DRVisSys:基于属性相关性分析的可视化推荐系统
2018-04-08吴小全戴震宇
吴小全,李 晖,陈 梅,戴震宇
WU Xiaoquan1,2,LI Hui1,2,CHEN Mei1,2,DAI Zhenyu1,2
1.贵州大学 计算机科学与技术学院,贵阳 550025
2.贵州大学 贵州省先进计算与医疗信息服务工程实验室,贵阳 550025
1.College of Computer Science and Technology,Guizhou University,Guiyang 550025,China
2.Guizhou Engineering Lab of Advanced Computing and Medical Information Services,Guizhou University,Guiyang 550025,China
1 引言
可视化通常是数据分析中一个关键步骤。加拿大维多利亚大学的研究人员[1]提出了可视化分析任务,包括三个主要步骤:数据属性子集选择、可视化展现模式推荐、数据和图表映射。文献[1]证明,计算出和目标具有强相关性的属性子集并为其确定合适的可视化展现模式是一项困难的技术工作。尤其是当数据和维度数量增加时,现有的可视化分析系统[2-3]通常会面临如下问题:
(1)多维属性子集选择的搜索空间不够大。现有数据分析工具在对多维数据集进行非平凡属性组分析时,需耗费大量时间进行迭代计算并构建可视化展示模式,且这个过程通常需要人为干预和反馈,未能包含对所有重要的属性组合的探索和评估。
(2)对分析人员的技术门槛要求较高。由于通常要求分析人员能够针对初步分析结果做进一步的关联分析和探索,分析人员需具备良好的统计知识和编程技术素养,进一步增加了应用难度。
(3)分析过程的自动化程度不够高。缺乏基于用户行为反馈的推荐模型及其展现模式的自动化更新机制。
针对解决上述问题,法国里尔第二大学的研究人员设计并实现了基于知识库技术实现可视化推荐系统VizAssist[4]。该系统为了推荐出合适的可视化图表,在属性选择上充分考虑到属性的数据类型和属性的权重,优先选择权重高的属性通过知识库内部已制定规则构建可视化展现模式。然而在设计知识库时,它依然存在规则有限的缺陷,导致部分不符合该规则的属性无法构建可视化展现模式。此外,VizAssist通过人为设置属性的权重和属性的数据类型来决定推荐的属性列,这使得推荐出的数据可视化展示模式过于依赖人为初始化的设定,导致人为干预成为数据分析的主导地位,无法实现自动探索和推荐。Voyager[5]是华盛顿大学的研究人员研发的可视化推荐系统,其为数据分析添加合适的统计函数,通过人机交互进行数据探索,并将探索出的数据自动生成可视化图表,从而较为有效地支撑用户进行交互式数据导航。
现有的可视化推荐系统通常是通过参数设置来推荐出部分有价值的可视化展现模式,在一定程度上提高了推荐的准确率。但大多数推荐仅仅利用静态的初始化设置而忽略了数据本身动态组合的特性。数据属性之间的关联性是数据价值的潜在表现。此外,现有可视化推荐系统通常引入了过多的人为判断操作,在处理大规模复杂多维数据时,将会增加交互难度。
针对目前可视化分析领域存在的上述问题,本文基于属性相关性分析策略,研究非平凡可视化推荐的度量标准,引入典型关联算法用于解决非平凡属性组的选择问题。设计并实现了数据分析可视化推荐系统DRVisSys,主要技术工作如下:
(1)在非平凡属性组选择环节中引入属性关联分析技术。为了从整体考虑属性之间的相关性,应用典型关联分析技术计算属性之间的关联系数,用典型关联系数大小作为非平凡属性组合的评测标准[6-7]。
(2)通过自动构建大量SQL语句来生成所有属性组及属性组对应的数据子集。并针对大量SQL语句执行过程中资源消耗较高的问题,提出并行执行查询和共享公共数据子集的技术。
(3)引入知识库技术来构建可视化展示模式。只需将选择出的非平凡属性组及对应的数据子集作为输入,便可自动通过知识库构建出可视化展现模式。
(4)设计并实现了基于用户反馈的可视化推荐模型的持续更新方法,可根据用户行为迭代出更合适的展示模式[8]。
2 预备知识
2.1 非平凡属性组评测
麻省理工学院的研究人员,在2015年提出通过计算原数据集与参考数据集之间的偏差来确定非平凡属性组的方法[9]。该方法假设偏差值越大,属性组成为非平凡属性组的可能性越大。但部分特殊值可能会严重影响整体偏差值,从而导致非平凡属性组的分析有偏差。为解决此问题,本文通过分析属性之间相关关系来确定非平凡属性组。为了能从整体考虑属性之间相关关系,本文在计算过程中还引入了典型关联分析技术。
计算属性组的典型关联系数时存在下述问题:当属性组里存在一个或者多个非数值属性列时,无法计算非数值属性列的关联系数。本文根据SQL92标准将数值类型属性归类为度量属性,其他属性归为维度属性。在计算维度和度量的相关性时,首先按维度属性对数据集进行分组,然后在分组内计算度量属性的SUM、AVG、COUNT聚合函数值,选择组内任意属性构建属性组并计算其相关性。
为了解决当前可视化推荐系统对多维属性子集选择的搜索空间不够全的问题,DRVisSys对整个属性子集空间进行探索[10]。对任意数据集进行探索并生成候选属性组时,候选属性组的数量由数据集的维度属性和度量属性决定。假设数据集中有m1个维度属性,m2个度量属性,在生成候选属性组时,根据各维度属性进行分组,计算组内度量属性的聚合函数值(SUM、AVG、COUNT)。然后任意从该组中选择属性构建属性组,则共计会产生属性组。
2.2 基于可扩展VKB技术的知识库
基于VKB技术的知识库起源于1980年的BHARAT系统[11-12]。2015年,VizAssist系统的研究人员提出基于VKB技术的知识库构建方法,用于简化复杂可视化模型的构建。然而VKB技术受限于有限的规则模型,无法分析当前知识库内现有规则之外的可视化模型。本文提出基于可扩展VKB技术的知识库模型,为扩展知识库规则定义一套扩展机制,可通过扩展API添加新的规则,不断完善知识库。这使得推荐出的可视化展示模型能够更好地满足需求。
2.3 符号列表
本文用符号D={d1,d2,…,dn}表示数据子集,其中每一个di由k个属性组成{A1,A2,…,Ak} ,每个属性的数据类型为ti,用DT表示属性分类。下面列出了文中用到的其他符号。
VKB知识库模型所需符号定义:
D={d1,d2,…,dn}为数据子集定义;D={A1,A2,…,Ak}为数据属性定义;DT={Dimension,Measure}表示属性类型,简写为DT={dim,mea};ti,ti∈DT表示每个属性的数据类型;C={C1,C2,…,Cm}为每个组合的关联系数;V={V1,V2,…,Vv}为非平凡属性组;ρ为推荐系数;W为属性权重值。
3 系统总体设计
3.1 系统总体结构
DRVisSys系统的总体架构如图1所示。主要由可视化表现层、执行引擎层和数据库持久层三部分组成。
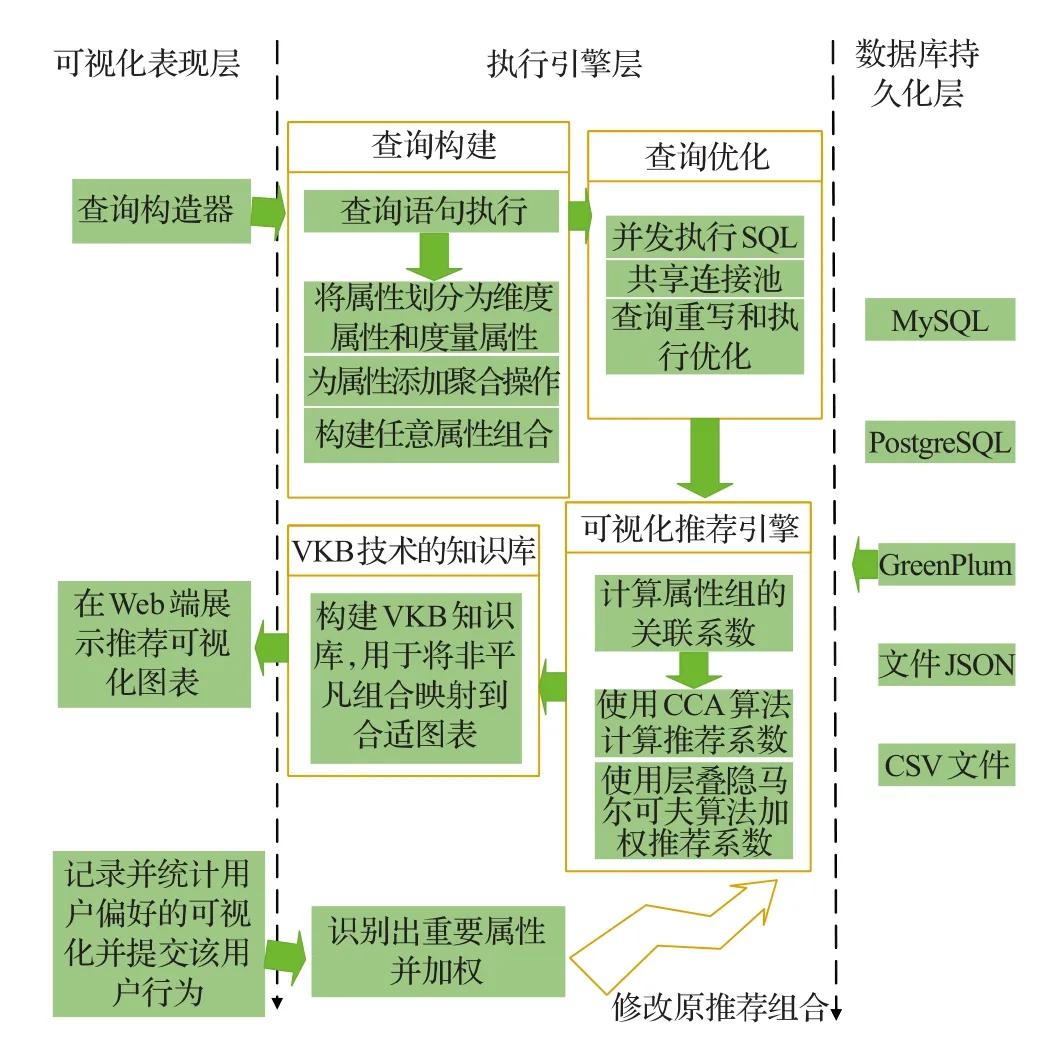
图1 DRVisSys系统结构框图
可视化表现层主要分为三个模块:(1)可视化构建查询语句模块。主要通过点击拖拽数据库表字段来定义查询条件,实现数据子集的生成。(2)可视化展示模式构建模块。在Web页面使用Echart3.0显示推荐可视化图表,并实现了图表数据异步加载。(3)用户交互模块。DRVisSys系统记录和分析当前用户对图表选择偏好,异步地将该用户行为反馈给后台执行引擎层。
执行引擎层主要负责计算和生成可视化推荐模型。具体包括四部分:
(1)查询构建模块。主要负责对任意属性组合构建查询语句,生成对应的数据子集。
(2)查询优化模块。负责优化(1)中查询语句的执行,减少整个执行引擎中数据库查询延迟。在此部分,本文设计并实现了查询的并行执行机制和共享公共表达式的优化策略。具体技术方法详见本文4.1节。
(3)可视化推荐引擎模块。主要负责计算出K非平凡属性组。该模块计算(1)中数据子集的典型关联系数,以关联系数排序,并选择前K个作为非平凡属性组。
(4)基于VKB技术的知识库模块。负责利用基于VKB技术的知识库技术,为(3)中生成的非平凡属性组构建出合适的可视化展现模式。
3.2 可视化展现模式构建
在DRVisSys系统中,针对一组非平凡的属性组{V1,V2,…,Vv},知识库通常将V中的属性类型、属性数据值统计、属性的权重等因素作为知识库引擎构建可视化展现模式时的输入。知识库引擎将输入的参数结合库中规则进行计算,然后输出符合知识库中规则的可视化展现模式。
在本文的工作中,通过基于VKB技术的知识库构建可视化展示模式。本文针对不同图表的特性构建对应的推荐规则。例如:柱状图用于展现多类别数据之间的差异,其特点如下:(1)展现数据可划分多种类别且类别不能过多;(2)数据必须是两维以上,其中至少一维是数值列;(3)数据维度不能过多,否则无法展示多类别的比较关系。系统根据该特点设计柱形图模型规则如下:(1)输入数据集的维度是2~5维;(2)至少存在一列数值数据,该数值类型的列用作为Y轴;(3)存在一列数据可用于分类,类别不超过30种,该列作为X轴。上述规则涉及的参数可根据需求调整。其他图表亦根据其特性构建相应的规则。针对满足多种图表模型规则的数据,系统能生成多个可视化图表,从多个角度展示数据价值。
针对上述构建的知识库规则,本文构建可视化展示模式的步骤如下:(1)确定非平凡属性组中的维度属性和度量属性,使用维度属性和度量属性生成合适的坐标轴。(2)统计属性组中的数据分布情况。通过COUNT、AVG和SUM可以了解属性值分布及总体比例情况。(3)构建可视化展现模式。将(1)、(2)中计算结果及属性组对应的数据集作为输入,利用库中规则进行计算,将属性组映射成对应的可视化展现模式。
3.3 可视化推荐展示结果
如图2是DRVisSys系统针对“病人治疗费用表”推荐出的可视化图表。整个区域分为三部分:A区是用于对每一个可视化图表的放大展示;B区是用于实时展示根据用户行为反馈生成的新的可视化图表;C区是用于显示推荐出的所有可视化图表。

图2 DRVisSys推荐出的可视化展示图表
从图2可以看出,DRVisSys根据不同属性集推荐出各种图表对数据进行展示。以(A)中的雷达图生成为例,该图表的构建流程简述如下:
(1)构建雷达图规则模型。雷达图是用来显示多项指标数据的数值占比情况。雷达图的推荐规则如下:属性维度数目3~10;任意两项指标相关系数偏差不超过0.1;数据量不超过100条。
(2)为数据集构建可视化展现模式。当前雷达图属性列有{ks,cwf,fyh,jcf,hyf},将字符型属性ks作为维度属性,其他作为度量属性。通过对任意属性列的关联系数计算,得知其关联系数的偏差都不超过0.1。上述计算结果符合雷达图规则,因而将该属性组映射成雷达图。
DRVisSys支持用户交互。系统可根据用户行为反馈,更新推荐模型。DRVisSys对当前用户选中可视化展示模式的偏好行为进行分析,将相应的属性添加权重并重新计算出非平凡属性组,更新当前推荐模型,构建新的可视化展现模式。相应的结果,均在B区列出。
4 查询优化及主要算法设计
本章主要介绍DRVisSys系统的两种查询优化技术,分别是并行执行查询技术和共享公共表达式技术[13-15]。此外,为了过滤大量的非平凡属性组,DRVisSys引入了典型关联算法并采用奇异值分解法求解出典型关联系数,取TopK个属性组定义为非平凡属性组。
4.1 查询优化
4.1.1查询的并行执行
为了增加多维属性子集选择的搜索空间,DRVisSys系统对数据集中的所有组合进行探索。对于数据集中有m1个维度属性m2个度量属性,生成的候选属性组的数量是m1×(2m2-m2)。每个属性组所对应的数据子集是通过执行一条为该属性组特别构建的SQL查询语句而得到。因此,获取各候选属性组对应的数据子集需要构建并执行大量SQL语句。考虑到候选属性组的数量,此过程的时间开销极大。DRVisSys通过采用多线程并行执行上述SQL任务的方法来提高查询执行效率。为了减少并行执行过程中数据库连接增加的问题,DRVis-Sys引入了数据库连接池技术来实现数据库连接共享,进一步减少数据库连接延迟。
4.1.2查询重写和执行优化
在构建候选属性组合时,属性组之间存在相同属性,即与之相对应的SQL之间存在公共的表达式。为了减少查询的执行开销,DRVisSys系统通过基于共享公共表达式(及其对应的数据子集)的查询重写技术实现多个SQL查询语句的合并。具体优化步骤如下:
(1)合并同一属性的不同聚合查询。在同一分组属性下,对所有度量属性添加不同聚合函数(如:SUM、AVG、COUNT)。若为每个聚合函数操作构建一个查询语句,会造成资源浪费。DRVisSys将类似于如下查询(a,m,f1),(a,m,f2),…,(a,m,fi)合并,重写成新的查询语句 (a,m,{f1,f2,…,fi})。
(2)合并同一分组属性的不同查询。针对同一分组属性下不同属性的聚合查询,本文采用group by分组属性区分不同聚合查询的结果集,将多个聚合查询重写成一个聚合查询。DRVisSys系统将类似如下的查询语句(a,m1,f),(a,m2,f),…,(a,mi,f)合并,重写形成新的查询语句(a,{m1,m2,…,mi},f)。
(3)添加分组属性,合并具有公共子表达式的不同查询。此外,存在一种特例:其中一条查询语句的结果集包含另外一条查询语句的结果集。此时,不能利用原有分组属性区分查询结果集,需为其添加新的分组属性。例如:合并如下所示的Q1和Q2两个查询语句时,需要为其新增分组属性G1和G2。
Q1=SELECTA,F(m) FROMDWHEREX=’贵州’GROUP BYA
Q2=SELECTA,F(m)FROMDGROUP BYA
将上述两个查询Q1和Q2合并,重写成新查询Q3:
Q3=SELECTA,F(m),CASE IFX=’贵州’THEN 1 ELSE 0 ENDAS G1,1AS G2FROMDGROUP BYA,G1,G2
4.2 非平凡属性组选择算法
为了从大量属性组合中过滤掉大部分平凡的属性组,本文引入CCA[16]作为非平凡属性组的评估算法。通过CCA算法可以计算出属性之间的关联系数,将其作为非平凡属性组的评估标准。但在求解典型关联系数时,为了避免属性组出现的小样本数据可能导致无法计算出关联系数的问题,DRVisSys系统采用奇异值分解法求解典型关联系数。非平凡属性组选择算法的步骤如下。
(1)计算推荐系数。通过计算属性组之间典型关联系数作为推荐的系数,下面是CCA计算相关系数过程:
①设定属性组中存在各包含n个样本的U和V,而且U和V的维度大于1。
②计算出样本U的方差Suu,样本V的方差Svv,以及U和V样本的协方差Suv。
④对矩阵M进行奇异值分解,计算出最大的奇异值,即为所需的最大关联系数ρ。
(2)加权推荐系数。考虑到部分维度属性在应用中有着特殊的实际意义,例如:日期、姓名和部门等,本文采用层叠隐马尔可夫算法[17]识别出此类重要属性并为其添加权重值。该算法为每种命名实体的识别方法构造独有的识别模型,例如:人名识别的HMM、地名识别的HMM和机构识别的HMM等等。当对某一个属性实体进行识别时,如果属于重要实体,设置该属性的权重值W=1;否则,设置权重值W=0。
在选择非平凡属性组时考虑到部分属性的权重值,本文引入式(1),将权重值与关联系数相结合,重新计算推荐系数。
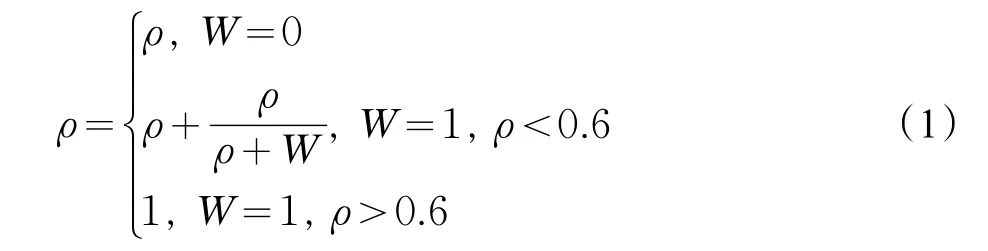
(3)取TopK个属性组将加权后的推荐系数进行排序,取前K个属性组合作为非平凡属性组合。推荐引擎默认取K=15,但当候选组合数超过15组且推荐系数ρ>0.9,引擎会自动添加推荐系数大于0.9的属性组作为非平凡属性组,其中K和ρ的值可根据需求自定义。
4.3 计算非平凡属性组的案例
为进一步说明非平凡属性组的选择算法流程,本节以“病人治疗费用表”为例进行说明,该表共23维属性,其中有10维维度属性,13维度量属性。根据2.1节中的方法构建属性组合及对应数据子集,然后通过推荐算法计算出平凡属性组,步骤如下:
(1)利用典型关联算法计算属性组的关联系数,并对其进行排序。本节取三个属性组合进行讲解:属性组V1={ks,cwf,hyf,fyh,jcf},计算典型关联系数ρ=0.94;属性组V2={cyqtzd,hyf,cwf,fyh,jcf,xyf},ρ=0.96;属性组V3={ks,zyf,ts},ρ=0.46。
(2)使用层叠马尔可夫算法识别重要属性并对属性进行加权。针对属性组V1,通过算法识别得出ks(科室)在命名实体中属于部门实体,属于重要属性且ρ>0.6,根据式(1)重新计算出推荐系数ρ=1;针对属性组V2识别,不属于重要属性,推荐系数不需修改;针对属性组V3,识别出ks属于重要属性且ρ<0.6,根据式(1)重新计算出推荐系数ρ=0.775。同理,其他属性组以此方法计算推荐系数。
(3)对重新计算的推荐系数进行排序,取TopK个属性组作为非平凡属性组,K=15。
5 实验结果与分析
对DRVisSys系统性能进行评测和分析。实验过程中选用不同数据量、不同维度、不同记录数的数据集进行评估,评估指标是DRVisSys推荐出可视化展现模式所需的时间开销。测试数据包含20个不同数据集,具体数据集描述如表1所示。
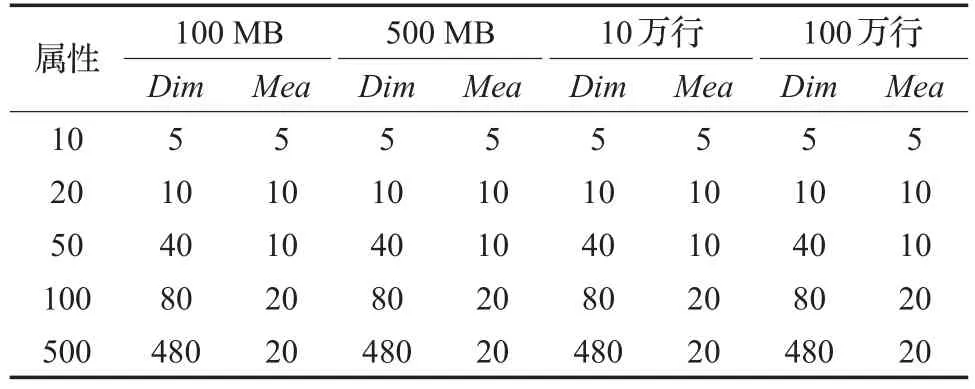
表1 实验数据集描述
所有实验运行在两个节点上,分别是分析数据集的数据节点和推荐引擎的执行节点,其中数据节点数量可根据实验要求进行配置,执行引擎节点是单节点。节点的参数配置如表2。

表2 实验节点参数配置
如图3、图4是系统在不同数据集下的性能测试结果。图3是10万条数据和100万条数据在不同维度情况下的性能测试结果。实验结果表明,在数据集记录数相同时,随着属性维度的增加,系统执行所需时间不断增加。图3中,当维度低于50时,10万条记录和100万条记录执行时间差较小,执行时间在3~25 s;当属性维度高于50维时,执行时间都偏高。这是由于:(1)随着属性维度的增加,候选属性组合数呈指数增加。(2)随着候选属性组合数量的增长,使构建与候选属性组相对应的数据子集的CPU开销、磁盘I/O和网络传输开销均显著增加。(3)在计算出候选属性组的推荐系数时,所需要的CPU开销也随着候选属性组合数量的显著增长而增加。
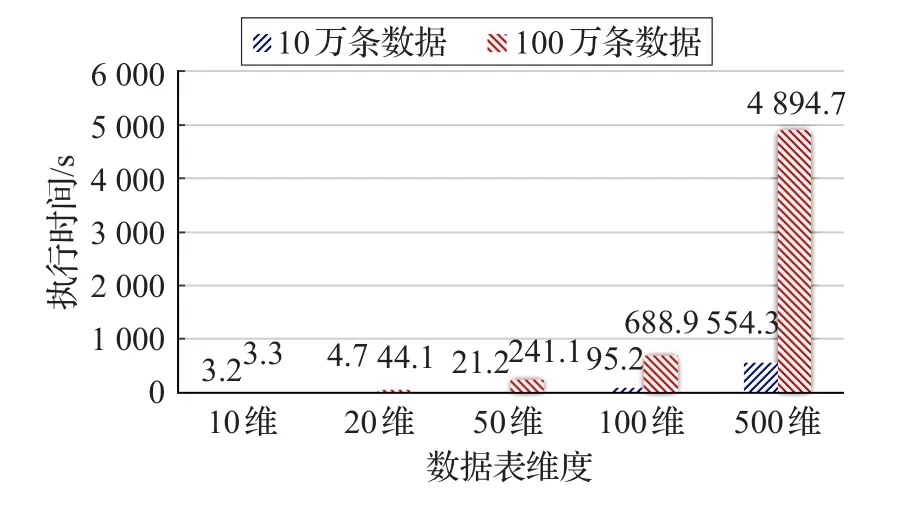
图3 10万条和100万条数据执行时间
为验证数据量对系统效率的影响,对100 MB和500 MB的数据集在不同维度情况下进行测试,实验结果如图4所示。维度相同的情况下,500 MB数据执行所需时间明显长于100 MB。数据量相同的情况下,维度越高,所需执行时间越长。
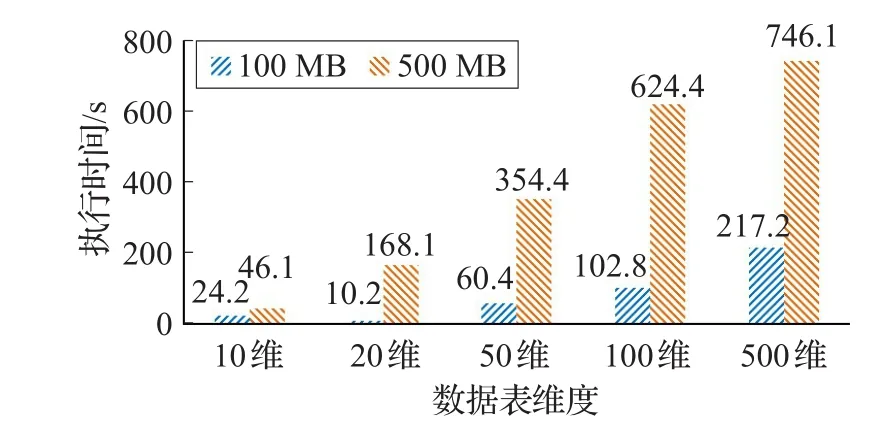
图4 100 MB和500 MB数据执行时间
图3、图4实验结果表明,该系统针对属性维度低于50的数据集,通常能够在几十秒内推荐出合适的可视化展示模式;系统针对高维度、数量大的数据集,亦能相对高效地完成推荐。
6 用户评价实验
上一章验证DRVisSys系统的性能,本章邀请用户使用真实数据进行实验,通过获取用户对该系统推荐图表的反馈来检验推荐效果。为此,该实验选择10个真实数据集(包含医疗数据、金融数据、NBA球员比赛数据)。实验招募16名计算机学院的在校硕士生参与实验,参与者有从事数据分析的人员和非数据分析方向的人员。对推荐满意度进行对比分析,本文选择VizAssist系统做实验对比。实验步骤如下:
(1)利用DRVisSys系统和VizAssist系统对10个真实数据集进行实验。两个系统在对不同数据集进行实验时,同时对同一数据集的推荐图表进行对比分析,比较各系统的推荐效果。
(2)16位参与者为系统推荐的前5个图表打分(满分为10)。参与者在评分前,需要对当前数据集进行了解,从而能更好地判断当前推荐是否有价值、有意义,推荐图表是否符合用户需求。
统计前5个推荐可视化图表平均评分情况,结果如表3所示。
从表3可以看出,DRVisSys系统的推荐效果明显好于VizAssist系统。DRVisSys系统采用典型关联算法整体分析属性之间相关关系,并且采用层叠马尔可夫算法对重要实体属性加权。VisAssist系统通过属性权重确定推荐属性,并采用交互式遗传算法修改属性权重,重新生成推荐图表。从推荐效果上看,本文中采用的算法推荐效果更好,同时也说明属性之间关联性是数据价值的潜在表现。
7 结束语
对大规模复杂多维数据进行分析时,现有的可视化分析工具需要耗费大量时间进行反复迭代计算,并且存在对多维属性子集探索空间不够大,对分析人员技术门槛高和分析过程自动化程度不够高等问题。本文设计并实现了基于属性相关性分析的可视化推荐系统DRVisSys,运用典型关联分析算法完成非平凡属性组的选择,并基于VKB技术的知识库构建合适的可视化展示模式。同时,针对执行效率问题,引入并行执行查询和基于公共表达式的查询重写技术。实验结果表明,DRVisSys系统能快速为不同维度的数据集推荐出合适可视化展现模式。
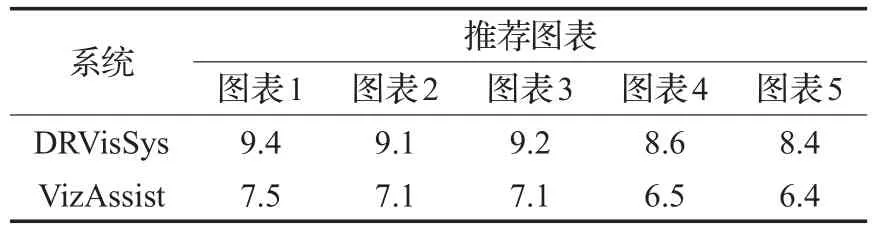
表3 可视化推荐图表评分统计表
参考文献:
[1]Grammel L,Tory M,Storey M A.How information visualization novices construct visualizations[J].IEEE Transactions on Visualization and Computer Graphics,2010,16(6):943-952.
[2]Mackinlay J,Hanrahan P,Stolte C.Show me:Automatic presentation for visual analysis[J].IEEE Transactions on Visualization and Computer Graphics,2007,13(6):1137-1144.
[3]Dan M.Tableau your data!:Fast and easy visual analysis with tableau software[M].[S.l.]:Wiley Publishing,2013.
[4]Bouali F,Guettala A,Venturini G.VizAssist:An interactive user assistant for visual data mining[J].The Visual Computer,2016,32(11):1447-1463.
[5]Wongsuphasawat K,Moritz D,Anand A,et al.Voyager:Exploratory analysis via faceted browsing of visualization recommendations[J].IEEE Transactions on Visualization and Computer Graphics,2016,22(1):649-658.
[6]Naimi A I,Westreich D J.Big data:A revolution that will transform how we live,work,and think[J].American Journal of Epidemiology,2014,47(17):181-183.
[7]梁吉业,冯晨娇,宋鹏.大数据相关分析综述[J].计算机学报,2016,39(1):1-18.
[8]Gotz D,Wen Z.Behavior-driven visualization recommendation[C]//Proceedings of International Conference on Intelligent User Interfaces,Sanibel Island,Florida,USA,2009:315-324.
[9]Vartak M,Rahman S,Madden S,et al.SEEDB:efficient data-driven visualization recommendations to support visual analytics[J].Proceedings of the VLDB Endowment,2015,8(13):2182-2193.
[10]Broeksema B,Telea A C,Baudel T.Visual analysis of multi-dimensional categorical data sets[C]//Proceedings of Computer Graphics Forum,2013:158-169.
[11]Gnanamgari S.Information presentation through default displays[M].[S.l.]:University of Pennsylvania,1981.
[12]Senay H,Ignatius E.A knowledge-based system for visualization design[M].[S.l.]:IEEE Computer Society Press,1994.
[13]Giannikis G,Makreshanski D,Alonso G,et al.Shared workload optimization[J].Proceedings of the VLDB Endowment,2014,7(6):429-440.
[14]Dalvi N N,Sanghai S K,Roy P,et al.Pipelining in multi-query optimization[J].Journal of Computer and System Sciences,2003,66(4):728-762.
[15]Sellis T K.Multiple-query optimization[J].ACM Transactions on Database Systems(TODS),1988,13(1):23-52.
[16]Dan K.A singularly valuable decomposition:The SVD of a matrix[J].College Mathematics Journal,1996,27(1):2-23.
[17]俞鸿魁,张华平,刘群,等.基于层叠隐马尔可夫模型的中文命名实体识别[J].通信学报,2006,27(2):86-94.
