中文图像描述的自动生成与模型分析
2018-04-03北京市延庆区第一中学
北京市延庆区第一中学 曹 斌
1.概述
自动图像描述功能从表面上来看,机器不仅要识别出图像中包括哪些物体,同时还必须能够理解并描述物体之间的联系以及它们各自的基本属性和参与的活动,这属于机器高级智能形态的表现了。
从具体实现机制上来看,自动图像描述从信息输入到输出经历了信息的编码和解码两个部分,在机器翻译中,信息编码把输入图像变成特征数据,解码部分再将特征数据转换成目标语言。所以图像描述结合了智能系统两个领域的发展成果:“看”和“语言表达”,分别对应人工智能最重要的两个领域: 机器视觉和自然语言处理。
图像描述的任务是通过一定的训练,让机器自动生成一句话S,来描述给定的二维图像I。句子中的第t个单词记为,其中N是句子的长度。是一个特殊的单词,表示句子结束。注意句子是变长的。单词来自于事先给定的词典,对词典中的单词进行编码后,可以用一个P维向量表示单词。一种常用的编码方式是one-hot编码,它的编码的长度P等于词典中的单词个数,如果单词只有第p个元素为,其余元素全为,那么就可以表示词典中的第p个单词。但是one-hot编码的效率比较低。而且,在使用one-hot编码的情况下,所有的单词都是独立的,距离也是固定的。而在实际情况中,一些意义比较相近的字词,它们在空间的表示应该比较接近。因此可以进一步对单词进行word embedding处理。Embedding编码把单词映射为空间中的实向量,可以更好地表示单词之间的相似性。
2.中文图像描述模型的建立
要对图像进行描述,可以先对图像中的物体进行检测与识别,从中提取出有效特征。卷积神经网络(Convolutional Neural Networks,CNN)是一种有效的图像识别方法。因为句子中的单词是有顺序的,所以可以使用循环神经网络(Recurrent Neural Networks, RNN)学习语言模型,把图像识别的结果转换为自然语言。中文图像描述的基本模型是把CNN的最后一个隐含层的状态作为LSTM的输入。而且中文标注具有其特殊性,可以直接把句子中的单个的字作为单词,也可以通过分词的方法,把句子中的语素提取出来作为单词。
本模型主要有两个重要部分组成:特征提取层和语言生成层。
(1)特征提取层。特征提取层是基于DCNN(Deep Convolutional Neural Network)深度卷积网络对输入的图像进行编程,输出一个N维特征向量,来提取每个特征中所包含的信息量。本模型中DCNN采用的是VGG网络。VGG网络架构于2014年出现在Simonyan和Zisserman中的论文中[3]。它把网络分为5组(模仿AlexNet的五层),使用的卷积核大小为 3 x 3,并把它们组合起来作为一个卷积序列进行处理。VGG网络的特点是:VGG网络非常深,一般有16~19层;由于它采用多个3 x 3的卷积,模仿出更大的感受野的效果。这些思想也被用在了后续的网络架构中,如 Inception 与 ResNet。VGG网络也有一些不足:1)训练很慢;2)weights很大。
(2)语言生成层。利用VGG网络提取完图像特征之后就可以使用LSTM来学习和生成相应标注。LSTM的初始输入是用CNN做图像特征提取后的输出向量。LSTM节点内部运算可以表示为:
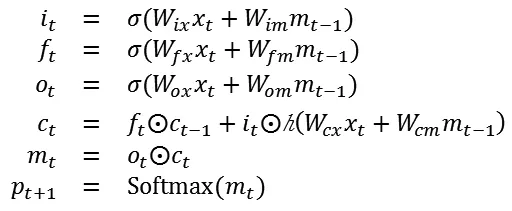
其中变量ct表示节点内部记忆,变量ft表示是否遗忘节点当前记忆,变量it表示是否读取新的输入,变量ot表示是否输出节点记忆,变量mt表示隐含状态。W是待训练的网络参数,以后用θ来表示。非线性变换表示sigmoid函数,表示双曲正切函数。符号表示Hadamard积。
网络的输出Pt是P维向量,表示对每个单词出现在句子的第t个位置的概率的预测。LSTM网络的训练过程为,学习最佳的模型参数θ,使得最大化在给定图片下其生成正确描述的概率最大:

其中I表示训练集中的一个图像,而S表示描述该图像的一个合适的标注(即正确的句子),θ为网络需要学习的参数。
由于训练集不够大,对整个数据集进行分布估计的效果不足,所以本模型容易出现过拟合问题。针对该缺点,可采取多种解决方法:如正则化、 early stopping、dropout、利用验证集进行交叉检验、权值衰减等方式。其中,正则化是在目标函数或代价函数后面增加一个正则项,降低模型的复杂度,增强模型对噪声的抗干扰能力。Early stopping方法在模型对训练集迭代收敛前截断迭代次数,停止迭代,具体思路是在训练的过程的同时,记录验证集上的正确率,记录验证集的正确率达到最佳时的epoch数,之后验证集的正确率开始下降则停止训练;本实验有验证数据,可以使用该方法。dropout方法是修改神经网络本身的结构来防止过拟合,在每次迭代中设置一定的比例随机删除一些隐藏层的神经元,假设这些神经元不存在,同时保持输入层与输出层的神经元的个数,这样便得到新的神经网络。这些方式都可以降低模型对训练集的过度依赖,防止过拟合问题,提高模型的泛化能力。
3.中文图像描述模型的分析
这里基于python语言建立一个基础的中文图像描述模型。本模型使用VGG19网络的第一个全连接层fc1的特征,维数为4096,训练集有8000张图片,每个图片配有3~5句标注,一共有38445句标注。
首先构造feature和caption之间的一一对应向量,由于caption个数比feature多,所以按照caption排列成一个38445×1的向量,根据它生成相应的大小为38445×4096的特征矩阵。然后对所有caption中出现的单词个数进行计数:如果不对中文进行分词,则一共有2591个不同的单词,其中出现频数大于3的单词只有1885个;如果使用Jieba库 对中文进行分词处理,则基本单元的组合数变多, 一共有11552个不同的单词组合,其中出现频数大于3的单词组合只有3786个。根据找到的频数大于3的单词构造词典,并计算每一个单词的出现概率。用于LSTM的语言生成模型中,其中,word embedding的结果x_t的维数为256,LSTM的隐含层的维数等于256,且LSTM模型参数优化方法是Adam,设置学习率为0.001。为防止过拟合,训练时利用验证集测试结果。实验平台为Ubuntu 14.04, 配置的GPU为Nvidia TITANX,使用Tensorflow 1.1.0版本。在该配置下,模型需要迭代约6个epoch,总共训练用时小于半小时。

图1 草地上的斑马
本模型的训练结果为:

由此可见本模型在一定程度上可以学习出语句中汉字之间的联系。但是模型一也存在很大的局限性,只适合于处理一些比较普通而且变化不大的句子,不适合区分相似的事物。比如上一个例子中本模型无法精确识别斑马数量上的特征。下表1为本模型在不同测试集上的指标。

表1 所建模型在测试集上的指标
4.全文总结
经过调试,本模型达到了较好效果,这与我们的预期以及人类进行图片描述的行为方式表现基本一致。此外,本实验还比较了分词与不分词对模型效果的影响:不分词的结果要略优于分词,这与我们的直觉相反,原因可能是分词不准确引入了噪声,以及我们的训练集样本量相对较小,分词后产生的词典更大,解空间的复杂度增加,模型更大概率收敛到效果较差的局部最优解。
[1]高永英,章毓晋.基于多级描述模型的渐进式图像内容理解[J].电子学报,2001,29(10):1376-1380.
[2]郑永哲.基于深度学习的图像语义标注与描述研究[D].广西师范大学,2017.
[3]蔡晓龙.深度学习在图像描述中的应用[J].电脑知识与技术,2017,13(24).
[4]雷国伟,吕迎阳,纪安妮等.图像特征的CNN提取方法及其应用[J].计算机工程与应用, 2004,40(14):204-206.
