仿真
实验仿真是在LFW数据库上进行的。该数据库共收集了13 233张人脸图片,图片大小为250×250像素,图片分属5 749个不同的人,其中只有一张图片的有4 096人,多于一张图片的有1 680人,图片中有些包含多个人脸,只考虑基本位于图片中间位置的目标人脸。在MATLAB2012b平台上进行程序编写。
实验对端正人脸和非端正人脸分别进行Viola-Jones的人脸检测,视觉显著性下的人脸检测[18]和视觉显著性下肤色导向的人脸检测。Viola-Jones人脸检测算法是目前最经典、使用最多的鲁棒人脸检测算法;文献[18]是国内最新的一篇关于视觉显著性的人脸检测算法。与它们进行比较可以有效说明文中算法在人脸检测中的有效性。端正人脸的测试结果如图3所示,非端正人脸的测试结果如图4所示。两图中的第一列表示输入的原始图像,第二列是Viola-Jones人脸检测算法结果,第三列表示是文献[18]中人脸检测算法得到的结果,第四列是文中算法的实验结果。

图3 端正人脸

图4 非端正人脸
由两图可知,在处理端正人脸图像时,文中算法与Viola-Jones算法都能准确地检测出人脸区域,且检测效果基本一致。但是在处理非端正人脸图像时,由于人脸姿态的变化,Viola-Jones算法过分关注眼睛、嘴巴等特征位置,检测区域缩小,不能截取完整的目标人脸,损失了部分面部信息,有的甚至根本就不能看出原来人的模样了;而文中算法是在视觉显著性的基础上确定目标大致位置,再利用人脸肤色确定检测中心,更有利保护目标人脸的完整性,因此检测效果要好于Viola-Jones算法。不管是在处理端正人脸还是非端正人脸,文献[18]的算法与文中算法都能很好地检测出人脸,但从两幅图中可以明显看出文献[18]中的算法检测出的人脸区域包含大量背景,相比较之下文中算法检测出的人脸区域所包含的背景则相对较少。此外,实验还统计了三种算法检测出人脸所消耗的时间与检测率,如表1和表2所示。

表1 时间比较
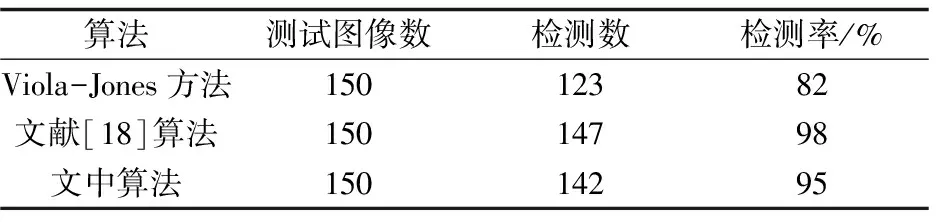
表2 检测率比较
根据表1可知,在时间消耗方面,文中算法和其余两种算法在时间上并无明显差异,三者之间的最大差距仅为0.30 s,因此可以看出算法运行迅速,具备较好的实时性。从表2可以看出,文中算法在LFW人脸库中的检测率明显高于Viola-Jones算法,基本能实现全检测,而Viola-Jones算法对于脸部分辨率有一定要求,对于脸部分辨率较低的图像,关键的特征提取变得困难,造成了一些检测不出人脸的情况。综上可得,文中算法是一种快速、自动、准确,且检测率高的人脸检测方法。
5 结束语
提出一种基于视觉显著性与肤色分割的人脸检测算法。首先通过GBVS算法获得原始图像的显著性图,接着选择一个显著性值作为阈值,分割该显著图得到二值模板,然后优化该模板得到初步的人脸区域,再根据人脸肤色在L*a*b*色彩空间中的a,b分量值与人脸初步区域中的像素点在L*a*b*色彩空间中的a,b分量的欧氏距离,确定人脸区域的中心,然后以初步区域边缘到中心的最小距离的80%为半径,在原图中截取出矩形人脸区域,实现了复杂环境下的人脸目标检测。与其他方法相比,该算法不仅准确度高,而且运行快速,可以很好地适用于智能手机前置拍照的人脸定位与人脸识别前期的预处理工作。
参考文献:
[1] 郑青碧.基于图像的人脸检测方法综述[J].电子设计工程,2014,22(8):108-110.
[2] YANG Y,XIE C,DU L,et al.A new face detection algorithm based on skin color segmentation[C]//Chinese automation congress.Washington DC,USA:IEEE Computer Society,2015:523-526.
[3] DONG C,WANG X,LIN T,et al.Face detection under particular environment based on skin color model and radial basis function network[C]//IEEE fifth international conference on big data and cloud computing.Washington DC,USA:IEEE Computer Society,2015:256-259.
[4] ALABBASI H A, MOLDOVEANU F. Human face detection from images,based on skin color[C]//18th international conference on system theory,control and computing.Washington DC,USA:IEEE Computer Society,2014:532-537.
[5] MAHADEVI M,SUMATHI C P.Face detection based on skin color model and connected component with template matching[C]//International conference on information communication and embedded systems.Washington DC,USA:IEEE Computer Society,2014:1-4.
[6] DUTTA P,BHATTACHARJEE D.Face detection using generic eye template matching[C]//2nd international conference on business and information management.Washington DC,USA:IEEE Computer Society,2014:36-40.
[7] TEJA M H.Real-time live face detection using face template matching and DCT energy analysis[C]//2011 international conference of soft computing and pattern recognition.Washington DC,USA:IEEE Computer Society,2011:342-346.
[8] YAN Siyang,WANG Haiying,FANG Zhao,et al.A face detection method combining improved AdaBoost algorithm and template matching in video sequence[C]//28th international conference on intelligent human-machine systems and cybernetics.Washington DC,USA:IEEE Computer Society,2016:231-235.
[9] VIOLA P,JONES M.Robust real-time face detection[C]//Proceedings of eighth IEEE international conference on computer vision.Washington DC,USA:IEEE Computer Society,2001:137-154.
[10] KOCH C,ULLMAN S.Shifts in selective visual attention:towards the underlying neural circuitry[J].Human Neurobiogy,1985,4(4):219-227.
[11] ITTI L,KOCH C,NIEBUR E.A model of saliency-based visual attention for rapid scene analysis[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,1998,20(11):1254-1259.
[12] ITTI L,KOCH C.Computational modelling of visual attention[J].Nature Reviews Neuroscience,2001,2(3):194-203.
[13] HAREL J,KOCH C,PERONA P.Graph-based visual saliency[C]//Advances in neural information processing systems.[s.l.]:[s.n.],2007:545-552.
[14] GOFERMAN S,LIHI Zelnik-Manor,TAL A.Context-aware saliency detection[C]//2010 IEEE computer society conference on computer vision and pattern recognition.Washington DC,USA:IEEE Computer Society,2010:2376-2383.
[15] CHENG M,ZHANG G,MITRA N J,et al.Global contrast based salient region detection[C]//CVPR 2011.Washington DC,USA:IEEE Computer Society,2011:409-416.
[16] 敖欢欢.视觉显著性应用研究[D].合肥:中国科学技术大学,2013.
[17] 殷世琼.基于视觉机制的图像和视频的显著性检测[D].合肥:合肥工业大学,2015.
[18] 陈 凡,童 莹,曹雪虹.复杂环境下基于视觉显著性的人脸目标检测[J].计算机技术与发展,2017,27(1):48-52.
