产业债主体信用等级上调决定因素的定量研究
2018-03-30冯振
冯振

摘要:对企业信用质量的判断,应落脚在具体对象的经营情况和财务状况之上,而在财务信息有效的前提下,财务指标的变化应能反映主体经营的变化。关注财务指标的变化,进而预判产业债主体信用等级上调的可能性,博弈等级上调引致的信用风险溢价回落及估值提升,可能获得超过市场平均的投资回报。
关键词:产业债发行主体 信用等级 logit模型
理论上,评级上调表明被评主体信用资质改善,在其他条件不变的情况下,信用风险溢价回落,估值相应提高。也就是说,提前判断信用等级上调可能在一定时间内,获得超过市场平均的回报。
就评级逻辑本身而言,如果单从宏观经济、行业、政策等层面,来判断某些特定主体信用资质未来发生变动的可能性,则针对性也较弱;以从公开渠道获取特定主体的信息作为判断等级调整的依据,则欠缺及时性,提前预测的效果也会较差。本文认为,对企业信用质量的判断,应在对宏观、行业、政策预期的基础上,落脚在具体对象的经营情况和财务状况之上,而在财务信息有效的前提下,财务指标的变化应能反映主体经营的变化。就此来看,财务指标的变化应该是评级公司在上调被评主体信用等级时的关注要点。
由于针对城投债的评级逻辑与产业债有所不同,前者财务指标的权重也相对较低,因此通过财务指标变动来预判城投主体(及债券)等级上调的思路可行性不高。因此,本文聚焦于产业债主体1,运用logit模型,通过计量检验来探寻影响产业债发债主体评级上调的财务指标及其变动特征,并通过设置相应阈值,对具有评级上调可能性的主体进行分档,进而构建相应的投资组合,博弈评级上调可能带来的额外收益,优化资产配置,丰富投资策略。
评级上调对债券估值的影响
以2012年初至2017年三季末期间有信用等级上调记录的产业债主体发行的企业债、公司债、中票为基础,剔除国外评级机构上调评级主体发行的债券、违约主体发行的债券、具有外部担保的债券,同时为避免到期或行权可能引致的利率变动,再剔除剩余期限或行权剩余期限不足180天的债券。
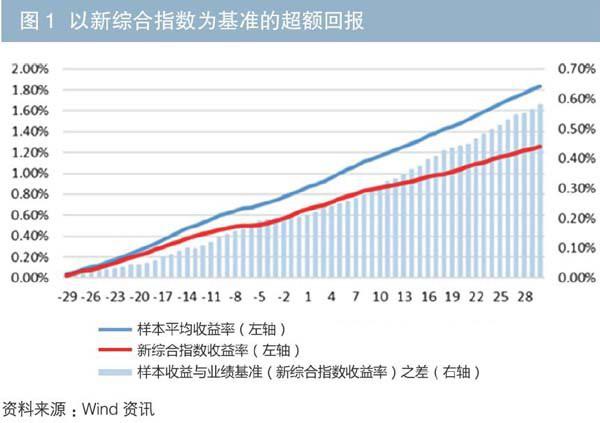
计算上述样本券评级上调前后30个交易日之间投资回报率的变动情况,并分别选取中债新综合财富(总值)指数(以下简称“新综合指数”)与中债新高信用等级财富(总值)指数(以下简称“新高信用等级指数”)作为业绩基准。总体来看,样本组合的平均回报率超过市场基准,特别是在评级调整日之后,样本组合相对市场的超额回报体现得更为明显。
在以新综合指数为基准时,样本平均回报率在观察区间内任一交易日均超过比较基准,且从评级上调日开始,样本组合回报与业绩基准之间的差距被更快地拉大了(见图1)。
在以新高信用等级指数为基准时,样本平均回报率在评级上调日前6个交易日左右超过比较基准,此后与基准收益率的差距在波动中不断被拉大(见图2)。
可见,主体评级上调对债券的估值具有一定的拉动作用,配置此类债券可能获得超过市场平均水平的回报。
指标选择、数据处理与计量检验
经营情况与评级高低密切相关,财务指标的变化应能反映主体经营的变化。在众多财务指标之中,能否抓住评级公司的主要关注点是提高预判准确率的关键。本文运用logit模型,通过计量检验对此问题进行探究。
(一)样本选择
以2012—2016年间有存续债券的产业债主体为样本。为提高数据采集的便利性,在样本期间内有信用评级上调(包括等级和展望)的主体,仅保留每年4—7月评级上调主体2,同时剔除2016年之前等级为AAA的主体3、样本期内有评级缺失的主体、样本期内主要评级机构发生变更的主体、等级调整由国外评级机构做出的主体、发生过债券违约的主体以及财务数据缺失主体。最终筛选出符合样本选择要求的主体446个,其中152个主体在样本期间内发生评级上调合计168次。在回归过程中,去掉100个在样本期内没有发生评级上调的主体用于样本外检验,同时减少样本数量也使两类主体(上调/未上调)的比例更为均衡。
(二)指标筛选
我们首先大量查阅评级公司的信用评级报告,来筛选各评级公司主要关注的财务指标。
评级报告反映出各评级机构关注的财务指标存在差异,但是多有重合。为扩大覆盖的指标范围,避免错漏关键财务指标,除被较多关注的指标,少数评级机构关注但可能较为关键的指标同样予以保留,最终筛选出24个财务指标。将这些财务指标按盈利能力类别、偿债能力类别、成长能力类别、周转能力类别进一步归类。其中,盈利能力类涵盖销售毛利率、净资产收益率等4个指标;偿债能力类涵盖资产负债率、流动比率、EBITDA利息倍数等8个指标;成长能力类涵盖总资产增长率、净资产增长率、净利润增长率等9个指标;周转能力类涵盖存货周转率、应收账款周转率、总资产周转率3个指标。
(三)变量设定
對于二元logit模型,其可取值的范围为0和1,因此我们可以样本主体是否发生评级上调为被解释变量。定义被解释变量为Yit:Yit=1代表第i个主体在第t期时信用等级(级别或展望)被上调,Yit=0代表第i个主体在第t期时信用等级没有被上调(不变或下调)。
我们以筛选出的财务指标变化量为解释变量。之所以以变化量为解释变量,是因为如果是外部条件改善或经营好转等导致的评级上调,则其财务指标应较前期保持原评级时出现一定的改善,或者说企业目前的财务表现,在某种程度上超过被赋予原等级时的表现。
为了控制可能影响评级调整的行业及企业自身因素,降低评级机构对某些类型企业的特殊偏好可能对估计结果的干扰,我们选择企业属性、企业净资产规模、企业所属行业产出增速、三年内是否有评级调整以及特定样本期前一年度末主体评级作为控制变量。
(四)数据处理
由于我们选择的控制组样本是每年4—7月评级上调主体,一般情况下,此时被评主体已公布上年度年报和本年度一季报,可选择这两期报告公布的财务数据进行分析(若未公布一季报,则主要采取上年度年报的相关数据)。
考虑到使用的是指标变化量为解释变量,对于一季报相关数据,需要选择是与上年同期还是与上年度末的数据比较。通过对外部跟踪评级报告的分析研究,结合对企业经营流程所应具有的基本判断,我们提出如下的数据处理方式:流量指标,如利润、收入等,应与上年同期进行比较,以去除经营时间差异和季节性影响;存量指标,如资产、负债、所有者权益等,其变化是在已有存量的基础之上产生的,因此可以与上年度末数据进行比较,以反映出企业财务情况的近期表现。对于比例形式存在的指标,则分别观察分子与分母指标的类型:流量/流量指标,与上年同期进行比较,去除季节性影响;流量/存量指标,与上年同期进行比较;存量/存量指标,与上年度末数据进行比较,考察其近期变动情况。
对于每一个解释变量,分别计算样本当期年报数据变化量和一季报数据变化量,平均赋权后取其加权值为该解释变量当期值,若样本主体未发布一季报,则以年报数据变化量作为该解释变量当期值。
在处理数据过程中,我们比较了评级上调主体的等级调整日期与一季报发布日期,同时查阅了部分主体的跟踪评级报告。若在等级调整时,样本主体尚未发布一季报,或评级机构未采用季度报告,则仅取其年报数据,无论其后是否发布当期一季报。
在进行计量检验之前,还需要剔除数据集中的异常值,并统一数据量纲。我们将与平均值的偏差超过三倍标准差的样本值视为异常值。对每一个指标,在每一样本期,若某数值超过正常值范围,则该数值以边界值进行替换。由于所用指标均为比例形式或同比形式,将量纲统一为百分比(见表1)。
(五)模型构建
除logit模型外,另一个经常被使用的二值选择模型是probit模型。在实际应用中,logit模型有两个较为明显的优势:一是probit模型假设的标准正态分布是量化积分,与之相比logit模型中logistic分布等式更为简洁(钱水土等,2016);二是logit更易于解释(Kliestik et al., 2015)。
Tseng和Hu(2010)指出,logit 模型作为基于概率理论的统计学意义上的方法,对样本数有较高的要求,需有较多的观测数。为扩充观测值,本文采用了面板类型数据来实证评估影响产业债主体信用等级上调的指标表现。
假设在第t期,对样本内某一主体i,存在一个不可观测的潜变量,用于描绘被评主体i在该期的评级上调情况,等级上调情况可由下式刻画:
(1)
(1)式中,N为样本主体个数,T为时间长度;Xit是l维解释变量,用来描述第i个主体在第t期的各财务指标变化; Zit是m维控制变量,用来描述第i個主体在第t期的可控可观测特征。μi为不可观测的个体效应,用于反映不同主体的个体异质性,包括混合效应、固定效应和随机效应4。若不存在个体效应,μi=a(常数),(1)式为混合模型;若μi随着主体的不同而变化,则(1)式为固定效应模型;若μi为随机变量,则(1)式为随机效应模型。
之前我们令Yit为取值为0或1的二值选择变量, 与 的关系如下:
(2)
部分研究设定临界值r=0,以 与0的比值大小(实际上是 的拟合值 )来判断 可能为0还是1,即:
(3)
由于我们采用logit模型,假定随机项 服从的是logistic分布,此时有:
(4)
进而有:
(5)
因此,设定0为阈值,实际上是认为当Yit=1的概率大于0.5时特定情况会出现,当概率小于0.5时特定情况不会出现。但是这种判别方法不免有些武断,同时可能影响模型的识别效果,特别是在某种情况出现的影响因素还包括定性因素时,定量因素所指示的发生概率即使在不足0.5时特定情形也有较大可能出现。本文并不预先人为设定一个判别阈值,而是根据估计结果结合我们的分析目的来进行选择。
(六)实证分析
在数据处理时,我们计算了原数据的增长或变动情况,且样本时间跨度较短(5期),因此可以认为样本数据是平稳的。
解释变量均为财务数据,各个财务指标之间可能因为相同的分子或分母,较容易产生共线性。因此,计量前需要进行共线性检验。我们采用方差膨胀因子(VIF)方法。检验结果显示,总负债增长率的方差膨胀因子大于10,同时,多个变量的方差膨胀因子超过5,表明变量中存在较为明显的多重共线性,需要采取措施加以克服。
根据计量模型构建原理,模型中的解释变量过多或过少都可能对模型的预测效果造成不良影响,因此在建立模型之前有必要对指标进行筛选,选出可用于预测主体信用评级上调的关键性指标。为了提高指标筛选的科学性、客观性,同时有效消除多重共线性、选取“最优”回归方程,我们选择逐步回归的方法来构建模型,选取最直接有效的影响变量。
变量选择的标准有三条:是否统计显著、是否有明确合理的经济学意义、变量纳入后是否能较为显著地提高模型的解释力度。如果一个有经济学意义且统计显著的变量纳入后,使得原先某个有经济学意义且统计显著的变量变得不再显著,则分别将这两个变量纳入模型之中,选择使模型解释力度更高的变量。
经过数轮筛选后,最终进入模型的解释变量有:净资产收益率、资产负债率、EBITDA利息倍数、总资产增长率、净利润增长率、总资产周转率;进入模型的控制变量包括:近三年是否被下调评级、行业产出加权平均增速、上年末净资产规模、是否AA评级、是否AA+及以上评级。
对筛选出的解释变量和控制变量再次进行VIF检验,方差膨胀因子最高的变量也没有超过2.5,较好地克服了变量之间的多重共线性。
对于面板logit模型,如果采用控制不随时间变化变量的固定效应模型进行估计,许多样本会被直接剔除,严重影响自由度并减少了用于估计的样本数量,干扰系数估计的准确性。因此,我们舍弃固定效应模型,在混合模型与随机效应模型之间进行选择。
通过BP_LM检验来判断混合模型与随机效应模型的适用性。根据表2中的检验结果可知,应选择混合模型进行计量。
混合模型的计量估计结果(见表3)显示,除常数项外,其他所有变量的回归系数都是显著的。
行业产出增速的符号为负且显著,这似乎与直觉不符。导致该变量估计系数为负的可能原因有两个:一是本文使用的产出增速数据在对行业进行分类时所覆盖的行业不全,且分类也不细致,部分未覆盖行业统一归为“其他”行业之中,可能影响到数据的代表性和准确性。二是样本区间跨越5年,且采用3年的平均数据,一些行业受产能或政策周期影响,产出增速变动幅度较大。另外,在经济增速换挡的过程中,行业产出增速也存在下行的动力,如果考虑到在行业整体增长趋缓的环境下,行业内企业经营改善从而评级上调的难度应当更大这一点的话,行业产出增速的估计系数为负具有一定的合理性。
当将样本量加以缩减或者将样本期限适当缩短时,仅有总资产周转率的估计结果变得略微不显著,其他变量的显著性水平不改变,且所有变量的符号没有任何变化,说明表3中的估计结果是较为稳健的。
图3是预测模型的ROC曲线及AUC值,ROC曲线覆盖的区域面积越大(即AUC值越大),表明模型分类效果越好。本模型的AUC值为80.09%,表明模型有较好的预测准确率。
阈值的选取
上文中提到,如果简单以0.5作为选择分类的标准,可能做出较为武断的结论并限制模型的预测效果。如以0.5为(唯一)阈值,则全部样本的分类正确率为88.5%,准确筛选出评级上调主体32个,占比19%。如果目的是尽可能使提示出的主体中涵盖更多的实际上调主体,0.5的阈值选择方式可能就不够有效。因此,将结合模型识别需要及样本特点来选择分类阈值。同时,并不仅设定单一阈值,而是根据分析的目的确定三个阈值,以满足不同的筛选需要。
(一)第一类别阈值
第一类阈值为最低标准,目的是提高模型整体的识别效果,即这一阈值可以尽可能地将等级上调样本和未上调样本区别开来。
将等级上调样本从全部样本中取出,形成一个集合,定义为Y1,其他样本的集合定义为Y0。注意Y1不是上调主体的集合,如果在t期主体i信用等级被上调,则进入Y1的是在t期的主体i这个样本而不是主体i。
图4是两类样本集合预测值( )的概率密度分布。从图中的分布情况直观判断,第一类阈值应该位于0.2~0.4之间。
我们利用穷举法去搜索阈值。搜索结果显示,将第一类别阈值定为0.22,可以最好地实现目标。此时,全部上调样本的66.67%在阈值右侧,全部未上调样本的79.32%在阈值左侧。
(二)第二类别阈值
本研究的最终目的,是从预估主体评级上调的角度,博取评级实际上调后可能带来的超额收益,进而优化投资组合。那么,使筛选出的主体中,尽可能多的涵盖事后实际发生评级上调的主体,是更为重要的目标。
从图4中可以看出,Y1集合分布的右尾较Y0集合覆盖的范围更广,若将阈值设定为一个比较大的数值,则可能使筛选出的主体中实际被上调的主体占比最大。但若选定一个较高的值,则即使可以达到目标,可供选择的范围也可能较窄,不利于组合配置的多样化。因此,将剩余区间划分为(0.22,0.75]与(0.75,1]两段,在两个区间中分别选择能够使筛选出的主体中实际等级上调主体占比最多的阈值。
通过穷举法在(0.22,0.75]区间内进行搜索,最终选择0.71作为第二类别阈值。此时,只有8.93%的上调样本被识别,但在该阈值筛选标准下,被认为有上调可能的样本中,51.72%实际出现等级上調。
(三)第三类别阈值
按照上述思路,在(0.75,1]区间内进行搜索,最终选择0.94作为第三类别阈值。虽然在此阈值筛选标准下,只有4.17%的上调样本被识别,但筛选出的可能上调样本100%出现过等级上调。该阈值使筛选出的主体中实际会被上调主体的占比尽可能多。
效果评估
在筛选出用于模型构建的全部样本中,留出了100个无等级上调记录的主体,共计500个样本。在三类阈值标准下,模型给出的预测结果显示,在这500个样本中分别有169个、8个和2个识别出现失误,占比分别为33.8%、1.6%和0.4%。
再以2017年的数据来检验模型实现投资目标的效果。
筛选符合标准的产业债主体共计1301个5,整理模型变量对应的2016年报和2017年一季报数据,按上文方法处理数据用于模型预测值的计算。全部样本预测值的概率密度分布见图5。
在第一类别阈值0.22标准下,我们选出445个可能上调主体,其中有122个主体在2017年4月至7月间信用等级发生上调,命中率27.42%。
在第二类别阈值0.71标准下,我们选出64个可能上调主体,其中有25个主体在2017年4月至7月间信用等级发生上调,命中率39.06%。
在第三类别阈值0.94标准下,我们选出22个可能上调主体,其中有11个主体在2017年4月至7月间信用等级发生上调,命中率50%。
该模型对8月份之后的评级上调主体也有一定的识别作用。8—12月共有36个产业债主体信用等级上调,本模型能够识别其中9个(其中有14个不在样本范围内)。这也从侧面说明,经营主体在短期内的经营情况具有一定的延续性,同时评级机构在上调主体评级时,考察的逻辑具有一致性。如果使用年报和二季度数据测算,则可识别其中的7个。由于7月份之后等级上调主体相对较少,这一策略的有效性将大打折扣。
投资组合构建与回测
假设现在处于2017年二季度,我们通过本模型的预测结果来构建投资组合,测试模型在实际中的运行效果。
对于可选标的范围的确定,根据我们2017年3月31日发布的《2017年信用债市场第二季度报告》所提出的高评级短久期配置建议,选择发债主体在AA及以上,久期小于3的信用债。
在筛选时,我们根据模型给出的预测值从大到小对各主体加以排序,之后自上而下选择符合投资标准的债券标的。在此过程中,我们忽略发债主体和债项的具体名称,以严格确保不会刻意选择已知在测试期间内被上调等级主体发行的信用债。
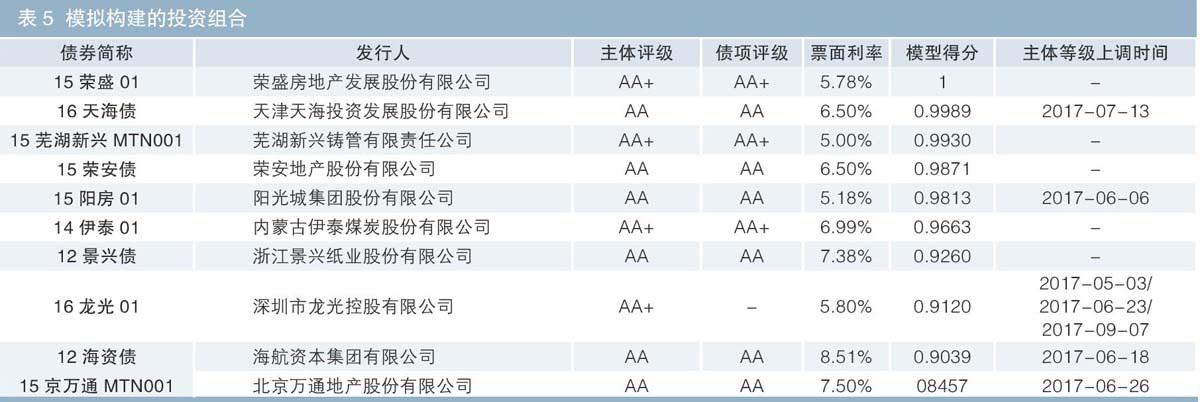
挑选如表5所示10只债券构建投资组合,为计算简便,假设每只债的购买数量为一个单位。经事后验证,其中的5只债券对应发行人在测试期间确实发生过等级上调。
由于在4月底时基本上可以获得多数发债主体的年报和一季报数据,首先尝试在5月第一个交易日,即5月3日构建上述组合。该组合如果一直持有至12月15日,这期间总回报率为3.26%(非年化,以中债估值计算;未考虑冲击成本、杠杆及利息再投资等因素,下同)。同期,新综合指数收益率为1.1%,新高信用等级指数收益率为1.97%,模拟组合收益明显高于业绩基准。
考虑到从3月开始,既有主体开始披露年报数据,且计算模型在只有年报数据的情况下同样可以进行处理,因此尝试从4月份开始構建组合。这样,模拟区间是2017年4月1日至12月15日,模拟组合回报率为3.26%。同期,新综合指数收益率为0.47%,新高信用等级指数收益率为1.46%,模拟组合依然明显优于业绩基准。
在挑选标的时,我们没有去刻意在意构建组合时点标的券的到期收益率,如果将此纳入考虑,这个组合的回报率还可能会更高。6
另一种相对较为激进的配置方法是,当有债券在持有期出现等级上调时,继续持有该债券一段时期(如10个交易日)后售出,再配置其他可能被上调主体发行的债券,多次博弈信用等级上调带来的估值提升。
仍以上述模拟组合为例,其中有5只涉及主体上调的信用债,在对应主体等级上调后10个工作日售出该债券,同时购入备选债券。为计算简便,假设备选债券的发行主体在期间内未出现等级上调。此时,这种模拟投资方法在4月1日至12月15日期间的回报率为2.92%,依然明显跑赢业绩基准。这种通过换手来博取更多主体等级上调带来超额收益的策略,在模拟中不如一直持有的组合收益率高。这种情况出现的一个可能原因是,当模拟组合中的债券需要调整时,许多优质标的对应的主体已发生过等级上调,从而被排除在备选范围之外。另外,增加换手次数会带来额外的冲击成本,需要将此纳入考虑。
投资建议
上述方法可以为信用债标的选择提供参考,或者优化已有投资组合,在获取票息收入的同时,有针对性地博弈估值提高带来的额外收益。虽然持有至到期策略在一定程度上可以忽略债券价格的波动,但是在净值型产品的配置中,估值的抬升将会提高配置组合的单位净值。由于不同投资机构具有不同的投资风格和投资策略,这使得可选择的债券范围不同,进而使选定的投资组合也会有较大差异。因此,这一方法更适合作为一种辅助型策略,即在债券配置的整体思路确定后,在具体配置信用品种时应用,以进一步优化投资组合。而具体的操作模式应根据实际情况灵活调整。另外需要提示的是,有等级上调可能性不代表完全没有信用风险,特别是存在财务数据不够真实的情况时,这种策略不应作为控制风险的替代方法。
注1.所发债券不属于中债城投债收益率曲线样本券的主体。
2.每年6、7月份的评级调整较为集中,选择这个时间段一是可以尽可能使用不同主体的同期数据,二是评级上调的样本较大。
3.若在样本期间等级为AAA/稳定,则该主体无论有怎样的经营和财务表现,信用等级均无法再次上调。即使主体样本评级为AAA/负面,但若在样本期内等级上调至AAA/稳定,则下一期内无等级进一步上调的空间,这会影响最终估计的准确性和有效性。为避免这一情况的出现,同时节省样本筛选所需要的时间成本,直接将2016年之前评级为AAA的主体剔除。
4.这里假设不存在时间固定效应和时间随机效应。
5.预测模型所需变量较初始构建模型时大为减少,因此由于数据缺失被剔除的主体明显减少。
6.在最初测试模型效果时,笔者曾将测试起点待选券的到期收益率作为选择标准,同时略微放开了久期限制,模拟组合的收益率比本文中组合的收益率高大约40%。
