基于图分析和支持向量机的企业网异常用户检测
2018-04-12郭渊博叶子维胡永进
徐 兵,郭渊博,叶子维,胡永进
(1.信息工程大学, 郑州 450001; 2.数学工程与先进计算国家重点实验室, 郑州 450001)(*通信作者电子邮箱1214443035@qq.com)
0 引言
近年来,网络安全威胁日益突出。如何保证网络信息的安全是信息时代人们要共同面对的挑战。在企业网络中,用户的身份认证是确认用户身份的过程,用户常常通过认证来得到对某种资源的访问和使用权限,而用户的身份认证安全正是众多挑战之一[1]。目前,身份认证可以有很多种不同的方式。传统的身份认证方法基本可以分为以下三大类:基于用户所知(what you know)、所有(what you are)、所是(what you are)。最简单常用的用户名和密码的方式就是基于用户所有的方式,还可以使用基于用户所知的动态口令和基于用户所是的生物特征的方式等[2]。基于生物特征的认证方式有不易丢失和被窃取的优点[3]。但专家指出,在可预见的未来,基于口令的认证方式仍无可替代,口令仍将是最主要的身份认证方式[4]。而这种方式的固有缺点是必须在服务端存储这些敏感的验证信息,而且这些信息容易被窃取[5]。在企业环境中,用户通过网络向很多计算机系统或应用发出认证[6],这种情况下,用户的认证活动通常由一个统一的网络身份认证机制所提供。这种机制就是集中式账户管理机制[7-8]。身份认证和集中式账户管理机制是现代信息技术管理的基石,在大量的系统中有着广泛应用。然而用户认证在方便的同时也存在着安全隐患。据赛迪网报道,某证券公司报案称该公司发现多名客户的股票账户被盗用,非法分子利用盗取的客户密码通过网上委托窗口卖出账户内股票后又全部买入某只股票,涉及资产上千万。2016年8月,北京海淀公安分局海淀网安大队收到百度网讯科技的报警。百度方面称,该公司威胁情报部门监测到有大量百度账号被成功登录。同期百度用户反馈后台、邮件、官方微博、内网等各渠道陆续收到5 000名用户反馈“账号因被盗而封禁以及文件丢失”等,造成严重的个人利益的损失,也使得百度公司直接损失上千万[9]。这些资源的未授权使用,个人或者组织的不正当活动,都可能使国家、社会以及各类主体的利益遭受严重损失。特别是攻击者在取得合法的身份以及认证信息后,他的认证行为跟正常用户就很难区分。著名的APT攻击案例——Google极光攻击正是利用这样的机制,攻击者盗用雇员的凭证成功渗透进入Google的邮件服务器,进而不断地获取特定Gmail账户的邮件内容信息[10]。传统的检测方法在这种情况下,基本丧失了检测能力。如何在复杂的网络环境中区分出这些被盗用或者滥用的账户,就显得尤为紧迫。机器学习与数据挖掘技术的引入,使得这类检测成为了可能。
本文在Kent等[11]用Logistic回归研究用户认证活动的基础上作了改进,将图分析和机器学习方法结合,同样利用用户的认证活动信息,建立正常用户与异常用户的分类模型,以此达到检测异常的目的。将机器学习方法应用到用户认证行为的异常检测中,减少了人工参与,节约了人工成本。本文方法可以独立应用在企业网络中,用于异常用户的识别与检测;也可与传统的安全防护方法结合,如加入到入侵检测系统中,进一步提升入侵检测系统的性能。本文使用了大型企业网络的真实数据集来验证文中所提出的检测方法,分析了在用支持向量机(Support Vector Machine, SVM)模型进行检测时各种惩罚参数和核函数的选择对检测结果的影响,最后用召回率、准确率、精确率、F1-score来评估实验结果。结果显示,当取得合适的参数之后,对异常用户的检测识别率能达到较高的水平,能构建较为高效的模型,也验证了本文方法的可行性和有效性。
1 相关研究
集中式认证管理和控制是现代IT管理的基础,也被应用在很多大型的IT企业网络中。网络身份认证是两种典型的认证技术——Microsoft NTLM身份认证技术和MIT Kerberos身份认证技术的结合,这两种认证方式也被广泛地应用在桌面计算机和面向服务的操作系统中。这两种认证方式都使用了证书缓存的方法,以方便证书的再次使用,因此也产生了很大的安全风险。当用户的证书被恶意人员盗用时,他所发起的认证都将遵循身份认证技术的规则,没有技术上的破绽。但恶意用户的认证活动可能与正常用户表现差异较大,如用户短时间内发出大量的认证、向很少认证过的应用或系统发出认证等。Javed在文献[12]中提出了检测企业网异常认证被盗的系统。该文中针对暴力破解攻击提出了一种利用自定义的方法标记信息源,当某些参数发生显著变化时,则身份认证过程可能异常;还提出了一种基于特征工程的方法识别异常用户,把正常用户中很少发生的事件和异常用户中大量发生的认证事件的特征提取出来进行建模,进而检测异常认证行为。文献[12]侧重于攻击前的检测与防护,而本文侧重于企业网络中具有异常认证行为的用户的检测。针对证书被盗或被滥用的用户,Kent等在文献[6]首先提出了分析用户认证行为的方法来检测企业网络中被盗的用户。后来,Kent等在文献[11]提出了利用“身份认证图”的方法来识别企业网络中的有特殊权限的管理员用户和普通用户,初步显示了认证数据的价值。接着,Kent等[11]又在身份认证图分类用户类型的基础上提出了基于Logistic回归的异常用户的检测模型,但模型的召回率不高,只有28%,可以判定是模型本身的缺点所致,调节参数不能从根本上解决检测效率低的问题。
基于机器学习的异常检测通常应用在入侵检测系统中,其中SVM作为一种非常活跃的机器学习方法经常用于正常与异常的分类。它是基于结构风险最小化(Structural Risk Minimization, SRM)原理,根据有限的样本信息在模型的复杂性和和学习能力之间寻求最佳折中,以期获得最好的泛化能力。早在2003年,饶鲜等[13]提出了SVM用于入侵检测的模型,直到现在仍然是机器学习用于异常检测的经典模型。2014年,Chitrakar等[14]提出一种用于增量SVM的候选支持向量方法,并实现算法CSV-ISVM,在实时网络异常检测中具有优势。SVM以及SVM的改进方法独立应用于异常检测中已相当成熟,但将其与其他方法结合来进行检测的案例不是很多。图分析方法是一种新的检测异常的思路,将图分析与SVM结合能发挥两种方法的优点,SVM难以在大规模样本上实施的缺点也可以用图分析中的信息转化所弥补。从后文的实验中可以看出,将两种方法结合运用于异常的检测取得了理想的检测效果。
2 研究思路
图论的研究已有一段历史,发展到今天已经相当成熟[15]。用户的认证活动显示了计算机与计算机之间的相互关系,这种关系可以很自然地用图的方式来表示。如图1,一台计算机可以用图中的一个节点来表示,用户之间的认证活动可以用节点之间的连线代替。图1表示,在一段时间内,某用户通过计算机C10分别向另外几台计算机发起过认证。表示在图中就是节点C10向其他节点C20、C30、C40的有向连接。
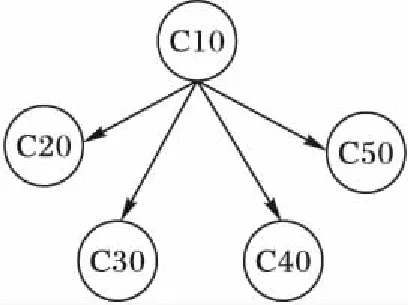
图1 用户身份认证图Fig.1 User authentication graph
为了更具体地描述用户认证图,可以作如下约定:
用户认证图:Gu=(Vu,Eu),表示给定的一段时间内,用户U的认证活动生成的有向图。节点集Vu表示参与认证的计算机的结合,边集Eu表示计算机之间的认证活动。
本文使用的数据集是洛斯阿拉莫国家实验室(Los Alamos National Laboratory,LANL)所收集的两个真实企业网络安全数据集[16]。其中一个数据集收集了企业网络中所有用户58天的认证活动信息,称为Authentication数据集;另一个数据集标注明确的红队事件,呈现明显的恶意行为,称为Red Team数据集。
Authentication数据集里有所有用户58天内的认证活动。每一行代表一条认证记录,包括认证时间、源认证用户、目的认证用户、源认证计算机、目的认证计算机、认证类型、登录类型、认证方向、成功或失败等九个方面的内容。原数据集中的两条记录示例如下:
91,U22@DOM1,U22@DOM1,C477,C2106,Kerberos,Network,LogOn,Success
91,U22@DOM1,U22@DOM1,C506,C457,Kerberos,Network,LogOn,Success
Red Team数据集中用户的认证活动都是研究者特意制造并明确标注的异常,可以用作异常发现的对比,也可以用来与正常用户认证活动一起构建分类模型。本文实验中利用其中一部分数据作为训练集,另一部分作为测试集来评估模型的性能。其中两条原始数据记录格式如下:
153792,U636@DOM1,C17693,C294
155219,U748@DOM1,C17693,C5693
Read Team数据集里每条记录包含的信息比Authentication数据集里记录的信息要少,但仍包含了必要的认证信息,如认证时间、源认证用户、源认证主机和目的认证主机,而用户认证图的生成也正是利用这些信息。
这样,为每一个用户生成一个用户认证图,就可以利用用户认证图中的属性来反映此用户的某些性质。如用户认证图的稀疏与稠密可以用密度来度量,来反映此用户与其他用户的交互关系是简单还是复杂。稀疏图对应着简单的交互关系,稠密的图对应着复杂的交互关系。把用户的认证活动以图的方式表示,将用户的认证性质浓缩到图的属性中,这样就把对用户含糊的性质分析,转化为对图的清晰的定量属性分析,完成信息的转换。识别和探索每个用户的用户认证图的属性能得出一些有用的结果。例如,大多数用户所认证的计算机都是固定的,这样反映了他们认证活动的固定。那些有特权的管理员用户,有着比普通用户更复杂的图,也有着更复杂的属性。如图2是某两个真实用户的身份认证图,可以看出真实的认证图更复杂,也更能反映一些信息。之后可以根据所得用户的间接信息作进一步的分析处理。
由前面认证数据的介绍可知,在企业网络中经常有异常认证的情况,正是由于用户的异常才导致异常认证的发生。所以,可以把对异常用户的检测转化为区分正常用户和异常用户这样一个二分类问题。由于SVM本身就是为二分类问题设计的,在二分类问题上有很好的分类效果,且具有较好的鲁棒性,所以选择SVM作为分类的模型。SVM的核心思想是把样本映射到一个高维的特征空间,使其在高维的空间中达到线性可分,通过在高维空间里构造一个超平面来达到分类的目的[17]。但SVM所不足的是在大规模训练样本上难以实施,要借助二次规划来求解支持向量。而图分析方法恰好能克服SVM此方面的缺点,将大规模的用户认证活动转换为图中的信息,数据规模将大大减小,训练分类器时的计算开销也大大减少。

图2 某真实用户的身份认证图Fig. 2 A real user’s authentication graph
3 研究思路
本文的系统设计分为三个阶段:数据准备、模型构建和结果检验。系统设计流程如图3所示。
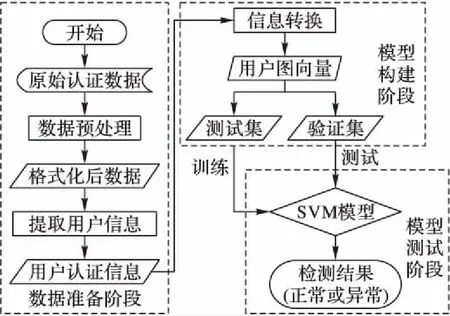
图3 系统设计流程Fig. 3 System design flowchart
3.1 数据准备阶段
数据准备阶段由以下步骤来完成:数据预处理、信息提取和信息转换。
3.1.1数据预处理
数据预处理的目的是把数据集预处理成只包含必要用户认证活动信息的数据,以方便进行下一步的信息提取。此阶段将Authentication数据集预处理成跟Red Team数据集相同的格式,删除对本实验无用的字段,完成数据的精简。精简后的数据只包含如下四个字段:认证时间、源认证用户、源认证主机和目的认证主机。
3.1.2信息提取
当完成数据预处理后,两个数据集的格式就变得相同。对两个数据集分别进行如下的处理:提取数据集中的用户,对每一个用户提取其认证数据。
由于Authentication数据集中有全部用户,包括正常和异常用户,而Red Team数据集中只包含异常用户,所以只需要提取Authentication数据集中的用户即可,Red Team数据集中的用户作为参考对比。提取完用户后,再提取其所对应的认证记录,生成用户自己的用户认证集。
3.1.3信息转换
利用每一个用户的认证集生成属于此用户的认证图,将用户认证数据集转换为用户认证图,即完成了一次信息转换。由用户认证数据集生成认证图的伪代码如下:
For every user authentication dataset:
SAC=Source Authentication Computer
#SAC表示源认证计算机
DAC=Destination Authentication Computer
#DAC表示目的认证计算机
IF SAC!=DAC :
IF SAC is exist:
IF DAC is exist:
PASS
ELSE:
CREATE DAC
ADD Edge(SAC,DAC)
ELSE:
CREATE SAC
IF DAC is exist:
PASS
ELSE:
CREATE DAC
ADD Edge(SAC,DAC)
ELSE:
PASS
上述伪代码表示:对于每一条认证,首先判断源认证主机和目的认证主机是否相同,如果相同则属于本地认证,再判断源认证主机节点在图中是否存在,若不存在,创建一个新节点;若存在,则跳过,不再重新创建。若源、目认证主机不同,再判断源、目主机是否在图中存在,不存在则先创建节点,再创建一条有向边;若主机已在图中存在,直接创建有向边。
对于所有的用户数据集重复以上操作,则可以得到转换后的198个用户认证图,之后是对图的分析与操作。从每个用户图提取出有效的认证属性,生成用户图向量,就完成了又一次的信息转换。由已定义过的图Gu出发,再作以下定义:
在一段时间内,用户U可能通过不止一台计算机发起认证,定义VS为发起认证的源主机的集合,VD为认证的目的主机的结合,|VS|为用户U的源认证主机数,|VD|为用户U的目的认证主机数。
定义Cu为图中连通组件,|Cu|为连通组件的个数。若用户在给定的时间内,所有的认证活动由此一台计算机发起,则图中只有一个连通组件,也即是最大连通组件Cu_max。
Cu_max一般是用户最常用的计算机以及最常认证的计算的结合。如图2中所示某真实用户的认证图,中间一部分比较密集的连通图就是最大连通组件。
Cu_min定义为最小连通组件,由于用户认证图是由用户的认证生成的图,所以最小连通组件至少有一个源认证主机和一个目的认证主机两个节点,将其定义为孤立认证,|Cu_min|为独立认证的数量。孤立认证表现在认证图中是只有两个节点的连通组件。如图2中边缘部分只有两个节点的认证。表1列出本文用于分类的一些图属性。
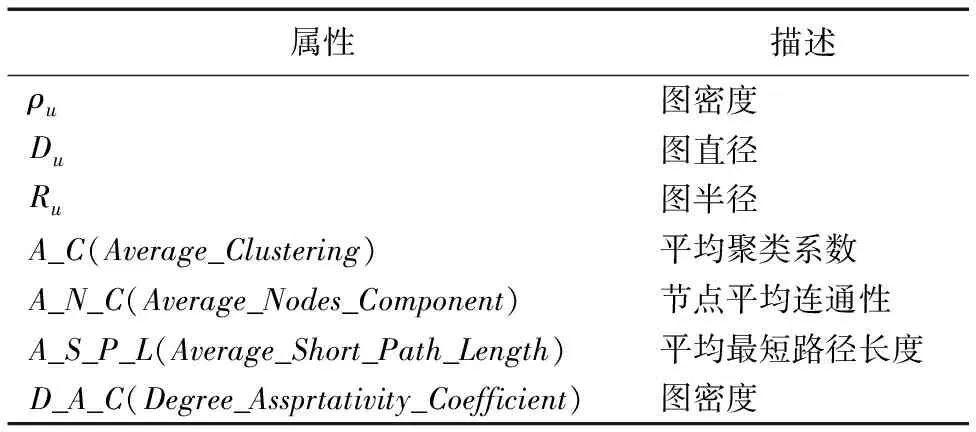
表1 属性及描述Tab. 1 Attributes and description
对于每个用户所生成的认证图,都可以进行上述的信息转换。转换完毕后,将为每一用户生成一个用户认证图向量。至此,第一阶段完成。
3.2 模型构建
从原始的认证数据到用户认证图,再到用户图向量,经过这一系列的数据准备工作之后,便可以开始进行模型的构建。模型的构建过程即SVM决策函数求解的过程。把上阶段准备好的用户图向量数据分为两部分:一部分用于本阶段模型的构建,另一部分用于下一阶段模型的性能测试。模型构建过程如下:
1)将用于构建模型的测试集部分作为输入样本:T={(x1,y1),(x2,y2),…,(xn,yn)},其中xi∈Rn,yi∈{+1,-1},i=1,2,…,N,每个xi表示一个用户图向量,yi为此用户的标签。
2)当样本可分时,分类超平面的最优问题可表示为:
(1)
s. t.yi(w·xi+b)-1≥0,i=1,2,…,N
当样本集线性不可分时,需引入非负松弛变量ξi(i=1,2,…,m),C为惩罚超参数,分类超平面的最优问题表示为:
(2)
s. t.yi(wTxi+b)≥1-ξi
由于此样本集线性不可分,所以利用式(2)来求解最优超平面。
3)选择合适的核函数K(x,xT)和惩罚参数C,构造并求解最优化问题:
(3)
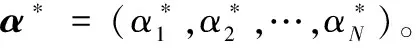
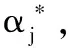
(4)
5)最终求得决策函数:
(5)
经由上述一系列步骤训练出检测模型后,此模型便可以用于未知用户类型的识别与检测。
3.3 模型测试
此阶段主要利用未知数据进行模型的性能测试,用准确率、召回率、精确率、F1-score几个指标进行定量的评估。由于SVM模型中不同惩罚超参数参数C设置得不同,分类效果可能表现不同,核函数的选择也对分类效果有一定的影响,所以,实验环节主要调节这两个参数以获得更好的分类效果,构建出最优的模型。
4 实验验证与分析
为验证本文方法的有效性,设计以下实验。实验所使用的数据集是LANL收集的β数据集的两个子集——Authentication数据集和Red Team数据集。经过数据预处理后得到格式相同的数据集,数据集的相关信息统计如表2。

表2 实验数据集的相关信息Tab.2 Information of the experimenatl dataset
如表2所示,Authentication数据集共提取12 418个用户,Red Team数据集共提取98个用户,其中Red Team中的98个用户包含在Authentication数据集中的12 418个用户之中。剔除这98个标注异常的用户,剩下12 320个用户即为正常用户,所发出的认证也为正常认证。由于正负样本不平衡,可以采取从大类样本中随机抽取与小类相同的样本个数的方法进行不平衡数据的降采样。本文随机从12 320个用户中提取100个用户参与实验。对这198个用户分别提取属于此用户的所有认证记录,这样对于每一个用户,都会生成一个属于自己的认证数据集。对于处理后的数据经过第一次信息转换之后可以得到198幅用户认证图,其中每一张认证图隶属于一个真实用户。图2和图4分别是其中两个真实用户的认证图:图2的用户认证图稍微简单,但已经到了人所不能分辨的地步,而图4的辨识度则更差。

图4 另一真实用户认证图Fig. 4 Another real user’s authentication graph
虽然人对用户图几乎没有辨识度,但可以将图中的重要属性提取出来以了解图的性质。将198张图进行第二次的信息转化,得到198个图向量。每个向量对应一张用户认证图,每张用户认证图对应一个用户。其中10个用户图向量以及每个维度表示的含义如表3所示。
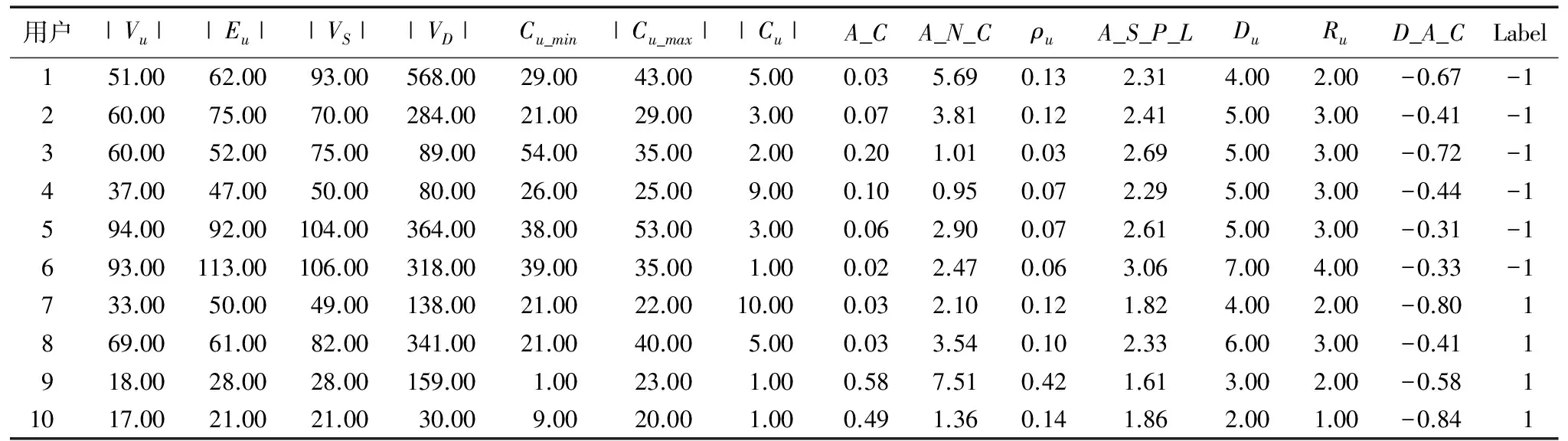
表3 10个用户的用户图向量Tab. 3 User graph vector of ten users
将此阶段得到的298个图向量按比例随机分成训练集和测试集,用训练集构建模型,用测试集来验证模型的性能。
结果的评价指标要求其能充分反映出模型对问题的解决能力,好的评价指标有利于对模型进行优化。目前,常用的几个评价指标有:准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1-Score。在正负样本不平衡的情况下,准确率评价指标有很大的缺陷,所以需要其他几项指标一同来进行衡量;F1-Score是精确率和召回率的调和均值,通常情况下,在精确率和召回率都很高的时候,F1-Score也会很高。
有了以上的评价指标,随机按比例选取一部分正常和异常用户的用户图向量作训练集,剩下的作测试集,以此来检验SVM模型的分类效果,每组实验做10次,取其平均值。固定惩罚参数和核函数为默认值,调节不同比例的测试集,实验结果如表4所示。由表4可以看出:精确率和召回率互相影响;根据F1-score可以看出当测试集与训练集分别取80%和20%时,模型能达到较好的分类结果,此时,F1-Score为0.74。
当固定训练集与测试集的比例80%和20%、选择默认核函数,调节不同的惩罚参数,实验结果如表5所示。由表5可知,设置惩罚参数分别为0.001、0.1、1、10、100,当惩罚参数设置为1时,能取得较好的分类结果。
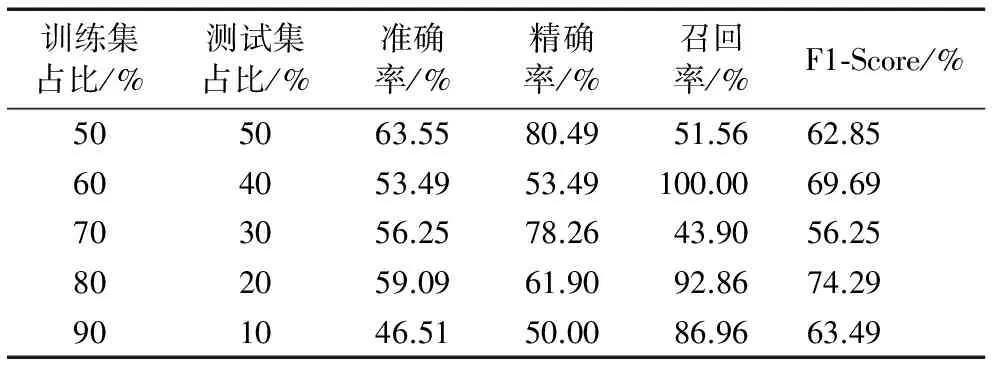
表4 不同比例的训练集和测试集的实验结果Tab. 4 Experimental results for different proportions of training sets and test sets
当固定训练集测试集比例分别为80%和20%、取惩罚参数C=1,选取不同的核函数时,各种核函数对分类结果的影响如表6。由表6可以看出,线性核函数表现良好,径向基核函数分类效果较差。所以,应选择线性核函数作为SVM的核函数,这样能达到最佳的分类效果。
综上,本文提出的方法调节合适的训练比例、选择合适惩罚参数和最优的核函数之后,最终模型的精确率能达89.67%,召回率达到92.86%,两者的加权调和F1-score也有0.89,都比文献[11]中所提方法的28%的召回率高出两倍之多。
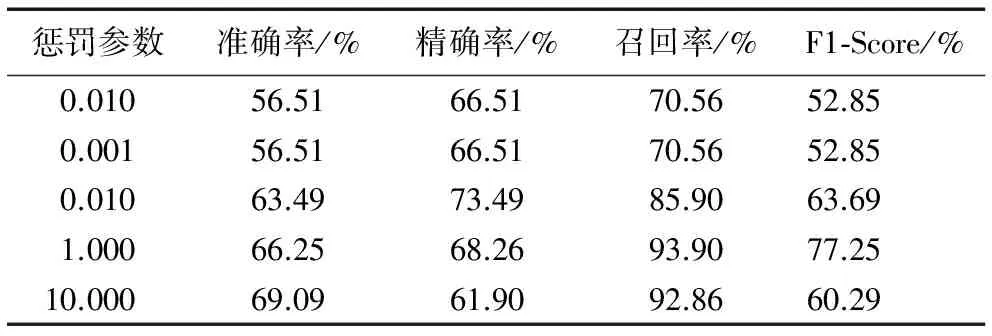
表5 选择不同惩罚参数对实验结果的影响Tab. 5 Experimental results of selecting different penalty parameters
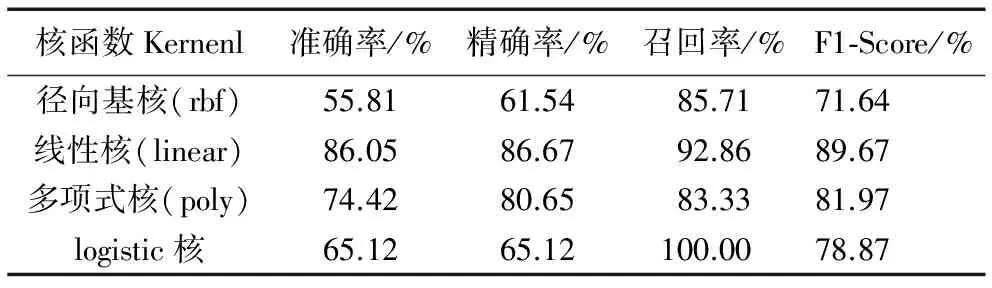
表6 选择不同核函数的实验结果Tab. 6 Experimental results of different kernel functions
5 结语
本文提出了在集中式认证系统和企业内部网络中,通过分析用户的认证行为来检测、识别系统或网络中的异常用户的方法。通过将用户的认证活动信息转化为用户认证图,再提取图中的属性来得到更为浓缩的用户认证图向量,之后对用户认证图向量进行建模,间接地对网络中的异常用户进行检测与识别。实验结果表明,该模型能有效对企业网络中正常与异常用户进行分类,相比Kent等[11]所使用的Logistic模型28%的召回率,本文的检测效果更好,模型更优。本文的不足之处是模型中所提取的特征杂乱,没有对特征的重要性进行区分。下一步的工作计划是进行特征的筛选,提取一些对于检测异常更优质的特征,即用更少的特征获得更优的效果;再结合β数据集中的其他几个数据集,来进行进一步的研究。
参考文献:
[1]JIANG P, WEN Q, LI W, et al. An anonymous and efficient remote biometrics user authentication scheme in a multi server environment [J]. Frontiers of Computer Science, 2015, 9(1): 142-156.
[2]王英,向碧群.基于用户行为的入侵检测系统[J].计算机工程,2008,34(9):167-169. (WANG Y, XIANG B Q. Intrusion detection system based on user behavior[J]. Computer Engineering, 2009, 34(9): 167-169.)
[3]王平,汪定,黄欣沂.口令安全研究进展[J].计算机研究与发展,2016,53(10):2173-2188. (WANG P, WANG D, HUANG X Y. Advances in password security [J]. Journal of Computer Research and Development, 2008, 34(9): 167-169.)
[4]HE D, WANG D. Robust biometric-based authentication scheme for multiserver environment [J]. IEEE Systems Journal, 2015, 9(3): 816-823.
[5]WANG D, WANG P. Two birds with one stone: two-factor authentication with security beyond conventional bound [J]. IEEE Transactions on Dependable and Secure Computing, 2016(99): 1-22.
[6]KENT A D, LIEBROCK L M. Differentiating user authentication graphs [C]// SPW ’13: Proceedings of the 2013 IEEE Security and Privacy Workshops. Washington, DC: IEEE Computer Society, 2013: 72-75.
[7]JOHNSON A, DEMPSEY K, ROSS R, et al. Guide for security configuration management of information systems [EB/OL]. [2017- 03- 06]. http://www.gocs.eu/pages/fachberichte/archiv/045-draft_sp800-128-ipd.pdf.
[8]AGARWAL N, SACHS E, KONG G, et al. Central account manager: US, US8789147 [P]. 2014- 07- 22.
[9]赛迪网.2016网络安全大事件[R/OL]. [2018- 08- 01]. http://www.ccidnet.com/2016/0801/10162993.shtml. (CCIDNET. Network security big event of 2016. [R/OL]. [2016- 08- 01]. http://www.ccidnet.com/2016/0801/10162993.shtml.)
[10]启明星辰 yepeng.八大典型APT攻击过程详解[R/OL]. (2013- 08- 27) [2017- 01- 15]. http://netsecurity.51cto.com/art/201308/408470.htm. (YE P. 8 typical APT attack process analysis in detail [R/OL]. (2013- 08- 27) [2017- 01- 15]. http://netsecurity.51cto.com/art/201308/408470.htm.)
[11]KENT A D, LIEBROCK L M, NEIL J C. Authentication graphs: analyzing user behavior within an enterprise network [J]. Computers & Security, 2015, 48: 150-166.
[12]JAVED M. Detecting credential compromise in enterprise networks [D]. Berkeley: University of California, Electrical Engineering and Computer Sciences, 2016.
[13]饶鲜,董春曦,杨绍全.基于支持向量机的入侵检测系统[J].软件学报,2003,14(4):798-803. (RAO X, DONG C X, YANG S Q. An intrusion detection system based on support vector machine [J]. Journal of Software, 2003, 14(4): 798-803.)
[14]CHITRAKAR R, HUANG C. Selection of candidate support vectors in incremental SVM for network intrusion detection [J]. Computers & Security, 2014, 45: 231-241.
[15]何大韧,刘宗华,汪秉宏,等.复杂网络与系统[M].北京:高等教育出版社,2009:148. (HE D R, LIU Z H, WANG B H, et al. Complex Networks and Systems [M].Beijing: Higher Education Press, 2009: 148.)
[16]KENT A D. Cyber security data sources for dynamic network research [M]// Networks and Cyber-Security. River Edge, NJ: World Scientific Publishing Company, 2016: 37-65.
[17]周志华,杨强.机器学习及其应用[M].北京:清华大学出版社,2011:95. (ZHOU Z H, YANG Q. Statistical Learning Method [M]. Beijing: Tsinghua University Press, 2011: 95.)
