考虑对象关联关系的多样化商品推荐方法
2018-04-08万常选陈煌烨
游 运,万常选,陈煌烨
YOU Yun1,2,3,WAN Changxuan1,3,CHEN Huangye1,3
1.江西财经大学 信息管理学院,南昌 330013
2.东华理工大学 理学院,南昌 330013
3.江西财经大学 数据与知识工程江西省高校重点实验室,南昌 330013
1.School of Information Technology,Jiangxi University of Finance and Economics,Nanchang 330013,China
2.School of Science,East China University of Technology,Nanchang 330013,China
3.Jiangxi Key Laboratory of Data and Knowledge Engineering,Jiangxi University of Finance and Economics,Nanchang 330013,China
1 引言
近年来,随着通信网络、电子交易平台和社会化媒体技术的快速发展,在网络平台上产生了大量的信息。对于消费者而言,信息缺乏无法理性决策,信息过量同样会使决策陷入困境,因此有必要提高消费者信息查询和分析的效率。通过推荐系统及其导航功能,决策者能在大量的网络商品信息中快速搜寻满足自身需求的商品,节约信息搜寻的成本,这在一定程度上有助于消费者摆脱由于“信息过载”所带来的决策困境。在实际应用过程中,这些推荐系统一般包括基于推荐对象相似度(知识推理)的推荐方法、基于用户兴趣的协同过滤方法、基于推荐对象关联挖掘的推荐方法或者这几种方法相结合的推荐[1-3]。基于推荐对象的相似度(知识推理)的推荐策略避免了协同过滤推荐的最初评价问题和数据稀疏性问题,但是当前基于推荐对象相似度(知识推理)的推荐方法存在两个缺点:一是在进行相似度算法的设计时,由于该算法本身的局限性,导致只有与消费者已购买商品有相同属性的对象才可能被最终推荐,这将导致推荐列表中对象类型过于单一;二是没有考虑到消费者对互补性商品和情景关联性商品的需求,忽视了消费者可能存在的对互补商品或情景相关商品的推荐需求,比如,在商品购买过程中,潜在的消费者更倾向于选择那些与自己已购买过的商品功能互补或情景关联的商品(如曾经购买过打印机的用户,随后更有可能会需要购买打印墨盒)。
针对以上存在的问题,文中从推荐商品之间的关联类型出发,综合考虑商品相似关联、情景关联和互补关联三种关联类型,提出了一种综合推荐商品间多种关联关系的多样化推荐算法。算法首先从语义关联实例的角度,进行基于领域本体的项目建模,通过分析用户兴趣本体,并对其进行偏好扩散,得到与用户兴趣本体可能存在关联关系的其他商品对象集,形成推荐候选集。其次分析用户兴趣本体与推荐候选集中各商品实例之间的综合相似度;再次分别分析用户兴趣本体与推荐候选集中各商品实例之间的层次互补度和商品互补关联度,两者综合得出推荐候选集中各商品实例的综合互补度;最后结合关联规则考察用户兴趣本体与推荐候选集中各商品实例之间情景关联特征,并结合对象间的综合相似度、综合互补度和潜在消费者兴趣度,计算得出该消费者的多样化商品推荐列表。
2 相关研究
推荐系统按照所使用的数据来分类,可以分为内容过滤[4-5]、协同过滤[6-7]和社会化推荐系统等。已有的社会化推荐算法虽然取得了一定的推荐效果,但它们大都是根据用户间社会网络关系和推荐商品直接的相似性进行研究,因此在一定程度上忽略了推荐商品之间互补关联和情景关联以及用户偏好与推荐商品之间关联的重要性。
2.1 基于本体的建模
本体是一种常用的建模方法,它主要是通过规范的知识结构、合理的层次划分,来进行知识的共享复用和逻辑推理[8]。文献[9-10]通过对推荐对象的相关领域知识的分析,建立领域本体模型,但建模时仅考虑了对象之间层次关系,忽略了推荐对象之间的属性语义关联。这将导致用户兴趣本体与推荐对象实例之间相似度计算的准确性受到影响。文献[11]利用不同领域中的语义本体信息和关联数据库,分析了音乐领域和建筑领域中的不同对象及这些对象之间的语义关联关系,构建了一个有向图,即跨领域的语义概念模型,并在该有向图的基础上,分析不同领域对象之间的语义关联关系并进行知识推理,将不同领域的对象或知识推荐给消费者,实现跨领域的推荐。文献[12]全面考虑推荐对象层次关系和属性关系,并通过电影实例之间的语义关联来改进实例的相似度计算算法,但忽略了互补关联对象的推荐。
2.2 多样性选择算法
大多商品推荐系统主要考虑属性相似的对象的推荐,从而导致推荐对象种类单一。多样性匮乏的推荐结果导致了消费者已购买、已熟悉的商品的重复推荐,而忽视了购买行为之后的情景关联性商品、互补性商品的实际推荐需求。朱郁筱等[13]对推荐系统的性能指标进行了归纳,认为推荐系统的好坏不仅要考虑准确率等传统指标,还要考虑其他指标,并特别强调了推荐的多样性指标及推荐商品在推荐列表中合理排序的重要性;文献[14]针对推荐的多样性问题,通过引入模糊相似测量等方法来提高基于内容过滤算法的有效性。薛福亮等[15]提出基于Vague理论和商品相似性计算的商品多样性选择算法,以提高推荐结果的多样性。文献[16]通过用户的需求调查和多领域知识的综合分析,将多源关联数据作为背景数据提出了基于多源关联知识的推荐系统,以实现推荐结果的准确性和有效性,但其并未从推荐对象间互补性关联和情景关联的角度来进行问题的综合分析。
在商品销售过程中,消费者购买了一件商品之后,可能会再一次购买相似的商品,更可能会购买与之具有功能互补或情景关联的商品。能否满足消费者对这些互补性和情景关联性商品的推荐需求,增加推荐商品的多样性,是当前的推荐方法务必考虑的问题,而这也将影响推荐结果的有效性。
3 问题描述
3.1 领域本体建模
本部分采用基于领域本体(Domain Ontology)的方法分别对商品(Commodities)和潜在消费者(Customers)进行建模,建立了领域本体Dom_O和潜在消费者模型PC_Model。
可以将商品领域本体表示为:Dom_O={G,RH,RP,RS,RC,P}。其中G代表领域中具有一定层级结构的信息的集合;RH指信息或者商品之间的层级结构关联;RP指概念之间的属性关联或实例之间的属性关联,这些关联将不同的概念和不同的实例组织起来,形成一个有机整体;RC指概念之间或实例之间的互补关系;RS指概念之间或实例之间的情景关系;P指商品实例集合,代表某个类别的具体实体集合。为了后面论述的需要,本文以家装商品为例,绘制家装领域本体片段(如图1所示),将家装领域本体中的类别、商品实例及其关联以图形的形式呈现出来。
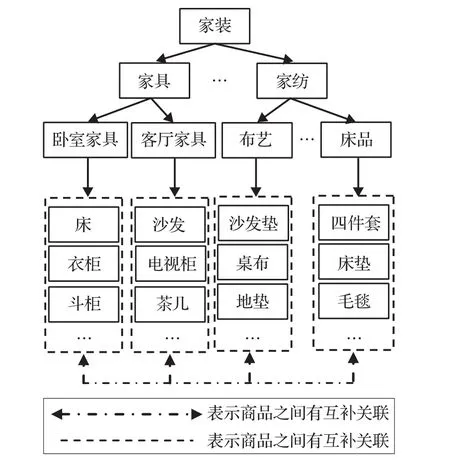
图1 家装领域本体片段
可以将潜在消费者(Customers)模型形式化表示为一个三元组:Customers_Model=(Customers_Info,Customers_DOI,Customers_Onto)。
Customers_Info代表消费者基本信息,表示为Customers_Info={CustomersID,CName,CSex,CBirth,CProfession},用来表示消费者基本信息。Customers_Onto代表用户兴趣本体,表示为Customers_Onto={C,RN,RP,P},其中C表示消费者感兴趣的概念集合,RN表示消费者之间的社交网络关系(Social Network Relationship),RP指概念之间或消费者之间的属性关系,P代表用户感兴趣的商品实例集合。Customers_DOI代表消费者兴趣度,表示为Customers_DOI={CustomersID,pi,Di(t),t},其中 pi(1≤i≤n)用来表示消费者兴趣本体P中的第i个商品实例,Di(t)(-1≤Di(t)≤1)表示在t时刻消费者对商品实例 pi的偏好值,当消费者对该商品有兴趣,则Di(t)为正值,否则为负值。随着时间的变化,Di(t)的值会发生变化。
3.2 基于商品之间关联关系的商品推荐算法
本文基于领域本体中商品实例之间的语义关联关系,分析了商品之间的相似关联、互补关联和情景关联,提出了基于商品之间关联关系的多样化推荐算法。
3.2.1商品相似度计算
商品的相似关联是指商品之间由于类别、功能和属性等相同或相近而产生的关联关系。可根据领域本体中商品实例之间的层次关系计算对应的层次相似度,根据商品实例之间的属性特征计算对应的属性相似度,最后综合得出商品实例的综合相似度。若商品实例 pi和pj属于同一个类或相似类的实例,则称 pi和 pj之间存在层次相似关联。
商品实例层次相交路径所在分支的深度越深,节点离最近的公共类越远,它们之间的层次相似度也越小。最近公共类的深度越深,商品实例 pi和 pj越具体,它们之间的层次相似度也越大。d(pi)和d(pj)表示商品实例 pi和pj的深度,d(A)为层次相交关联中相交节点的深度,D表示对应的总深度,则商品实例 pi和 pj之间的层次相似度表示为:

若商品实例 pi和 pj分别有x和y个属性,具有k个相似的属性,则称 pi和 pj之间存在属性相交关联,体现实例之间的属性相似性。当两个商品实例相同的属性越多,则k越大,说明两个商品实例类别越相近;而商品实例之间属性值越相似,则语义关联长度L(PJAi)越小,两个商品实例的属性相似度越大。
由于商品实例属性多为标称属性,因此两个商品的属性相似性可结合匹配率来计算。假设两个商品实例的属性值标准化后分别是(pi1,pi2,…,pix)和(pj1,pj2,…,pjy),其中k是匹配属性数目,则商品实例 pi和 pj之间的属性相似度表示为:
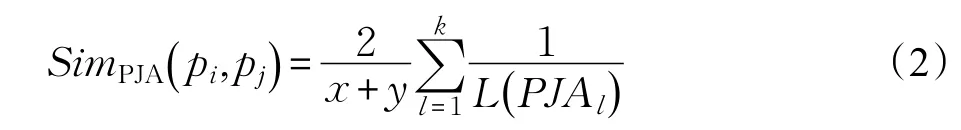
设层次相似度的权重为ε(0≤ε≤1),属性相似度的权重为φ(0≤φ≤1),且ε+φ=1,则本体中任意两个商品实例pi和pj的综合商品相似度为:
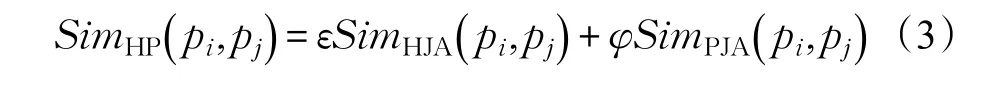
在计算时,可以根据具体应用需要调整公式(3)中的参数。
3.2.2商品互补度计算
商品的互补关联是指商品实例pi和pj之间由于功能上存在互补关系而产生的关联关系,比如打印机和墨盒之间就存在互补关联。通过层次语义互补度、商品互补关联度和商品相似度可计算出商品实例pi和pj之间综合商品互补度。若商品实例pi和 pj分别属于最近互补类Ci和Cj,商品实例 pk属于互补类Cj,相交类A为商品实例 pi和 pj的最近共同祖先,则称 pi和 pj及pi和 pk之间存在互补关联,如图2所示。
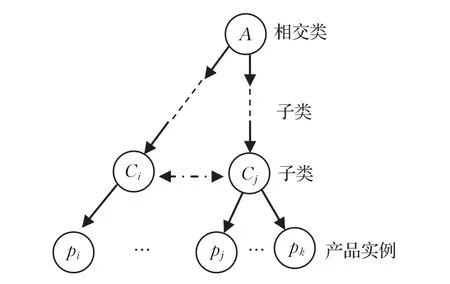
图2 pi和 pj、pk之间的层次互补关联
对于存在层次互补关联的商品实例 pi和 pj,如图2所示。对应的最近互补类Ci和Cj深度越深,商品实例 pi和 pj越具体,层次互补度也越大。同时,商品实例pi和 pj的深度越深,节点互补类Ci和Cj越远,节点之间的层次互补度也越小。d(pi)和d(pj)表示商品实例pi和 pj的深度,d(Ci)和d(Cj)为最近互补类Ci和Cj的深度,D表示总深度,则商品实例 pi和 pj之间的层次互补度表示为:
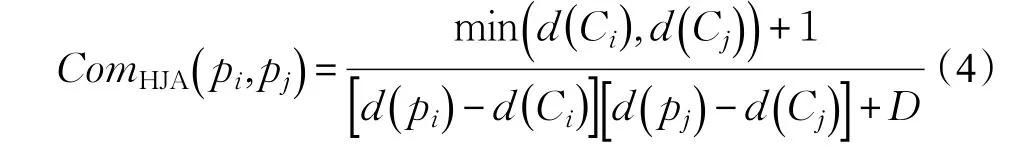
假设商品销售过程中,商品实例 pi和 pj之间存在对应关联规则 pi⇒pj或 pj⇒pi,支持度Dsup(pi⇒pj)≥α或Dsup(pj⇒pi)≥α,且置信度 Dconf(pi⇒pj)≥β或Dconf(pj⇒pi)≥β,α和β分别为对应阈值,则商品实例 pi和 pj之间的商品互补关联度可表示为:
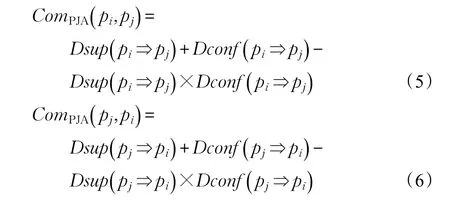
假设商品销售过程中,商品实例pi和pk之间有对应关联规则 pi⇒pk或 pk⇒pi,但支持度Dsup(pi⇒pk)<α或Dsup(pk⇒pi)<α,且置信度 Dconf(pi⇒pk)<β或Dconf(pk⇒pi)<β,α和β分别为对应阈值,则商品实例 pi和 pk之间的商品互补关联度表示为:
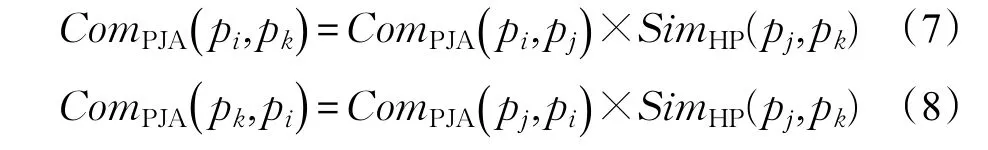
商品互补关联度与对应商品的置信度和支持度有关。系统发现的关联规则在过去可能具有较高的置信度或支持度,但随着时间的推移对应的值可能会发生变化,从而导致在实际应用中,商品互补关联度会随时间推移而发生变化。
设层次语义互补度的权重为μ(0≤μ≤1),属性相似度的权重为ω(0≤ω≤1),且μ+ω=1,则本体中任意两个商品实例pi和pj的综合商品互补度为:
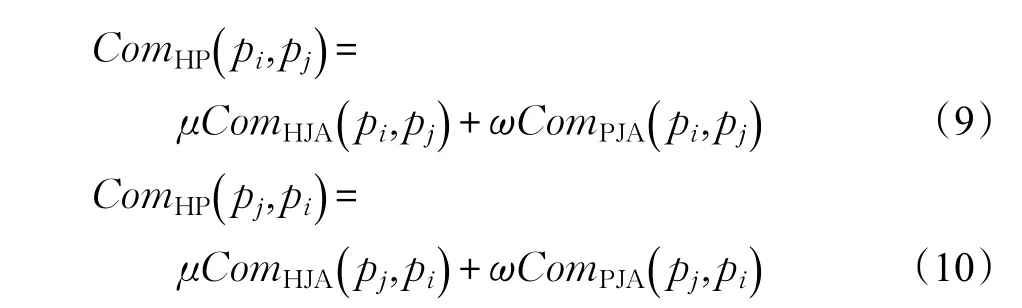
在计算时,可以根据具体应用需要调整式(9)、式(10)中的参数。
3.2.3商品情景关联度计算
商品的情景关联是指某些商品可能需要在同一情景或场合下同时出现而产生的关联关系,比如沙发和茶几之间则存在情景关联。若商品实例pi和pj是属于不同领域本体的实例,在商品销售过程中,支持度Dsup(pi⇒pj)≥α或Dsup(pj⇒pi)≥α,且置信度Dconf(pi⇒pj)≥β或Dconf(pj⇒pi)≥β,α和β分别为对应阈值,则称 pi、pj之间存在商品情景关联。商品实例 pi和 pj之间的商品情景关联度可表示为:

商品情景关联度与当前商品实例的置信度和支持度相关。系统发现的规则在过去可能具有较高的置信度或支持度,但随着时间的推移对应的值可能会发生变化。因而在商品推荐过程中,应考虑商品情景关联度的时效性。
若已知综合商品相似度、综合商品互补度和商品情景关联度,则可计算该商品的推荐度:

其中,ζ+ψ+ϑ=1(0≤ζ≤1,0≤ψ≤1,)0≤ϑ≤1 。
4 基于商品间关联关系的推荐算法
根据消费者兴趣本体Customers_Onto和消费者兴趣度Customers_DOI,基于本文第3章提出的基于商品间关联关系的多样化推荐算法对消费者维与商品维(Customers*Commodities)进行匹配。该推荐算法根据领域本体中商品之间的语义关联,对消费者兴趣本体进行偏好扩散,可以发现更多语义相似、互补和情景关联的商品实例,然后通过综合商品实例之间的相似关联、互补关联和情景关联,计算商品推荐度,并结合消费者兴趣度的高低产生商品实例推荐列表。基于商品实例关联关系的多样化商品推荐方法包含以下几点:
第一,结合领域知识对消费者兴趣本体Customers_Onto进行偏好扩散,搜寻更多与消费者模型中商品实例存在相似关联、互补关联和情景关联的商品实例,形成推荐商品候选集。该方法可使推荐结果不仅包含与消费者兴趣本体相似的商品,还包含与之存在功能互补或情景关联的商品,发现消费者多种潜在购买需求,改善推荐的效果,其步骤如下:
(1)根据消费者兴趣本体Customers_DOI中的商品编号CustomersID,在领域本体Dom_O中搜寻所有已评分的商品实例。
(2)根据商品实例之间的相似关联、互补关联和情景关联并结合商品实际销售中的关联规则数据,在领域本体Dom_O中找出与Customers_Onto中的已评分商品实例有关联的所有商品,形成推荐商品候选集CS,分
第二,根据商品实例与Customers_Onto中的已评分商品的相似关联、互补关联和情景关联预测消费者对该商品兴趣度,其计算步骤如下:
(1)针对某商品实例与用户兴趣本体的不同关联
(2)分别根据商品实例 pi类型与消费者兴趣本体pj(pj∈Customers_Onto)的综合商品相似度、综合商品互补度和商品情景关联度,来预测消费者对该商品实例的兴趣度D(pi),计算公式为:
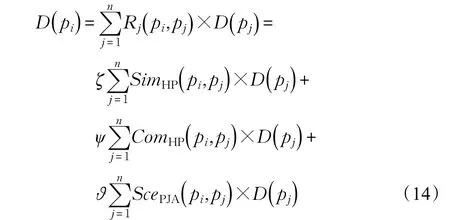
其中,ζ+ψ+ϑ=1(0≤ζ≤1,0≤ψ≤1,0≤ϑ≤1)。
(3)根据预测兴趣度的高低产生基于关联数据的推荐列表Top-N。
在该算法中,由于可以在领域本体建模的基础上,依据消费者兴趣本体对当前商品集进行过滤,获取推荐商品候选集,这将提高算法的计算速度,该算法的计算复杂度为O(nlnn)。
5 实验与结果分析
本章将利用“天猫”商城中某知名家装店铺的畅销商品及其交易数据进行实验设计,并对实验结果进行对比分析,以评估基于推荐对象间关联关系的商品推荐算法的有效性。本实验数据的爬取、处理及最终计算主要采用Python语言编程实现。实验数据集中包含了该店铺2015年3月到2017年3月期间畅销商品的基本信息,与之相关的消费者及其购买信息,产品涉及了床、床垫、餐边柜、餐椅、书桌、衣帽架、茶几、壁画等多种商品类别,不同类别的商品基本属性有所不同。购买信息主要包括消费者昵称、购买商品ID、时间、评分等内容。
5.1 实验设计
在实验中,着重考察推荐商品候选集CS中商品与消费者兴趣本体Customers_DOI中商品的关联和消费者的兴趣偏好对商品推荐列表排序及推荐效果的影响。假设某消费者小明(CustomersID=1)在当前时刻t买过两件商品 p1(商品型号:CP1A-A,商品类别:床)和 p2(商品型号:LA202-S,商品类别:餐桌),根据评分确定其对这两种商品的兴趣值分别为0.8和0.2,小明的消费者模型可以表示为Customers_Model=(Customers_Info,Customers_DOI,Customers_Onto),其中Customers Info={“1”,“小明”,“男”,“30”,“教师”},Customers DOI={(1,p1,0.8,t),(1,p2,0.2,t)}。
根据小明的消费者模型,结合本文的推荐算法,给出将为小明推荐的商品序列。
首先,对消费者兴趣本体Customers_Onto进行偏好扩散,根据3.1节建立的领域本体模型在数据集中找出与Customers_Onto中商品 p1和 p2存在关联关系的其他商品,形成推荐商品候选集CS={pi},其中i=3,4,…,75。在该候选集中包含了该店铺2015年3月到2017年3月期间畅销的73种商品。包含 p1、p2在内的这75种产品有床、床垫、餐边柜、餐椅、书桌等16种商品类别,实验将涉及这些商品的基本信息,以及与之相关的21 524位消费者及其98 284条购买订单信息。在本实验中为使描述简化,对这75种商品进行了重新编号,商品编号及类别信息如表1所示。
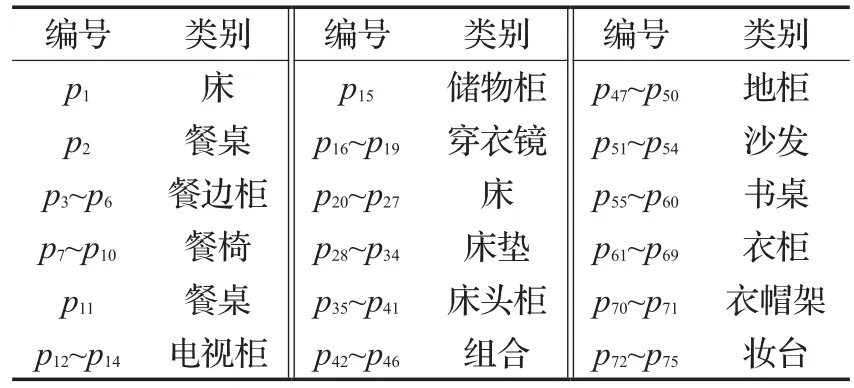
表1 商品编号及类别说明
其次,根据式(1)~(3)计算推荐商品候选集CS中商品与Customers_Model中两个商品 p1和 p2的综合相似度,其中ε=0.5,φ=0.5;根据式(4)~(10),计算偏好扩散后的商品实例与Customers_Model中两个商品实例 p1和 p2的综合商品互补度,式(10)中取 μ=0.5,ω=0.5;根据式(11)和式(12),计算偏好扩散后的商品实例与Customers_Model中两个商品实例p1和p2的商品情景关联度。t时刻Customers_Model中2个商品实例与其他73个商品实例的对应的支持度和置信度的部分数据,如表2所示,计算结果部分数据如表3和表4所示。
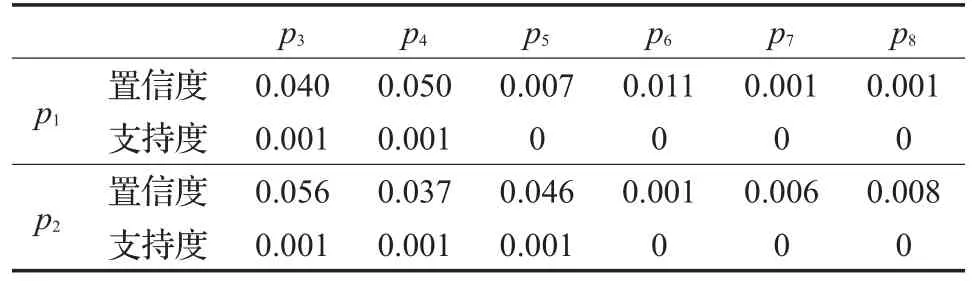
表2 t时刻2个商品实例与其他实例对应的支持度和置信度的部分数据
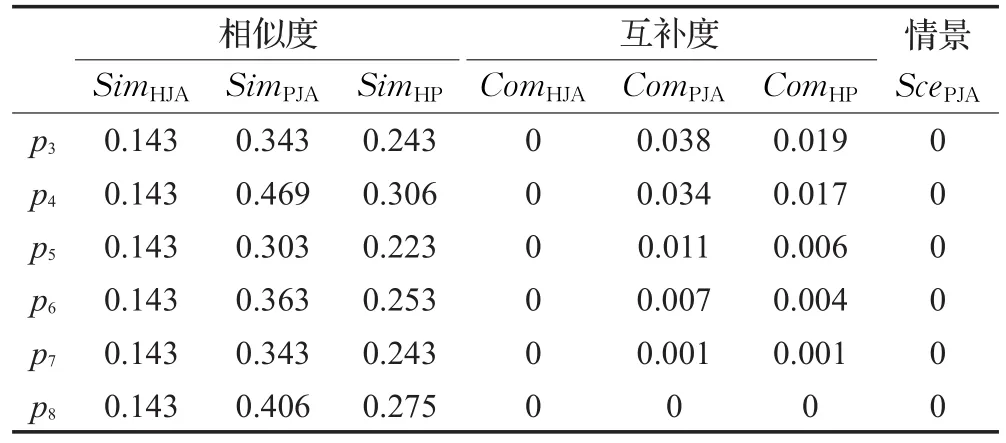
表3 t时刻Customers Model中p1与其他实例的部分关联数据
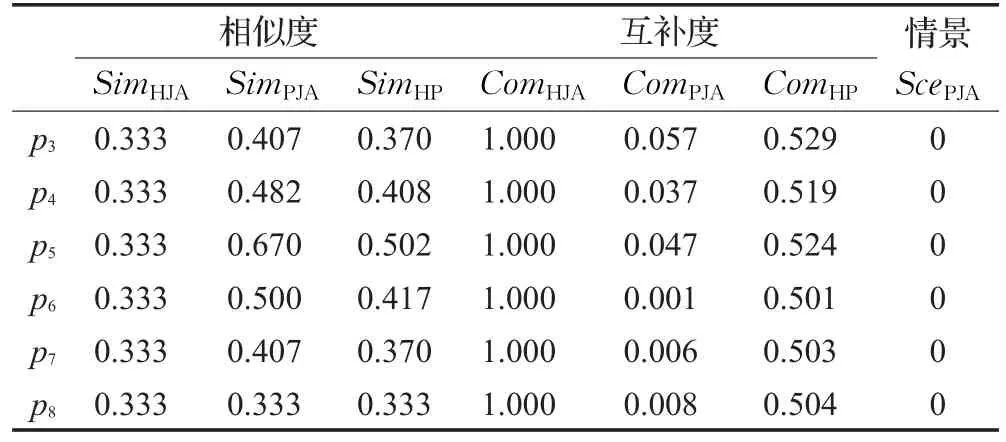
表4 t时刻p2与其他实例的部分关联数据
设 ζ=0.3,ψ=0.3,ϑ=0.4,则可通过式(13)计算其推荐度,如表5中给出了部分商品实例推荐度。

表5 t时刻关于p1、p2的部分推荐度数据
最后,根据式(14)计算消费者对推荐候选集中的每个商品的兴趣度,计算结果如图3所示。
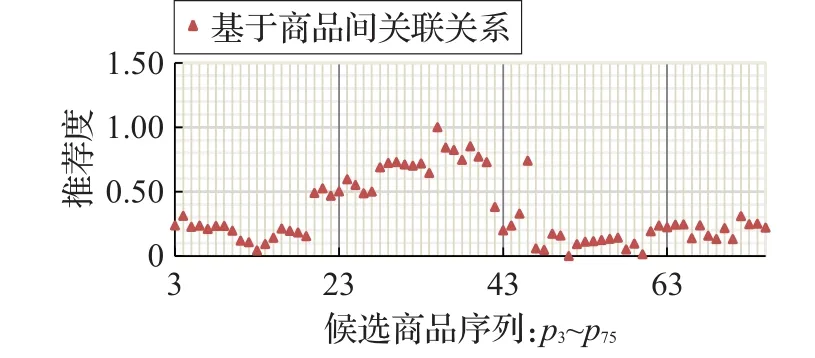
图3 基于关联关系的候选商品推荐度
根据预测兴趣度大小产生的基于推荐对象间关联关系的推荐列表中排名前8的商品为:
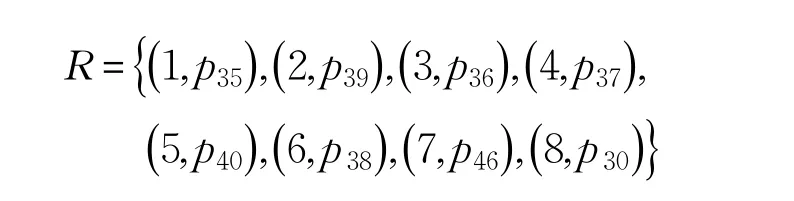
5.2 基于推荐对象间关联关系的推荐结果分析
传统商品推荐算法中,大多只依据推荐对象的属性相似度进行相似性计算。本文结合领域本体,提出了融合推荐对象间相似关联、互补关联和情景关联的商品推荐算法。
首先,为了验证该方法对推荐结果中商品排名的影响,在实验中对比了这3种方法(即基于传统商品的属性相似度的推荐方法、基于综合商品相似度的推荐方法、基于推荐商品间关联关系的推荐方法)在该数据集上的推荐效果,计算结果如图4所示。
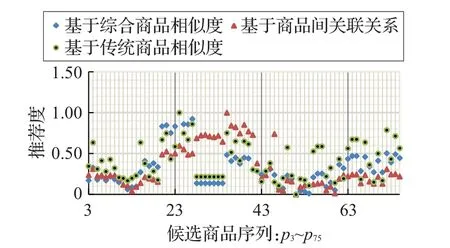
图4 3种方法的候选商品推荐度及排名变化
由图4可知,基于推荐对象关联关系的推荐算法对推荐商品类别及排名有较大调整,许多与消费者兴趣本体有着互补关联或情景关联的商品,由于推荐度增加,获得了推荐的机会,甚至有一些商品在推荐列表中排名非常靠前。如编号为 p35的商品,与用户兴趣本体相似度较小,在基于传统属性相似度和综合相似度的推荐列表中排名分别为4和11,但由于该商品与用户兴趣本体的互补关联和情景关联,其在基于推荐商品间关联关系的推荐列表中的排名上升为1。由此可见,相比于传统的基于商品相似度的推荐算法,本文提出的方法可以较好地提高互补关联或情景关联商品的推荐度,在丰富推荐列表中的商品类型的同时,也满足了消费者对与其已购买的商品具有互补或情景关联的商品的推荐需求。
其次,为了验证本文提出的算法的推荐效果,实验根据数据集中同时购买了 p1、p2这两种商品的消费者历史交易及其评分信息,采用了较为常用的precision、recall、F-measure、diversity(推荐度大于0.5的推荐商品种类数)等指标对上述3种方法的推荐效果进行对比,以全面地评价该算法的优劣。其中为了使得比较数据更加可靠,对每一位同时购买了这两种商品的消费者的相应指标分别进行计算,然后再求平均值,最终结果如表6所示。根据表6数据,不难发现,在该数据集中,基于商品间关联关系的推荐方法的各项指标都要更优,这表明该算法的推荐结果更加有效,在一定程度上更能符合消费者的实际购买需求。
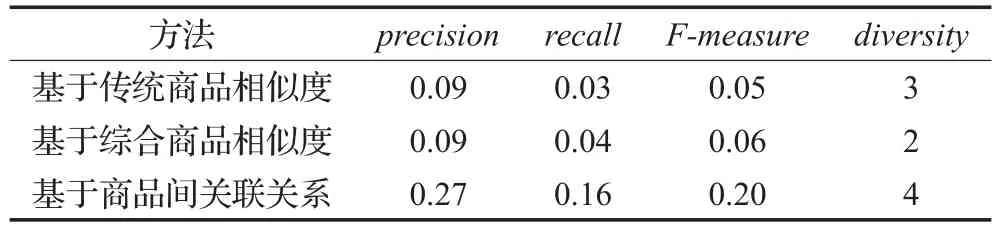
表6 3种方法的推荐效果
最后,分析了消费者偏好的变化对本文算法推荐效果的影响,通过实验发现上述3种方法中用户偏好的变化对各推荐指标值及推荐效果均有影响,结果如图5所示。通过对比分析发现消费者兴趣或偏好的变化对基于商品间关联关系的推荐算法的推荐效果虽会产生影响,但相比传统方法,其在推荐效果上仍然具有优越性。而且如果能够在推荐过程中根据实时交易数据准确把握消费者的偏好及其变化,则可以较大提高该算法的最终推荐效果。
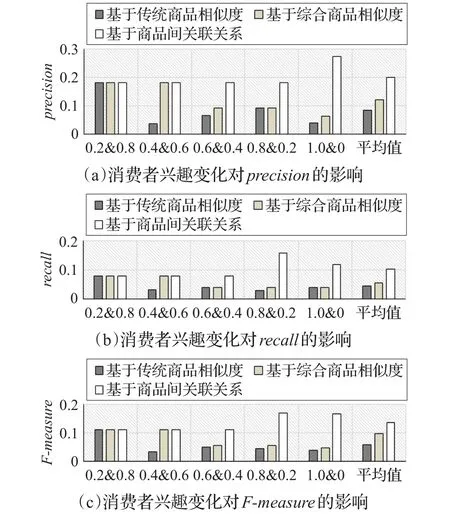
图5 消费者兴趣偏好变化对推荐结果的影响
6 结束语
本文在商品实例关联关系和领域本体建模的基础上,提出了综合商品相似度、商品互补度和商品情景关联的多样化商品推荐算法。该算法特点体现在:(1)相对于传统推荐算法仅考虑相似性商品的推荐,该算法在领域本体的基础上,结合消费者当前的购买情况,考虑了其对互补性商品及情景关联性商品的推荐需求,并据此对推荐算法进行重新设计。实验结果表明,该算法在一定程度上丰富了推荐商品的类型,提高了推荐的效果。(2)通过考虑推荐对象间关联关系和用户兴趣,来调整推荐列表排序,全方位把握消费者购买需求与偏好,使得推荐结果更加符合消费者的购买实际需要和个性化需求;同时,该算法还可以用于协同过滤推荐和信息检索中,以改善前者的稀疏性问题和后者的查全率和查准率不高的问题。
参考文献:
[1]Burke R.Hybrid recommender systems:Survey and experiments[J].User Modeling and User-Adapted Interaction,2002,12(4):331-370.
[2]Adomavicius G,Tuzhilin A.Toward the next generation of recommender systems:A survey of the state-of-theart and possible extensions[J].IEEE Transactions on Knowledge&Data Engineering,2005,17(6):734-749.
[3]姜书浩,张立毅,张志鑫.一种基于相对相似性提高推荐总体多样性的协同过滤算法[J].数据分析与知识发现,2016,32(12):44-49.
[4]Musto C.Enhanced vector space models for content-based recommender systems[C]//Proceedings of Conference on Recommender Systems,2010:361-364.
[5]Song Y,Zhuang Z,Li H,et al.Real-time automatic tag recommendation[C]//Proceedings of International ACM SIGIR Conference on Research and Development in Information Retrieval,Singapore,2008:515-522.
[6]文俊浩,舒珊.一种改进相似性度量的协同过滤推荐算法[J].计算机科学,2014,41(5):68-71.
[7]王付强,彭甫镕,丁小焕,等.基于位置的非对称相似性度量的协同过滤推荐算法[J].计算机应用,2016,36(1):171-174.
[8]Studer R,Benjamins V R,Fensel D.Knowledge engineering:Principles and methods[J].Data&Knowledge Engineering,1998,25(1/2):161-197.
[9]周莉,潘旭伟,谢玉开.情境感知的电子商务个性化商品信息服务[J].图书情报工作,2011,55(10):130-134.
[10]李志隆,王道平,关忠兴.基于领域本体的用户兴趣模型构建方法研究[J].情报科学,2015,32(11):69-73.
[11]Fernández-Tobías I,Cantador I,Kaminskas M,et al.A generic semantic-based framework for cross-domain recommendation[C]//Proceedings of International Workshop on Information Heterogeneity and Fusion in Recommender Systems,2011:25-32.
[12]李枫林,陈德鑫,梁少星.基于语义关联和情景感知的个性化推荐方法研究[J].情报杂志,2015(10):189-195.
[13]朱郁筱,吕琳媛.推荐系统评价指标综述[J].电子科技大学学报,2012,41(2):163-175.
[14]Kant V,Bharadwaj K K.Enhancing recommendation quality of content-based filtering through collaborative predictions and fuzzy similarity measures[J].Procedia Engineering,2012,38:939-944.
[15]薛福亮,马莉.利用动态产品分类树改进的关联规则推荐方法[J].计算机工程与应用,2016,52(4):135-141.
[16]Gordea S,Lindley A,Graf R.Computing recommendations for long term data accessibility basing on open knowledge and linked data[C]//Joint Proceedings of the Recsys 2011 Workshop on Human Decision Making in Recommender Systems,2011.
